I. overview
It is a reliable, scalable and distributed open source software.
It is a framework that allows large data and distributed processing across clusters of computers, using a simple programming model (mapreduce)
It can be extended from a single server to thousands of hosts, and each node provides computing and storage functions.
Hardware-independent HA implementation at application level
Volume is large
velocity
variaty
Low value density
hadoop common class library, supporting other modules
HDFS, hadoop distributed file system, hadoop distributed file system
Hadoop yarn Job Scheduling and Resource Management Framework
Haoop MapReduce is a parallel processing technology for large data sets based on yarn system.
II. Installation and Deployment
2.1 Host Planning
| Host name | IP address | Installation node application |
|---|---|---|
| hadoop-1 | 172.20.2.203 | namenode/datanode/nodemanager |
| hadoop-2 | 172.20.2.204 | secondarynode/datanode/nodemanager |
| hadoop-3 | 172.20.2.205 | resourcemanager/datanode/nodemanager |
2.2 deployment
2.2.1 Basic Environment Configuration
a. Configuring the java environment
yum install java-1.8.0-openjdk.x86_64 java-1.8.0-openjdk-devel -y cat >/etc/profile.d/java.sh<<EOF export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-3.b14.el6_9.x86_64 export CLASSPATH=.:\$JAVA_HOME/jre/lib/rt.jar:\$JAVA_HOME/lib/dt.jar:\$JAVA_HOME/lib/tools.jar export PATH=\$PATH:\$JAVA_HOME/bin EOF source /etc/profile.d/java.sh
b. Modify the host name to add hosts
hostname hadoop-1 cat >>/etc/hosts<<EOF 172.20.2.203 hadoop-1 172.20.2.204 hadoop-2 172.20.2.205 hadoop-3 EOF
c. Creating Users and Directories
useradd hadoop
echo "hadoopwd" |passwd hadoop --stdin
mkdir -pv /data/hadoop/hdfs/{nn,snn,dn}
chown -R hadoop:hadoop /data/hadoop/hdfs/
mkdir -p /var/log/hadoop/yarn
mkdir -p /dbapps/hadoop/logs
chmod g+w /dbapps/hadoop/logs/
