1, Introduction to HAProxy
HAProxy is a proxy software that provides high availability, load balancing and applications based on TCP (layer 4) and HTTP (layer 7). It supports virtual hosts. It is a free, fast and reliable solution. HAProxy is especially suitable for web sites with heavy load, which usually need session persistence or seven layer processing. HAProxy runs on current hardware and can fully support tens of thousands of concurrent connections. And its operation mode makes it easy and safe to integrate into your current architecture, and can protect your web server from being exposed to the network.
HAProxy implements an event driven, single process model that supports a very large number of concurrent connections. The multiprocess or multithreading model is limited by memory, system scheduler and ubiquitous locks, and can rarely handle thousands of concurrent connections. The event driven model does not have these problems because it implements all these tasks on the user space with better resource and time management. The disadvantage of this model is that these programs usually have poor scalability on multi-core systems. This is why they must be optimized to do more work per CPU cycle.
HAProxy supports connection rejection: because the overhead of maintaining a connection open is very low, sometimes we need to limit attack bots, that is, limit their connection open, so as to limit their harm. This has been developed for a website caught in a small DDoS attack, and has saved many sites. This advantage is not available in other load balancers.
HAProxy supports fully transparent proxy (it already has the typical characteristics of hardware firewall): you can use the client IP address or any other address to connect to the back-end server. This feature can only be used after the Linux 2.4/2.6 kernel is patched with cttproxy. This feature also makes it possible to handle some traffic for a special server without modifying the server address.
HAProxy uses several common technologies on the OS to maximize performance.
-
The single process and event driven model significantly reduces the overhead and memory consumption of context switching.
-
O(1) event checker allows it to detect any event of any connection in high concurrency connection.
-
Under any available condition, the single buffering mechanism can complete the read-write operation without copying any data, which will save a lot of CPU clock cycles and memory bandwidth;
-
With the help of the splice() system call on Linux 2.6 (> = 2.6.27.19), HAProxy can realize zero copy forwarding and zero starting in Linux 3.5 and above OS;
-
The memory allocator can realize immediate memory allocation in a fixed size memory pool, which can significantly reduce the time to create a session;
-
Tree storage: it focuses on using the elastic binary tree developed by the author many years ago, and realizes the low overhead of O(log(N)) to maintain timer commands, keep running queue commands, manage polling and minimum connection queue;
-
Optimized HTTP header analysis: the optimized header analysis function avoids rereading any memory area during HTTP header analysis;
-
The expensive system calls are carefully reduced, and most of the work is completed in user space, such as time reading, buffer aggregation, enabling and disabling file descriptors, etc;
The optimization of all these nuances realizes that there is still a very low CPU load above the medium-sized load. Even in very high load scenarios, 5% user space occupancy and 95% system space occupancy are very common, which means that the HAProxy process consumption is more than 20 times lower than the system space consumption. Therefore, it is very important to tune the OS performance. Even if the occupancy rate of user space is doubled, the CPU occupancy rate is only 10%, which explains why layer 7 processing has a limited impact on performance. Thus, on high-end systems, the layer 7 performance of HAProxy can easily exceed that of hardware load balancing devices.
In the production environment, using HAProxy as an emergency solution for expensive high-end hardware load balancing equipment failure on layer 7 processing can also be seen for a long time. Hardware load balancing devices process requests at the "message" level, which is difficult to support request across multiple packets, and they do not buffer any data, so they have a long response time. Correspondingly, the software load balancing device uses TCP buffer, which can establish extremely long requests and has a large response time.
2, HAProxy load mysql Cluster
In this era of large amount of data, single machine mysql is no longer competent for the current amount of data. Therefore, we have also made corresponding changes, such as building master-slave replication, realizing read-write separation architecture, or building sub database and sub table architecture, but these all have the problem of single point of failure. Of course, if you use mycat middleware, you can configure multiple master nodes to realize fault transfer, If mycat is not applicable, using HAProxy is also a good solution.
In this experiment, mysql master master to master replication is not built in order to see the changes of data more square. For mysql master-slave replication, you can use mysql's own master-slave replication. Pay attention to modifying the self increasing size to avoid conflict. You can also use otter middleware to synchronize data efficiently.
