When did Apache Spark start to support the integrated Hive feature? I believe that as long as readers have used Spark, they will say that this is a long time ago.
When does Apache Flink support integration with Hive? Readers may be confused. Haven't they supported it yet, haven't they used it? Or the latest version only supports it, but the function is still weak.
In fact, it doesn't make sense to compare. The development goals of different communities will always be different, and Flink has invested a lot of energy in real-time streaming computing. But what I want to express is that Apache Hive has become the focus of data warehouse ecosystem. It is not only a SQL Engine for big data analysis and ETL, but also a data management platform. Therefore, whether it is Spark, Flink, Impala, Presto, etc., it will actively support the function of integrating Hive.
Indeed, readers who really need to use Flink to access Hive for data reading and writing will find that Apache Flink version 1.9.0 is only beginning to provide the function of integrating with Hive. However, it is gratifying that the Flink community has made a lot of efforts to integrate the Hive function, and the progress is relatively smooth at present. Recently, the Flink 1.10.0 RC1 version has been released, and interested readers can conduct research and verification of the function.
architecture design
First of all, based on the community open materials and blogs, the author gives a general introduction to the architecture design of Flink integrated Hive.
The purpose of Apache Flink and Hive integration mainly includes access to metadata and actual table data.
metadata
In order to access the metadata of external system, Flink has just provided the concept of external catalog. However, the definition of external catalog is very incomplete, and it is basically unavailable. Flink 1.10 officially removed the ExternalCatalog API (FLINK-13697), which includes:
- ExternalCatalog (and all dependent classes, such as ExternalTable)
- SchematicDescriptor, MetadataDescriptor and StatisticsDescriptor
To solve the problem of external Catalog, Flink community proposed a new set of Catalog interface (new Catalog API) to replace the existing external Catalog. The new Catalog implementation features include:
- It can support database, table, partition and other metadata objects
- Allows multiple Catalog instances to be maintained in a user Session, enabling simultaneous access to multiple external systems
- Catalog accesses Flink in pluggable way, allowing users to provide customized implementation
The following figure shows the overall architecture of the new Catalog API:
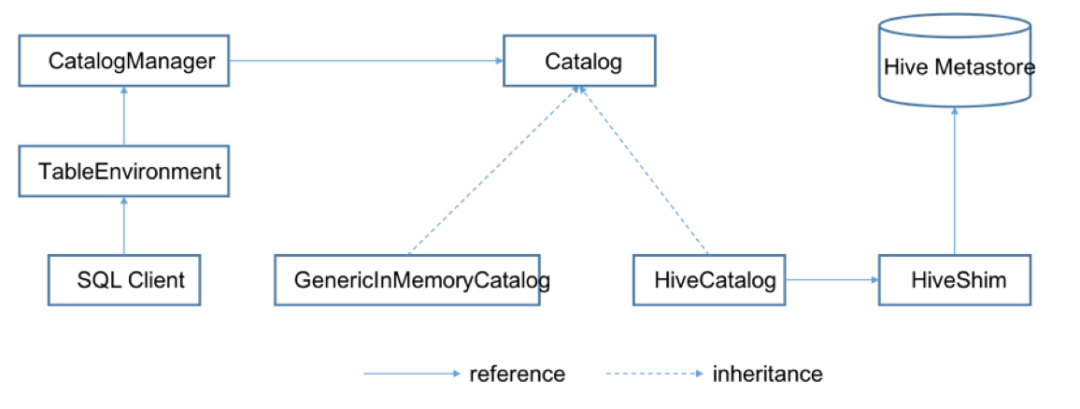
When creating a TableEnvironment, a CatalogManager will be created at the same time to manage different Catalog instances. TableEnvironment provides metadata services for Table API and SQL Client users through Catalog.
val settings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build() val tableEnv = TableEnvironment.create(settings) val name = "myhive" val defaultDatabase = "mydatabase" val hiveConfDir = "/opt/hive-conf"// a local path val version = "2.3.4" val hive = newHiveCatalog(name, defaultDatabase, hiveConfDir, version) tableEnv.registerCatalog("myhive", hive) // set the HiveCatalog as the current catalog of the session tableEnv.useCatalog("myhive")
At present, there are two implementations of Catalog, GenericInMemoryCatalog and HiveCatalog. GenericInMemoryCatalog keeps the original Flink metadata management mechanism and saves all metadata in memory. The HiveCatalog will connect with an instance of Hive Metastore to provide metadata persistence. To interact with Hive using Flink, users need to configure a HiveCatalog and access metadata in Hive through HiveCatalog.
