Configure the programming environment on Hadoop and test sample run
Pre-preparation:
-
Hadoop runs successfully
"Hadoop" Installation of the Sixth Bullet from Zero - Brief Book
http://www.jianshu.com/p/96ed8b7886d2 -
Install the Linux version of eclipse
eclipse-jee-mars-2-linux-gtk-x86_64.tar.gz
Use tar command to decompress under Linux, refer to the previous Hadoop decompression installation -
Copy the hadoop plug-in of eclipse to the plugin folder in the eclipse installation directory
hadoop-eclipse-plugin-2.6.0.jar
Okay, let's start our Hadoop programming tour!
-
Start the hadoop service
$start-all.sh is equivalent to $start-dfs.sh and $start-yarn.sh
-
Setting up hadoop installation path

-
Turn out the elephant in the upper right corner

-
Manually configure Hadoop to create or edit Hadoop location

-
Successful display of files in hdfs

-
Then you can start a new MapReduce project and drive.
Sample Program Running
Open the specified file in HFDS by the given uri and output it to the console
import java.io.InputStream; import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; public class ReadFromFileSystemAPI { public static void main(String[] args) throws Exception{ //File Address String uri = "hdfs://master:9000/input/words.txt"; //Read configuration files Configuration conf = new Configuration(); //Get file system object fs FileSystem fs = FileSystem.get(URI.create(uri), conf); //The second method of obtaining file system //FileSystem fs = FileSystem.newInstance(URI.create(uri), conf); //Create an input stream InputStream in = null; try{ //Call the open method to open the file and output it to the console in = fs.open(new Path(uri)); IOUtils.copyBytes(in, System.out, 4096, false); }finally{ IOUtils.closeStream(in); } } }
console output

Copy the specified folder on Linux to the specified directory on HDFS
import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class CopyFile { public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); String uri = "hdfs://master:9000/"; FileSystem hdfs=FileSystem.get(URI.create(uri),conf); //Local files Path src =new Path("/home/sakura/outout"); //HDFS file Path dst =new Path("/"); //File system calls copy method hdfs.copyFromLocalFile(src, dst); //i do not why it is not hdfs://master:9000 System.out.println("Upload to"+conf.get("fs.defaultFS")); //Get the file directory in hdfs FileStatus files[]=hdfs.listStatus(dst); //Loop out file names in hdfs for(FileStatus file:files){ System.out.println(file.getPath()); } } }
console output
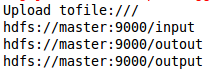
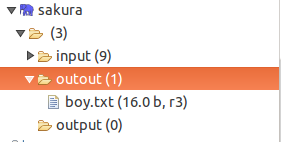
Navigation bar added outout folder
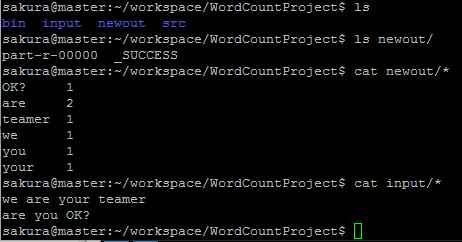
The first MapReduce word count WordCount
Statistics/home/sakura/workspace/WordCountProject
Number of words in the input folder
And output to the newout folder in the same directory
package org.apache.hadoop.examples; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.set("mapred.job.tracker", "192.168.19.131:9001"); String[] ars=new String[]{"input","newout"}; String[] otherArgs = new GenericOptionsParser(conf, ars).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount "); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
Output results
First try to understand the MapReduce process. Usually it is divided into three categories: a startup class contains Map and Reduce; a Map class is responsible for Map work; and a Reduce class is responsible for Reduce work.
After a detailed analysis of the MapReduce program, let me talk about it. This time, the main task is to run the program, follow the knock, and see if the environment is good or not.
Read file content
Read the specified file content through DSDataInputStream and read the output according to a certain offset (6)
This example has no main class and requires JUnit Test to run
import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.log4j.Logger; import org.apache.log4j.PropertyConfigurator; import org.junit.Before; import org.junit.Test; public class TestFSDataInputStream { private FileSystem fs = null; private FSDataInputStream in = null; private String uri = "hdfs://master:9000/input/words.txt"; private Logger log = Logger.getLogger(TestFSDataInputStream.class); static{ PropertyConfigurator.configure("conf/log4j.properties"); } @Before public void setUp() throws Exception { Configuration conf = new Configuration(); fs = FileSystem.get(URI.create(uri), conf); } @Test public void test() throws Exception{ try{ in = fs.open(new Path(uri)); log.info("Document content:"); IOUtils.copyBytes(in, System.out, 4096, false); in.seek(6); Long pos = in.getPos(); log.info("Current offset:"+pos); log.info("Read content:"); IOUtils.copyBytes(in, System.out, 4096, false); byte[] bytes = new byte[10]; int num = in.read(7, bytes, 0, 10); log.info("Read 10 bytes from offset 7 to bytes,Co-reading"+num+"byte"); log.info("Read content:"+(new String(bytes))); //The following code throws EOFException // in.readFully(6, bytes); // in.readFully(6, bytes, 0, 10); }finally{ IOUtils.closeStream(in); } } }
Write the specified file to the HDFS specified directory through creat()
import java.io.BufferedInputStream; import java.io.FileInputStream; import java.io.InputStream; import java.io.OutputStream; import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.util.Progressable; import org.apache.log4j.PropertyConfigurator; import org.junit.Test; public class WriteByCreate { static{ //PropertyConfigurator.configure("conf/log4j.properties"); } @Test public void createTest() throws Exception { String localSrc = "/home/sakura/outout/newboy.txt"; String dst = "hdfs://master:9000/output/newboy.txt"; InputStream in = new BufferedInputStream(new FileInputStream(localSrc)); Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(URI.create(dst), conf); OutputStream out = null; try{ //Call the Create method to create a file out = fs.create(new Path(dst), new Progressable() { public void progress() { System.out.print("."); } }); //Log.info("write start!"); IOUtils.copyBytes(in, out, 4096, true); System.out.println(); //Log.info("write end!"); }finally{ IOUtils.closeStream(in); IOUtils.closeStream(out); } } }
Output results

summary
This time we tried to run a few simple Hadoop examples, test environments, and experience the feeling of programming on Hadoop. Code is not very difficult, but it needs a bit of Java foundation. If you encounter understanding problems in code, please leave a message and ask questions.
PS: Recently, I was working on a small project recommended by Douban Film. MapReduce was used to analyze the data. Ha-ha, wait and see! ____________.