Article directory
- Introduction to HBase
- HBase introduction
- HBase
- HBase architecture
- RegionServer cluster structure
- HBase logical storage structure
- HBase physical storage structure
- HBase installation
- HBase command
- HBase command introduction
- HBase Shell command introduction
- status command
- namespace related commands
- introduce
- Create? Namespace command
- Drop? Namespace command
- Describe? Namespace command
- List? Namespace command
- list command
- Create hbase user table
- Delete user table
- put command
- get command
- scan command
- Scan filter related commands
- scan other parameters
- count command
- delete command
- truncate command
- describe command
- Java client
- Java client programming
Introduction to HBase
HBase introduction
- HBase is an open-source product of google bigtable, which is built on hdfs to provide high reliability, high performance, column storage, scalability, real-time read-write database system.
- It is a database system between nosql and RDBMs, which only supports data retrieval through rowkey and range, mainly stores unstructured data and semi-structured data.
- Like Hadoop, HBase aims to increase storage performance and computing performance by expanding horizontally and adding ordinary machines.
- HBase features: large (a table can have hundreds of millions of rows and millions of rows), row oriented storage, sparse (because null does not occupy storage space, all table results can be designed very sparse).
HBase
- HBase uses Zookeeper for cluster node management. Of course, HBase integrates a ZK system, but it is generally not used in the actual production environment.
- HBase consists of two types of nodes: master and regionserver (if the zk service of HBase is used, there is also the HQuorumPeer process).
- Hbase supports the provision of master backup. The master node is responsible for communicating with zk and storing the location information of region server. The region server node implements the specific operation of data, and the final data is stored on hdfs.
HBase architecture
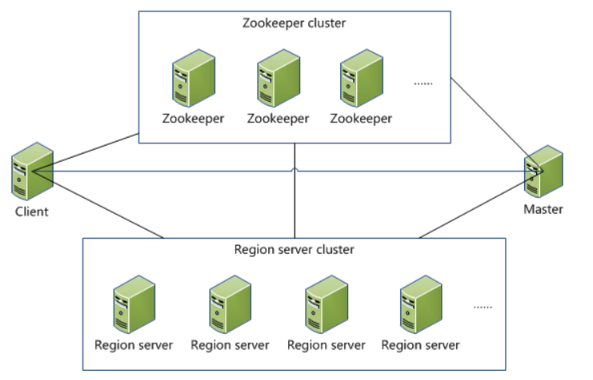
RegionServer cluster structure
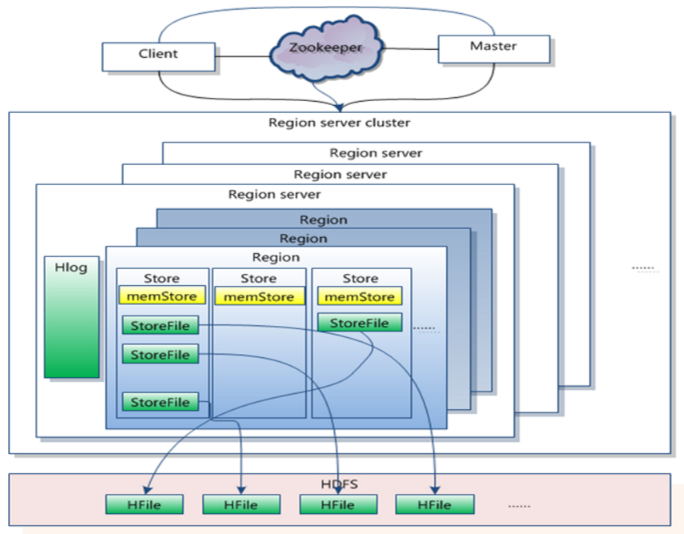
HBase logical storage structure
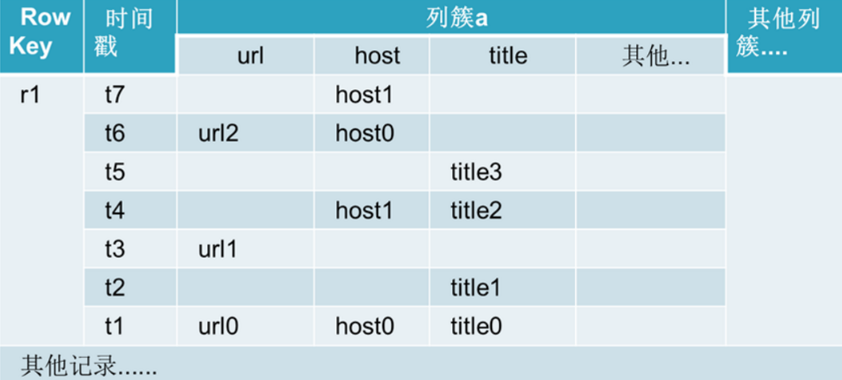
HBase physical storage structure
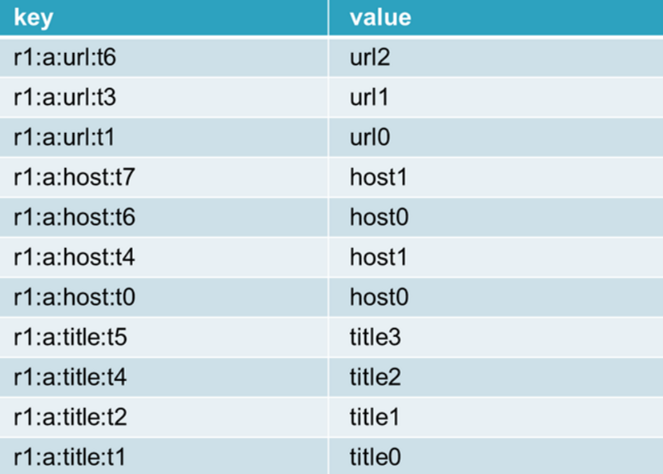
key: rowkey: column cluster: column name: timestamp
HBase installation
preparation in advance
- HBase can be installed in three ways: the first is independent mode, the second is distributed mode (integrated zookeeper), and the third is distributed mode (independent zookeeper).
- Installation steps:
- Install jdk, at least 1.6 (except version u18).
- Install ssh password free login.
- Modify hostname and hosts, hbase obtains ip address through hostname.
- Hadoop installation.
- Generate environment cluster (dfs.datanode.max.xcievers of NTP + ulimit & nproc + HDFS)
- hbase download and installation
HBase installation steps
- Download HBase, select version hbase-0.98.6-cdh5.3.6, and download at http://archive.cloudera.com/cdh5/cdh/5/.