On the other hand, HiveCatalog can also be used to process the metadata of Flink itself. In this scenario, HiveCatalog only uses Hive Metastore as persistent storage. The metadata written to Hive Metastore is not necessarily the format supported by Hive. A HiveCatalog instance can support both modes. Users do not need to create different instances for managing metadata of Hive and Flink.
In addition, different versions of Hive Metastore are supported by designing HiveShim. Please refer to the official documents for the list of supported versions of Hive.
Table data
Flink provides the Hive Data Connector to read and write hive's table data. Hive Data Connector reuses Input/Output Format, SerDe and other classes of hive itself as much as possible. On the one hand, it reduces code duplication, and on the other hand, it can maintain compatibility with hive to the greatest extent, that is, the data written by Flink hive can be read normally, and vice versa.
Integrated Hive features
The integrated function of Flink and Hive is released as trial function in version 1.9.0, which has many limitations. However, the stable version of Flink 1.10 released soon will more perfect the function of integrated Hive and apply it to enterprise scenarios.
In order to let readers experience the function of Flink 1.10 integrated Hive in advance, the author will compile Flink 1.10.0 RC1 version based on Cloudera CDH and conduct a more complete test.
environmental information
CDH version: cdh5.16.2
Flink version: release-1.10.0-rc1
Flink uses the RC version for testing purposes only and is not recommended for production.
At present, the Cloudera Data Platform officially integrates Flink as its stream computing product, which is very convenient for users to use.
The CDH environment turns on Sentry and Kerberos.
Download and compile Flink
$ wget https://github.com/apache/flink/archive/release-1.10.0-rc1.tar.gz $ tar zxvf release-1.10.0-rc1.tar.gz $ cd flink-release-1.10.0-rc1/ $ mvn clean install -DskipTests-Pvendor-repos -Dhadoop.version=2.6.0-cdh5.16.2
If there is no accident, the following error will be reported when compiling to the Flink Hadoop FS module:
[ERROR] Failed to execute goal on project flink-hadoop-fs: Could not resolve dependencies for project org.apache.flink:flink-hadoop-fs:jar:1.10.0: Failed to collect dependencies at org.apache.flink:flink-shaded-hadoop-2:jar:2.6.0-cdh5.16.2-9.0: Failed to read artifact descriptor for org.apache.flink:flink-shaded-hadoop-2:jar:2.6.0-cdh5.16.2-9.0: Could not transfer artifact org.apache.flink:flink-shaded-hadoop-2:pom:2.6.0-cdh5.16.2-9.0 from/to HDPReleases (https://repo.hortonworks.com/content/repositories/releases/): Remote host closed connection during handshake: SSL peer shut down incorrectly
During compilation, we encountered a problem that flink-shaded-hadoop-2 could not find. Actually, looking at the Maven warehouse, we found that the root cause is that the jar package of CDH's flink-shaded-hadoop-2 does not have a corresponding compiled version in the Maven central warehouse, so we need to package the flink-shaded-hadoop-2 that Flink relies on before compiling.
■ solve the problem of flick-shaded-hadoop-2
- Get the Flink shaved source code
git clone https://github.com/apache/flink-shaded.git
- Switch dependent version branches
Switch the corresponding code branches according to the missing version prompted in error reporting above, that is, the missing version is 9.0's flick-shaded-hadoop-2:
git checkout release-9.0
- Configure CDH Repo warehouse
Modify pom.xml in the Flink shared project and add the CDH maven warehouse, otherwise, no CDH related package can be found at compile time.
