Written in front
Since the last project 58HouseSearch After the migration from. NET to. NET core, it took a month to officially launch the new version.
Then recently a new pit was opened and a new pit was built. Dy2018Crawler Film resources used to climb dy2018 Film Paradise. Here is also a brief introduction to how to write a crawler based on. NET Core.
PS: If there are any errors, please specify that ____________
PPS: Should we go to the cinema or go to the cinema more? After all, beauty is priceless at a good time.
Preparations (. NET Core Preparations)
First, you must install. NET Core first. Download and install the tutorial here: .NET - Powerful Open Source Development . Whether you are Windows, linux or mac, you can play it all.
My environment here is: Windows 10 + VS2015 community updata3 + NET Core 1.1.0 SDK + NET Core 1.0.1 tools Preview 2.
In theory, you only need to install. NET Core 1.1.0 SDK to develop. NET Core programs. It doesn't matter what tools you use to write code.
After installing the above tools, you can see the template of. NET Core in the new project of VS2015. The following picture:
For simplicity, when we create it, we directly select the template that comes with VS. NET Core tools.
A Reptile's Self-cultivation
Analysis web page
Before writing a crawler, we first need to understand the composition of the web data to be crawled.
Specifically to the web page, it is to analyze what tags or tags we want to grab data in HTML, and then use this tag to extract data from HTML. In my case, I use more ID and CSS attributes of HTML tags.
Take dy2018.com, which this article wants to crawl, for example, to briefly describe the process. The home page of dy2018.com is as follows:
In chrome, press F12 to enter the developer mode, then use the mouse to select the corresponding page data, and then analyze the HTML composition of the page.
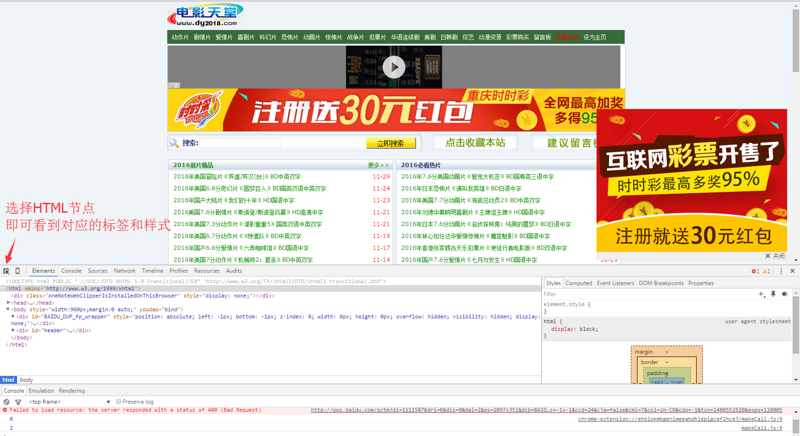
Then we start to analyze the page data:
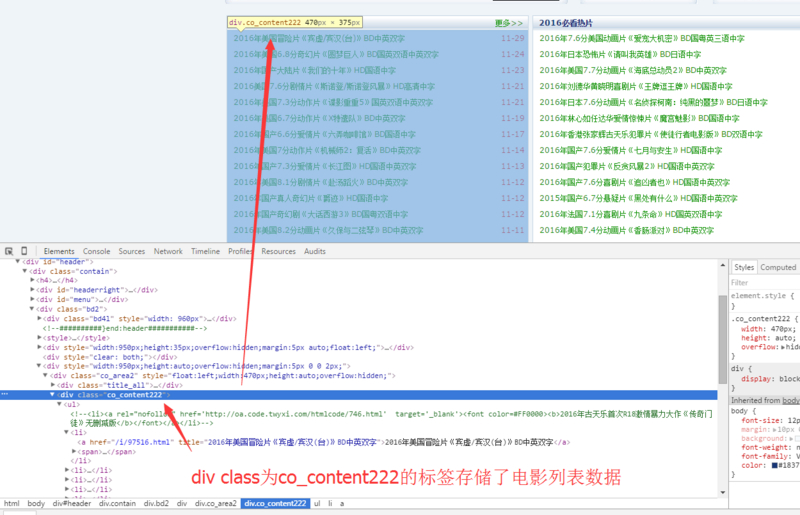
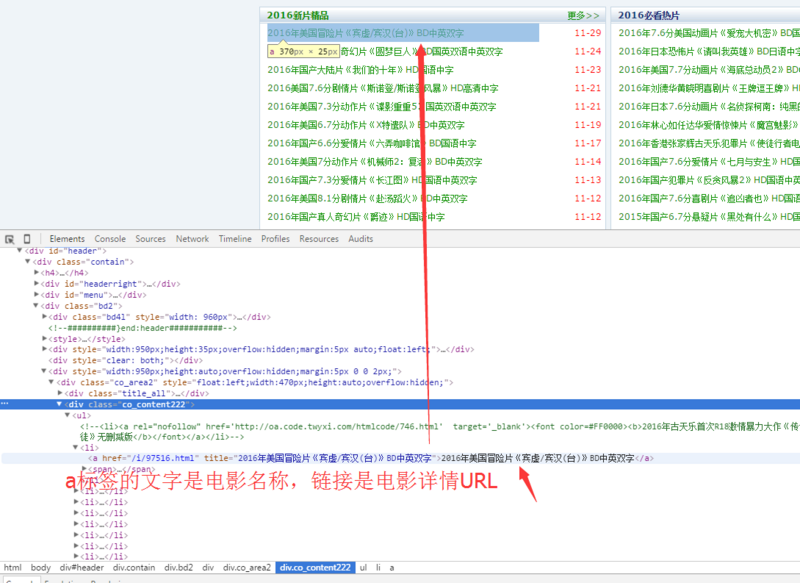
After a brief analysis of HTML, we come to the following conclusions:
Film data on the home page of www.dy2018.com is stored in a div tag with class co_content 222
Film details are linked to a tag. The tag shows the text as the name of the movie and the URL as the detail URL.
