Reference page:
http://www.yuanjiaocheng.net/CSharp/Csharp-data-types.html
http://www.yuanjiaocheng.net/CSharp/cshart-value-reference-type.html
http://www.yuanjiaocheng.net/CSharp/Csharp-keys.html
http://www.yuanjiaocheng.net/CSharp/csharp-interface.html
http://www.yuanjiaocheng.net/CSharp/Csharp-operators.html
Starting with the title, why is it no longer difficult to grab website data (in fact, it is difficult to grab website data), SO EASY!!! With Fizzler, I believe that most people or companies should have the experience of grabbing other people's website data. For example, every time our blog Park publishes an article, it will be grabbed by other websites. If you don't believe it, you can see it. Others grab useful information such as mailboxes, phone numbers, QQ on other people's websites, which can definitely sell money or do other things. We receive spam messages or e-mails from time to time every day. Maybe that's the same thing. O() Ohaha ~.
I wrote two programs a while ago, one is to grab the data of a lottery website (double-color ball), the other is to grab the data of job-hunting website (hunting, future-free, recruitment and so on). When writing these two programs, it was particularly difficult to see a bunch of HTML tags really want to die. First of all, let's review how I parsed HTML before. It's a very conventional way to get HTML content through WebRequest, and then to intercept what you want step by step through HTML tags. The following code is the code for intercepting red balls and basketball for two-color balls. Once the label of the website changes a little, it may be faced with the need to re-program, which is very inconvenient to use.
The following is my code for analyzing the red ball and basketball of the two-color ball. The most I do is to intercept the corresponding content of the tag (regular expression). Maybe this code is not very complicated, because the intercepted data is limited and very regular, so it is relatively simple.
1 #region * In one TR Analysis of TD,Get the number of Phase I 2 /// <summary> 3 /// In one TR Analysis of TD,Get the number of Phase I 4 /// </summary> 5 /// <param name="wn"></param> 6 /// <param name="trContent"></param> 7 private void ResolveTd(ref WinNo wn, string trContent) 8 { 9 List<int> redBoxList = null; 10 //Expression of Matching Period Number 11 string patternQiHao = "<td align=\"center\" title=\"Date"; 12 Regex regex = new Regex(patternQiHao); 13 Match qhMatch = regex.Match(trContent); 14 wn.QiHao = trContent.Substring(qhMatch.Index + 17 + patternQiHao.Length, 7); 15 //The expression of matching basketball 16 string patternChartBall02 = "<td class=\"chartBall02\">"; 17 regex = new Regex(patternChartBall02); 18 Match bMatch = regex.Match(trContent); 19 wn.B = Convert.ToInt32(trContent.Substring(bMatch.Index + patternChartBall02.Length, 2)); 20 //Store matched red ball numbers 21 redBoxList = new List<int>(); 22 //The expression of matching red ball 23 string patternChartBall01 = "<td class=\"chartBall01\">"; 24 regex = new Regex(patternChartBall01); 25 MatchCollection rMatches = regex.Matches(trContent); 26 foreach (Match r in rMatches) 27 { 28 redBoxList.Add(Convert.ToInt32(trContent.Substring(r.Index + patternChartBall01.Length, 2))); 29 } 30 //The expression of matching red ball 31 string patternChartBall07 = "<td class=\"chartBall07\">"; 32 regex = new Regex(patternChartBall07); 33 rMatches = regex.Matches(trContent); 34 foreach (Match r in rMatches) 35 { 36 redBoxList.Add(Convert.ToInt32(trContent.Substring(r.Index + patternChartBall07.Length, 2))); 37 } 38 //Sort Red Ball Number 39 redBoxList.Sort(); 40 //First Red Ball Number 41 wn.R1 = redBoxList[0]; 42 //Second Red Ball Number 43 wn.R2 = redBoxList[1]; 44 wn.R3 = redBoxList[2]; 45 wn.R4 = redBoxList[3]; 46 wn.R5 = redBoxList[4]; 47 wn.R6 = redBoxList[5]; 48 }
The following code is the interception data of a recruitment website, that is, a series of intercepting HTML tags. Haha, at that time, it was quite a headache to write. I wonder if anyone who did this method felt the same way. When you parse the data of more websites, it is even more important (I wrote the data of grasping the future without worry, hunting for employment, future without worry and pulling the net). O() O() O() O() O() O() O() O() O() O() O() O