chown -R hadoop.hadoop /dbapps/hadoop/
d. Configuring hadoop environment variables
cat>/etc/profile.d/hadoop.sh<<EOF
export HADOOP_PREFIX=/usr/local/hadoop
export PATH=\$PATH:\$HADOOP_PREFIX/bin:\$HADOOP_PREFIX/sbin
export HADOOP_COMMON_HOME=\${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=\${HADOOP_PREFIX}
export HADOOP_MAPRED_HOME=\${HADOOP_PREFIX}
export HADOOP_YARN_HOME=\${HADOOP_PREFIX}
EOF
source /etc/profile.d/hadoop.sh
e. Download and decompress the package
mkdir /software cd /software wget -c http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz tar -zxf hadoop-2.6.5.tar.gz -C /usr/local ln -sv /usr/local/hadoop-2.6.5/ /usr/local/hadoop chown hadoop.hadoop /usr/local/hadoop-2.6.5/ -R
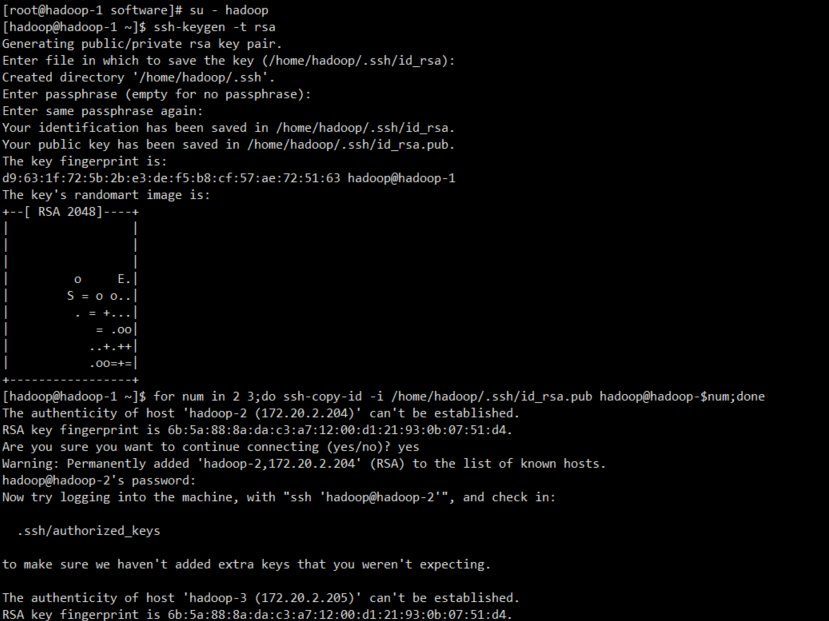
f.hadoop user key-free configuration
su - hadoop ssh-keygen -t rsa for num in `seq 1 3`;do ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@hadoop-$num;done