So in conclusion, our work is to find the div tag of class='co_content 222', and extract all a tag data from it.
Start writing code...
Before writing 58 HouseSearch project migrated to asp.net core Briefly mention the AngleSharp library, a DLL component based on. NET (C#) for parsing xHTML source code.
The AngleSharp home page is here: https://anglesharp.github.io/,
Blog Garden Articles: Introduction to AngleSharp, a sharp tool for parsing HTML,
Nuget address: Nuget AngleSharp Install command: Install-Package AngleSharp
Get movie list data
private static HtmlParser htmlParser = new HtmlParser(); private ConcurrentDictionary<string, MovieInfo> _cdMovieInfo = new ConcurrentDictionary<string, MovieInfo>(); private void AddToHotMovieList() { //This operation does not block other current operations, so use Task // _ cdMovieInfo is a thread-safe dictionary that stores all current movie data. Task.Factory.StartNew(()=> { try { //Getting HTML from a URL var htmlDoc = HTTPHelper.GetHTMLByURL("http://www.dy2018.com/"); //HTML parses into IDocument var dom = htmlParser.Parse(htmlDoc); //Extract div tags from dom for all class='co_content 222' //QuerySelectorAll method accepts selector syntax var lstDivInfo = dom.QuerySelectorAll("div.co_content222"); if (lstDivInfo != null) { //The first three DIV s are new movies foreach (var divInfo in lstDivInfo.Take(3)) { //Get all a tags in div and a tag contains "/i/" //Contains("/i/") condition filtering is due to the fact that the div a tag in this block may be an advertisement link in the test. divInfo.QuerySelectorAll("a").Where(a => a.GetAttribute("href").Contains("/i/")).ToList().ForEach( a => { //Stitching together to form a complete link var onlineURL = "http://www.dy2018.com" + a.GetAttribute("href"); //See if it already exists in existing data if (!_cdMovieInfo.ContainsKey(onlineURL)) { //Get detailed information about the movie MovieInfo movieInfo = FillMovieInfoFormWeb(a, onlineURL); //Download links are not added to existing data until they are empty if (movieInfo.XunLeiDownLoadURLList != null && movieInfo.XunLeiDownLoadURLList.Count != 0) { _cdMovieInfo.TryAdd(movieInfo.Dy2018OnlineUrl, movieInfo); } } }); } } } catch(Exception ex) { } }); }
Getting Film Details
private MovieInfo FillMovieInfoFormWeb(AngleSharp.Dom.IElement a, string onlineURL) { var movieHTML = HTTPHelper.GetHTMLByURL(onlineURL); var movieDoc = htmlParser.Parse(movieHTML); //http://www.dy2018.com/i/97462.html analysis process see above, no more details //Details of the movie are shown in the tag id Zoom var zoom = movieDoc.GetElementById("Zoom"); //The download link is in the td of bgcolor=' fdfddf', there may be multiple links var lstDownLoadURL = movieDoc.QuerySelectorAll("[bgcolor='#fdfddf']"); //Publishing time is in the span tag of class='updatetime' var updatetime = movieDoc.QuerySelector("span.updatetime"); var pubDate = DateTime.Now; if(updatetime!=null && !string.IsNullOrEmpty(updatetime.InnerHtml)) { //Content with the word "publish time:" replace into ", then go to conversion, conversion failure does not affect the process DateTime.TryParse(updatetime.InnerHtml.Replace("Release time:", ""), out pubDate); } var movieInfo = new MovieInfo() { //InnerHtml may also contain font tags to do one more Replace MovieName = a.InnerHtml.Replace("<font color=\"#0c9000\">","").Replace("<font color=\" #0c9000\">","").Replace("</font>", ""), Dy2018OnlineUrl = onlineURL, MovieIntro = zoom != null ? WebUtility.HtmlEncode(zoom.InnerHtml) : "No introduction...",//There may be no introduction, though it seems unlikely. XunLeiDownLoadURLList = lstDownLoadURL != null ? lstDownLoadURL.Select(d => d.FirstElementChild.InnerHtml).ToList() : null,//There may be no download link PubDate = pubDate, }; return movieInfo; }
HTTPHelper
There is a small pit here. dy2018 Web page encoding format is GB2312. NET Core does not support GB2312 by default. When using Encoding.GetEncoding("GB2312"), an exception will be thrown.