- Extract the package to the directory / home / Hadoop / bigdata /.
- Create a folder hbase in the root directory of hbase to store temporary files, pid, etc. Default / tmp.
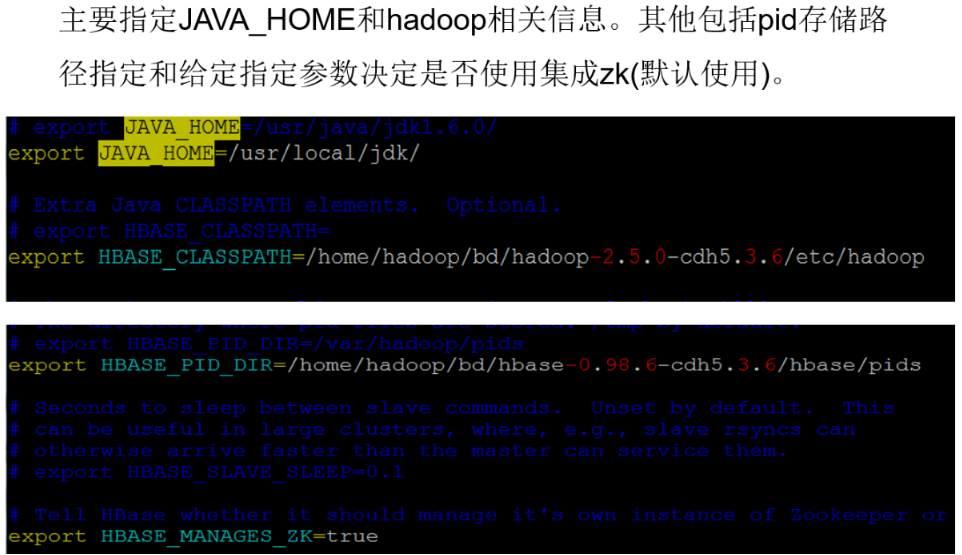
- Modify the configuration information hbase.home/conf/hbase − site.xml and {hbase.home}/conf/hbase-site.xml and HBase. Home / conf / HBase − site.xml and {HBase. Home} / conf / HBase env.sh files.
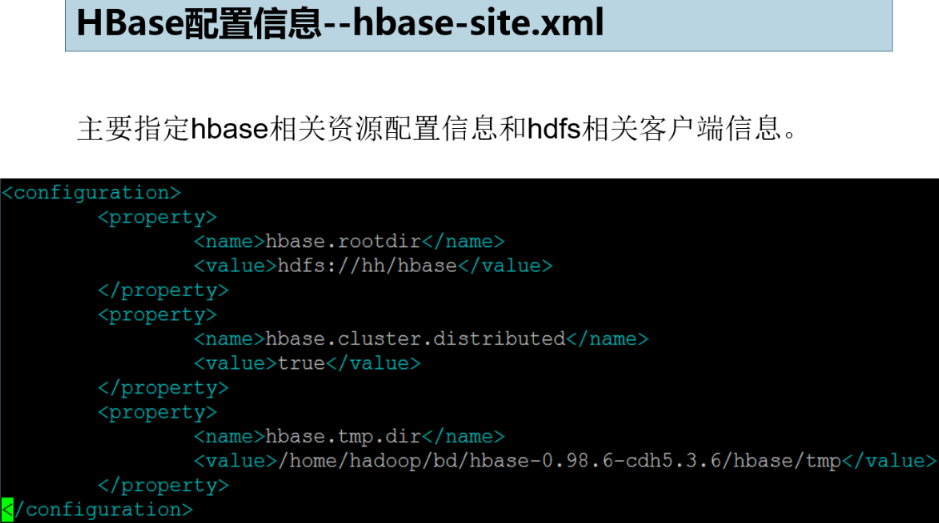
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://oda.com/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.tmp.dir</name> <value>/home/jlu/bd/hbase-0.98.6-cdh5.3.6/hbase/tmp</value> </property> </configuration>
-
Specify the region server node hostname, and modify the file region servers.
-
Create a soft connection to hdfs-site.xml or configure the configuration information of the connection HDFS (recommended).
-
Add hbase related information to the environment variable (vi ~/.bash_profile).

-
Start hbase cluster and verify.
Hbase boot
- Start cluster command: start-hbase.sh
- Stop cluster command: stop hbase.sh
- Separate start / stop process command: (separate start master or regionserver)
hbase-daemon.sh (start|stop) (master|regionserver|zookeeper)
hbase-daemons.sh (start|stop) (regionserver|zookeeper)
HBase verification
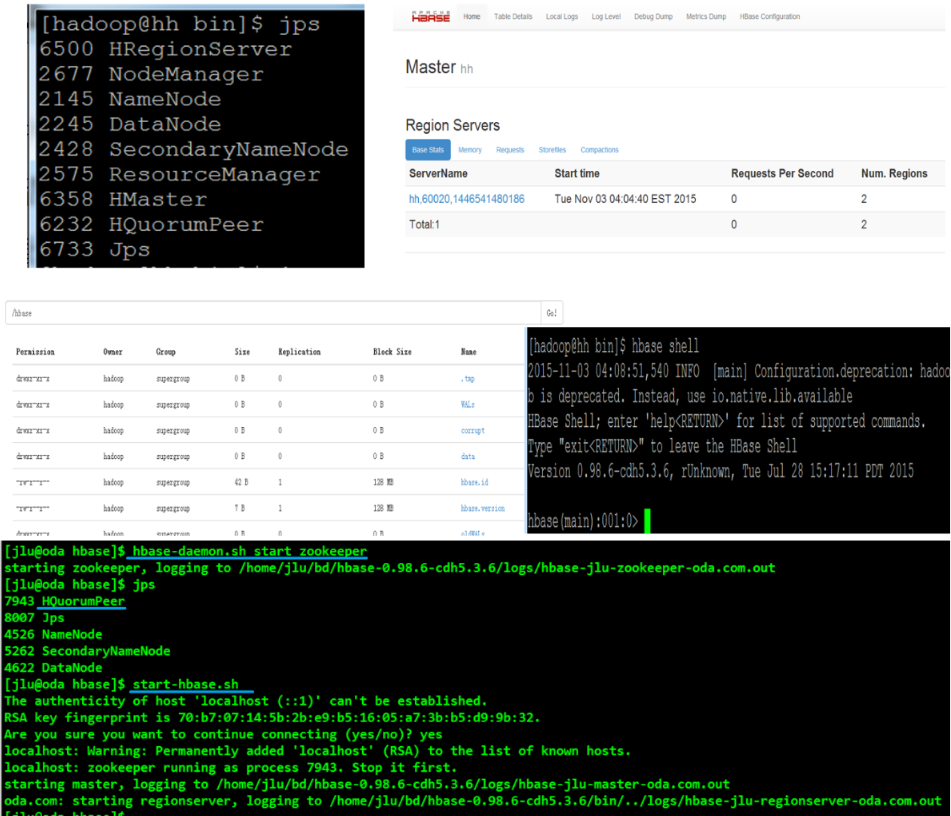
There are four ways to verify:
- jsp to see if hbase is started normally.
