1. background
JSON(JavaScript Object Notation) is a lightweight data exchange format. JSON has many advantages over XML, another data exchange format. For example, the readability is better and the space occupied is less.
In the field of web application development, thanks to the good support of JavaScript for JSON, JSON is more popular with developers than XML. So as a developer, if you are interested, you should have a deep understanding of JSON.
In order to explore the principle of JSON, I will introduce a simple parsing process and implementation details of JSON parser in detail in this article.
Because JSON itself is relatively simple, parsing is not complicated. So if you are interested, after reading this article, you may as well implement a JSON parser yourself.
Well, I won't say much else. Let's move to the key chapters.
2. Implementation principle of JSON parser
The JSON parser is essentially a state machine created according to JSON grammar rules. The input is a JSON string and the output is a JSON object. Generally speaking, the parsing process includes two stages: lexical analysis and grammatical analysis.
The goal of the lexical analysis stage is to parse JSON strings into Token streams according to word formation rules, such as the following JSON strings:
{
"name" : "Xiao Ming",
"age": 18
}Results after lexical analysis, a set of tokens were obtained as follows:
{, name,:, Xiaoming,,, age,:, 18,}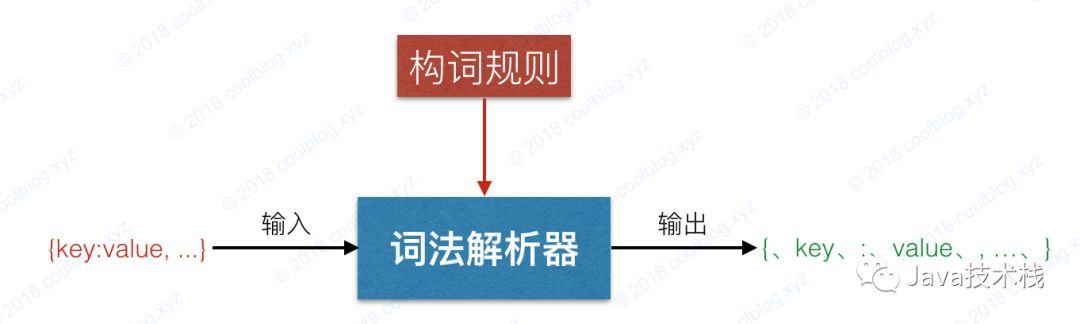
After the Token sequence is parsed by lexical analysis, the next step is syntax analysis. The purpose of syntax analysis is to check whether the JSON structure formed by the Token sequence above is legal according to the JSON grammar.
For example, JSON grammar requires non empty JSON objects to appear in the form of key value pairs, such as object = {string: value}. If a malformed string is passed in, for example:
{
"name", "Xiao Ming"
}In the syntax analysis stage, after the parser analyzes the Token name, it is considered to be a Token conforming to the rules and a key. Please do not use this JSON package in JDK 7 +! Look at this one.
Next, the parser reads the next token, expecting it to be:. But when it reads the Token, it finds that the Token is, not expected to be:, so the grammar analyzer will report an error.
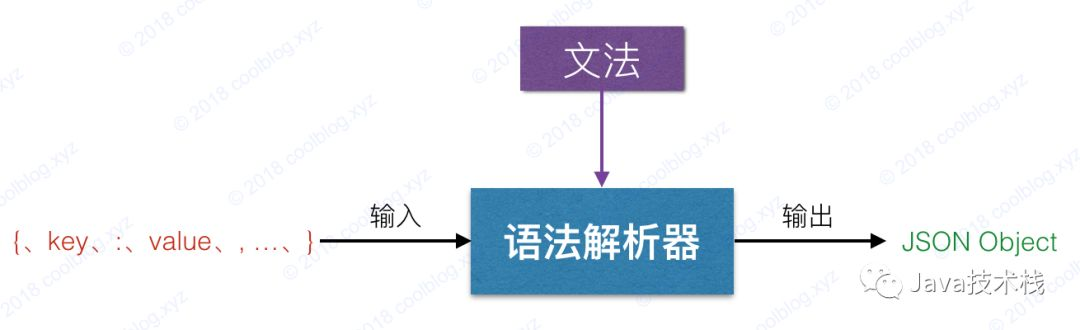
Here is a brief summary of the above two processes. Lexical analysis is to parse strings into a set of Token sequences, while syntax analysis is to check whether the JSON format formed by the input Token sequence is legal. Here you have an impression on the JSON parsing process. Next, I will analyze each process in detail.
