1. Brief description
When using HBase, if you have billions of rows or millions of columns of data, the ability to return a large amount of data in a query is subject to the bandwidth of the network, and even if the network conditions allow, the client's computing may not be able to meet the requirements.In this case, Coprocessors arise.It allows you to put your business computing code in the coprocessor of the RegionServer and return the processed data to the client, which can greatly reduce the amount of data that needs to be transferred and thereby improve performance.At the same time, the coprocessor allows users to extend the functionality that HBase does not currently have, such as permission checking, secondary indexing, integrity constraints, and so on.
2. Coprocessor Types
2.1 Observer Coprocessor
1. Functions
Observer coprocessors are similar to triggers in relational databases, which are called by the Server side when certain events occur.Usually it can be used to implement the following functions:
- Privilege check: You can use the preGet or prePut method to check permissions before performing a Get or Put operation;
- Integrity constraints: HBase does not support foreign key functionality in relational databases. It can check the associated data when inserting or deleting data by triggers.
- Secondary index: You can use a coprocessor to maintain secondary indexes.
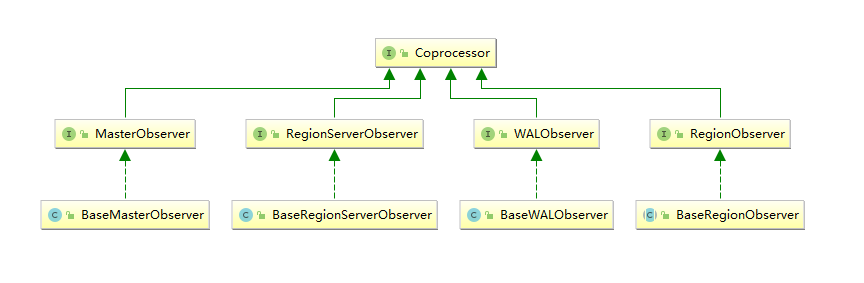
2. Types
There are currently four types of Observer coprocessors:
-
RegionObserver :
Allows you to observe events on Region s, such as Get and Put operations. -
RegionServerObserver :
Allows you to observe events related to RegionServer operations, such as start, stop, or perform merges, commit, or rollback. -
MasterObserver :
Allows you to observe events related to the HBase Master, such as table creation, deletion, or schema modification. -
WalObserver :
Allows you to observe events related to the pre-written log (WAL).
3. Interface
All four types of Observer coprocessors inherit from the Coprocessor interface, where all available hook methods are defined to perform specific operations before and after the corresponding methods.Normally, instead of implementing the above interface directly, we inherit its Base implementation class, which simply implements the methods in the interface empty, so that when we implement a custom coprocessor, we don't have to implement all the methods, just rewrite the necessary ones.
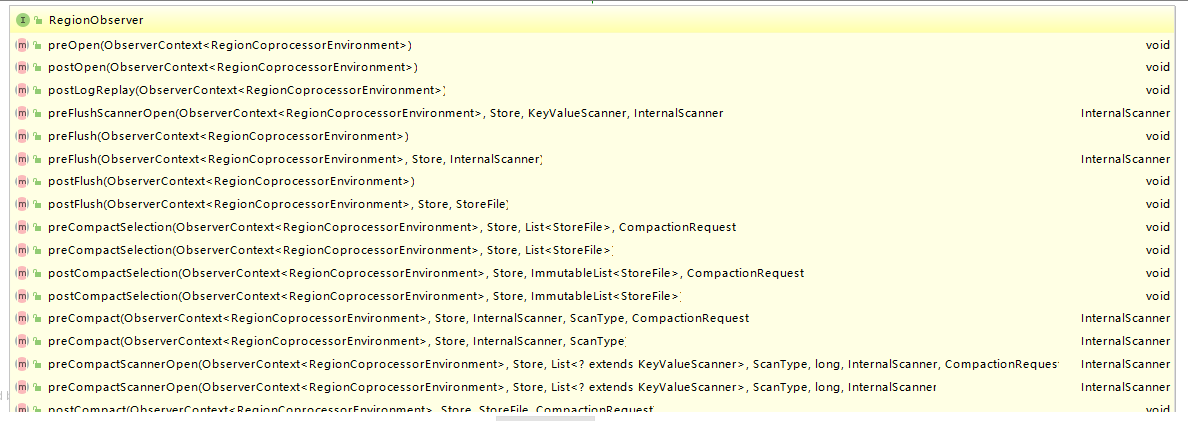
For example, RegionObservers defines all available hook methods in its interface class. Below, some methods are intercepted. Most methods appear in pairs, with pre post:
4. Execution process
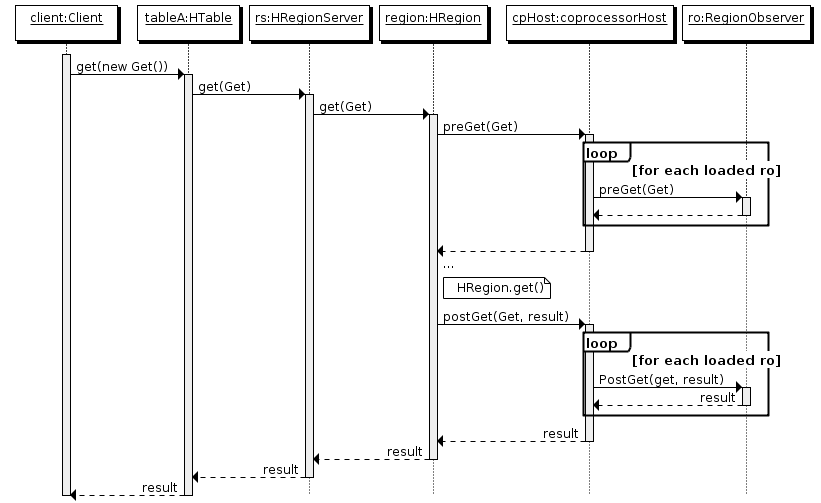