- The web interface looks to see if it started successfully. http://192.168.162.121:60010/
- The shell command client checks to see if it started successfully.
- Check whether hbase is installed successfully and whether there is a hbase folder under the hdfs file.
Backup master
- If you need to use hbase's multi master structure, you need to add the backup masters file in the conf folder, and then a host name line by line, which is the same as region servers;
- Or add the HBase ﹣ backup ﹣ masters variable in hbase-env.sh, and the corresponding value is the backup masters storage path (the same as the startup command).
HBase command
HBase command introduction
- HBase commands are mainly divided into two categories,
- The first type refers to shell commands related to hbase table operation;
- The second is the command to provide other related services of hbase.
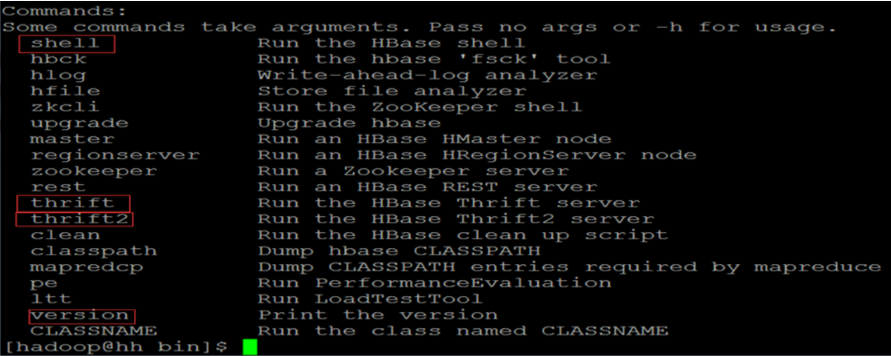
- The first type of commands are all in the * * * hbase** shell commands, so the second type of commands are mainly services such as thrift/thrift2 * *.
HBase Shell command introduction
- The Shell commands of HBase are written with JRuby as the core, which are mainly divided into two categories: DDL and DML. In addition to these two categories, there are other commands related to operation and maintenance, such as snapshots.
- When we enter hbase's shell command client, we can view help information through help command, or view the usage of specific commands through help command.
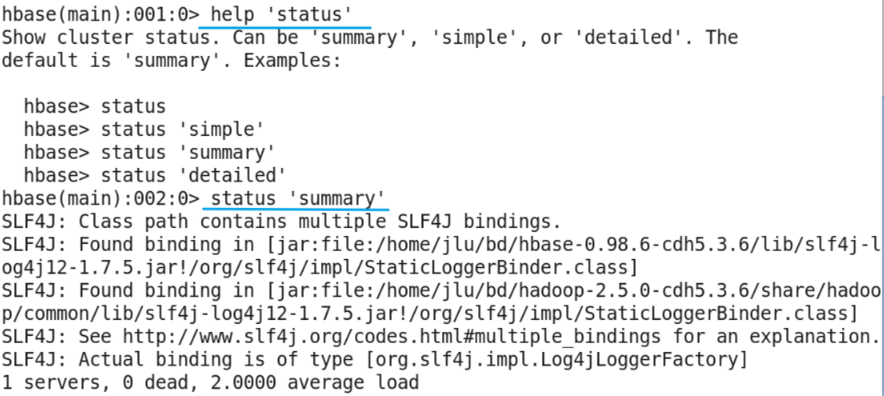
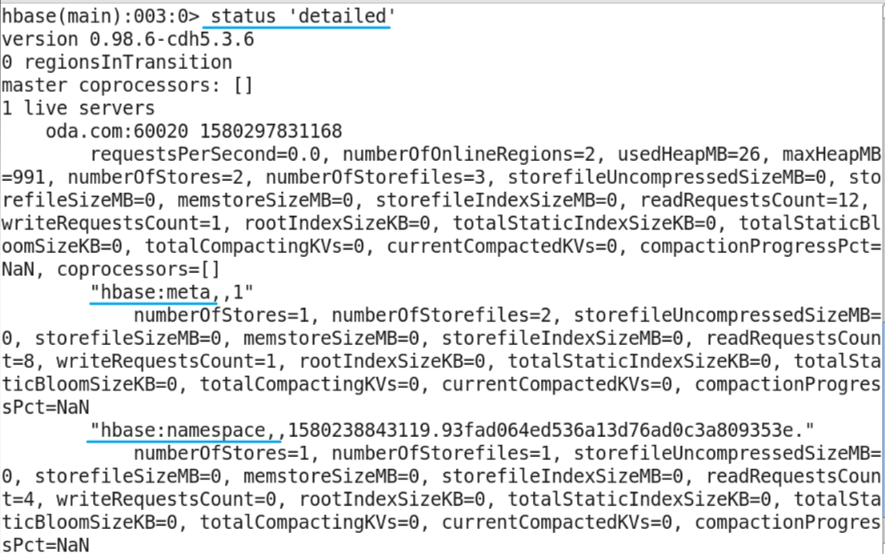
status command
- Function: view hbase cluster status information.
- Parameters: simple, summary, detailed; the default is summary.
namespace related commands
introduce
- Function: similar to database in relational database, the function is to separate HBase tables according to business functions, which is beneficial to maintenance. HBase has two namespaces by default, HBase and default. The HBase namespace stores the table information of HBase itself, and the default stores the tables created by users.
- Order:
- Create? Namespace,
- Alter? Namespace (namespace modification),
- Show namespace description,
- Drop? Namespace (delete a namespace if it is empty),
- List? Namespace (show all namespaces),
- List > namespace > tables (shown for table names in the namespace).
Create? Namespace command
- Role: creates a namespace.
- Example: create [namespace 'bigrater', {'comment' = > 'this is our namespace', 'keyname' = > 'valuename'}

Drop? Namespace command
- Function: delete the specified namespace; note that table cannot exist in the deleted namespace, that is, only empty namespace can be deleted.