2.1 lexical analysis
At the beginning of this chapter, I talked about the purpose of lexical parsing, which is to parse JSON strings into Token streams according to "word formation rules". Please note that double quotation marks cause words -- word formation rules, which refer to the rules that the lexical analysis module references when parsing strings into tokens.
In JSON, word formation rules correspond to several data types. When a word is read in by a lexical parser and the word type conforms to the data type specified by JSON, the lexical analyzer thinks that the word conforms to the word formation rules and generates the corresponding Token.
Here we can refer to the definition of JSON at http://www.json.org/ and list the data types specified by JSON:
BEGIN_OBJECT({)
END_OBJECT(})
BEGIN_ARRAY([)
END_ARRAY(])
NULL(null)
NUMBER (NUMBER)
STRING (STRING)
BOOLEAN(true/false)
SEP_COLON(:)
SEP_COMMA(,)
When the word read by the lexical analyzer is one of the above types, it can be parsed into a Token. We can define an enumeration class to represent the above data types, as follows:
public enum TokenType {
BEGIN_OBJECT(1),
END_OBJECT(2),
BEGIN_ARRAY(4),
END_ARRAY(8),
NULL(16),
NUMBER(32),
STRING(64),
BOOLEAN(128),
SEP_COLON(256),
SEP_COMMA(512),
END_DOCUMENT(1024);
TokenType(int code) {
this.code = code;
}
private int code;
public int getTokenCode() {
return code;
}
}In the parsing process, only the TokenType type is not enough. In addition to saving the type of a word, we need to save the literal amount of the word. Therefore, a Token class needs to be defined here. Used to encapsulate word types and literals as follows:
public class Token {
private TokenType tokenType;
private String value;
// Omit unimportant code
}After defining the Token class, we will define a class to read the string. As follows:
public CharReader(Reader reader) {
this.reader = reader;
buffer = new char[BUFFER_SIZE];
}
/**
* Returns the character at the pos subscript and returns
* @return
* @throws IOException
*/
public char peek() throws IOException {
if (pos - 1 >= size) {
return (char) -1;
}
return buffer[Math.max(0, pos - 1)];
}
/**
* Returns the character at the pos subscript, pos + 1, and finally the character
* @return
* @throws IOException
*/
public char next() throws IOException {
if (!hasMore()) {
return (char) -1;
}
return buffer[pos++];
}
public void back() {
pos = Math.max(0, --pos);
}
public boolean hasMore() throws IOException {
if (pos < size) {
return true;
}
fillBuffer();
return pos < size;
}
void fillBuffer() throws IOException {
int n = reader.read(buffer);
if (n == -1) {
return;
}
pos = 0;
size = n;
}
}With three helper classes, TokenType, Token and CharReader, we can implement a lexical parser.