// Regular expression filtering: Regular expression, text to be replaced private static readonly string[][] Filters = { new[] { @"(?is)<script.*?>.*?</script>", "" }, new[] { @"(?is)<style.*?>.*?</style>", "" }, new[] { @"(?is)<!--.*?-->", "" }, // filter Html Comments in code new[] { @"(?is)<footer.*?>.*?</footer>",""}, //new[] { "(?is)<div class=\"job-require bottom-job-require\">.*?</div></div>",""} new[] { @"(?is)<h3>Common links:.*?</ul>",""} }; private void GetJobInfoFromUrl(string url) { try { JobInfo info = new JobInfo(); //-- string pageStr = GetHtmlCode.GetByget(url, "utf-8"); if (string.IsNullOrEmpty(pageStr)) { return; } //-- pageStr = pageStr.Replace("\r\n", "");//Replace line breaks // Obtain html,body Label content string body = string.Empty; string bodyFilter = @"(?is)<body.*?</body>"; Match m = Regex.Match(pageStr, bodyFilter); if (m.Success) { body = m.ToString().Replace("<tr >", "<tr>").Replace("\r\n", ""); } // Uncorrelated labels such as filtering styles, scripts, etc. foreach (var filter in Filters) { body = Regex.Replace(body, filter[0], filter[1]); } //-- if (!string.IsNullOrEmpty(mustKey) && !body.Contains(mustKey)) { return; } body = Regex.Replace(body, "\\s", ""); info.Url = url; string basicInfoRegexStr0 = "<h1title=([\\s\\S]+?)>(.*?)</h1>"; //Job title string position = Regex.Match(body, basicInfoRegexStr0).Value; info.Position = string.IsNullOrEmpty(position) ? "" : position.Substring(position.IndexOf(">") + 1, position.IndexOf("</") - position.IndexOf(">") - 1);//Job title string basicInfoRegexStr1 = "</h1><h3>(.*?)</h3>";//Corporate name string company = Regex.Match(body, basicInfoRegexStr1).Value; info.Company = string.IsNullOrEmpty(company) ? "" : company.Substring(company.IndexOf("<h3>") + 4, company.IndexOf("</h3>") - company.IndexOf("<h3>") - 4);//Corporate name string basicInfoRegexStr2 = "<divclass=\"resumeclearfix\"><span>(.*?)</span>";//Working place string address = Regex.Match(body, basicInfoRegexStr2).Value; info.Address = string.IsNullOrEmpty(address) ? "" : address.Substring(address.IndexOf("<span>") + 6, address.IndexOf("</") - address.IndexOf("<span>") - 6);//Working place string basicInfoRegexStr3 = "<li><span>Enterprise nature:</span>(.*?)</li>";//Company nature string nature = Regex.Match(body, basicInfoRegexStr3).Value; info.Nature = string.IsNullOrEmpty(nature) ? "" : nature.Substring(nature.IndexOf("</span>") + 7, nature.IndexOf("</li>") - nature.IndexOf("</span>") - 7);//Company nature if (string.IsNullOrEmpty(info.Nature)) { string basicInfoRegexStr3_1 = "<br><span>Nature:</span>(.*?)<br>"; string nature_1 = Regex.Match(body, basicInfoRegexStr3_1).Value; info.Nature = string.IsNullOrEmpty(nature_1) ? "" : nature_1.Substring(nature_1.IndexOf("</span>") + 7, nature_1.LastIndexOf("<br>") - nature_1.IndexOf("</span>") - 7);//Company nature } string basicInfoRegexStr4 = "<li><span>Enterprise size:</span>(.*?)</li>";//company size string scale = Regex.Match(body, basicInfoRegexStr4).Value; info.Scale = string.IsNullOrEmpty(scale) ? "" : scale.Substring(scale.IndexOf("</span>") + 7, scale.IndexOf("</li>") - scale.IndexOf("</span>") - 7);//company size if (string.IsNullOrEmpty(info.Scale)) { string basicInfoRegexStr4_1 = "<br><span>Scale:</span>(.*?)<br>"; string scale_1 = Regex.Match(body, basicInfoRegexStr4_1).Value; info.Scale = info.Nature = string.IsNullOrEmpty(scale_1) ? "" : scale_1.Substring(scale_1.IndexOf("</span>") + 7, scale_1.LastIndexOf("<br>") - scale_1.IndexOf("</span>") - 7);//company size } string basicInfoRegexStr5 = "<spanclass=\"noborder\">(.*?)</span>";//Hands-on background string experience = Regex.Match(body, basicInfoRegexStr5).Value; info.Experience = string.IsNullOrEmpty(experience) ? "" : experience.Substring(experience.IndexOf(">") + 1, experience.IndexOf("</") - experience.IndexOf(">") - 1);//Hands-on background string basicInfoRegexStr6 = "</span><span>(.*?)</span><spanclass=\"noborder\">";//Minimum academic qualifications string education = Regex.Match(body, basicInfoRegexStr6).Value; info.Education = string.IsNullOrEmpty(education) ? "" : education.Substring(education.IndexOf("<span>") + 6, education.IndexOf("</span><spanclass=") - education.IndexOf("<span>") - 6);//Minimum academic qualifications string basicInfoRegexStr7 = "<pclass=\"job-main-title\">(.*?)<";//A monthly salary string salary = Regex.Match(body, basicInfoRegexStr7).Value; info.Salary = string.IsNullOrEmpty(salary) ? "" : salary.Substring(salary.IndexOf(">") + 1, salary.LastIndexOf("<") - salary.IndexOf(">") - 1);//A monthly salary string timeInfoRegexStr = "<pclass=\"release-time\">Release time:<em>(.*?)</em></p>";//Release time string time = Regex.Match(body, timeInfoRegexStr).Value; info.Time = string.IsNullOrEmpty(time) ? "" : time.Substring(time.IndexOf("<em>") + 4, time.IndexOf("</em>") - time.IndexOf("<em>") - 4);//Release time if (GetJobEnd != null) { GetJobEnd(pageStr, info); } } catch (Exception exMsg) { throw new Exception(exMsg.Message); } } }
From the above code, we can see that they are intercepting (regular expressions) the corresponding content, which is very complex. It is very difficult to intercept website data without paying attention to it. Finally, Fizzler is used to extract website data through the introduction of friends in QQ group (186841119). It feels much easier at once. Here's how to introduce Fizzler. Tools (as if this is open source), related information can be found on the website.