- Example: drop [namespace 'bigrater'

Describe? Namespace command
- Function: displays information about the namespace.
- Example: describe [namespace 'bigrater'

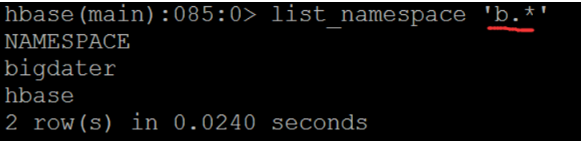
List? Namespace command
- Function: display all existing namespaces.
- Example: list \ u namespace or list \ u namespace 'regex \ u STR'
list command
- Function: display hbase table name, similar to show tables in mysql;
- You can view the tables in the corresponding namespace by specifying the namespace. By default, all user tables are displayed, and fuzzy matching is also supported. Similar to the command list > namespace > tables, view the tables in the corresponding namespace.
Create hbase user table
- Command format: create '[namespace'u Name:] table'u name', 'family'u name'u 1' "Family" name "(" family "name" = column cluster name)
- If the name of the namespace is not given, it is created in the default namespace by default.
- Example: create 'bigger: Test', 'f'

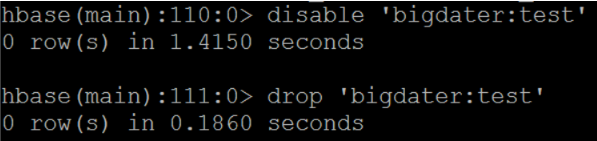
Delete user table
- You need to set the table to disable before deleting the user table.
- In fact, in hbase, if you need to ddl an existing table, you need to disable it. After the ddl operation is completed, you need to enable it.
- Command format:
- disable '[namespace_name:]table_name'
- drop '[namespace_name:]table_name'
- Example:
- disable 'bigdater:test'
- drop 'bigdater:test'
- Command format:
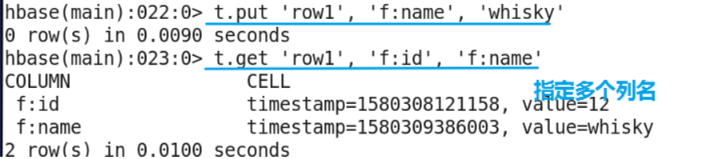
put command
- Create the users table in the default namespace, and then operate on the basis of this table. The put command of hbase is a command to add data.
Command format:
put '[namespace_name:]table_name', 'rowkey', 'family:[column]', 'value' [, timestamp] [, {ATTRIBUTES=>{'mykey'=>'myvalue'}, VISIBILITY=>'PRIVATE|SECRET'}]
Examples: put 'users',' row1 ',' f:id ',' 1 '

HBase shell uses Api of Java
Table assign to temporary variable

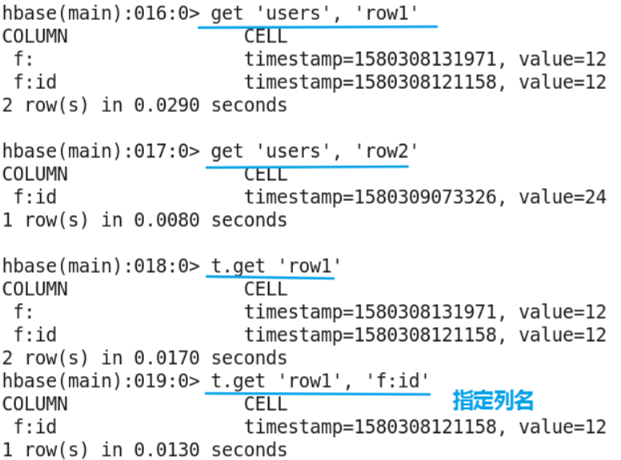
get command
- The get command is used to get the data of the corresponding rowkey in the corresponding table. By default, all the column data of the latest version is obtained. You can specify the version information through time stamp or the obtained column.