public class Tokenizer {
private CharReader charReader;
private TokenList tokens;
public TokenList tokenize(CharReader charReader) throws IOException {
this.charReader = charReader;
tokens = new TokenList();
tokenize();
return tokens;
}
private void tokenize() throws IOException {
// Using do while to process empty files
Token token;
do {
token = start();
tokens.add(token);
} while (token.getTokenType() != TokenType.END_DOCUMENT);
}
private Token start() throws IOException {
char ch;
for(;;) {
if (!charReader.hasMore()) {
return new Token(TokenType.END_DOCUMENT, null);
}
ch = charReader.next();
if (!isWhiteSpace(ch)) {
break;
}
}
switch (ch) {
case '{':
return new Token(TokenType.BEGIN_OBJECT, String.valueOf(ch));
case '}':
return new Token(TokenType.END_OBJECT, String.valueOf(ch));
case '[':
return new Token(TokenType.BEGIN_ARRAY, String.valueOf(ch));
case ']':
return new Token(TokenType.END_ARRAY, String.valueOf(ch));
case ',':
return new Token(TokenType.SEP_COMMA, String.valueOf(ch));
case ':':
return new Token(TokenType.SEP_COLON, String.valueOf(ch));
case 'n':
return readNull();
case 't':
case 'f':
return readBoolean();
case '"':
return readString();
case '-':
return readNumber();
}
if (isDigit(ch)) {
return readNumber();
}
throw new JsonParseException("Illegal character");
}
private Token readNull() {...}
private Token readBoolean() {...}
private Token readString() {...}
private Token readNumber() {...}
}The above code is the implementation of lexical analyzer. Some codes are not pasted here, and will be pasted later for specific analysis.
Let's take a look at start, the core method of lexical analyzer. This method has a small amount of code and is not complicated. It continuously reads characters through a dead cycle, and then performs different parsing logic according to the type of characters.
As mentioned above, the parsing process of JSON is relatively simple. The reason is that the Token Type of each word can be determined by the first character of each word. For example:
The first character is {,}, [,],,:, which can be directly encapsulated as the corresponding Token to return
The first character is n, the word is expected to be null, and the Token type is null
The first character is t or f, the word is expected to be true or false, and the Token type is BOOLEAN
The first character is ", expecting the word to be a String, and the Token type to be String
The first character is 0-9 or - expect the word to be a NUMBER, of type NUMBER
As mentioned above, a lexical analyzer only needs to know what it expects to read next based on the first character of each word. If the expectation is met, a Token is returned, otherwise an error is returned.
Let's take a look at the processing of the lexical parser when the first character is n and ". First, look at the process of encountering the character n:
private Token readNull() throws IOException {
if (!(charReader.next() == 'u' && charReader.next() == 'l' && charReader.next() == 'l')) {
throw new JsonParseException("Invalid json string");
}
return new Token(TokenType.NULL, "null");
}The above code is very simple. After the lexical analyzer reads the character n, it expects the next three characters to be u,l,l, and N to form the word NULL. If the expectation is met, a Token of NULL type will be returned, otherwise an exception will be reported. readNull method logic is very simple, not much to say.
Next, let's look at the data processing of string type:
private Token readString() throws IOException {
StringBuilder sb = new StringBuilder();
for (;;) {
char ch = charReader.next();
// Processing escape characters
if (ch == '\\') {
if (!isEscape()) {
throw new JsonParseException("Invalid escape character");
}
sb.append('\\');
ch = charReader.peek();
sb.append(ch);
// Handle Unicode encoding, such as \ u4e2d. Only encoding in the range of \ u0000 ~ \ ufff is supported
if (ch == 'u') {
for (int i = 0; i < 4; i++) {
ch = charReader.next();
if (isHex(ch)) {
sb.append(ch);
} else {
throw new JsonParseException("Invalid character");
}
}
}
} else if (ch == '"') { // When another double quotation mark is encountered, the string parsing is considered to be finished, and the Token is returned
return new Token(TokenType.STRING, sb.toString());
} else if (ch == '\r' || ch == '\n') { // Incoming JSON string does not allow wrapping
throw new JsonParseException("Invalid character");
} else {
sb.append(ch);
}
}
}
private boolean isEscape() throws IOException {
char ch = charReader.next();
return (ch == '"' || ch == '\\' || ch == 'u' || ch == 'r'
|| ch == 'n' || ch == 'b' || ch == 't' || ch == 'f');
}
private boolean isHex(char ch) {
return ((ch >= '0' && ch <= '9') || ('a' <= ch && ch <= 'f')
|| ('A' <= ch && ch <= 'F'));
}Data parsing of string type is a little more complicated, mainly dealing with some special types of characters. The special types of characters allowed by JSON are as follows:
\" \ \b \f \n \r \t \u four-hex-digits \/
The last special character \ / code is not processed, and other characters are judged. The judgment logic is in the isEscape method. In the incoming JSON string, only the escape characters listed above are allowed in the string. If the escape character is misinterpreted, an error will be reported during parsing.
