What is heterogeneous data processing? Simply put, in order to satisfy the expansion of our business, data is transformed from a specific format to a new data format.
Why does this need arise?
In traditional enterprises, data are mainly stored in relational databases, such as MySQL, but in order to meet the expansion of demand, the dimension of queries will continue to increase, then we need to do heterogeneous data processing.
What are the common data heterogeneity?
For example, MySQL data is dumped to Redis, MySQL data is dumped to es, and so on. It is also because this heterogeneous data scenario began to appear. Many middleware emerged in the market one after another, such as rocketMq, kafka and canal.
Below is an easy-to-understand data heterogeneity process diagram:
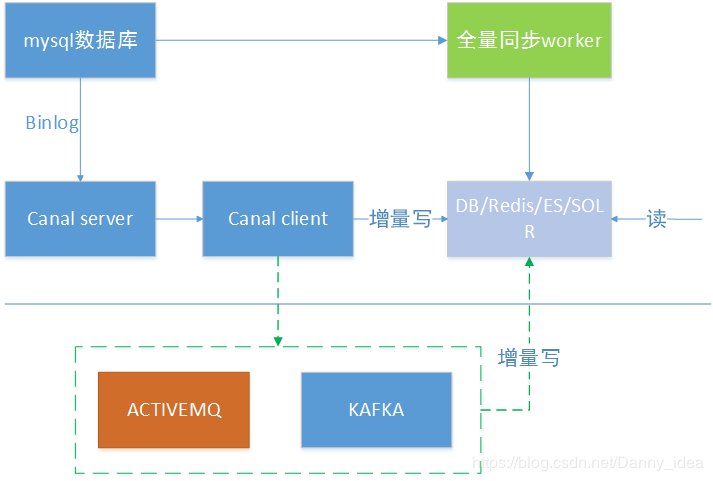 Insert a picture description here
Insert a picture description here
Data synchronization in canal
First, we need to properly open the canal server to subscribe to the binlog log log.
Several commands commonly used for binlog log viewing are as follows:
#Whether logging is enabled mysql>show variables like 'log_bin'; #How to know the current log mysql> show master status; #View mysql binlog mode show variables like 'binlog_format'; #Get a list of binlog files show binary logs; #View the binlog file currently being written show master statusG #View the contents of the specified binlog file show binlog events in 'mysql-bin.000002';
Note that the binlog log log format requires row format:
Characteristics of ROW format log
Recording sql statements and the changes of each field can make clear the change history of each row of data, occupy more space, and do not record sql that has no effect on data, for example, select statements will not record. The mysqlbinlog tool can be used to view internal information.
Log content in STATEMENT mode
The journal in the format of STATEMENT is similar to its own naming. It only records the content of sql separately, but does not record the context information, which may cause data loss when the data meets the UI blessing.
Log content in MIX mode mode
The log content of this mode is more flexible. When the table structure changes, it will be recorded as state mode, and if it encounters data modification, it will become row mode.
How to configure information about canal?
It's relatively simple. First, we download the installation package of canal. Then we need to do some tricks on the configuration file of canal.
canal Of example Below the folder properties file canal.instance.master.address=**.***.***.**:3306 # File name of log canal.instance.master.journal.name=master-96-bin.000009 canal.instance.dbUsername=**** canal.instance.dbPassword=****
Start our canal program, and then look at the log. If you show the contents below, it means that the startup is successful:
2019-10-13 16:00:30.072 [main] ERROR com.alibaba.druid.pool.DruidDataSource - testWhileIdle is true, validationQuery not set 2019-10-13 16:00:30.734 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for 1-example 2019-10-13 16:00:30.783 [main] INFO c.a.otter.canal.instance.core.AbstractCanalInstance - start successful....
ps: There are many online tutorials on introductory installation of canal, so I won't elaborate too much here.
After the canal server is built, we enter the coding part of the program on the java side:
Next, we look at our client code. In the client, we need to get the connection of the canal server through the java program, and then go into the state of listening for the binlog log log.