- Command format:
get '[namespace_name:]table_name', 'rowkey' - Example: get 'users',' row1 '
scan command
- scan command is another search method of hbase, which is to find the data in hbase by range. By default, all the data in table can be obtained. You can filter the data by specifying column, filter and other related information.
- Command format:
scan '[namespace_name:]table_name' - Example: scan 'users'
Scan filter related commands
-
scan provides a variety of filter commands. Common filter commands are as follows: ColumnPrefixFilter, MultipleColumnPrefixFilter, RowFilter, SingleColumnValueFilter, SingleColumnValueExcludeFilter, etc.
-
It should be noted that 'binary:' should be added before the specified value, for example: scan 'users',' filter = > "SingleColumnValueFilter('f ',' id ',' binary:1)"}
-
Multiple column prefixfilter matches multiple column prefixes
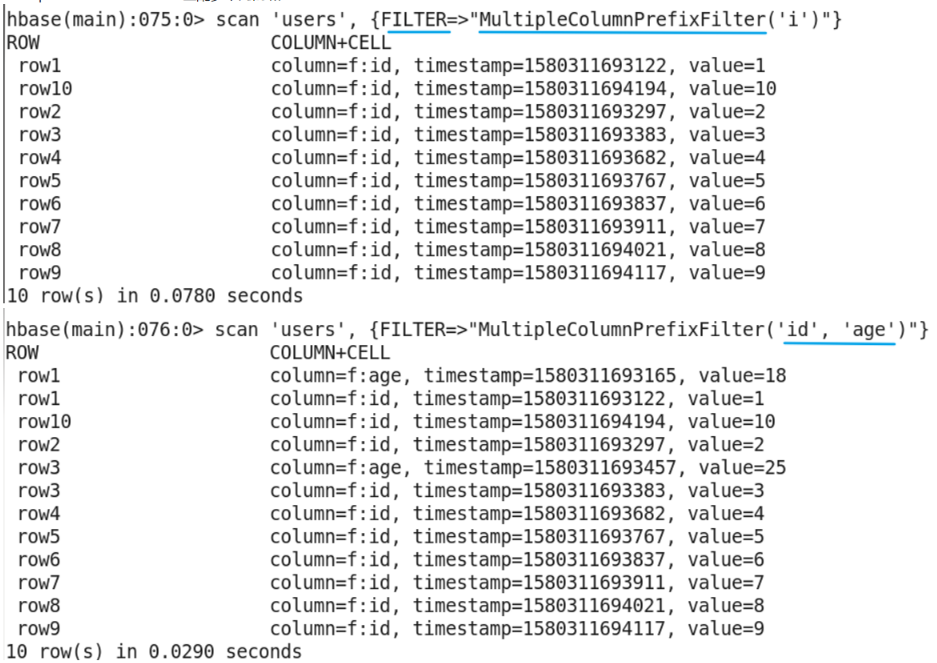
-
RowFilter requires two parameters
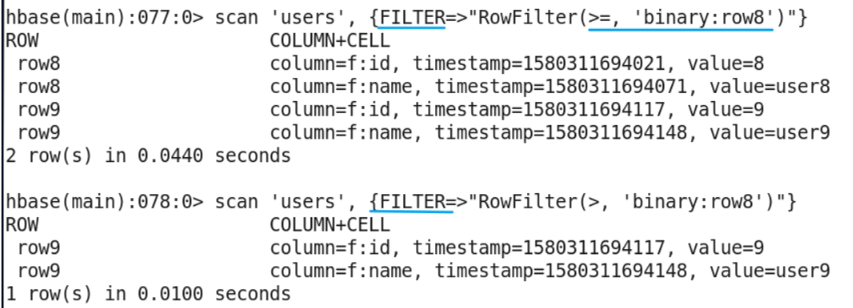
-
SingleColumnValueFilter is most commonly used and requires many parameters. In the figure, because the id stores the string type, it is compared and filtered in dictionary order

-
Combination of multiple filter conditions
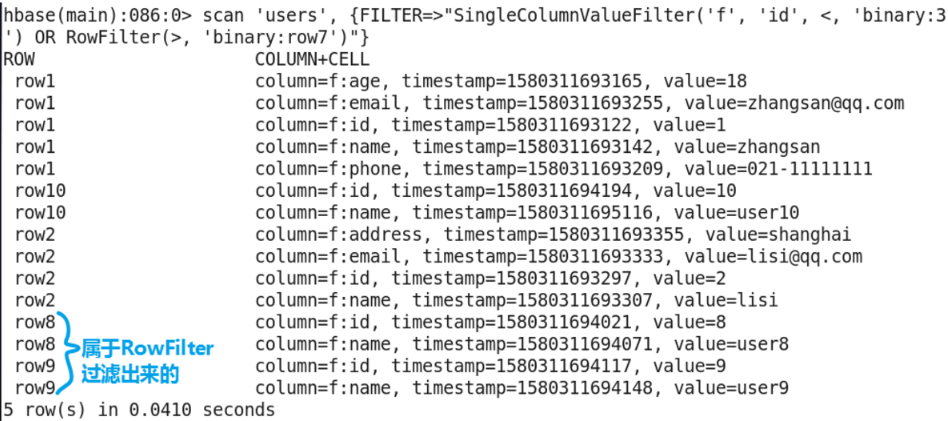
scan other parameters
- In addition to using filter, the scan command can also define the column s we need, the rowkey to start scanning, the rowkey to end scanning, and obtain the number of rows and other information.
- eg:
- scan 'users', {COLUMN=>['f:id','f:name']}
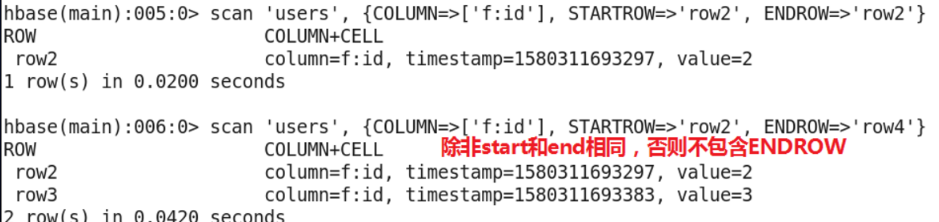
- scan 'users', {STARTROW=>'row1',ENDROW=>'row2'}
- scan 'users', {LIMIT=>1}
- Limit output to three records (all records at the beginning of row1 belong to one)
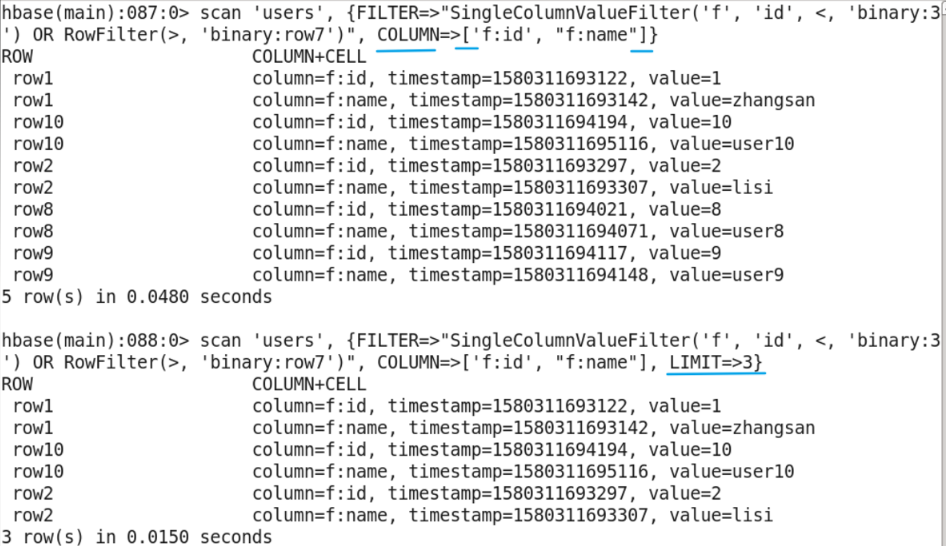
- Specify start rowkey and limit output to three records
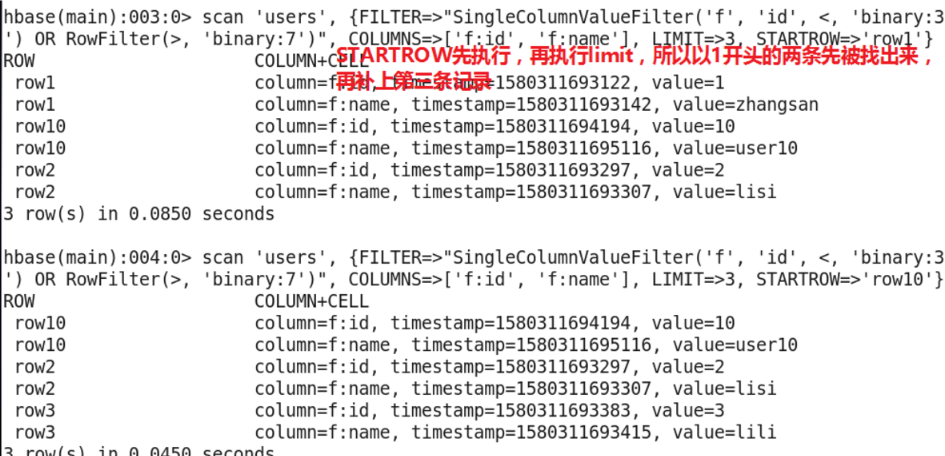
- STARTROW and ENDROW
count command
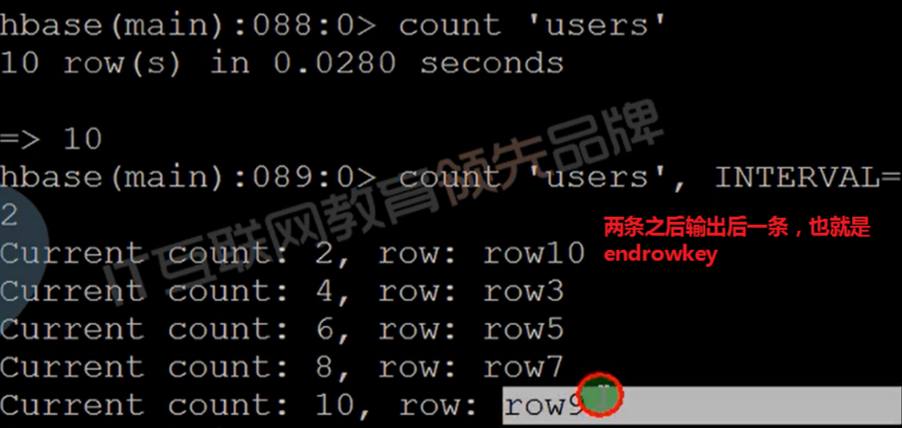
