query
1. Data preparation
1.1 create table
// Create department table
create table if not exists dept (
deptno int,
dname string,
loc int
)
row format delimited fields terminated by '\t';
// Create employee table
create table if not exists emp (
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
row format delimited fields terminated by '\t';
1.2 loading data
// Import data load data local inpath '/opt/module/hive-3.1.2/datas/dept.txt' into table dept; load data local inpath '/opt/module/hive-3.1.2/datas/emp.txt' into table emp;
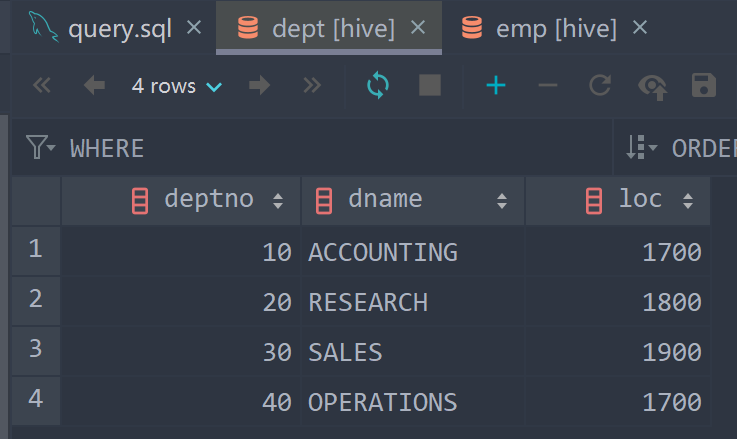
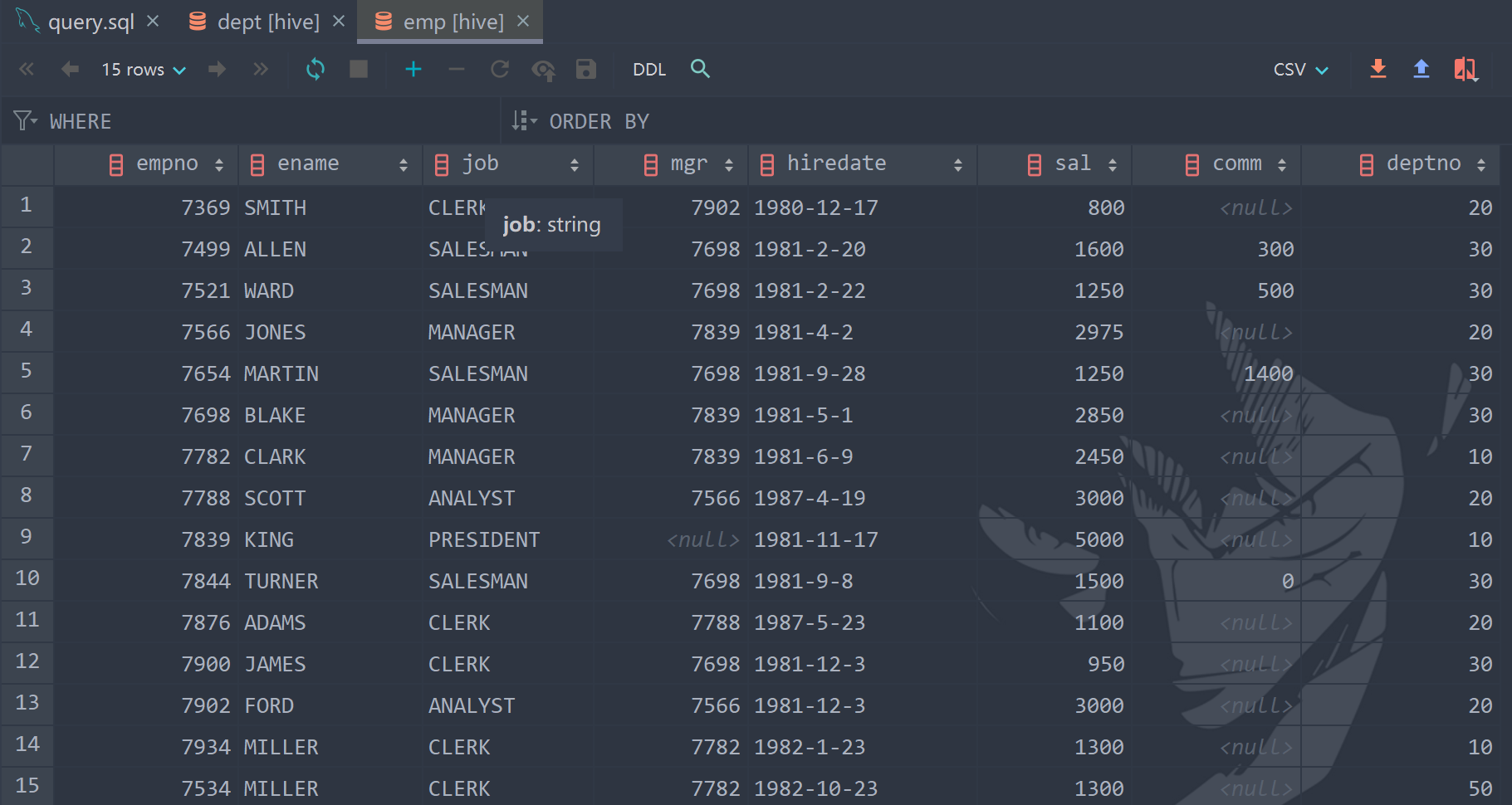
1.3 data display
2. Basic query
2.1 basic query
- Full table query
select * from emp;
- Select a specific column query
select empno, ename from emp;
2.2 column alias
- Rename a column
- Easy to calculate
- Immediately following the column name, you can also add the keyword AS between the column name and alias
select ename AS name, deptno dn from emp;
2.3 arithmetic operators
| operator | describe |
|---|---|
| A+B | Add A and B |
| A-B | A minus B |
| A*B | Multiply A and B |
| A/B | A divided by B |
| A%B | A to B remainder |
| A&B | A and B are bitwise AND |
| A|B | A and B take or by bit |
