Objective: give a news article and count the most frequent words. Grab a piece of news on the Internet
Analysis: for text vocabulary extraction, Lucene index is used here to extract Top10 of term Frequency. The essence of indexing process is a process of generating inverted index from entry, which will remove punctuation and stop words from the text, and finally generate word items. In the code, we use the getTermVector of IndexReader to get the terms of a field of the document, get the term Frequency from the terms, get the term Frequency of the word item, put it in the map to sort in descending order, and get Top10.
public static void main(String[] args) throws IOException { //News txt location File f = new File("/Users/**/src/main/resources/news/news.txt"); String text = textToString(f); Analyzer analyzer = new IKAnalyzer6x(true); IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer); indexWriterConfig.setOpenMode(IndexWriterConfig.OpenMode.CREATE); Directory directory; IndexWriter indexWriter; directory = FSDirectory.open(Paths.get("indexdir")); indexWriter = new IndexWriter(directory, indexWriterConfig); //New file type, used to specify information when field index FieldType type = new FieldType(); //Index save document, term frequency, location information, offset information type.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS); type.setStored(true); type.setStoreTermVectors(true); type.setTokenized(true); //New document Document doc = new Document(); Field field = new Field("content", text, type); doc.add(field); indexWriter.addDocument(doc); indexWriter.close(); directory.close(); } public static String textToString(File f) { StringBuilder sb = new StringBuilder(); try { BufferedReader br = new BufferedReader(new FileReader(f)); String str; while ((str = br.readLine()) != null) { sb.append(System.lineSeparator() + str); } br.close(); } catch (Exception e) { e.printStackTrace(); } return sb.toString(); }
Use IndexReader to query term frequency.
public static void main(String[] args) throws IOException { IndexReader reader = DirectoryReader.open(FSDirectory.open(Paths.get("indexdir"))); Terms terms = reader.getTermVector(0, "content"); TermsEnum termsEnum = terms.iterator(); Map<String, Integer> map = new HashMap<>(); BytesRef thisTerm; while ((thisTerm = termsEnum.next()) != null) { String termText = thisTerm.utf8ToString(); map.put(termText, (int) termsEnum.totalTermFreq()); } List<Map.Entry<String, Integer>> sortedMap = new ArrayList<>(map.entrySet()); Collections.sort(sortedMap, (o1, o2) -> o2.getValue() - o1.getValue()); for (int i = 0; i < 10; i++) { System.out.println(sortedMap.get(i).getKey() + " : " + sortedMap.get(i).getValue()); } }
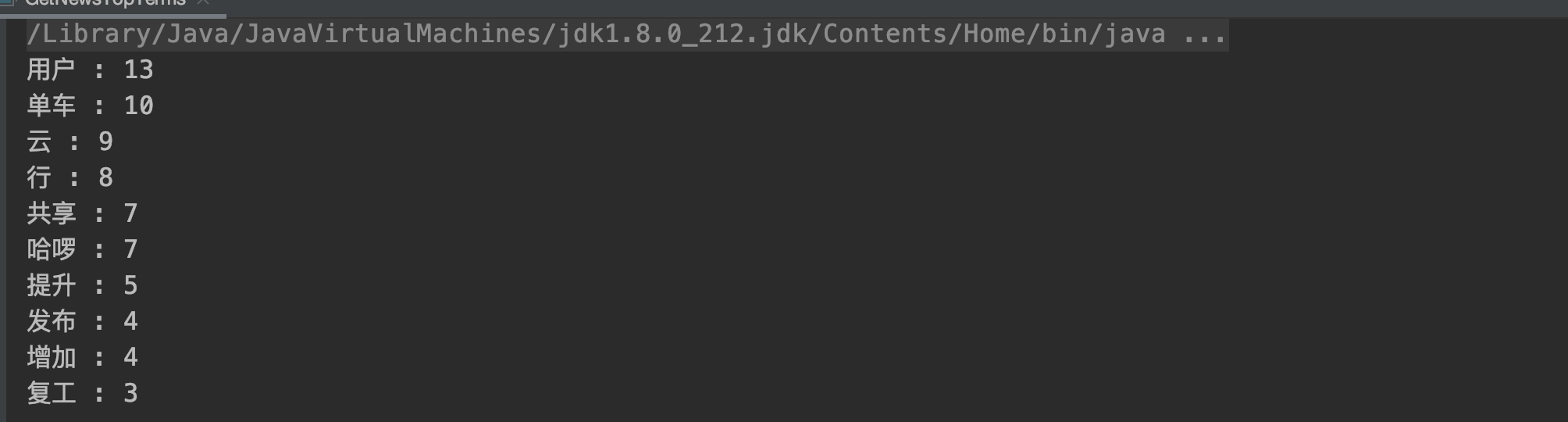
The output results are as follows: