1. Target of this crawl
To crawl data from websites and analyze and organize it, my goal is to completely recreate a webapp site for practice, so I'll think about how inputs are stored in MongoDB.The crawled data is temporarily stored in the json file first; of course, it can be stored directly in your own MonoDB, so the duplicated website is a complete website. As for video playback, you can crawl the video address and write it to a specific field. The user call is to take the video from the original website directly (just crawl all the data from the free course).
) Run the meeting to another json file with the following structure
Free.json (Record course directions and classifications)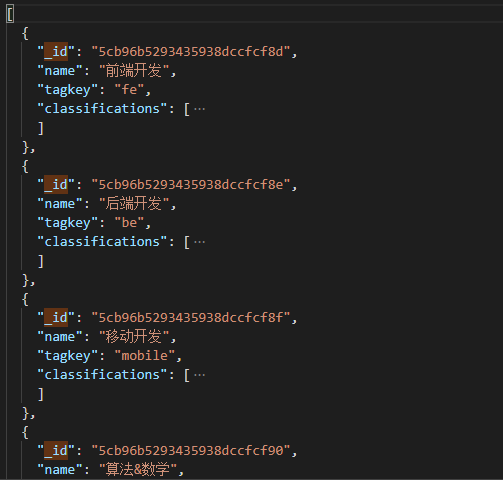
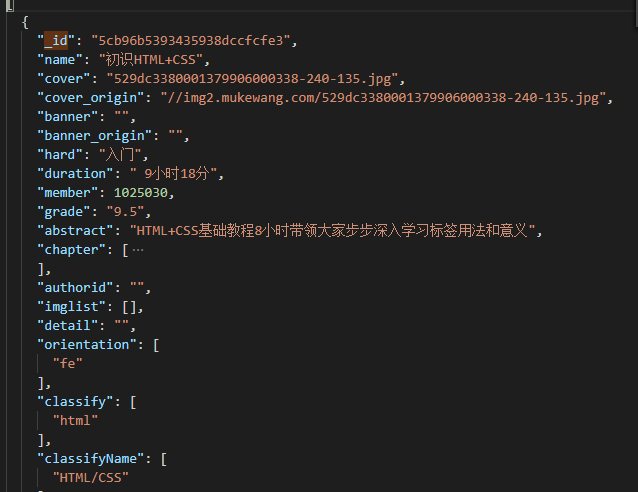
FreeCourse.json (Files recording all courses, but data will have IDs that correspond to categories in free)
2. Create Project
1) Create a craler directory, and then create a new index.js file.Execute the npm init command in the directory and then go back all the way.
2) Install npm package, execute npm install mongoose (id for generating MongoDB), npm install https, npm install cheerio; get the following directory structure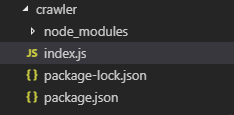
3. Get data on the classification and direction of the course
const mongoose = require('mongoose');
const https = require('https');
const fs = require('fs');
const cheerio = require('cheerio');
var courses = [],
totalPage = 0,
orientations = [],//Course Direction
orientationMap = {},
classifyMap = {},//Classification of courses
baseUrl = 'https://www.imooc.com',
freeCourseUrl = 'https://www.imooc.com/course/list'; //Free course
function fetchPage(url){
getFreeType(url);
}
//Type acquisition
function getFreeType(url) {
https.get(url, function(res){
var html = '';
res.setEncoding('utf-8')//Prevent Chinese random code
res.on('data' ,function(chunk){
html += chunk;
})
//Listens for end events and executes callback functions when the html of the entire page content is retrieved
res.on('end',function(){
var $ = cheerio.load(html);
var orientationUrl = []//Get course direction url
,orientationTag = $($('.course-nav-row')[0]);
orientationTag.find('.course-nav-item').each(function(index,ele){
if(index == 0){return}
//Course Direction Data Sheet
let orientationTemp ={
_id:new mongoose.Types.ObjectId(),
name: $(ele).find('a').text().trim(),
tagkey: $(ele).find('a').attr('href').split('=').pop(),
}
orientations.push(orientationTemp)
orientationUrl.push('https://m.imooc.com' + $(ele).find('a').attr('href'));
});
getOrientationPage(orientationUrl);//Get classification in each direction
})
})
}
//Get classification in each direction
function getOrientationPage(orientationUrl){
var promiseList = [];
orientationUrl.forEach((url,index) => {
var prom = new Promise(function(resolve,reject){
https.get(url,function(res){
var html = '';
res.setEncoding('utf-8');
res.on('data',function(chunk){
html += chunk;
});
res.on('end',function(){
var $ = cheerio.load(html);
var classifications = [];
$('.course-item-w a').each((ind,ele) => {
var classTemp = {
_id: new mongoose.Types.ObjectId(),
name: cheerio.load(ele)('.course-label').text().trim(),
tagkey: $(ele).attr('href').split('=').pop(),