Add the following to
<profile> <id>vendor-repos</id> <activation> <property> <name>vendor-repos</name> </property> </activation> <!-- Add vendor maven repositories --> <repositories> <!-- Cloudera --> <repository> <id>cloudera-releases</id> <url>https://repository.cloudera.com/artifactory/cloudera-repos</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>false</enabled> </snapshots> </repository> </repositories> </profile>
- Compile Flink shaded
Start compilation:
mvn clean install -DskipTests-Drat.skip=true-Pvendor-repos -Dhadoop.version=2.6.0-cdh5.16.2
It is recommended to compile through scientific Internet access. If readers encounter some problems with network connection, they can try again or change the warehouse address of dependent components.
After the compilation is successful, the flink-shaded-hadoop-2-uber-2.6.0-cdh5.16.2-9.0.jar will be installed in the local maven warehouse, as follows is the final log of compilation:
Installing /Users/.../source/flink-shaded/flink-shaded-hadoop-2-uber/target/flink-shaded-hadoop-2-uber-2.6.0-cdh5.16.2-9.0.jar to /Users/.../.m2/repository/org/apache/flink/flink-shaded-hadoop-2-uber/2.6.0-cdh5.16.2-9.0/flink-shaded-hadoop-2-uber-2.6.0-cdh5.16.2-9.0.jar
Installing /Users/.../source/flink-shaded/flink-shaded-hadoop-2-uber/target/dependency-reduced-pom.xml to /Users/.../.m2/repository/org/apache/flink/flink-shaded-hadoop-2-uber/2.6.0-cdh5.16.2-9.0/flink-shaded-hadoop-2-uber-2.6.0-cdh5.16.2-9.0.pom
Recompile Flink
mvn clean install -DskipTests-Pvendor-repos -Dhadoop.version=2.6.0-cdh5.16.2
The long waiting process allows readers to do other things in parallel.
During compilation, if there is no accident, you will see the following error message:
[INFO] Running 'npm ci --cache-max=0 --no-save' in /Users/xxx/Downloads/Flink/flink-release-1.10.0-rc1/flink-release-1.10.0-rc1/flink-runtime-web/web-dashboard [WARNING] npm WARN prepare removing existing node_modules/ before installation [ERROR] WARN registry Unexpected warning for https://registry.npmjs.org/: Miscellaneous Warning ECONNRESET: request to https://registry.npmjs.org/mime/-/mime-2.4.0.tgz failed, reason: read ECONNRESET [ERROR] WARN registry Using stale package data from https://registry.npmjs.org/ due to a request error during revalidation. [ERROR] WARN registry Unexpected warning for https://registry.npmjs.org/: Miscellaneous Warning ECONNRESET: request to https://registry.npmjs.org/optimist/-/optimist-0.6.1.tgz failed, reason: read ECONNRESET
As you can see, the Flink runtime web module introduces the dependency on frontend Maven plugin, which requires node, npm and dependency components to be installed.
If you do not access the Internet through science, you can modify the flink-runtime-web/pom.xml file to add the information of nodeDownloadRoot and npmDownloadRoot:
<plugin> <groupId>com.github.eirslett</groupId> <artifactId>frontend-maven-plugin</artifactId> <version>1.6</version> <executions> <execution> <id>install node and npm</id> <goals> <goal>install-node-and-npm</goal> </goals> <configuration> <nodeDownloadRoot>https://registry.npm.taobao.org/dist/</nodeDownloadRoot> <npmDownloadRoot>https://registry.npmjs.org/npm/-/</npmDownloadRoot> <nodeVersion>v10.9.0</nodeVersion> </configuration> </execution> <execution> <id>npm install</id> <goals> <goal>npm</goal> </goals> <configuration> <arguments>ci --cache-max=0 --no-save</arguments> <environmentVariables> <HUSKY_SKIP_INSTALL>true</HUSKY_SKIP_INSTALL> </environmentVariables> </configuration> </execution> <execution> <id>npm run build</id> <goals> <goal>npm</goal> </goals> <configuration> <arguments>run build</arguments> </configuration> </execution> </executions> <configuration> <workingDirectory>web-dashboard</workingDirectory> </configuration> </plugin>
After compilation, the Flink installation file is located in the flink-release-1.10.0-rc1 / Flink disk / target / flink-1.10.0-bin directory, packaged and uploaded to the deployment node:
$ cd flink-dist/target/flink-1.10.0-bin $ tar zcvf flink-1.10.0.tar.gz flink-1.10.0
Deployment and configuration
Flink deployment is relatively simple, just unzip the package. In addition, soft links and environment variables can be set, which will not be introduced by the author.
