advantage:
-
If we store a large amount of HBase data at one time, the processing speed is slow, and the Region resources are particularly occupied, a more efficient and convenient method is to use the "Bulk Loading" method, that is, the HFileOutputFormat class provided by HBase.
-
It uses the principle that hbase data information is stored in hdfs according to a specific format, directly generates the data format file stored in hdfs, and then uploads it to the appropriate location, that is, it completes the rapid warehousing of a large amount of data. It is completed with mapreduce, which is efficient and convenient, does not occupy region resources and adds load.
Limitations:
-
It is only applicable to the initial data import, that is, the data in the table is empty or there is no data in the table every time.
-
HBase cluster and Hadoop cluster are the same cluster, that is, HDFS based on HBase is the cluster that generates MR of HFile
The main principle of Bulk Loading method is to make use of the characteristics that the data in HBase will eventually be stored on hdfs in the form of HFile, bypass the original process of HBase using put to write data, directly write the data into hdfs in the form of HFile, and then let HBase load HFile files, so as to complete the one-time storage of a large amount of data in HBase. The classes that specifically implement Bulk Loading are the HFileOutputFormat class and LoadIncrementalHFiles class provided by HBase
The main steps are divided into two steps. The first step is to generate HFile files in hdfs (with the help of HFileOutputFormat class). The second step is to load the generated HFile files into the Region of HBase, that is, the HFile files are stored in HBase (with the help of LoadIncrementalHFiles class)
It should be noted that the HFile file is generated by MapReduce task at the beginning and stored in hdfs. The HFile of HBase is also stored in hdfs. However, the HFile file generated by MapReduce cannot be directly moved to the HBase directory, because the metadata of HBase will not be updated. Therefore, the doBulkLoad method of LoadIncrementalHFiles needs to be used to complete the warehousing of HFile files into HBase
Take a look at the instructions for the HFileOutputFormat class

-
Sets the number of reduce tasks to match the current number of regions
The bottom layer of Bulk Loading calls MapReduce tasks, so this sentence means that the number of set reduce tasks should be the same as the number of region s of the table to be written -
Sets the output key/value class to match HFileOutputFormat2's requirements
Set the appropriate key and value types for the output -
Sets the reducer up to perform the appropriate sorting (either KeyValueSortReducer or PutSortReducer)
Set reasonable sorting. For reduce, the data in reduce should be in order
job.setPartitionerClass(SimpleTotalOrderPartitioner.class); Ensure that the reduction is orderly and the data will not overlap
job.setReducerClass(KeyValueSortReducer.class); Ensure the internal order of reduce
Two sorting classes, KeyValueSortReducer or PutSortReducer, are given in the introduction of class. Select which class to use according to your own code -
The user should be sure to set the mapy output value class to either KeyValue or Put before runningthis function.
The value data type of Map output should be KeyValue type or Put type
Set the appropriate output key and value types. Because Bulk Loading reads data from hdfs, mapper's input key and value types are LongWritable and Text. Mapper's output key and value are different from before. The output key should be of rowkey type, that is, immutablebytesworitable type, and the output value can be of KeyValue type or Put type.
The output key is of rowkey type to facilitate sorting and partitioning, because the data output by MapTask will be sent to the reduce end after the partition sorting process. In order to ensure that the data processed by the reduce end cannot be repeated and orderly, rowkey is used as the output key of Mapper
Assuming that the table to be written has three region s in total, there should be three reductions, and the data processed by these three reductions should be rowkey0-10, rowkey11-20 and rowkey21-30, so as to ensure that the data processed by each reduction will not be the same.
For the output value, the meaning of KeyValue type is the value of a cell, and the meaning of Put type is the value of a piece of data. Select different output types as needed.