For words of type STRING, the parsing begins with the character "and ends with". So in the process of parsing, when encountering characters again, "readString method will think that the STRING parsing process is over this time, and return the corresponding type of Token.
The above describes the data parsing process of null type and string type. The process is not complicated and should not be difficult to understand. As for the data analysis process of boolean and number types, if you are interested, you can read the source code yourself, which is not mentioned here.
WeChat official account: Java technology stack, back in the background: Java, can get the latest Java tutorial I have compiled N, all dry cargo.
2.2 grammatical analysis
When the lexical analysis is finished and no errors are thrown during the analysis, then the syntax analysis can be carried out next. In the syntax analysis process, the Token sequence parsed in the lexical analysis stage is used as the input, and JSON Object or JSON Array is output.
The grammar of the implementation of the parser is as follows:
object = {} | { members }
members = pair | pair , members
pair = string : value
array = [] | [ elements ]
elements = value | value , elements
value = string | number | object | array | true | false | nullThe implementation of the parser requires two auxiliary classes, namely, the output class of the parser, JsonObject and JsonArray. Java commonly used several Json libraries, strong performance comparison! Take a look at this recommendation.
The code is as follows:
public class JsonObject {
private Map<String, Object> map = new HashMap<String, Object>();
public void put(String key, Object value) {
map.put(key, value);
}
public Object get(String key) {
return map.get(key);
}
public List<Map.Entry<String, Object>> getAllKeyValue() {
return new ArrayList<>(map.entrySet());
}
public JsonObject getJsonObject(String key) {
if (!map.containsKey(key)) {
throw new IllegalArgumentException("Invalid key");
}
Object obj = map.get(key);
if (!(obj instanceof JsonObject)) {
throw new JsonTypeException("Type of value is not JsonObject");
}
return (JsonObject) obj;
}
public JsonArray getJsonArray(String key) {
if (!map.containsKey(key)) {
throw new IllegalArgumentException("Invalid key");
}
Object obj = map.get(key);
if (!(obj instanceof JsonArray)) {
throw new JsonTypeException("Type of value is not JsonArray");
}
return (JsonArray) obj;
}
@Override
public String toString() {
return BeautifyJsonUtils.beautify(this);
}
}
public class JsonArray implements Iterable {
private List list = new ArrayList();
public void add(Object obj) {
list.add(obj);
}
public Object get(int index) {
return list.get(index);
}
public int size() {
return list.size();
}
public JsonObject getJsonObject(int index) {
Object obj = list.get(index);
if (!(obj instanceof JsonObject)) {
throw new JsonTypeException("Type of value is not JsonObject");
}
return (JsonObject) obj;
}
public JsonArray getJsonArray(int index) {
Object obj = list.get(index);
if (!(obj instanceof JsonArray)) {
throw new JsonTypeException("Type of value is not JsonArray");
}
return (JsonArray) obj;
}
@Override
public String toString() {
return BeautifyJsonUtils.beautify(this);
}
public Iterator iterator() {
return list.iterator();
}
}The core logic of the syntax parser is encapsulated in two methods, parseJsonObject and parseJsonArray. Next, I will analyze the parseJsonObject method in detail. Let's analyze the parseJsonArray method ourselves.