Before the experiment, you can close the firewall or release the required ports to avoid different connections. Close selinux:
temporary
setenforce 0
Permanent restart required
sed -i 's/enforcing/disabled/' /etc/selinux/config
Build architecture:
| host | role |
|---|---|
| 192.168.40.163 | HAProxy proxy |
| 192.168.40.130 | mysql1 |
| 192.168.40.164 | mysql2 |
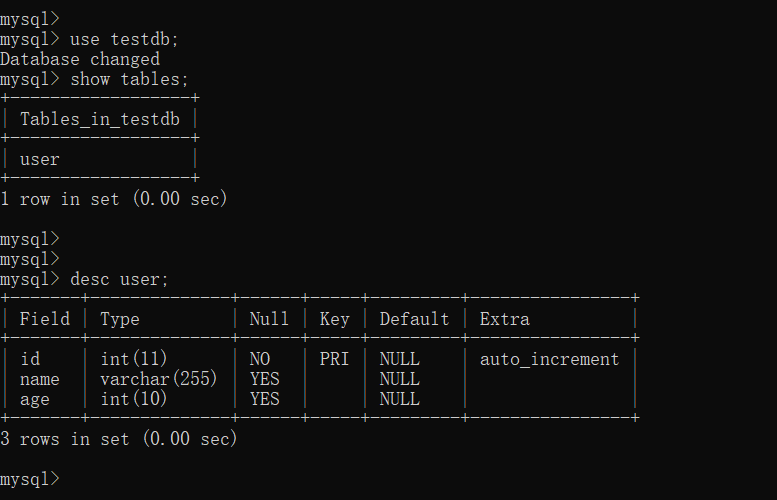
The testdb library and the user table are created in both databases.
Install HAProxy
In the 192.168.40.163 host:
- Download HAProxy
yum install -y haproxy
- Modify haproxy.cfg configuration file
cat > /etc/haproxy/haproxy.cfg << EOF
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
# to have these messages end up in /var/log/haproxy.log you will
# need to:
# 1) configure syslog to accept network log events. This is done
# by adding the '-r' option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# local2.* /var/log/haproxy.log
#
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
#---------------------------------------------------------------------
# kubernetes apiserver frontend which proxys to the backends
#---------------------------------------------------------------------
frontend mysql-apiserver
mode tcp