img: $(ele).find('.course-img').css('background-image').replace('url(','').replace(')',''),
};
classifications.push(classTemp);
classifyMap[classTemp.name] = classTemp.tagkey;
orientationMap[classTemp.name] = orientations[index].tagkey;
})
orientations[index].classifications = classifications;
resolve('done');
})
}).on('error',function(err){
reject(err)
})
})
promiseList.push(prom);
});
Promise.all(promiseList).then(arr => {
console.log('Type data collection completed');
getFreeCourses(freeCourseUrl);
fs.writeFile('./free.json',JSON.stringify(orientations),function(err){
if(err){
console.log(err);
}else{
console.log('free.json File written successfully!');
}
});
});
}4. Get all courses
Because there are more than 800 courses in this course, including paging, it is not possible to get all courses at once.I started with recursive requests and asked for the next lesson after each request was processed, which was also possible, but that was too slow; it didn't take advantage of Ajax asynchronism at all, so I used the es6 syntax and solved the problem with promise.all.Request 10 pages at a time (if you have more node services, you can't handle them, you will make all kinds of errors, and at present you can't think of any other good way to forget your gods and teaches).For each 10 requests processed, the next page is requested until completed.It will take about 3 minutes for more than 800 courses to be processed in this way.
//Get Courses
function getFreeCourses(url,pageNum) {
https.get(url, function(res){
var html = '';
if(!pageNum){
pageNum = 1;
}
res.setEncoding('utf-8')//Prevent Chinese random code
res.on('data' ,function(chunk){
html += chunk;
})
//Listens for end events and executes callback functions when the html of the entire page content is retrieved
res.on('end',function(){
let $ = cheerio.load(html);
if(pageNum == 1){
let lastPageHref = $(".page a:contains('End Page')").attr('href');
totalPage = Number(lastPageHref.split('=').pop());
}
$('.course-card-container').each(function(index,ele){
let $ele = cheerio.load(ele);
let cover_origin = $ele('img.course-banner').attr('src');
let cover = cover_origin.split('/').pop();
let classifyName = [];
let classify = [];
let orientation = [];
let hardAndMember = $ele('.course-card-info span');
$ele('.course-label label').each((index,item) => {
var typeTxt = cheerio.load(item).text();
classifyName.push(typeTxt);
classify.push(classifyMap[typeTxt]);
orientation.push(orientationMap[typeTxt])
});
let obj ={
_id: new mongoose.Types.ObjectId(),
name: $ele("h3.course-card-name").text(),
cover: cover,
cover_origin: cover_origin,
banner:'',
banner_origin:'',
hard: cheerio.load(hardAndMember[0]).text(),//difficulty
duration: '',//Duration
member: Number(cheerio.load(hardAndMember[1]).text()),//Number of people
grade: '',//score
abstract: $ele('.course-card-desc').text(),//brief introduction
chapter: [],
authorid: '',//author
imglist: [],//Picture details
detail: '',//details
orientation: orientation,
classify: classify,
classifyName: classifyName,
detailUrl: baseUrl + $ele('a.course-card').attr('href')
};
courses.push(obj);
});
if(pageNum == totalPage){
console.log('Total length of course'+courses.length);
pageGetDetail();