| A^B | A and B bitwise XOR |
| ~A | A reverse by bit |
// + 1 after querying the salary of all employees select sal +1 AS sal from emp;
2.4 common functions
- count the total number of rows
select count(*) cnt from emp;
- Find the maximum value of salary max
select max(sal) max_sal from emp;
- Find the minimum value of salary min
select min(sal) min_sal from emp;
- sum of wages
select sum(sal) sum_sal from emp;
- Average wages avg
select avg(sal) avg_sal from emp;
2.5 Limit statement
The LIMIT clause is used to LIMIT the number of rows returned
select * from emp limit 5;
2.6 Where statement
- Use the WHERE clause to filter out rows that do not meet the conditions
- The WHERE clause follows the FROM clause
// Query all employees with salary greater than 1000 select * from emp where sal > 1000;
2.7 comparison operators
| Operator | Supported data types | describe |
|---|---|---|
| A=B | Basic data type | If A is equal to B, it returns TRUE, otherwise it returns FALSE |
| A<=>B | Basic data type | Returns TRUE if both A and B are NULL, and False if one side is NULL |
| A<>B, A!=B | Basic data type | If A or B is NULL, NULL is returned; If A is not equal to B, it returns TRUE, otherwise it returns FALSE |
| A<B | Basic data type | If A or B is NULL, NULL is returned; If A is less than B, it returns TRUE, otherwise it returns FALSE |
| A<=B | Basic data type | If A or B is NULL, NULL is returned; If A is less than or equal to B, it returns TRUE, otherwise it returns FALSE |
| A>B | Basic data type | If A or B is NULL, NULL is returned; If A is greater than B, it returns TRUE, otherwise it returns FALSE |
| A>=B | Basic data type | If A or B is NULL, NULL is returned; If A is greater than or equal to B, it returns TRUE, otherwise it returns FALSE |
| A [NOT] BETWEEN B AND C | Basic data type | If any of A, B or C is NULL, the result is NULL. If the value of A is greater than or equal to B and less than or equal to C, the result is TRUE, otherwise it is FALSE. If you use the NOT keyword, the opposite effect can be achieved. |
| A IS NULL | All data types | If A is equal to NULL, it returns TRUE, otherwise it returns FALSE |
| A IS NOT NULL | All data types | If A is not equal to NULL, it returns TRUE, otherwise it returns FALSE |
| In (value 1, value 2) | All data types | Use the IN operation to display the values IN the list |