- Count is a command to count the number of rows in hbase table. Because it is equivalent to a built-in mapreduce program, you can choose to use coprocessor to calculate the number of rows when the data volume is large.
- Command format:
- count '[namespace:]table_name' [INTERVAL => 1000,] [CACHE => 10]
- By default, INTERVAL is 1000 (number of intervals), and CACHE is 10.
delete command
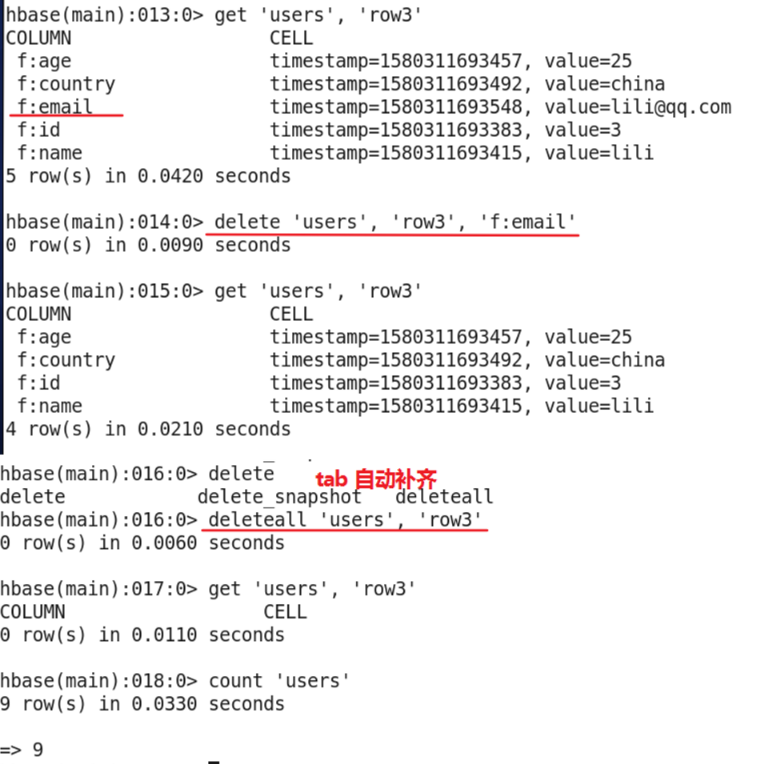
- The delete command is to delete the specified column of the specified rowkey of the specified table, that is to say, the delete command is suitable for deleting columns.
- Command format:
- delete '[namespace:]table_name', 'rowkey', 'family:column'
- If you need to delete all the rowkey column data, you can use the delete all command.
truncate command
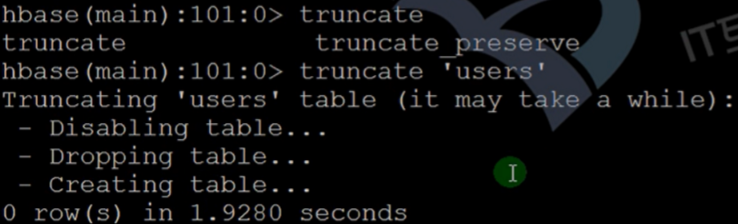
- The truncate command is used to clear the database. When there is more data in our database, we can choose this command to clear the database.
- Command format: truncate '[namespace'name:] table'name'
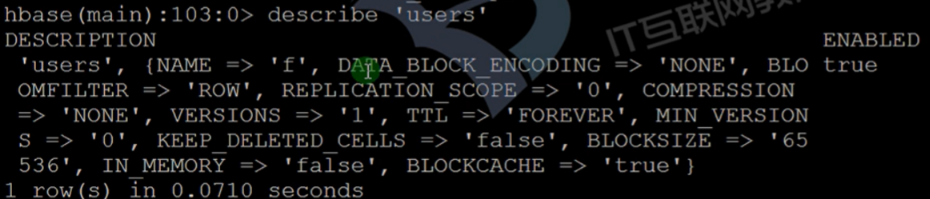
describe command
- View description information
- You can also view it directly through the web interface
Java client
Java client
Java client is actually an implementation of shell client. Operation command is basically a mapping of shell client command. The configuration information used by the Java client is mapped to an instance object of HBaseConfiguration. When the instance object is created using the create method of this class, the hbase-site.xml file will be obtained from the classpath path, and the content of the configuration file will be read. At the same time, the configuration file information of hadoop will be read. The command information can also be specified by java code, only the environment variable information of zk needs to be given. The code is as follows:
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "hh1,hh2.."); // The second parameter is the host name
HBaseAdmin
HBaseAdmin class is an interface class related to DDL operation, mainly including namespace management and user table management. Through this interface, we can create, delete and get user tables, and also can split and compact user tables.