You can refer to the following program code:
package com.sise.client.simple; import com.alibaba.otter.canal.client.CanalConnector; import com.alibaba.otter.canal.client.CanalConnectors; import com.alibaba.otter.canal.protocol.CanalEntry; import com.alibaba.otter.canal.protocol.Message; import com.google.protobuf.InvalidProtocolBufferException; import com.sise.common.dto.TypeDTO; import com.sise.common.handle.CanalDataHandler; import java.net.InetSocketAddress; import java.util.List; import java.util.stream.Collectors; /** * Simple version of canal listening client * * @author idea * @date 2019/10/12 */ public class SImpleCanalClient { private static String SERVER_ADDRESS = "127.0.0.1"; private static Integer PORT = 11111; private static String DESTINATION = "example"; private static String USERNAME = ""; private static String PASSWORD = ""; public static void main(String[] args) throws InterruptedException { CanalConnector canalConnector = CanalConnectors.newSingleConnector( new InetSocketAddress(SERVER_ADDRESS, PORT), DESTINATION, USERNAME, PASSWORD); canalConnector.connect(); canalConnector.subscribe(".*\..*"); canalConnector.rollback(); for (; ; ) { Message message = canalConnector.getWithoutAck(100); long batchId = message.getId(); if(batchId!=-1){ // System.out.println(message.getEntries()); System.out.println(batchId); printEntity(message.getEntries()); } } } public static void printEntity(List<CanalEntry.Entry> entries){ for (CanalEntry.Entry entry : entries) { if (entry.getEntryType()!=CanalEntry.EntryType.ROWDATA){ continue; } try { CanalEntry.RowChange rowChange=CanalEntry.RowChange.parseFrom(entry.getStoreValue()); for (CanalEntry.RowData rowData : rowChange.getRowDatasList()) { System.out.println(rowChange.getEventType()); switch (rowChange.getEventType()){ //If you want to monitor multiple events, you can add them manually case case INSERT: String tableName = entry.getHeader().getTableName(); //Test selection t_type This table is mapped if ("t_type".equals(tableName)) { TypeDTO typeDTO = CanalDataHandler.convertToBean(rowData.getAfterColumnsList(), TypeDTO.class); System.out.println(typeDTO); } System.out.println("this is INSERT"); break; default: break; } } } catch (InvalidProtocolBufferException e) { e.printStackTrace(); } } } /** * print contents * * @param columns */ private static void printColums(List<CanalEntry.Column> columns){ String line=columns.stream().map(column -> column.getName()+"="+column.getValue()) .collect(Collectors.joining(",")); System.out.println(line); } }
After listening to the log information configured in the example folder of canal locally, the data recorded in the log will be printed and read automatically.
At this time, we still need to do a lot of processing, that is, to transform the hard-hearted data into recognizable objects, and then transfer the objects.
In fact, it is not difficult to link to binlog log log of canal. Then we need to encapsulate the binlog log log uniformly. We need to write a specific processor to convert the content of the log into DTO classes which we commonly use.
The following tool class can be used for reference:
package com.sise.common.handle; import com.alibaba.otter.canal.protocol.CanalEntry; import com.sise.common.dto.CourseDetailDTO; import lombok.extern.slf4j.Slf4j; import java.lang.reflect.Field; import java.util.HashMap; import java.util.List; import java.util.Map; /** * Data processor based on canal * * @author idea * @data 2019/10/13 */ @Slf4j public class CanalDataHandler extends TypeConvertHandler { /** * Resolve binlog records into a bean object * * @param columnList * @param clazz * @param <T> * @return */ public static <T> T convertToBean(List<CanalEntry.Column> columnList, Class<T> clazz) { T bean = null; try { bean = clazz.newInstance(); Field[] fields = clazz.getDeclaredFields(); Field.setAccessible(fields, true); Map<String, Field> fieldMap = new HashMap<>(fields.length); for (Field field : fields) { fieldMap.put(field.getName().toLowerCase(), field); } if (fieldMap.containsKey("serialVersionUID")) { fieldMap.remove("serialVersionUID".toLowerCase()); } System.out.println(fieldMap.toString()); for (CanalEntry.Column column : columnList) { String columnName = column.getName(); String columnValue = column.getValue(); System.out.println(columnName); if (fieldMap.containsKey(columnName)) { //Foundation type cannot be converted Field field = fieldMap.get(columnName); Class<?