| A [NOT] LIKE B | STRING type | B is A simple regular expression under SQL, also known as wildcard pattern. If A matches it, it returns TRUE; Otherwise, FALSE is returned. |
| A RLIKE B, A REGEXP B | STRING type | B is A regular expression based on java. If A matches it, it returns TRUE; Otherwise, FALSE is returned. |
// Query employees with salary equal to 5000 select * from emp where sal = 5000; // Query employee information with salary between 500 and 1000 select * from emp where sal between 500 and 1000; // Query employee information with comm blank select * from emp where comm is null; // Query employee information with salary of 1500 or 5000 select * from emp where sal in (1500, 5000);
2.8 Like and RLike
- Use the LIKE operator to select a similar value
- %Represents zero or more characters
- _ Represents a character
- RLIKE clause is an extension of this function in Hive, which can specify matching conditions through Java regular expressions
// Query employee information whose name starts with A select * from emp where ename like 'A%'; // Query the employee information with the second letter A in the name select * from emp where ename like '_A%'; // Query employee information with A in name select * from emp where ename rlike '[A]';
2.9 logical operators
| Operator | meaning |
|---|---|
| AND | Logical Union |
| OR | Logical or |
| NOT | Logical no |
// The inquiry salary is greater than 1000 and the Department is 30 select * from emp where sal > 1000 and deptno = 30; // Query salary is greater than 1000 or department is 30 select * from emp where sal > 1000 or deptno = 30; // Query employee information except 20 departments and 30 departments select * from emp where deptno not in (30, 20);
3. Grouping
3.1 Group By statement
The GROUP BY statement is usually used with an aggregate function to group one or more queued results, and then aggregate each group.
// Calculate the average salary of each department select deptno, avg(sal) avg_sal from emp group by deptno; // Calculate the maximum salary for each position in each department select t.deptno, t.job, max(t.sal) max_sal from emp t group by t.deptno, t.job;
3.2 Having statement
Differences between having and where:\
- having is to filter the data after grouping, and where is to filter the data before grouping
- Aggregate functions can be used after having, but not after where
- The execution order during query: from > where > group (including aggregation) > having > order > select
