objective
The purpose of grpool is to control the number of goroutines to execute tasks, so as to avoid creating too many goroutines and causing the memory consumption to soar
Simple use
func UseWorkerPool() {
pool := grpool.NewPool(100, 50)
defer pool.Release()
for i := 0; i < 10; i++ {
count := i
pool.JobQueue <- func() {
fmt.Printf("I am worker! Number %d\n", count)
}
}
time.Sleep(1 * time.Second)
}
Source code analysis
Key API s
func NewPool(numWorkers int, jobQueueLen int) *Pool func (p *Pool) Release()
NewPool: create a worker goroutine pool. numWorkers represents the number of workers created in the pool. jobQueueLen represents the number of tasks that can be received. If it is full, it will be blocked
Pool.Release: release the worker goroutine created in the pool. Note that the job in the jobQueue is not released here
data structure

Pool
goroutine pool, which contains three attributes: JobQueue, Dispatcher and wg
JobQueue: task queue. All tasks are executed in first in first out order. Dispatcher and Pool share a JobQueue
Dispatcher: task distributor, which is responsible for fetching idle workers from the workerPool, fetching jobs from the jobQueue, and handing the jobs to the workers for execution
wg: used for task blocking and waiting
Job
The task to be executed is a method with no parameters and no return value
dispatcher
The task distributor contains three attributes: workerPool, jobQueue and stop
workerPool: worker queue
jobQueue: task queue
Stop: bufferless channel, used to transmit stop signal
worker
The goroutine that executes the task contains three attributes: workerPool, jobChannel and stop
workerPool: worker queue. The source code process will be explained later. Why does the worker refer to the worker queue
jobChannel: the unbuffered channel of the worker itself, which is used to transmit the tasks to be executed by the worker
Stop: bufferless channel, used to transmit stop signal
Key API source code analysis
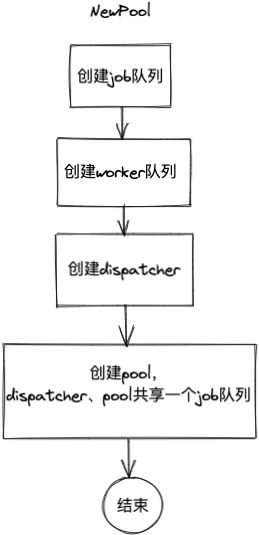
NewPool
func NewPool(numWorkers int, jobQueueLen int) *Pool {
jobQueue := make(chan Job, jobQueueLen)
workerPool := make(chan *worker, numWorkers)
pool := &Pool{
JobQueue: jobQueue,
dispatcher: newDispatcher(workerPool, jobQueue),
}
return pool
}
Create a job queue, a worker Pool, then a dispatcher task distributor, and finally a Pool object
Here newDispatcher is the key
newDispatcher
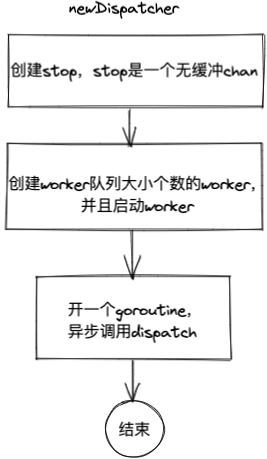
func newDispatcher(workerPool chan *worker, jobQueue chan Job) *dispatcher {
d := &dispatcher{
workerPool: workerPool,
jobQueue: jobQueue,
stop: make(chan struct{}),
}
for i := 0; i < cap(d.workerPool); i++ {
worker := newWorker(d.workerPool)
worker.start()
}
go d.dispatch()
return d
}
Create a dispatcher object, then create a specified number of workers and start workers. Finally, start a goroutine for task distribution
newWorker
func newWorker(pool chan *worker) *worker {
return &worker{
workerPool: pool,
jobChannel: make(chan Job),
stop: make(chan struct{}),
}
}
Create a worker object. The workerPool refers to the previously created worker pool object. jobChannel and stop create their own unbuffered channel
worker.start
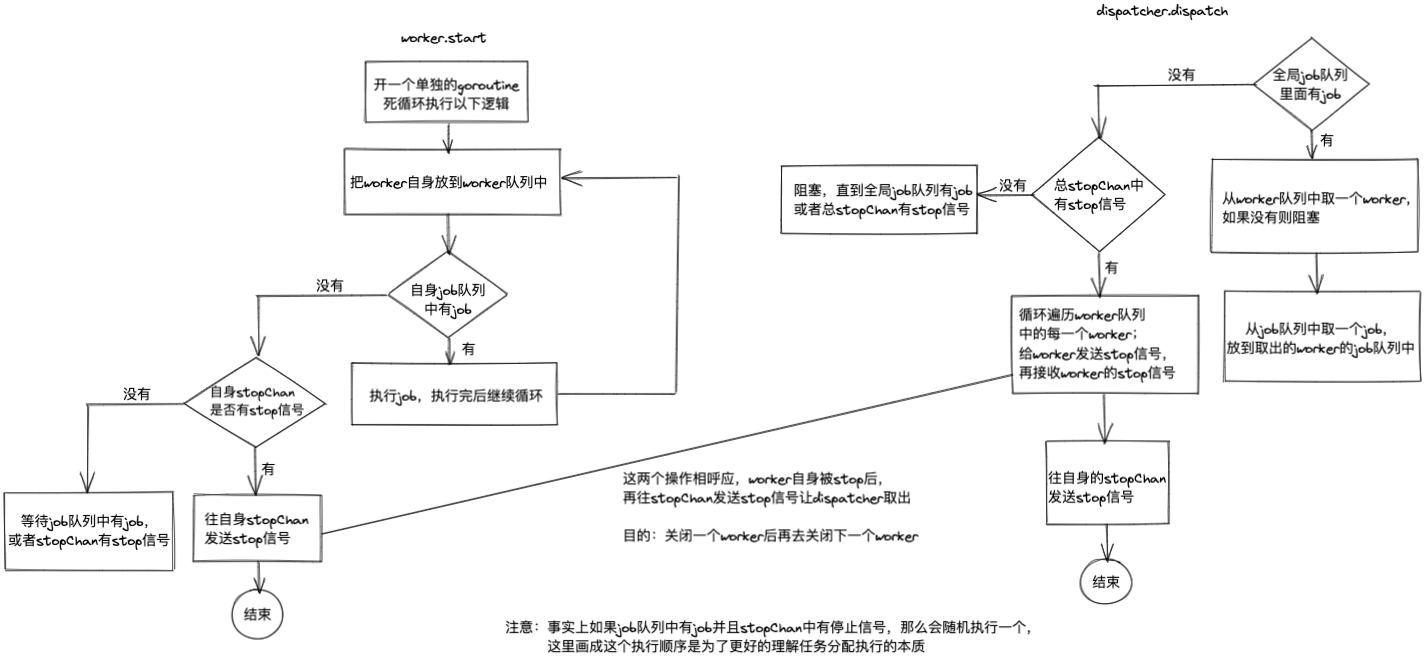
func (w *worker) start() {