- Client makes put request
- The request is assigned to the appropriate RegionServer and region
- coprocessorHost intercepts the request and then calls prePut() on each RegionObserver in the table
- If not intercepted by prePut(), the request continues to be sent to the region and processed
- The result from the region is again intercepted by CoprocessorHost, calling postPut()
- If no postPut() intercepts the response, the final result is returned to the client
If you know Spring, you can compare it to how its AOP works, as do official documents:
If you are familiar with Aspect Oriented Programming (AOP), you can think of a coprocessor as applying advice by intercepting a request and then running some custom code,before passing the request on to its final destination (or even changing the destination).
If you are familiar with Aspect Oriented Programming (AOP), you can think of a coprocessor as using Advice by intercepting requests and running some custom code, then passing the request to its final target (or changing the target).
2.2 Endpoint Coprocessor
Endpoint coprocessors are similar to stored procedures in relational databases.Clients can call the Endpoint coprocessor to process data on the service side and return.
For example, if there is no coprocessor, when the user needs to find the largest data in a table, that is, the max aggregation operation, a full table scan must be performed, and then the scan results are traversed on the client, which will certainly increase the pressure on the client to process the data.With Coprocessor, users can deploy maximum-seeking code to the HBase Server side, and HBase will use multiple nodes of the underlying cluster to perform maximum-seeking operations concurrently.That is to execute the code that evaluates the maximum value within each region, calculates the maximum value for each region on the Region Server side, and returns only the max value to the client.Clients then only need to compare the maximum value of each region to find the maximum value.
3. Loading methods for co-processing
To use our own coprocessors, you must load them either statically (using HBase configuration) or dynamically (using HBase Shell or Java API).
- Statically loaded coprocessors are referred to as System Coprocessor (system-level coprocessor), scoped to all tables on the entire HBase and require restarting the HBase service;
- A dynamically loaded coprocessor, called a Table Coprocessor, acts on a specified table without restarting the HBase service.
The loading and unloading methods are described below.
4. Static Loading and Unloading
4.1 Static Loading
Static loading consists of three steps:
- Define the coprocessors that need to be loaded in hbase-site.xml.