Specific implementation:
package Demo.hbase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.hbase.mapreduce.KeyValueSortReducer;
import org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles;
import org.apache.hadoop.hbase.mapreduce.SimpleTotalOrderPartitioner;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class bulkLoad {
public static class BulkLoadMapper extends Mapper<LongWritable,Text,ImmutableBytesWritable,KeyValue>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split(",");
String mdn = split[0];
String start_time = split[1];
//longitude
String longitude = split[4];
//latitude
String latitude = split[5];
//Set the rowkey value to be written to the table
String rowkey = mdn+"_"+start_time;
//Set the value of longitude and latitude to be written into the table, because KeyValue is the value of cell
//Therefore, a cell is determined in the form of rowkey + column cluster + column name, and then the value in the specific cell is passed in
KeyValue lgKV = new KeyValue(rowkey.getBytes(),"info".getBytes(),"lg".getBytes(),longitude.getBytes());
KeyValue latKV = new KeyValue(rowkey.getBytes(),"info".getBytes(),"lat".getBytes(),latitude.getBytes());
context.write(new ImmutableBytesWritable(rowkey.getBytes()),latKV);
context.write(new ImmutableBytesWritable(rowkey.getBytes()),latKV);
}
}
//Because there is no calculation requirement here, the code of Reducer can be omitted
//Driver end
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","master:2181,node1:2181,node2:2181");
Job job = Job.getInstance(conf);
job.setJobName("bulkLoad");
job.setJarByClass(bulkLoad.class);
//At this time, the number of reduce cannot be set on the Driver side, because the number of reduce is consistent with the number of region s in the table
//Even if the setting statement is written here, it will not take effect
//Configure Map
job.setMapperClass(BulkLoadMapper.class);
job.setOutputKeyClass(ImmutableBytesWritable.class);
job.setOutputValueClass(KeyValue.class);
//Ensure that the data processed by different reduce will not overlap, and that the reduction is orderly
job.setPartitionerClass(SimpleTotalOrderPartitioner.class);
//Configure reduce
//Ensure that the data in Reduce is orderly
job.setReducerClass(KeyValueSortReducer.class);
//Configure I / O path
FileInputFormat.addInputPath(job,new Path("/bulk_load/input"));
Path outputPath = new Path("/bulk_load/output");
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);
}
FileOutputFormat.setOutputPath(job,outputPath);
//Generation and loading of configuration Hfile Hbase
Connection conn = ConnectionFactory.createConnection(conf);
Admin admin = conn.getAdmin();
Table dianxin_bulk = conn.getTable(TableName.valueOf("dianxin_bulk"));
//Get RegionLocator object
//Because different HFile files belong to different regions, the RegionLocator object is used to tell which region the HFile file should go to
RegionLocator regionLocator = conn.getRegionLocator(TableName.valueOf("dianxin_bulk"));
//The first step is to generate HFile
// Use HFileOutputFormat2 to format the output data into a HFile file
//This method needs to pass in three parameters: job, table name and RegionLocator object
HFileOutputFormat2.configureIncrementalLoad(
job,
dianxin_bulk,
regionLocator
);
//Wait until the HFile file in the first step is written, because the MapReduce task is called to generate the HFile file
//Therefore, in the second step of loading data, the HFile file should be loaded after job.waitforcompletement, that is, after the task is completed
boolean flag = job.waitForCompletion(true);
if(flag){
//Step 2: load HFile into HBase
LoadIncrementalHFiles load = new LoadIncrementalHFiles(conf);
//The parameters that need to be passed into the method are output path, Admin object, table name and RegionLocator object
load.doBulkLoad(
outputPath,
admin,
dianxin_bulk,
regionLocator
);
}else{
System.out.println("MapReduce The task failed to run");
}
}
}
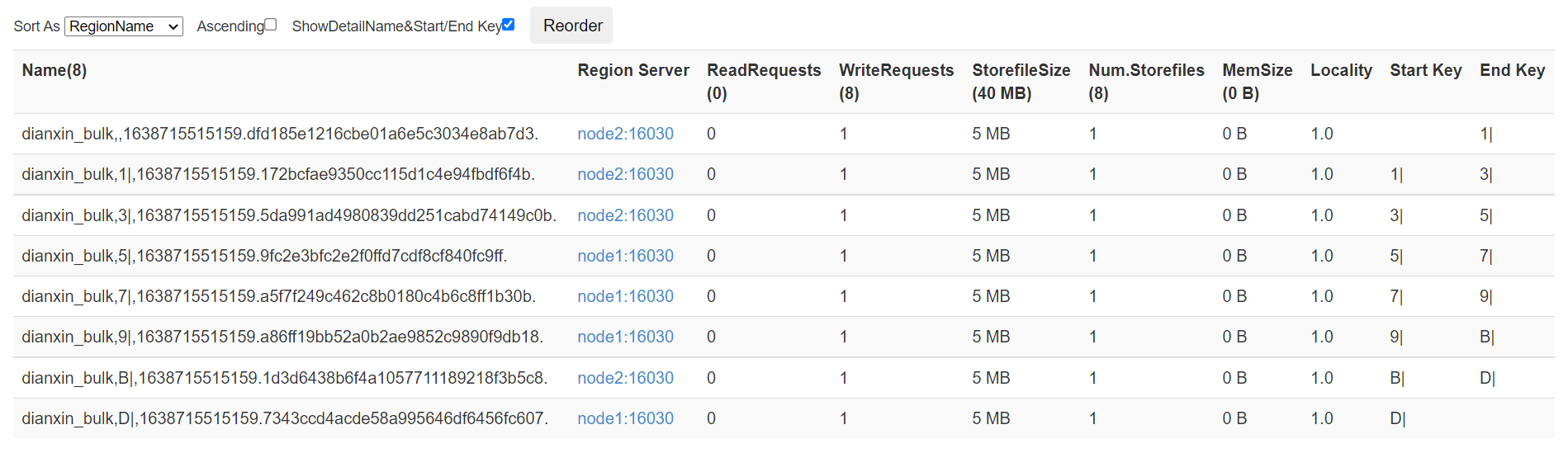
Before executing the program, create a pre partitioned table in HBase
hbase(main):001:0> create 'dianxin_bulk','info',{SPLITS=>['1|','3|','5|','7|','9|','B|','D|']}
0 row(s) in 5.4560 seconds
=> Hbase::Table - dianxin_bulk
Then create the input file in hdfs and pass the dataset into the input folder
hdfs dfs -mkdir -p /bulk_load/input hdfs dfs -put /usr/local/data/DIANXIN.csv /bulk_load/input
Then package the project file and transfer it to linux
Run the specified program in the jar package
hadoop jar hdfs-1.0-SNAPSHOT-jar-with-dependencies.jar Demo.hbase.bulkLoad
After the program runs, go to the visualization page to check it