// Find the average salary of each department select deptno, avg(sal) from emp group by deptno; // The average salary of each department is greater than 2000 select deptno, avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;
4. Join statement
Benefits of table aliases:
- Using aliases can simplify queries
- Using table name prefix can improve execution efficiency
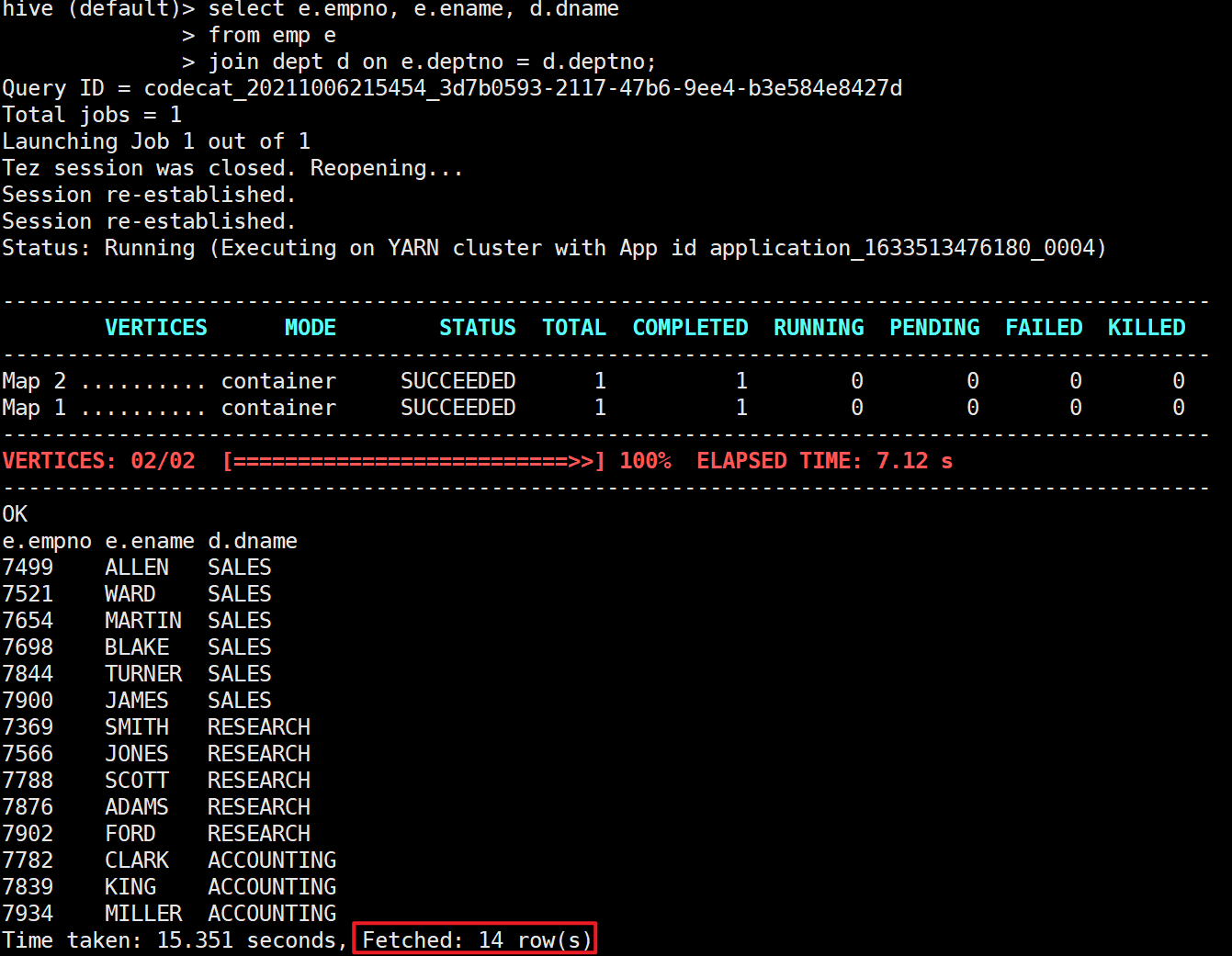
4.1 internal connection
Only if there are data matching the connection conditions in the two tables to be connected, the data will be retained
select e.empno, e.ename, d.dname from emp e join dept d on e.deptno = d.deptno;
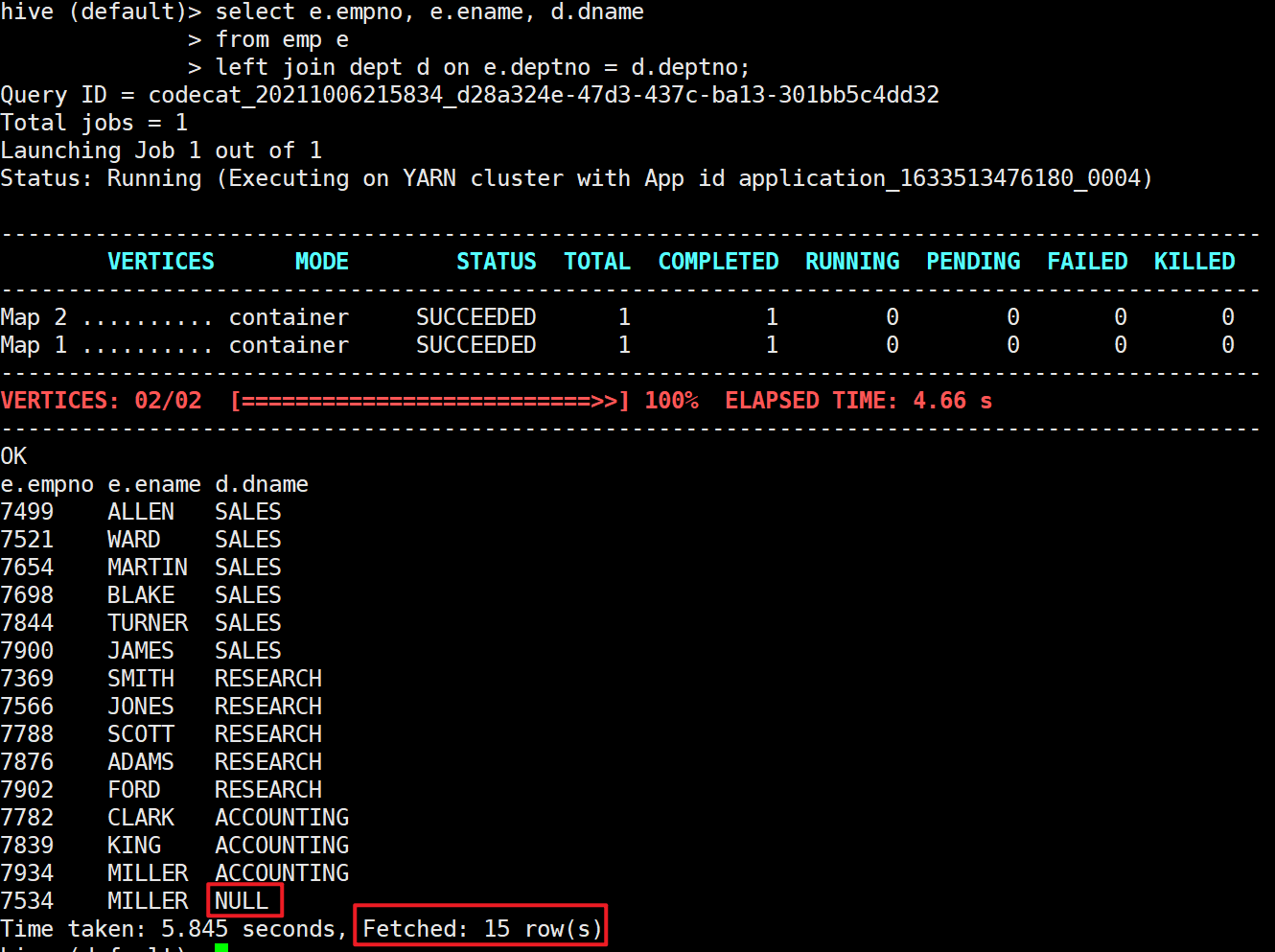
4.2 left outer connection
The data in the left table that matches the connection conditions will be retained
select e.empno, e.ename, d.dname from emp e left join dept d on e.deptno = d.deptno;
4.3 right outer connection
The data in the right table that matches the connection conditions will be retained
select e.empno, e.ename, d.dname from emp e right join dept d on e.deptno = d.deptno;
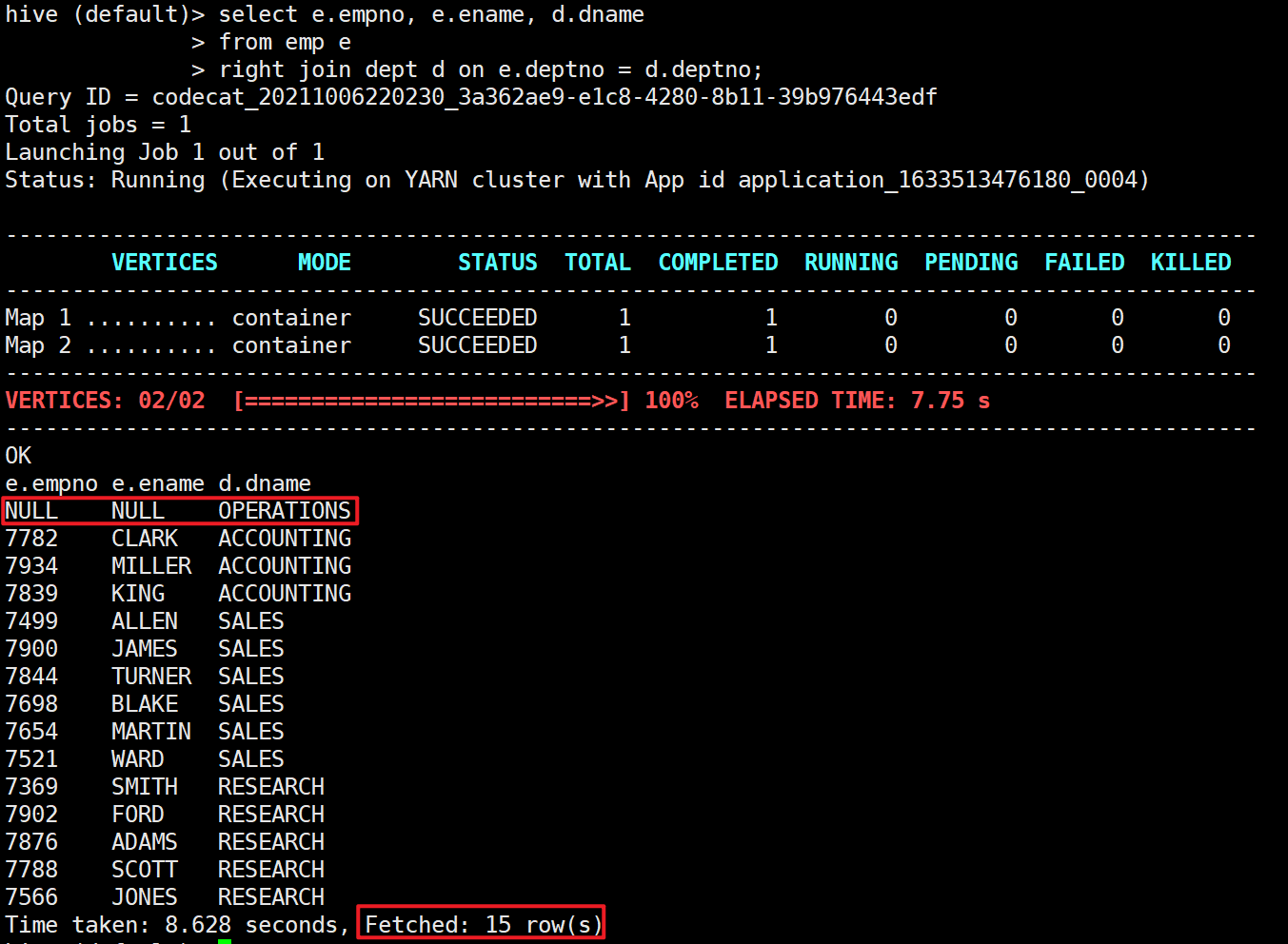
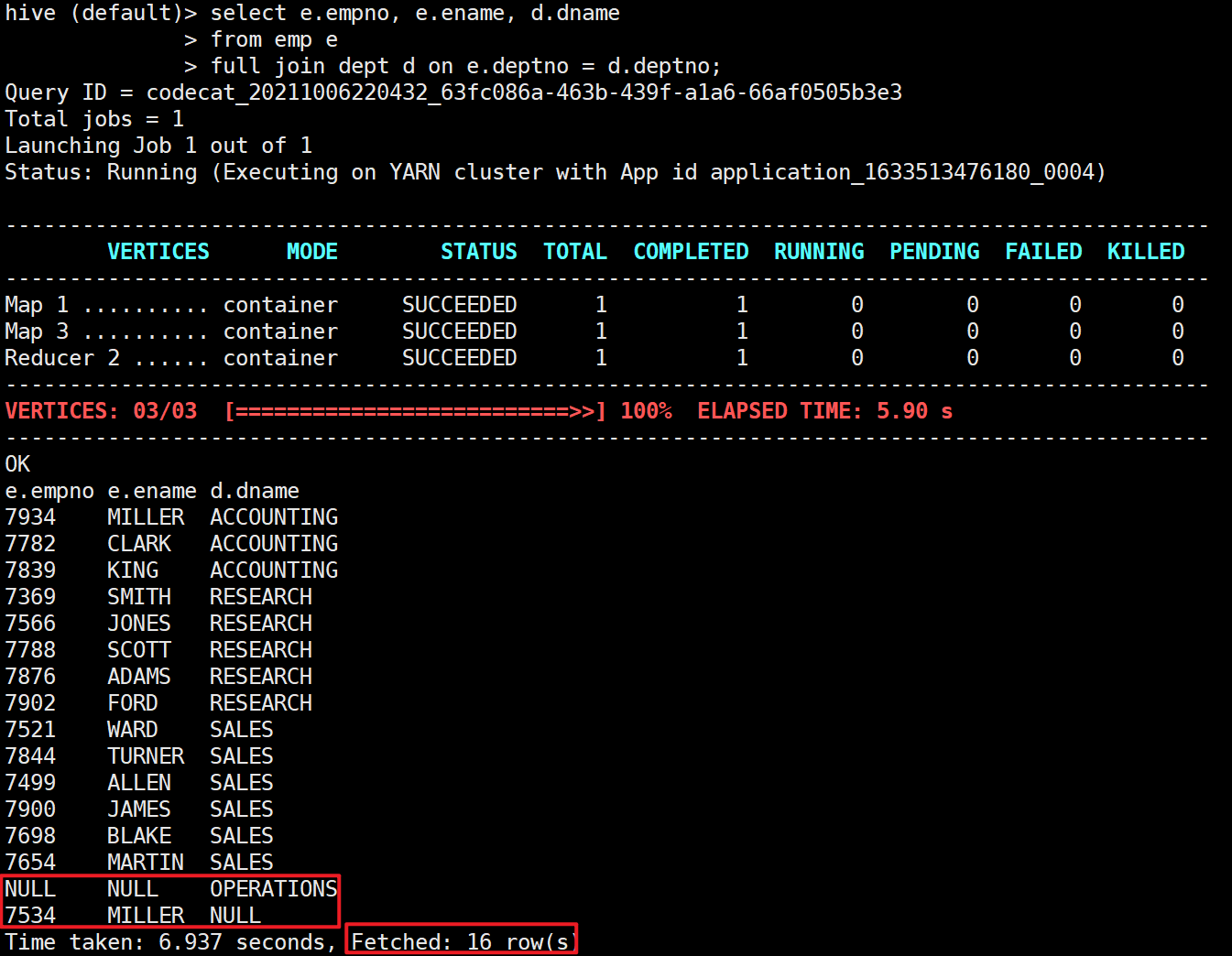
4.4 full external connection
The data matching the connection conditions in the two tables to be connected will be retained