The implementation of the parseJsonObject method is as follows:
private JsonObject parseJsonObject() {
JsonObject jsonObject = new JsonObject();
int expectToken = STRING_TOKEN | END_OBJECT_TOKEN;
String key = null;
Object value = null;
while (tokens.hasMore()) {
Token token = tokens.next();
TokenType tokenType = token.getTokenType();
String tokenValue = token.getValue();
switch (tokenType) {
case BEGIN_OBJECT:
checkExpectToken(tokenType, expectToken);
jsonObject.put(key, parseJsonObject()); // Recursive parsing of json object
expectToken = SEP_COMMA_TOKEN | END_OBJECT_TOKEN;
break;
case END_OBJECT:
checkExpectToken(tokenType, expectToken);
return jsonObject;
case BEGIN_ARRAY: // Parsing json array
checkExpectToken(tokenType, expectToken);
jsonObject.put(key, parseJsonArray());
expectToken = SEP_COMMA_TOKEN | END_OBJECT_TOKEN;
break;
case NULL:
checkExpectToken(tokenType, expectToken);
jsonObject.put(key, null);
expectToken = SEP_COMMA_TOKEN | END_OBJECT_TOKEN;
break;
case NUMBER:
checkExpectToken(tokenType, expectToken);
if (tokenValue.contains(".") || tokenValue.contains("e") || tokenValue.contains("E")) {
jsonObject.put(key, Double.valueOf(tokenValue));
} else {
Long num = Long.valueOf(tokenValue);
if (num > Integer.MAX_VALUE || num < Integer.MIN_VALUE) {
jsonObject.put(key, num);
} else {
jsonObject.put(key, num.intValue());
}
}
expectToken = SEP_COMMA_TOKEN | END_OBJECT_TOKEN;
break;
case BOOLEAN:
checkExpectToken(tokenType, expectToken);
jsonObject.put(key, Boolean.valueOf(token.getValue()));
expectToken = SEP_COMMA_TOKEN | END_OBJECT_TOKEN;
break;
case STRING:
checkExpectToken(tokenType, expectToken);
Token preToken = tokens.peekPrevious();
/*
* In JSON, a string can be used as both a key and a value.
* As a key, only the next Token type is expected to be SEP Ou color.
* As a value, the next Token type is expected to be SEP comma or end object
*/
if (preToken.getTokenType() == TokenType.SEP_COLON) {
value = token.getValue();
jsonObject.put(key, value);
expectToken = SEP_COMMA_TOKEN | END_OBJECT_TOKEN;
} else {
key = token.getValue();
expectToken = SEP_COLON_TOKEN;
}
break;
case SEP_COLON:
checkExpectToken(tokenType, expectToken);
expectToken = NULL_TOKEN | NUMBER_TOKEN | BOOLEAN_TOKEN | STRING_TOKEN
| BEGIN_OBJECT_TOKEN | BEGIN_ARRAY_TOKEN;
break;
case SEP_COMMA:
checkExpectToken(tokenType, expectToken);
expectToken = STRING_TOKEN;
break;
case END_DOCUMENT:
checkExpectToken(tokenType, expectToken);
return jsonObject;
default:
throw new JsonParseException("Unexpected Token.");
}
}
throw new JsonParseException("Parse error, invalid Token.");
}
private void checkExpectToken(TokenType tokenType, int expectToken) {
if ((tokenType.getTokenCode() & expectToken) == 0) {
throw new JsonParseException("Parse error, invalid Token.");
}
}The parse process of parseJsonObject method is as follows:
Read a Token and check whether the Token is of the expected type
If so, update the expected Token type. Otherwise, throw an exception and exit
Repeat steps 1 and 2 until all tokens have been resolved or exceptions occur
The above steps are not complicated, but may not be easy to understand. Here is an example to illustrate the following Token sequence:
{, id, :, 1, }After parseJsonObject has parsed {Token, it will expect Token of STRING type or Token of end Ou object type to appear next. So parseJsonObject reads a new Token and finds that the type of the Token is STRING, which meets the expectation.
The parseJsonObject update expects the Token type to be sel'u color, that is:. This cycle continues until the Token sequence parsing ends or an exception is thrown to exit.
Although the above parsing process is not very complex, some details need to be paid attention to in the specific implementation process. For example:
In JSON, strings can be used as both keys and values. As a key, the parser expects the next Token type to be SEP Ou color. As a value, the next Token type is expected to be SEP comma or end object.
Therefore, it is easy to determine whether the string is a key or a value, that is, to determine the type of the last Token. If the previous Token is sep'u color, that is:, then the string here can only be used as a value. Otherwise, it can only be used as a key.