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.myname.hbase.coprocessor.endpoint.SumEndPoint</value>
</property>The value of the <name>tag must be one of the following:
- RegionObservers and Endpoints coprocessor: hbase.coprocessor.region.classes
- WALObservers coprocessor: hbase.coprocessor.wal.classes
-
MasterObservers coprocessor: hbase.coprocessor.master.classes
<value>must be the fully qualified class name of the coprocessor implementation class.If multiple classes are specified for loading, class names must be comma-separated.
- Put jar (including code and all dependencies) in the lib directory of the HBase installation directory;
- Restart HBase.
4.2 Static Uninstall
- Remove the <property>element and its child elements of the configured coprocessor from hbase-site.xml;
- Delete coprocessor JAR files from the class path or HBase lib directory (optional);
- Restart HBase.
V. Dynamic Loading and Unloading
With a dynamically loaded coprocessor, there is no need to restart HBase.However, a dynamically loaded coprocessor is loaded on a per-table basis and can only be used with the specified table.
In addition, tables must be disable d to load coprocessors when using dynamic loading.There are usually two ways to dynamically load: Shell and the Java API.
The following examples are based on two premises:
- coprocessor.jar contains the coprocessor implementation and all its dependencies.
- The path where JAR packages are stored on HDFS is: hdfs://namenode>:<port>/user /<hadoop-user>/coprocessor.jar
5.1 HBase Shell Dynamic Loading
- Disable tables using HBase Shell
hbase > disable 'tableName'
- Load the coprocessor using the following command
hbase > alter 'tableName', METHOD => 'table_att', 'Coprocessor'=>'hdfs://<namenode>:<port>/ user/<hadoop-user>/coprocessor.jar| org.myname.hbase.Coprocessor.RegionObserverExample|1073741823| arg1=1,arg2=2'
Coprocessor contains four parameters separated by the pipe (|) character, which are interpreted in sequence as follows:
- JAR package path: Usually the path of the JAR package on HDFS.Two things to note about routes are:
- Wildcards such as: hdfs://<namenode>:<port>/user/<hadoop-user>/*.jar are allowed to add the specified JAR package;
- You can make the specified directory, for example, hdfs://<namenode>:<port>/user/<hadoop-user>/, which adds all JAR packages in the directory but does not search for JAR packages in subdirectories.
- Class name: The full class name of the coprocessor.
- Priority: The priority of the coprocessor, following the natural order of numbers, i.e., the smaller the value, the higher the priority.It can be empty, in which case the default priority value will be assigned.
- Optional parameters: Optional parameters for the passed coprocessor.
- Enable tables
hbase > enable 'tableName'
- Verify that the coprocessor is loaded
hbase > describe 'tableName'
The presence of a coprocessor in the TABLE_ATTRIBUTES property indicates that the load was successful.
</br>
5.2 HBase Shell Dynamic Uninstall
- Disable tables
hbase> disable 'tableName'
- Remove Table Coprocessor
hbase> alter 'tableName', METHOD => 'table_att_unset', NAME => 'coprocessor$1'
- Enable tables
hbase> enable 'tableName'
</br>
5.3 Java API Dynamic Loading
TableName tableName = TableName.valueOf("users");
String path = "hdfs://<namenode>:<port>/user/<hadoop-user>/coprocessor.jar";
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
admin.disableTable(tableName);
HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName);
HColumnDescriptor columnFamily1 = new HColumnDescriptor("personalDet");
columnFamily1.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily1);
HColumnDescriptor columnFamily2 = new HColumnDescriptor("salaryDet");
columnFamily2.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily2);
hTableDescriptor.setValue("COPROCESSOR$1", path + "|"
+ RegionObserverExample.class.getCanonicalName() + "|"
+ Coprocessor.PRIORITY_USER);
admin.modifyTable(tableName, hTableDescriptor);
admin.enableTable(tableName);In HBase 0.96 and later versions, the addCoprocessor() method of HTableDescriptor provides a more convenient loading method.