> type = field.getType(); if(BEAN_FIELD_TYPE.containsKey(type)){ switch (BEAN_FIELD_TYPE.get(type)) { case "Integer": field.set(bean, parseToInteger(columnValue)); break; case "Long": field.set(bean, parseToLong(columnValue)); break; case "Double": field.set(bean, parseToDouble(columnValue)); break; case "String": field.set(bean, columnValue); break; case "java.handle.Date": field.set(bean, parseToDate(columnValue)); break; case "java.sql.Date": field.set(bean, parseToSqlDate(columnValue)); break; case "java.sql.Timestamp": field.set(bean, parseToTimestamp(columnValue)); break; case "java.sql.Time": field.set(bean, parseToSqlTime(columnValue)); break; } }else{ field.set(bean, parseObj(columnValue)); } } } } catch (InstantiationException | IllegalAccessException e) { log.error("[CanalDataHandler]convertToBean,An exception occurred to the initialization object and the object could not be instantiated,Exception is{}", e); } return bean; } public static void main(String[] args) throws IllegalAccessException { CourseDetailDTO courseDetailDTO = new CourseDetailDTO(); Class clazz = courseDetailDTO.getClass(); Field[] fields = clazz.getDeclaredFields(); Field.setAccessible(fields, true); System.out.println(courseDetailDTO); for (Field field : fields) { if ("java.lang.String".equals(field.getType().getName())) { field.set(courseDetailDTO, "name"); } } System.out.println(courseDetailDTO); } /** * Other types of custom processing * * @param source * @return */ public static Object parseObj(String source){ return null; } }
Next is the core processor of canal. The main purpose is to convert binlog into the object of entity class we want. At present, there are eight compatible data types in this class, which are relatively limited. If the reader meets some special data types in the subsequent development, he can add them to map manually.
package com.sise.common.handle; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date; import java.util.HashMap; import java.util.Map; /** * Type Converter * * @author idea * @data 2019/10/13 */ public class TypeConvertHandler { public static final Map<Class, String> BEAN_FIELD_TYPE; static { BEAN_FIELD_TYPE = new HashMap<>(8); BEAN_FIELD_TYPE.put(Integer.class, "Integer"); BEAN_FIELD_TYPE.put(Long.class, "Long"); BEAN_FIELD_TYPE.put(Double.class, "Double"); BEAN_FIELD_TYPE.put(String.class, "String"); BEAN_FIELD_TYPE.put(Date.class, "java.handle.Date"); BEAN_FIELD_TYPE.put(java.sql.Date.class, "java.sql.Date"); BEAN_FIELD_TYPE.put(java.sql.Timestamp.class, "java.sql.Timestamp"); BEAN_FIELD_TYPE.put(java.sql.Time.class, "java.sql.Time"); } protected static final Integer parseToInteger(String source) { if (isSourceNull(source)) { return null; } return Integer.valueOf(source); } protected static final Long parseToLong(String source) { if (isSourceNull(source)) { return null; } return Long.valueOf(source); } protected static final Double parseToDouble(String source) { if (isSourceNull(source)) { return null; } return Double.valueOf(source); } protected static final Date parseToDate(String source) { if (isSourceNull(source)) { return null; } if (source.length() == 10) { source = source + " 00:00:00"; } SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); Date date; try { date = sdf.parse(source); } catch (ParseException e) { return null; } return date; } protected static final java.sql.Date parseToSqlDate(String source) { if (isSourceNull(source)) { return null; } SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd"); java.sql.Date sqlDate; Date utilDate; try { utilDate = sdf.parse(source); } catch (ParseException e) { return null; } sqlDate = new java.sql.Date(utilDate.getTime()); return sqlDate; } protected static final java.sql.Timestamp parseToTimestamp(String source) { if (isSourceNull(source)) { return null; } SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); Date date; java.sql.Timestamp timestamp; try { date = sdf.parse(source); } catch (ParseException e) { return null; } timestamp = new java.sql.Timestamp(date.getTime()); return timestamp; } protected static final java.sql.Time parseToSqlTime(String source) { if (isSourceNull(source)) { return null; } SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss"); Date date; java.sql.Time time; try { date = sdf.parse(source); } catch (ParseException e) { return null; } time = new java.sql.Time(date.getTime()); return time; } private static boolean isSourceNull(String source) { if (source == "" || source == null) { return true; } return false; } }
ps: t_type table is a table we use for testing, where we can customize different entity class objects according to our actual business needs.
Now that we can convert the entity class through binlog, the next step is how to do additional transmission and processing of the entity class. We usually use middleware such as mq to transfer data, and I will do detailed output in subsequent articles about this part.
Recommended reading (click to skip reading)
1.SpringBook content aggregation
2.Content aggregation of interview questions