HTable,HTableDescriptor
HTable is a mapped java instance of user table in hbase. We can use this class to operate table data, including data addition, deletion, query and modification. That is to say, we can operate data like put, get and scan in shell.
HTableDescriptor is the specific description information class of hbase user table. Generally, we create a table to obtain (given) table information through this class.
Put,Get,Scan,Delete
- The Put class is a class that specifically provides insert data.
- The Get class is a class that provides data acquisition based on rowkey.
- Scan is a class that specializes in scope lookup.
- Delete is a special class for deletion.
HBase connection pool
in web applications, if we use HTable to operate HBase, we will waste resources when creating and closing connections. Then HBase provides the foundation of a connection pool, mainly involving four classes and interfaces: HConnection, HConnectionManager, HTableInterface, and ExecutorService.
- HConnection is the hbase connection pool encapsulated by hbase,
- HConnectionManager is a class for managing connection pools,
- HTableInterface is an interface abstraction based on HTable class,
- ExecutorService is the thread pool object of the jdk.
Java client programming
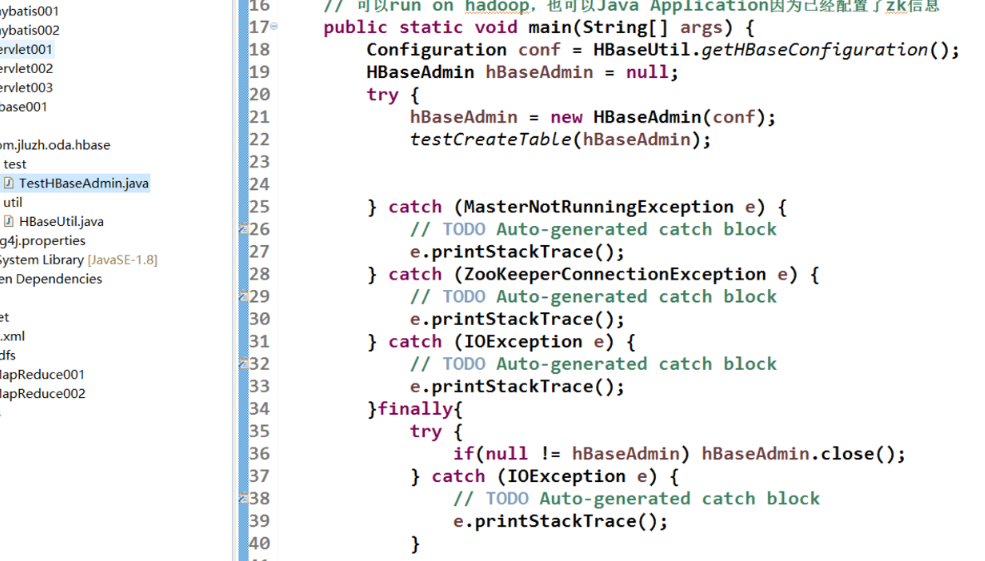
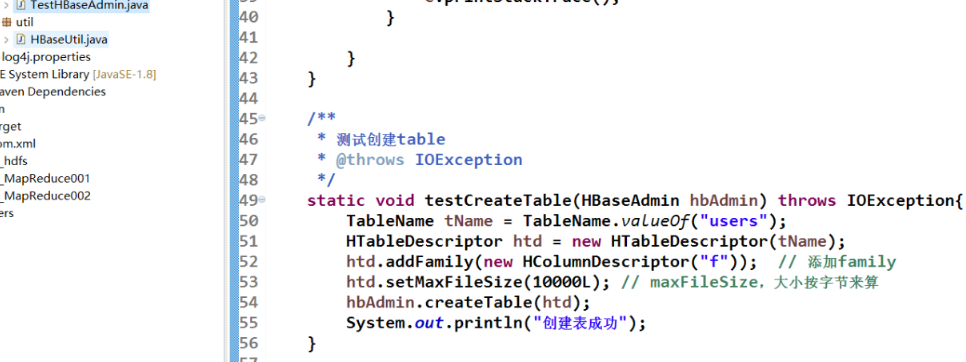
Detailed introduction to HBaseAdmin class
- Test creation table

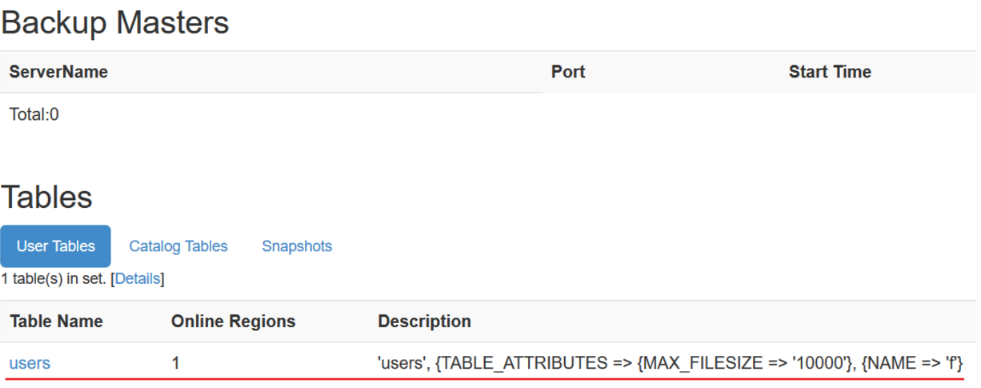 -Get table information and delete table
-Get table information and delete table
HTable class and connection pool
package com.jluzh.oda.hbase.test;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.NavigableMap;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HConnection;
import org.apache.hadoop.hbase.client.HConnectionManager;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.HTableInterface;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.FilterList.Operator;
import org.apache.hadoop.hbase.filter.MultipleColumnPrefixFilter;
import org.apache.hadoop.hbase.util.Bytes;
import com.jluzh.oda.hbase.util.HBaseUtil;
public class TestHTable {
static byte[] family = Bytes.toBytes("f");
public static void main(String[] args) {
Configuration conf = HBaseUtil.getHBaseConfiguration();
try {
// testUseHTable(conf);
testUseHbaseConnectionPool(conf);
} catch (IOException e) {
e.printStackTrace();
}
}
// Centralized call test method
static void testUseHTable(Configuration conf) throws IOException {
HTable hTable = new HTable(conf, "users");
try {
// testPut(hTable);
// testGet(hTable);
// testDelete(hTable);
testScan(hTable); // Parameter is a class instance that implements the interface
} finally {
hTable.close();
}
}
// Better to use thread pool
static void testUseHbaseConnectionPool(Configuration conf) throws IOException {
ExecutorService threads = Executors.newFixedThreadPool(10); // 10 threads
HConnection pool = HConnectionManager.createConnection(conf, threads);
HTableInterface hTable = pool.getTable("users");
try {
// testPut(hTable); / / parameter is the class instance that implements the interface
// testGet(hTable);
// testDelete(hTable);
testScan(hTable);
} finally {
hTable.close(); // Every time htable is closed, it is actually put into the pool
pool.close(); // Close at the end
}
}
/**
* Test scan
*
* @param hTable;Interface
* @throws IOException
*/
static void testScan(HTableInterface hTable) throws IOException{
Scan scan = new Scan();
// Add start row key
scan.setStartRow(Bytes.toBytes("row1"));
scan.setStopRow(Bytes.toBytes("row5"));
// An ordered list of filters evaluated with the specified Boolean operator
FilterList list = new FilterList(Operator.MUST_PASS_ALL); // Equivalent to AND
byte[][] prefixes = new byte[2][]; // Filter prefix
prefixes[0] = Bytes.toBytes("id");
prefixes[1] = Bytes.toBytes("name");
// Create multiple column prefix filter instances
MultipleColumnPrefixFilter mcpf = new MultipleColumnPrefixFilter(prefixes);
list.addFilter(mcpf); // Add filter
scan.setFilter(list); // scan operation set filter
// Returns a scanner on the current table as specified
// by the {@link Scan} object.