TableName tableName = TableName.valueOf("users");
Path path = new Path("hdfs://<namenode>:<port>/user/<hadoop-user>/coprocessor.jar");
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
admin.disableTable(tableName);
HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName);
HColumnDescriptor columnFamily1 = new HColumnDescriptor("personalDet");
columnFamily1.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily1);
HColumnDescriptor columnFamily2 = new HColumnDescriptor("salaryDet");
columnFamily2.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily2);
hTableDescriptor.addCoprocessor(RegionObserverExample.class.getCanonicalName(), path,
Coprocessor.PRIORITY_USER, null);
admin.modifyTable(tableName, hTableDescriptor);
admin.enableTable(tableName);5.4 Java API Dynamic Uninstall
Uninstalling is essentially redefining tables without setting up coprocessors.This deletes the coprocessors on all tables.
TableName tableName = TableName.valueOf("users");
String path = "hdfs://<namenode>:<port>/user/<hadoop-user>/coprocessor.jar";
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
admin.disableTable(tableName);
HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName);
HColumnDescriptor columnFamily1 = new HColumnDescriptor("personalDet");
columnFamily1.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily1);
HColumnDescriptor columnFamily2 = new HColumnDescriptor("salaryDet");
columnFamily2.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily2);
admin.modifyTable(tableName, hTableDescriptor);
admin.enableTable(tableName);VI. COPROCESSOR CASES
Here is a simple case to implement a coprocessor similar to the append command in Redis. When we perform a put operation on an existing column, HBase defaults to an update operation. Here we modify it to an append operation.
# Example redis append command redis> EXISTS mykey (integer) 0 redis> APPEND mykey "Hello" (integer) 5 redis> APPEND mykey " World" (integer) 11 redis> GET mykey "Hello World"
6.1 Create test tables
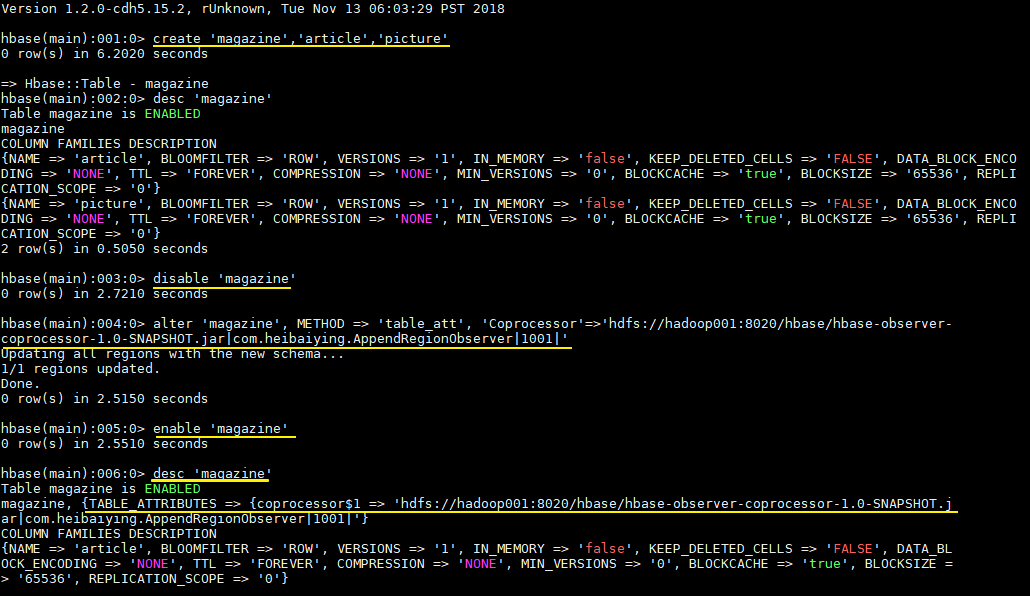