The core configuration file of Flink is flink-conf.yaml. A typical configuration is as follows:
jobmanager.rpc.address: localhost jobmanager.rpc.port: 6123 jobmanager.heap.size: 2048m taskmanager.heap.size: 1024m taskmanager.numberOfTaskSlots: 4 parallelism.default: 1 high-availability: zookeeper high-availability.storageDir:hdfs:///user/flink110/recovery high-availability.zookeeper.quorum: zk1:2181,zk2:2181,zk3:2181 state.backend: filesystem state.checkpoints.dir: hdfs:///user/flink110/checkpoints state.savepoints.dir:hdfs:///user/flink110/savepoints jobmanager.execution.failover-strategy: region rest.port: 8081 taskmanager.memory.preallocate: false classloader.resolve-order: parent-first security.kerberos.login.use-ticket-cache: true security.kerberos.login.keytab:/home/flink_user/flink_user.keytab security.kerberos.login.principal: flink_user jobmanager.archive.fs.dir:hdfs:///user/flink110/completed-jobs historyserver.web.address: 0.0.0.0 historyserver.web.port: 8082 historyserver.archive.fs.dir:hdfs:///user/flink110/completed-jobs historyserver.archive.fs.refresh-interval: 10000 //The author only lists some common configuration parameters, which are modified according to the actual situation. In fact, the configuration parameters are easy to understand, and will be explained in detail later in combination with the actual combat articles. **■ Integrate Hive Configured dependencies** //In addition to the above configuration, users also need to add corresponding dependencies if they want to use the function integrated by Flink and Hive: - If you need to use SQL Client,You need to jar copy to Flink Of lib Directory - If you need to use Table API,The corresponding dependency needs to be added to the project (such as pom.xml)
org.apache.flink
flink-connector-hive_2.11
1.11-SNAPSHOT
provided
org.apache.flink
flink-table-api-java-bridge_2.11
1.11-SNAPSHOT
provided
org.apache.hive
hive-exec
${hive.version}
provided
The author mainly introduces how to use SQL Client. Because the CDH version is 5.16.2, including Hadoop version 2.6.0 and Hive version 1.1.0, the following jar packages need to be copied to the lib directory in the flink deployment home directory: -Flink's Hive connector flink-connector-hive2.11-1.10.0.jar flink-hadoop-compatibility2.11-1.10.0.jar flink-orc_2.11-1.10.0.jar
flink-release-1.10.0-rc1/flink-connectors/flink-hadoop-compatibility/target/flink-hadoop-compatibility_2.11-1.10.0.jar
flink-release-1.10.0-rc1/flink-connectors/flink-connector-hive/target/flink-connector-hive_2.11-1.10.0.jar
flink-release-1.10.0-rc1/flink-formats/flink-orc/target/flink-orc_2.11-1.10.0.jar
- Hadoop rely on flink-shaded-hadoop-2-uber-2.6.0-cdh5.16.2-9.0.jar
flink-shaded/flink-shaded-hadoop-2-uber/target/flink-shaded-hadoop-2-uber-2.6.0-cdh5.16.2-9.0.jar
- Hive dependence
hive-exec-1.1.0-cdh5.16.2.jar
hive-metastore-1.1.0-cdh5.16.2.jar
libfb303-0.9.3.jar
/opt/cloudera/parcels/CDH/lib/hive/lib/hive-exec-1.1.0-cdh5.16.2.jar /opt/cloudera/parcels/CDH/lib/hive/lib/hive-metastore-1.1.0-cdh5.16.2.jar /opt/cloudera/parcels/CDH/lib/hive/lib/libfb303- 0.9.3.jar
flink-shaded-hadoop-2-uber contains Hive's dependency on Hadoop. If you do not use the package provided by Flink, you can also add the Hadoop package used in the cluster, but you need to ensure that the added Hadoop version is compatible with the version Hive depends on.