}else{
let nextPageNum = pageNum + 1;
let urlParams = freeCourseUrl + '?page=' + nextPageNum;
getFreeCourses(urlParams,nextPageNum);
}
})
})
}
function pageGetDetail(startPage){
if(!startPage)startPage = 0;
let page = 10;
let eachArr = courses.slice(startPage*page,(startPage+1)*page);
let promiseList = [];
eachArr.forEach((course,index)=> {
var promise = new Promise(function(resolve,reject){
https.get(course.detailUrl,res =>{
let html = '';
res.setEncoding('utf-8');
res.on('data',function(chunk){
html += chunk;
});
res.on('end',function(){
let $ = cheerio.load(html);
let chapter = [];
let chapterEle = $('.course-chapters .chapter');
let teacherEle = $('.teacher-info');
var element = courses[startPage*page+index];
chapterEle.each(function(ind,ele){
let $ele = cheerio.load(ele);
let chapterList = [];
$ele('.video .J-media-item').each(function(ind,item){
let txt = cheerio.load(item).text();
txt = txt.replace('Start Learning');
txt = txt.trim();
chapterList.push({
txt: txt.replace(/[ \r\n]/g, ""),
type:'vedio'
});
})
let tempObj ={
header: $ele('h3').text().replace(/[ \r\n]/g, ""),
desc: $ele('.chapter-description').text().replace(/[ \r\n]/g, ""),
list: chapterList
}
chapter.push(tempObj);
})
element.duration = $('.static-item')[1] ? cheerio.load($('.static-item')[1])(".meta-value").text() : '';
element.grade = $('.score-btn .meta-value')[0] ? cheerio.load($('.score-btn .meta-value')[0]).text() : '';
element.intro = $('.course-description').text().replace(/[ \r\n]/g, "");
element.notice = $('.course-info-tip .first .autowrap').text();
element.whatlearn = $('.course-info-tip .autowrap')[1] ? cheerio.load($('.course-info-tip .autowrap')[1]).text() : "";
element.chapter = chapter;
element.teacher = {
name: teacherEle.find('.tit').text().trim(),
job: teacherEle.find('.job').text(),
imgSrc: 'http' + $('.teacher-info>a>img').attr('src'),
img: $('.teacher-info>a>img').attr('src')?$('.teacher-info>a>img').attr('src').split('/').pop():''
};
element.teacherUrl = baseUrl + $('.teacher-info>a').attr('href'),
element.questionUrl = baseUrl + $('#qaOn').attr('href');
element.noteUrl = baseUrl + $('#noteOn').attr('href');
element.commentUrl = baseUrl + $('#commentOn').attr('href');
delete element.detailUrl;
resolve('done');
})
})
});
promiseList.push(promise);
});
Promise.all(promiseList).then(arr => {
if( startPage * 10 > courses.length){
fs.writeFile('./freeCourses.json',JSON.stringify(courses),function(err){
if(err){
console.log(err);
}else{
console.log('freeCourses.json File written successfully!');
}
});
}else{
let currentPage = startPage + 1;
pageGetDetail(currentPage);
}
})
}
getFreeType(freeCourseUrl);5. Executing Programs
Once the code is written, execute the node index directly in the crawler directory.I use vscode for thieves.If the following results are printed, they are successful.
6. Summary
It feels great to finish this crawl, and the data is successfully written to the database as background data for the website.The difficulty in the process is to process the data, because although I am a trainer this time, I still treat it as a normal project to do, data is to provide front-end use, so be careful when collating.In short, as a yard farmer, continuous learning is necessary