go func() {
var job Job
for {
// worker free, add it to pool
w.workerPool <- w
select {
case job = <-w.jobChannel:
job()
case <-w.stop:
w.stop <- struct{}{}
return
}
}
}()
}
In the dead loop, put yourself into the worker pool. If there are jobs in your job queue, take out the job for execution. If there are no jobs but there is a stop signal in stopChan, take out the stop signal and send a stop signal to stopChan
Here are a few points to note:
1) If there is a task in jobChannel and a stop signal in stopchannel, in fact, a path is selected randomly for execution
2) Each cycle puts the worker itself into the workerPool, so when will it be taken out?
3) The worker has received a stop signal from stopChan. Why send a stop signal to stopChan?
The answers to 2 and 3 are in the next dispatcher.dispatch method, so I also put the flowchart of worker.start in the following dispatcher.dispatch method explanation
dispatcher.dispatch
func (d *dispatcher) dispatch() {
for {
select {
case job := <-d.jobQueue:
worker := <-d.workerPool
worker.jobChannel <- job
case <-d.stop:
for i := 0; i < cap(d.workerPool); i++ {
worker := <-d.workerPool
worker.stop <- struct{}{}
<-worker.stop
}
d.stop <- struct{}{}
return
}
}
}
Dead loop: if there is a job in the job queue, get the idle worker from the workerPool. If not, block and wait all the time. If it is obtained, throw the job into the worker's own job queue; If there is no job in the job queue and there is a stop signal in stopChan, send a stop signal to each worker's stopChan to stop the worker. After sending a stop signal to each worker, receive a stop signal from the worker's stopChan again before continuing to stop the next worker. After all workers stop, Send a stop signal to the dispatcher's own stopChan and end
Here are some key points:
1) If there is a task in jobQueue and a stop signal in stopChan, in fact, a path is selected randomly for execution
2) When the dispatcher distributes tasks, it takes a worker from the workerPool and then distributes the tasks to the worker. Here is the answer to the second concern above, and it is also the way that the dispatcher and the worker handle job s together
3) After stopping a worker, you should receive the stop signal from the worker's stopChan before continuing to stop the next worker. This is echoed with the third concern above to ensure that the next worker is closed after one worker is closed
4) After all worker s stop, why does the dispatcher send a stop signal to its stopChan before returning? The answer to this question will be given in the following Pool.Release method
Pool.Release
func (p *Pool) Release() {
p.dispatcher.stop <- struct{}{}
<-p.dispatcher.stop
}
Release all worker s in the workerPool
After sending the stop signal to the dispatcher's stopChan, you need to receive a stop signal from the dispatcher's stopChan again before returning. This echoes the fourth key point above. The purpose is to ensure that the Release method returns only after all worker s in the workerPool are released
summary
The design of the whole grpool is relatively simple. The key is to understand how the two methods of worker.start and dispatcher.dispatch cooperate in job distribution and job execution