# Create a magazine table with articles and pictures hbase > create 'magazine','article','picture'
6.2 Coprocessor Programming
The complete code can be seen in this repository: hbase-observer-coprocessor
Create a new Maven project and import the following dependencies:
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>1.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.2.0</version>
</dependency>Inherit BaseRegionObserver to implement our custom RegionObserver, and when executing the put command on the same article:content, add the newly inserted content to the end of the original content with the following code:
public class AppendRegionObserver extends BaseRegionObserver {
private byte[] columnFamily = Bytes.toBytes("article");
private byte[] qualifier = Bytes.toBytes("content");
@Override
public void prePut(ObserverContext<RegionCoprocessorEnvironment> e, Put put, WALEdit edit,
Durability durability) throws IOException {
if (put.has(columnFamily, qualifier)) {
// Traverse the query results to get the original value of the specified column
Result rs = e.getEnvironment().getRegion().get(new Get(put.getRow()));
String oldValue = "";
for (Cell cell : rs.rawCells())
if (CellUtil.matchingColumn(cell, columnFamily, qualifier)) {
oldValue = Bytes.toString(CellUtil.cloneValue(cell));
}
// Gets the newly inserted value of the specified column
List<Cell> cells = put.get(columnFamily, qualifier);
String newValue = "";
for (Cell cell : cells) {
if (CellUtil.matchingColumn(cell, columnFamily, qualifier)) {
newValue = Bytes.toString(CellUtil.cloneValue(cell));
}
}
// Append operation
put.addColumn(columnFamily, qualifier, Bytes.toBytes(oldValue + newValue));
}
}
}
6.3 Packaging Project
Package using the maven command with the file name hbase-observer-coprocessor-1.0-SNAPSHOT.jar
# mvn clean package
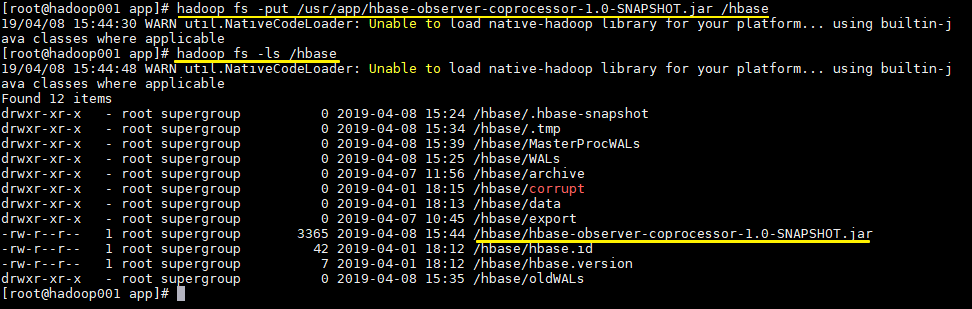
6.4 Upload JAR packages to HDFS
# Upload items to the hbase directory on HDFS hadoop fs -put /usr/app/hbase-observer-coprocessor-1.0-SNAPSHOT.jar /hbase # See if the upload was successful hadoop fs -ls /hbase
6.5 Load Coprocessor