2.3 Configure hadoop
2.3.1 Configuration of nodes
Configure master node
The hadoop-1 node runs namenode/datanode/nodemanager and modifies the Hadoop configuration file for hadoop-1
core-site.xml (defining namenode nodes)
cat>/usr/local/hadoop/etc/hadoop/core-site.xml <<EOF <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-1:8020</value> <final>true</final> </property> </configuration> EOF
hdfs-site.xml modifies replication to the number of data nodes (defining secondary nodes)
cat >/usr/local/hadoop/etc/hadoop/hdfs-site.xml <<EOF <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop-2:50090</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///data/hadoop/hdfs/nn</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///data/hadoop/hdfs/dn</value> </property> <property> <name>fs.checkpoint.dir</name> <value>file:///data/hadoop/hdfs/snn</value> </property> <property> <name>fs.checkpoint.edits.dir</name> <value>file:///data/hadoop/hdfs/snn</value> </property> </configuration> EOF
Add mapred-site.xml
cat >/usr/local/hadoop/etc/hadoop/mapred-site.xml <<EOF <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> EOF
yarn-site.xml modifies the host name corresponding to values as master (defines the resourcemanager node)
cat >/usr/local/hadoop/etc/hadoop/yarn-site.xml<<EOF <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>yarn.resourcemanager.address</name> <value>hadoop-3:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>hadoop-3:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>hadoop-3:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>hadoop-3:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>hadoop-3:8088</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.auxservices.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> </property> </configuration> EOF
Slaves (Defining data nodes)