The dependent Hive packages (i.e. Hive exec and Hive Metastore) can also use the jar packages provided by Hive in the user cluster. For details, please refer to support different versions of Hive.
For Flink deployed nodes, add Hadoop, Yarn and Hive clients.
■ configure HiveCatalog
Over the years, Hive Metastore has developed into a de facto metadata center in the Hadoop ecosystem. Many companies have a single instance of the Hive Metastore service in their production to manage all their metadata (Hive metadata or non Hive metadata).
If you have deployed both Hive and Flink, you can use Hive Metastore to manage the metadata of Flink through HiveCatalog.
If only Flink is deployed, HiveCatalog is the only persistent Catalog that Flink provides out of the box. If there is no persistent Catalog, using Flink SQL to create DDL requires that meta objects like Kafka tables be created repeatedly in each session, which wastes a lot of time. HiveCatalog only needs to create tables and other meta objects once through authorized users, and can be easily referenced and managed in future cross sessions.
If you want to use SQL Client, you need to specify your own Catalog in sql-client-defaults.yaml, and you can specify one or more Catalog instances in the catalogs list of sql-client-defaults.yaml.
The following example shows how to specify a HiveCatalog:
execution: planner: blink type: streaming ... current-catalog: myhive # set the HiveCatalog as the current catalog of the session current-database: mydatabase catalogs: - name: myhive type: hive hive-conf-dir: /opt/hive-conf # contains hive-site.xml hive-version:2.3.4
Among them:
- Name is the name specified by the user for each Catalog instance. The Catalog name and DB name constitute the metadata namespace in FlinkSQL. Therefore, it is necessary to ensure that the name of each Catalog is unique.
- Type indicates the type of Catalog. For HiveCatalog, type should be specified as hive.
- Hive conf dir is used to read hive's configuration file. You can set it as hive's configuration file directory in the cluster.
- Hive version specifies the hive version used.
After HiveCatalog is specified, the user can start SQL client and verify that HiveCatalog is loaded correctly with the following command.
Flink SQL> show catalogs; default_catalog myhive Flink SQL> use catalog myhive;
Where show catalogs lists all Catalog instances loaded. It should be noted that in addition to the Catalog configured by the user in the sql-client-defaults.yaml file, FlinkSQL will automatically load a GenericInMemoryCatalog instance as the built-in Catalog, which is named default ﹣ u Catalog by default.
Read write Hive table
After HiveCatalog is set, you can read and write tables in Hive through SQL Client or Table API.
Suppose there is already a table named mytable in Hive, we can use the following SQL statement to read and write this table.
■ read data
Flink SQL> show catalogs; myhive default_catalog Flink SQL> use catalog myhive; Flink SQL> show databases; default Flink SQL> show tables; mytable Flink SQL> describe mytable; root |-- name: name |-- type: STRING |-- name: value |-- type: DOUBLE Flink SQL> SELECT * FROM mytable; name value __________ __________ Tom 4.72 John 8.0 Tom 24.2 Bob. 3.14 Bob 4.72 Tom 34.9 Mary 4.79 Tiff 2.72 Bill 4.33 Mary 77.7
■ write data
Flink SQL> INSERT INTO mytable SELECT 'Tom', 25; Flink SQL> INSERT OVERWRITE mytable SELECT 'Tom', 25; # Static zoning Flink SQL> INSERT OVERWRITE myparttable PARTITION (my_type='type_1', my_date='2019-08-08') SELECT 'Tom', 25; # Dynamic zoning Flink SQL> INSERT OVERWRITE myparttable SELECT 'Tom', 25, 'type_1', '2019-08-08'; # Static and dynamic partitions Flink SQL> INSERT OVERWRITE myparttable PARTITION (my_type='type_1') SELECT 'Tom', 25, '2019-08-08';
summary
In this paper, the author first introduces the architecture design of the integration function of Flink and Hive, then compiles from the source code to solve some problems encountered, then deploys and configures the Flink environment and the specific operation process of integrating Hive, and finally reads and writes the Hive table by referring to the official case.
Later, the author will explain how to operate Hive through Flink SQL based on the actual use of the production environment.