When the Token of Integer type is parsed, the Integer can be directly parsed into Long type by simple point processing. However, considering the problem of space occupation, it is more appropriate for integers in the range of [Integer.min-value, Integer.max-value] to be parsed into Integer, so it is also necessary to pay attention to the process of parsing.
3. Test and effect display
In order to verify the correctness of the code, a simple test of the code is carried out here. The test data comes from Netease music, about 4.5W characters. In order to avoid the problem that the test fails due to the change of data every time the data is downloaded.
I saved the downloaded data in the music.json file. Later, every test will read the data from the file.
As for the test part, no code and screenshots will be posted here. If you are interested, you can download the source code test for fun.
Let's not talk about the test. Let's take a look at the JSON beautification effect display. Here you can simulate any data, just simulate the hero information of Di Renjie in the king's glory (yes, I often use this hero). The following picture:
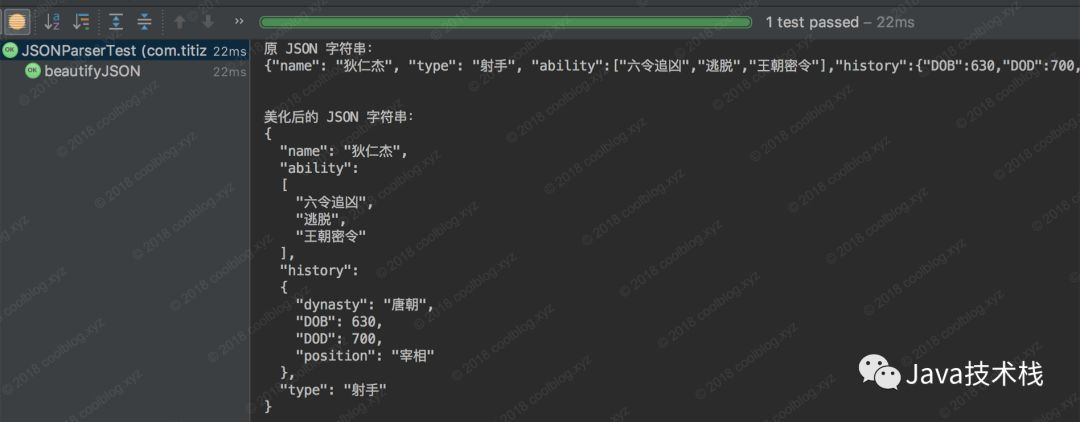
The code about JSON beautification is not explained here. It is not the key point. It is just a colorful egg.
4. Writing last
This is the end of the article. The corresponding code of this article has been put on GitHub. If you need it, you can download it yourself: https://github.com/code4wt/JSONParser.
It needs to be stated here that the code corresponding to this article implements a relatively simple JSON parser, the purpose of which is to explore the parsing principle of JSON. JSONParser is just an exercise project, the code implementation is not elegant, and lack of sufficient testing.
At the same time, limited to my ability (the basic compilation principle can be ignored), I can not guarantee that there are no errors in this article and the corresponding code. If you find some mistakes or bad writing in the process of reading the code, you can bring them up and I will modify them. If you are bothered by these mistakes, let's say sorry first.
Finally, this paper and its implementation mainly refer to two articles about writing a JSON parser together and how to write a JSON parser and the corresponding implementation code of the two articles. Thank the authors of the two articles here. Well, this is the end of the article. Have a good life! Bye.
Author: Tian Xiaobo
www.cnblogs.com/nullllun/p/8358146.html
Reference resources
Write a JSON parser together
http://www.cnblogs.com/absfree/p/5502705.html
How to write a JSON parser
https://www.liaoxuefeng.com/article/994977272296736
Introduce JSON
http://json.org/json-zh.html
What's the idea of writing a JSON, XML, or YAML Parser? www.zhihu.com/question/24640264/answer/80500016
Recommended reading
1.Java JVM, collection, multithreading, new features series
2.Spring MVC, Spring Boot, Spring Cloud series tutorials
3.Maven, Git, Eclipse, Intellij IDEA series tools tutorial
4.Latest interview questions of Java, backend, architecture, Alibaba and other large factories