cat >/usr/local/hadoop/etc/hadoop/slaves<<EOF hadoop-1 hadoop-2 hadoop-3 EOF
The same procedure operates on hadoop-2/3. It is recommended that the files of hadoop-1 be distributed directly to hadoop-2/3.
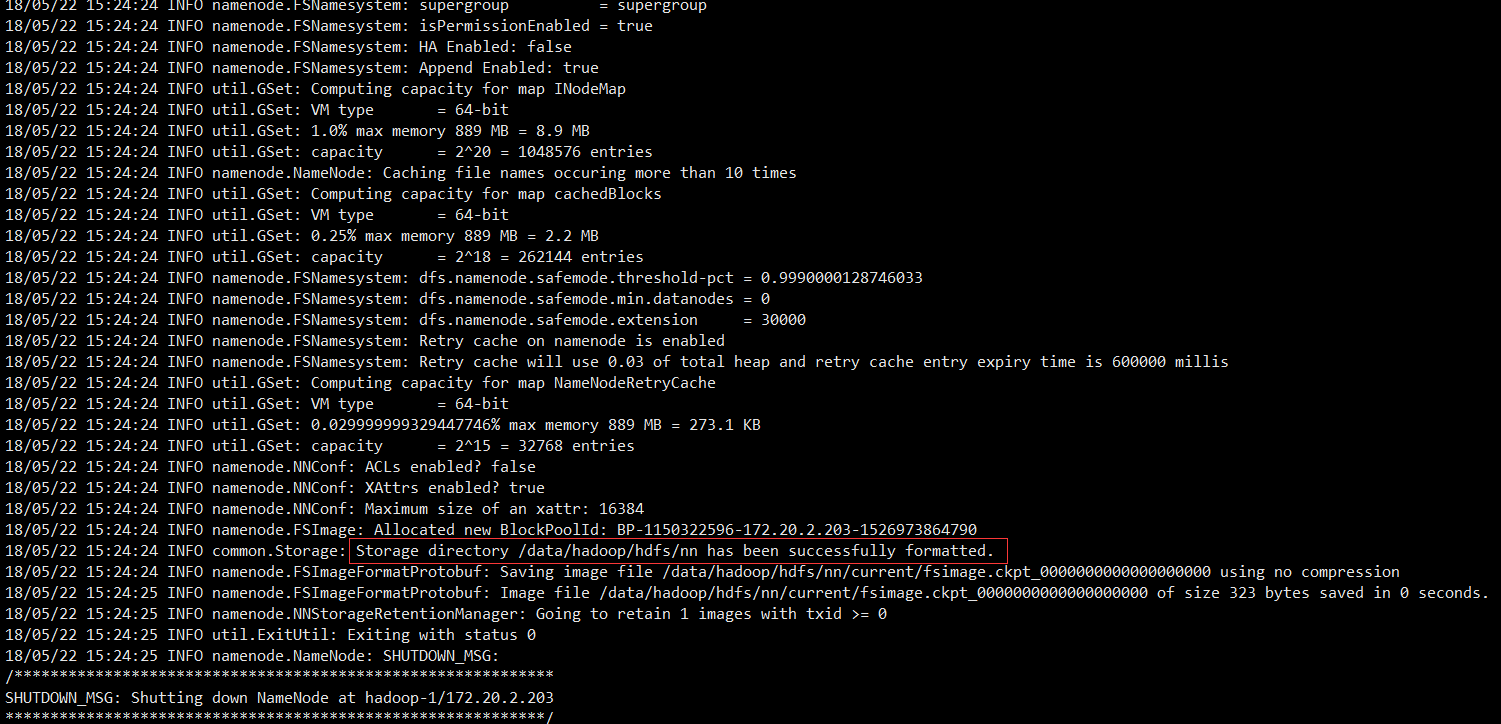
2.3.2 Format namenode
Perform formatting on the NameNode machine (hadoop-1):
hdfs namenode -format


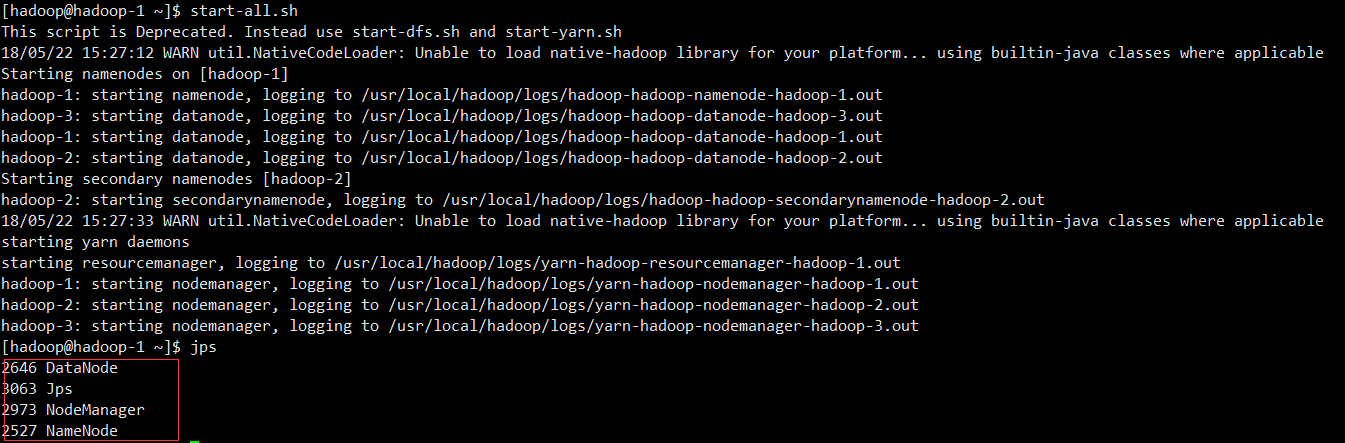
2.3.3 Startup Services
Execute start-all.sh startup service in namenode hadoop-1
Start the resource manager service in hadoop-3``
hadoop-2 service view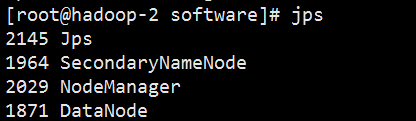
hadoop-3 service view
2.3.4 Running Test Program
yarn jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar pi 2 10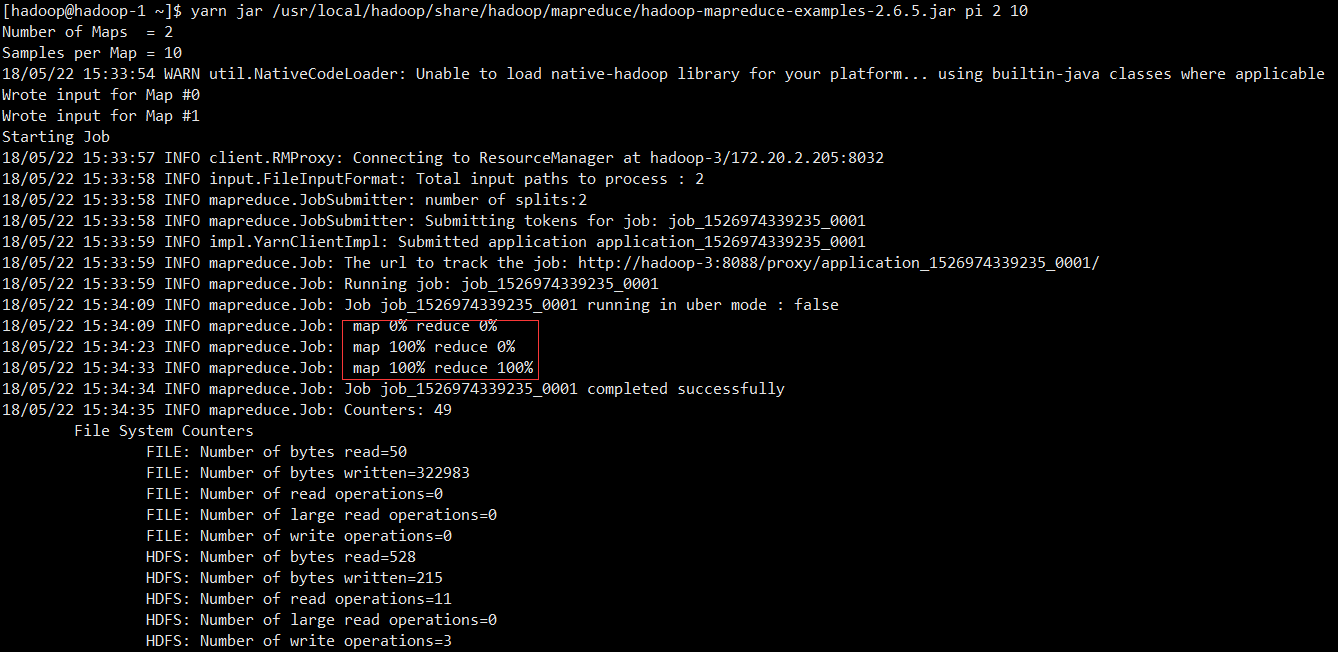
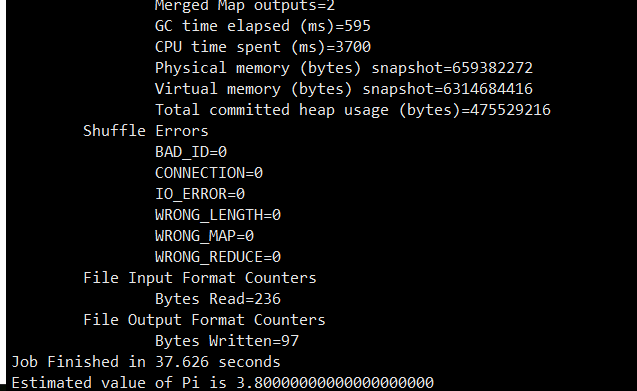
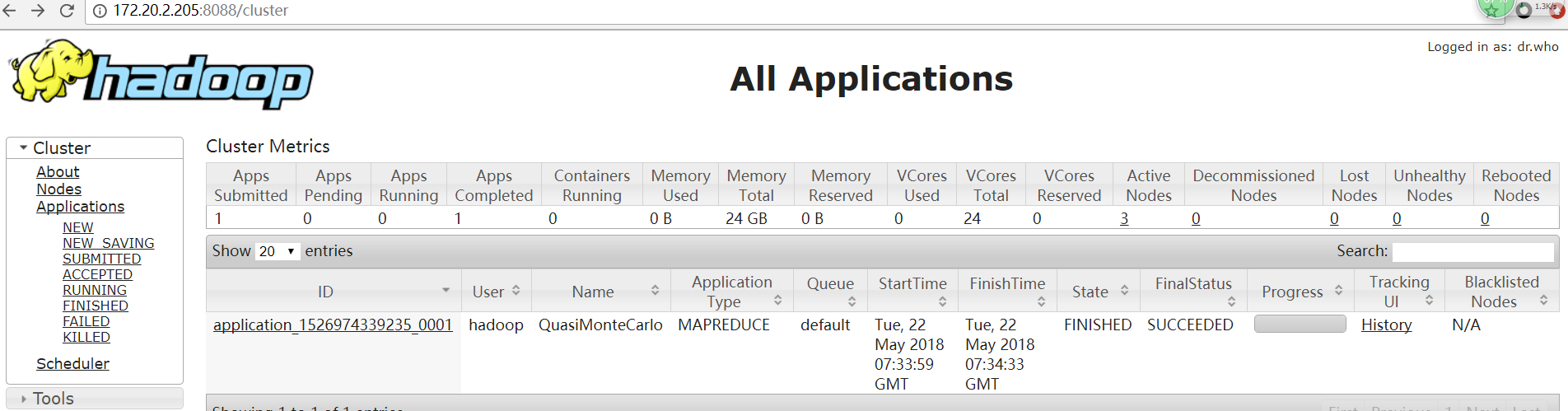
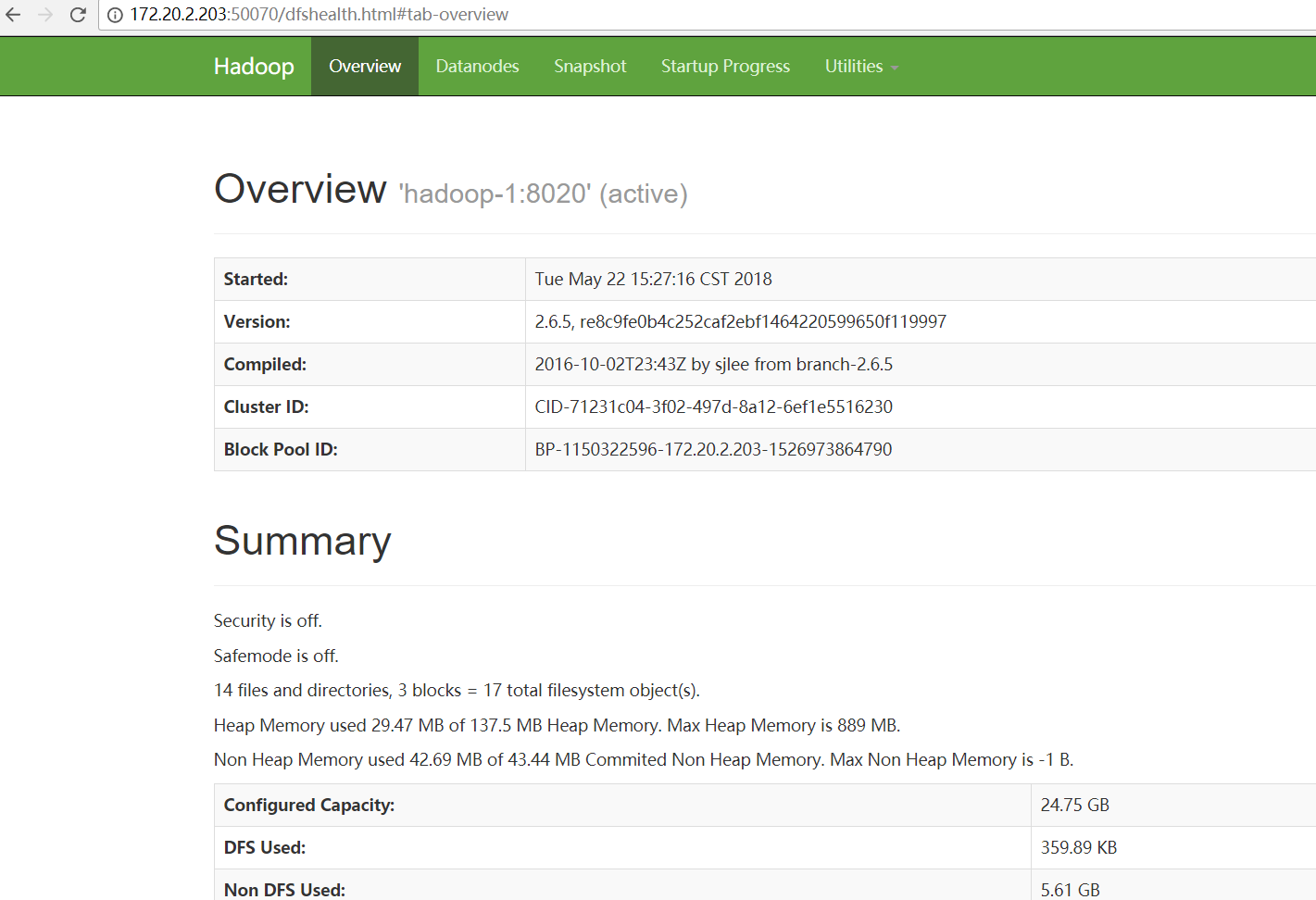
2.3.5 View web Interface
HDFS-NameNode
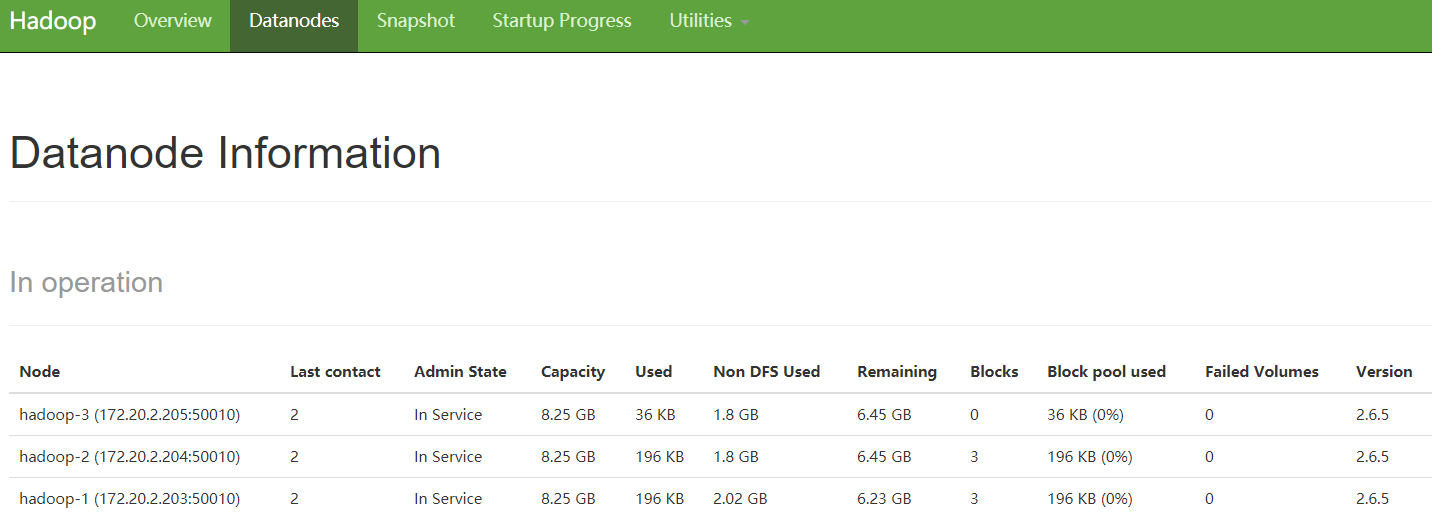
YARN-ResourceManager