- Disable tables before loading coprocessors
hbase > disable 'magazine'
- Load Coprocessor
hbase > alter 'magazine', METHOD => 'table_att', 'Coprocessor'=>'hdfs://hadoop001:8020/hbase/hbase-observer-coprocessor-1.0-SNAPSHOT.jar|com.heibaiying.AppendRegionObserver|1001|'
- Enable tables
hbase > enable 'magazine'
- See if the coprocessor loaded successfully
hbase > desc 'magazine'
The presence of a coprocessor in the TABLE_ATTRIBUTES property indicates that the load was successful, as shown below:
6.6 Test Load Results
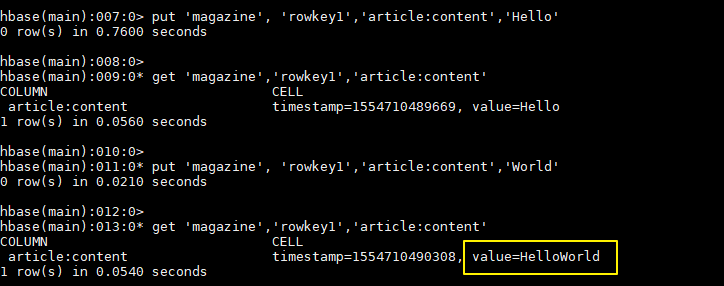
Insert a set of test data:
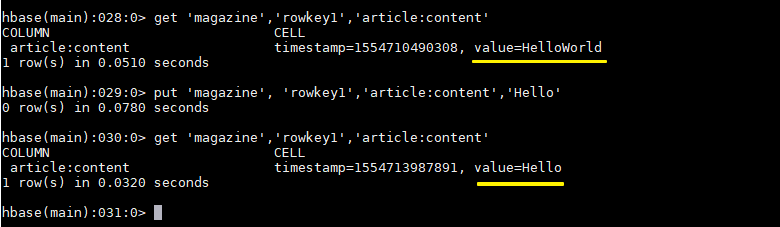
hbase > put 'magazine', 'rowkey1','article:content','Hello' hbase > get 'magazine','rowkey1','article:content' hbase > put 'magazine', 'rowkey1','article:content','World' hbase > get 'magazine','rowkey1','article:content'
You can see that the append operation has been performed on the value of the specified column:
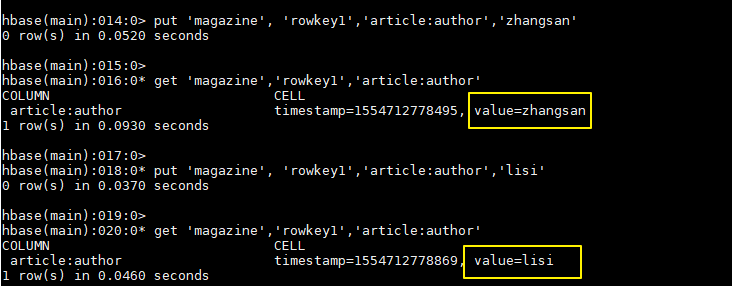
Insert a set of comparison data:
hbase > put 'magazine', 'rowkey1','article:author','zhangsan' hbase > get 'magazine','rowkey1','article:author' hbase > put 'magazine', 'rowkey1','article:author','lisi' hbase > get 'magazine','rowkey1','article:author'
You can see whether update is performed for normal columns:
 >
>
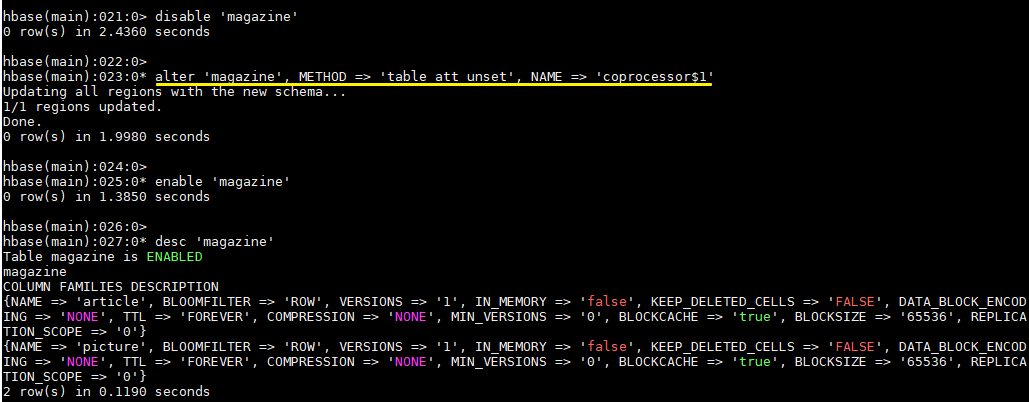
6.7 Uninstall Coprocessor
- Disable tables before uninstalling coprocessors
hbase > disable 'magazine'
- Uninstall Coprocessor
hbase > alter 'magazine', METHOD => 'table_att_unset', NAME => 'coprocessor$1'
- Enable tables
hbase > enable 'magazine'
- See if the coprocessor uninstalled successfully
hbase > desc 'magazine'
6.8 Test Uninstall Results
Execute the following commands in turn to test whether uninstallation was successful
hbase > get 'magazine','rowkey1','article:content' hbase > put 'magazine', 'rowkey1','article:content','Hello' hbase > get 'magazine','rowkey1','article:content'
Reference material
For more big data series articles, see the individual GitHub open source project: Starter's Guide to Big Data