The solution is to manually install the System.Text.Encoding.CodePages package (Install-Package System.Text.Encoding.CodePages).
Then add Encoding. RegisterProvider (CodePages Encoding Provider. Instance) to the Configure method of Starup.cs, and then you can use Encoding.GetEncoding("GB2312") normally.
using System; using System.Net.Http; using System.Net.Http.Headers; using System.Text; namespace Dy2018Crawler { public class HTTPHelper { public static HttpClient Client { get; } = new HttpClient(); public static string GetHTMLByURL(string url) { try { System.Net.WebRequest wRequest = System.Net.WebRequest.Create(url); wRequest.ContentType = "text/html; charset=gb2312"; wRequest.Method = "get"; wRequest.UseDefaultCredentials = true; // Get the response instance. var task = wRequest.GetResponseAsync(); System.Net.WebResponse wResp = task.Result; System.IO.Stream respStream = wResp.GetResponseStream(); //dy2018 is coded in GB2312. using (System.IO.StreamReader reader = new System.IO.StreamReader(respStream, Encoding.GetEncoding("GB2312"))) { return reader.ReadToEnd(); } } catch (Exception ex) { Console.WriteLine(ex.ToString()); return string.Empty; } } } }
Realization of Timing Task
Timing tasks I use here are Pomelo.AspNetCore.TimedJob.
Pomelo.AspNetCore.TimedJob is a timed task job library implemented by. NET Core. It supports millisecond timed tasks, reads timed configuration from database, synchronous asynchronous timed tasks and other functions.
By. NET Core Community Gods and Former Microsoft MVP AmamiyaYuuko (After joining Microsoft, leaving MVP...) Development and maintenance, but it seems that there is no open source, look back and see if it can be open source.
There are various versions of nuget, on demand. Address: https://www.nuget.org/package...
The author's own introductory article: Timed Job - Pomelo Extension Package Series
Startup.cs related code
If I use it here, I must first install the corresponding package: Install-Package Pomelo. AspNetCore. TimedJob-Pre.
Then add Service in the ConfigureServices function of Startup.cs and Use it in the ConfigureFunction.
// This method gets called by the runtime. Use this method to add services to the container. public void ConfigureServices(IServiceCollection services) { // Add framework services. services.AddMvc(); //Add TimedJob services services.AddTimedJob(); } public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory) { //Use TimedJob app.UseTimedJob(); if (env.IsDevelopment()) { app.UseDeveloperExceptionPage(); app.UseBrowserLink(); } else { app.UseExceptionHandler("/Home/Error"); } app.UseStaticFiles(); app.UseMvc(routes => { routes.MapRoute( name: "default", template: "{controller=Home}/{action=Index}/{id?}"); }); Encoding.RegisterProvider(CodePagesEncodingProvider.Instance); }
Job related code
Then create a new class, clearly XXXJob.cs, referring to the namespace using Pomelo.AspNetCore.TimedJob, XXXJob inherits from Job, add the following code.
public class AutoGetMovieListJob:Job { // Begin start time; Interval execution time interval, in milliseconds, recommended the following format, here for 3 hours; SkipWhileExecuting whether to wait for the last execution to complete, true for waiting; [Invoke(Begin = "2016-11-29 22:10", Interval = 1000 * 3600*3, SkipWhileExecuting =true)] public void Run() { //Job's logical code to execute //LogHelper.Info("Start crawling"); //AddToLatestMovieList(100); //AddToHotMovieList(); //LogHelper.Info("Finish crawling"); } }
Project Release Related
Added runtimes Node
Using the new template project VS2015, the project.json configuration defaults to no runtimes nodes.
When we want to publish to a non-Windows platform, we need to configure this node manually to generate it.
"runtimes": { "win7-x64": {}, "win7-x86": {}, "osx.10.10-x64": {}, "osx.10.11-x64": {}, "ubuntu.14.04-x64": {} }
Delete/comment scripts nodes
The node.js script is called to build the front-end code when it is generated, which does not ensure that every environment has a bower... Comment is done.
//"scripts": { // "prepublish": [ "bower install", "dotnet bundle" ], // "postpublish": [ "dotnet publish-iis --publish-folder %publish:OutputPath% --framework %publish:FullTargetFramework%" ] //},
Delete/annotate the type in dependencies node
"dependencies": { "Microsoft.NETCore.App": { "version": "1.1.0" //"type": "platform" },
The configuration instructions for project.json can be seen in this official document: Project.json-file,
Or Mr. Zhang Shanyou's article NET Core Series: 2. What kind of medicine is sold in the gourd project.json
Development, compilation and publishing
//Restore various package files dotnet restore; //Publish to C: Code Website Dy2018Crawler folder dotnet publish -r ubuntu.14.04-x64 -c Release -o "C:\code\website\Dy2018Crawler";
Finally, open source as usual... the above code is found below:
Gayhub address: https://github.com/liguobao/Dy2018Crawler
Online address: http://codelover.win/
PS: Come back and write a crawler. No, everyone supports it.
This article is first published in: http://codelover.link/2016/12...