bind *:3306
option tcplog
default_backend mysql-apiserver
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend mysql-apiserver
mode tcp
balance roundrobin
server master1 192.168.40.130:3306 check
server master2 192.168.40.164:3306 check
#---------------------------------------------------------------------
# collection haproxy statistics message
#---------------------------------------------------------------------
listen stats
bind *:1080
stats auth admin:awesomePassword
stats refresh 5s
stats realm HAProxy\ Statistics
stats uri /admin?stats
EOF
- Start haproxy
systemctl start haproxy
- Set startup and self startup
systemctl enable haproxy
View startup status
systemctl status haproxy

3, Testing
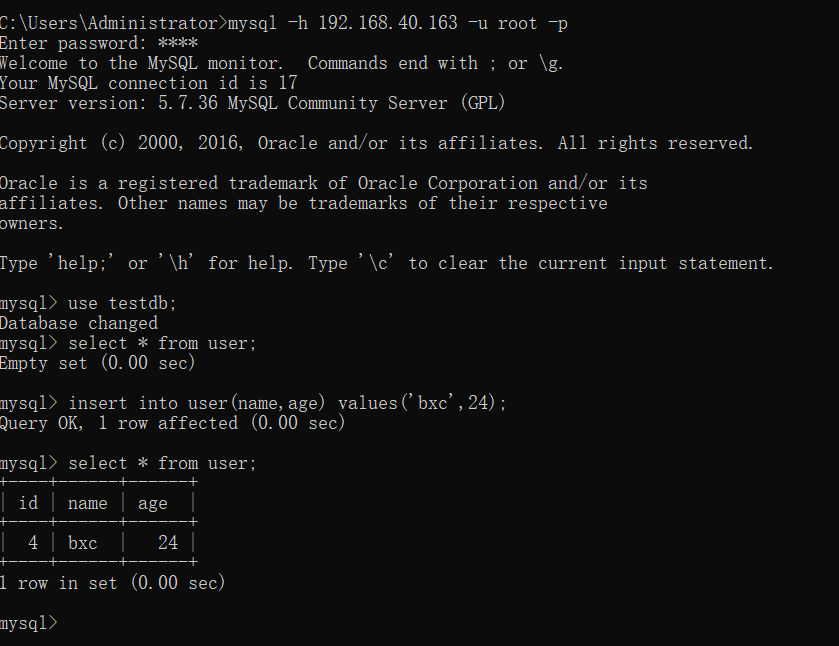
Connect 163 using client connections:
mysql -h 192.168.40.163 -u root -p
In the connection, add data to the user table:
insert into user(name,age) values('bxc',24);
Disconnect, reconnect and query again:
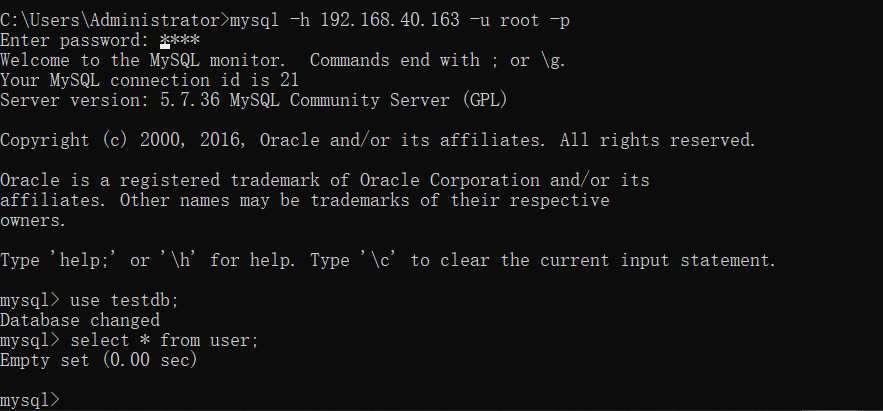
It is found that no data can be found. We insert a different data again:
insert into user(name,age) values('bxc22',24);
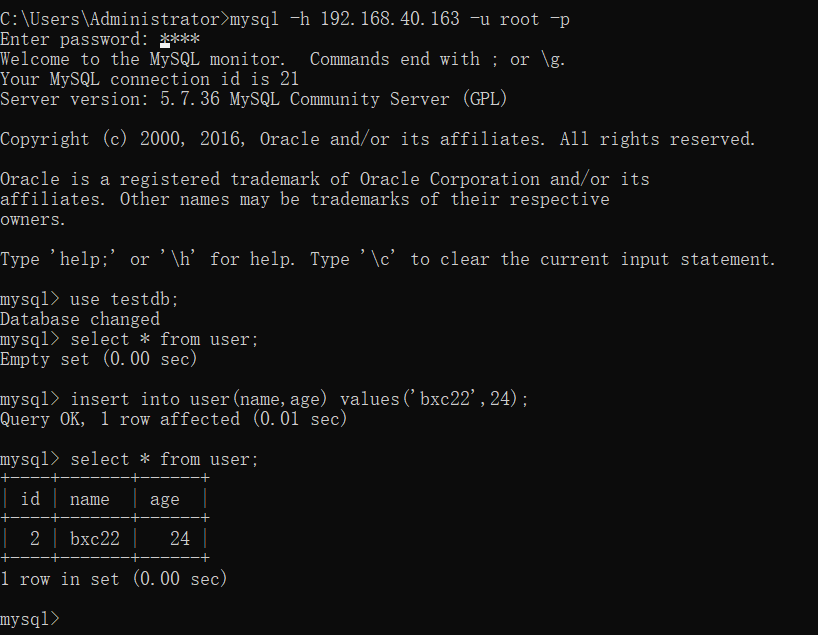
Disconnect and reconnect query:

The data is restored to the content just written.