select e.empno, e.ename, d.dname from emp e full join dept d on e.deptno = d.deptno;
4.5 Cartesian product
Cartesian assemblies are generated under the following conditions:
- Omit connection conditions
- Invalid connection condition
- All rows in all tables are connected to each other
select empno, dname from emp, dept;
5. Sorting
5.1 global sort Order By
Global sorting, only one Reducer
// Query employee information in ascending order of salary select * from emp order by sal; // Query employee information in descending order of salary select * from emp order by sal desc;
5.2 sorting by alias
// Sort by twice the employee's salary select ename, sal*2 twosal from emp order by twosal;
5.3 sorting multiple columns
// Sort by multiple columns: sort by department and salary in ascending order select ename, deptno, sal from emp order by deptno, sal;
5.4 Sort By within each Reduce
Sort by: for large-scale data sets, order by is very inefficient. In many cases, global sorting is not required. In this case, Sort by can be used. Sort by generates a sort file for each Reducer. Each Reducer is sorted internally, not for the global result set
// Set the number of reduce set mapreduce.job.reduces=3; // Import query results into a file insert overwrite local directory '/opt/module/hive-3.1.2/datas/export/sortby-result' row format delimited fields terminated by '\t' select * from emp sort by deptno desc ;
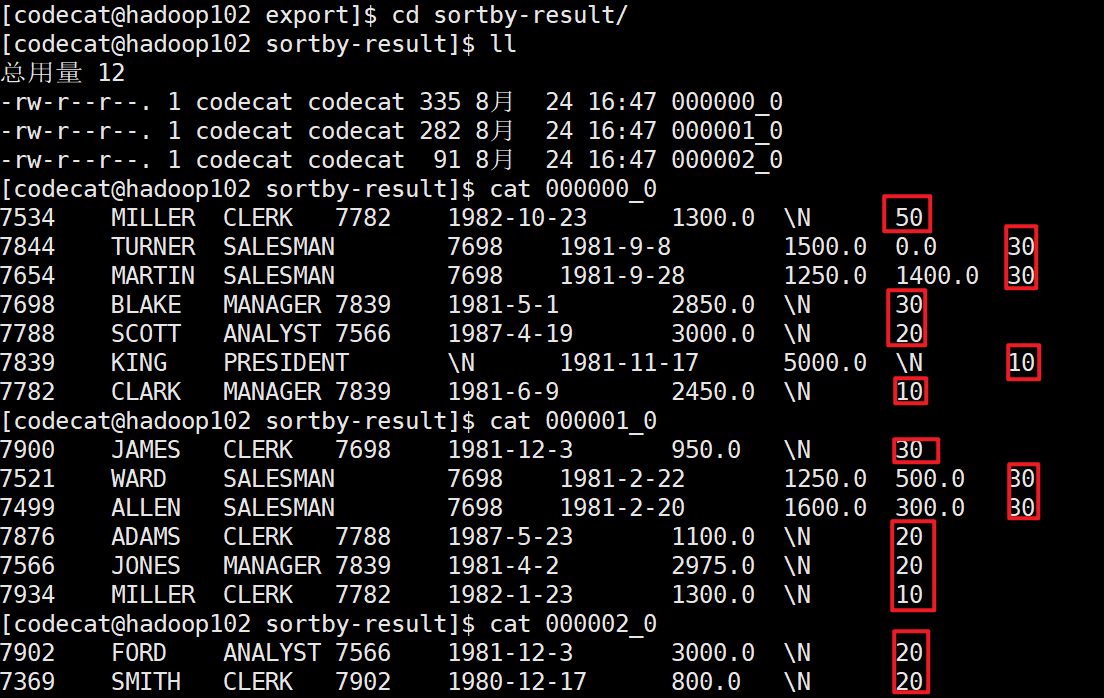
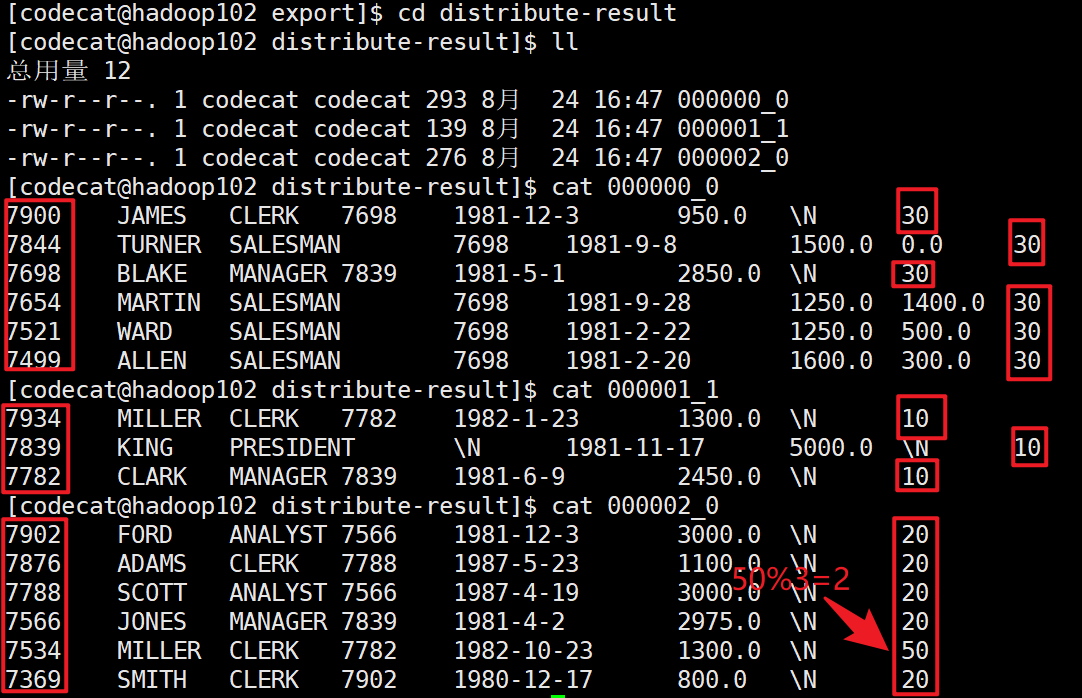
5.5 partition distribution by
Distribution by: in some cases, we need to control which reducer a particular row should go to, usually for subsequent aggregation operations. The distribute by clause can do this. distribute by is similar to partition (custom partition) in MR. it is used in combination with sort by.
// Set the number of reduce set mapreduce.job.reduces=3; // First, divide by department number, and then sort by employee number in descending order insert overwrite local directory '/opt/module/hive-3.1.2/datas/export/distribute-result_4' row format delimited fields terminated by '\t' select * from emp distribute by deptno sort by empno desc ;
5.6 Cluster By
When the distribution by and sort by fields are the same, the cluster by mode can be used
// The following two expressions are equivalent select * from emp cluster by deptno; select * from emp distribute by deptno sort by deptno;