ResultScanner rs = hTable.getScanner(scan);
Iterator<Result> iter = rs.iterator();
while (iter.hasNext()) {
// Single row result of a {@link Get} or {@link Scan} query.
Result result = iter.next();
printResult(result);
}
}
/**
* Print result object
*
* @param result
*/
static void printResult(Result result) {
System.out.println("*********************" + Bytes.toString(result.getRow())); // Get rowkey
//
// getMap(): maps a family to all versions of its qualifiers and values.
NavigableMap<byte[], NavigableMap<byte[], NavigableMap<Long, byte[]>>> map = result.getMap();
// Traversing map
for (Map.Entry<byte[], NavigableMap<byte[], NavigableMap<Long, byte[]>>> entry : map.entrySet()) {
String family = Bytes.toString(entry.getKey()); // Get family
for (Map.Entry<byte[], NavigableMap<Long, byte[]>> columnEntry : entry.getValue().entrySet()) {
String column = Bytes.toString(columnEntry.getKey()); // Get column
String value = "";
if ("age".equals(column)) {
value = "" + Bytes.toInt(columnEntry.getValue().firstEntry().getValue());
} else {
value = Bytes.toString(columnEntry.getValue().firstEntry().getValue());
}
System.out.println(family + ":" + column + ":" + value);
}
}
}
/**
* Test put operation
*
* @param hTable
* @throws IOException
*/
static void testPut(HTableInterface hTable) throws IOException {
// Single put
Put put = new Put(Bytes.toBytes("row1"));
put.add(Bytes.toBytes("f"), Bytes.toBytes("id"), Bytes.toBytes("11"));
put.add(Bytes.toBytes("f"), Bytes.toBytes("name"), Bytes.toBytes("zhangsan"));
put.add(Bytes.toBytes("f"), Bytes.toBytes("age"), Bytes.toBytes(27));
put.add(Bytes.toBytes("f"), Bytes.toBytes("phone"), Bytes.toBytes("021-11111111"));
put.add(Bytes.toBytes("f"), Bytes.toBytes("email"), Bytes.toBytes("zhangsan@qq.com"));
hTable.put(put); // Implementation of put
// put multiple at the same time
Put put1 = new Put(Bytes.toBytes("row2"));
put1.add(Bytes.toBytes("f"), Bytes.toBytes("id"), Bytes.toBytes("2"));
put1.add(Bytes.toBytes("f"), Bytes.toBytes("name"), Bytes.toBytes("user2"));
Put put2 = new Put(Bytes.toBytes("row3"));
put2.add(Bytes.toBytes("f"), Bytes.toBytes("id"), Bytes.toBytes("3"));
put2.add(Bytes.toBytes("f"), Bytes.toBytes("name"), Bytes.toBytes("user3"));
Put put3 = new Put(Bytes.toBytes("row4"));
put3.add(Bytes.toBytes("f"), Bytes.toBytes("id"), Bytes.toBytes("4"));
put3.add(Bytes.toBytes("f"), Bytes.toBytes("name"), Bytes.toBytes("user4"));
List<Put> list = new ArrayList<Put>();
list.add(put1);
list.add(put2);
list.add(put3);
hTable.put(list); // Execute multiple put s
// If put is detected, the condition will be inserted if it succeeds. rowkey is required to be the same.
Put put4 = new Put(Bytes.toBytes("row5"));
put4.add(Bytes.toBytes("f"), Bytes.toBytes("id"), Bytes.toBytes("7"));
hTable.checkAndPut(Bytes.toBytes("row5"), Bytes.toBytes("f"), Bytes.toBytes("id"), null, put4);
System.out.println("Insert success");
}
/**
* Test get command
*
* @param hTable
* @throws IOException
*/
static void testGet(HTableInterface hTable) throws IOException {
// Create a Get operation for the specified row.
Get get = new Get(Bytes.toBytes("row1"));
// Single row result of a {@link Get} or {@link Scan} query.
Result result = hTable.get(get); // Implementation of get
// Get the latest version of the specified column.
byte[] buf = result.getValue(family, Bytes.toBytes("id")); // Get id
System.out.println("id:" + Bytes.toString(buf));
buf = result.getValue(family, Bytes.toBytes("age")); // Get age
System.out.println("age:" + Bytes.toInt(buf));
buf = result.getValue(family, Bytes.toBytes("name"));
System.out.println("name:" + Bytes.toString(buf));
buf = result.getRow();
System.out.println("row:" + Bytes.toString(buf));
}
/**
* Test delete
*
* @param hTable
* @throws IOException
*/
static void testDelete(HTableInterface hTable) throws IOException {
// Create a Delete operation for the specified row.
Delete delete = new Delete(Bytes.toBytes("row3"));
// Delete column
delete = delete.deleteColumn(family, Bytes.toBytes("id"));
// Delete family directly
// delete.deleteFamily(family);
hTable.delete(delete); // Delete rowkey (delete delete delete = new delete (bytes.tobytes ("row3"));)
System.out.println("Delete successful");
}
}