You can connect mysql of 130 and 163 to view data:
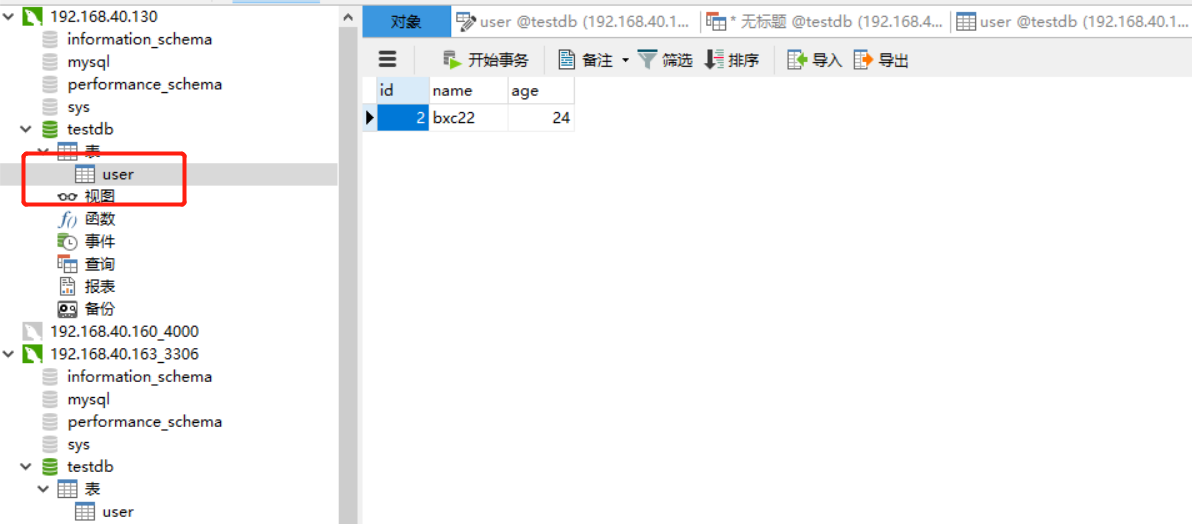
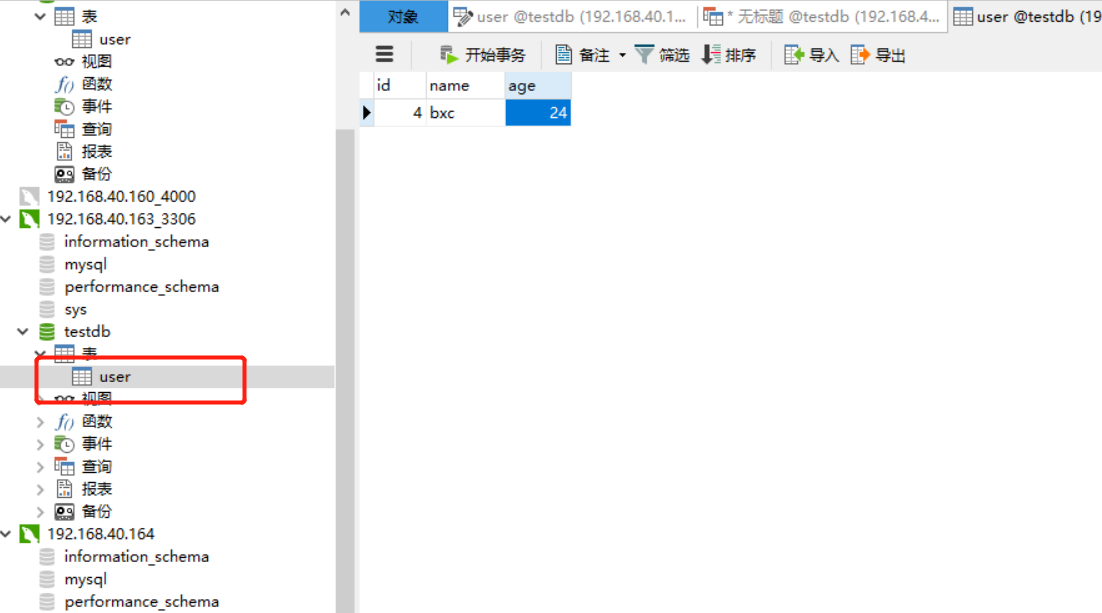
From the above data, we can see that the load effect has been achieved. If mysql master replication is built, we can share the pressure and achieve the effect of mysql load balancing.

Love little buddy can pay attention to my personal WeChat official account and get more learning materials.