First, provide the download address of the tool: Fizzler
This includes three files: Fizzler.dll, Fizzler.Systems.HtmlAgilityPack.dll and HtmlAgilityPack.dll, which can be referenced directly in VS2010.
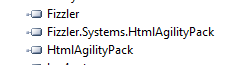
Completing the above is the reference to Fizzler.
using HtmlAgilityPack; using Fizzler; using Fizzler.Systems.HtmlAgilityPack;
The above can be cited in CS.
The following is the implementation of the code.
private static WebDownloader m_wd = new WebDownloader(); /// <summary> /// Obtain HTML content /// </summary> /// <param name="Url">link</param> /// <param name="Code">character set</param> /// <returns></returns> public static string GetHtml(string Url, Encoding Code) { return m_wd.GetPageByHttpWebRequest(Url, Code); } public string GetPageByHttpWebRequest(string url, Encoding encoding) { Stream sr = null; StreamReader sReader = null; try { HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url); request.Method = "Get"; request.Timeout = 30000; HttpWebResponse response = request.GetResponse() as HttpWebResponse; if (response.ContentEncoding.ToLower() == "gzip")//If used GZip First decompression. { sr = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress); } else { sr = response.GetResponseStream(); } sReader = new StreamReader(sr, encoding); return sReader.ReadToEnd(); } catch { return null; } finally { if (sReader != null) sReader.Close(); if (sr != null) sr.Close(); } }
The above is the implementation of HTML data grabbing code, the above code is basically no difference, that is, the common method of grabbing data.
/// <summary> /// Get the corresponding label content /// </summary> /// <param name="Url">link</param> /// <param name="CSSLoad">CSS Route</param> /// <param name="Code">character set</param> /// <returns></returns> public static IEnumerable<HtmlNode> GetUrlInfo(string Url, string CSSLoad, Encoding Code) { HtmlAgilityPack.HtmlDocument htmlDoc = new HtmlAgilityPack.HtmlDocument { OptionAddDebuggingAttributes = false, OptionAutoCloseOnEnd = true, OptionFixNestedTags = true, OptionReadEncoding = true }; htmlDoc.LoadHtml(GetHtml(Url, Code)); IEnumerable<HtmlNode> NodesMainContent = htmlDoc.DocumentNode.QuerySelectorAll(CSSLoad);//Query Path return NodesMainContent; } /// <summary> /// Get the corresponding label content /// </summary> /// <param name="html">html content</param> /// <param name="CSSLoad">CSS Route</param> /// <returns></returns> public static IEnumerable<HtmlNode> GetHtmlInfo(string html, string CSSLoad) { HtmlAgilityPack.HtmlDocument htmlDoc = new HtmlAgilityPack.HtmlDocument { OptionAddDebuggingAttributes = false, OptionAutoCloseOnEnd = true, OptionFixNestedTags = true, OptionReadEncoding = true }; htmlDoc.LoadHtml(html); IEnumerable<HtmlNode> NodesMainContent = htmlDoc.DocumentNode.QuerySelectorAll(CSSLoad);//Query Path return NodesMainContent; }
The above two methods are to capture the corresponding path label data. One is to capture the corresponding path label data according to the URL, the other is to capture the corresponding data according to the HTML content. The following focuses on the acquisition method of CSSLoad, which requires the installation of Firefox Browser. FireBug plug-in is needed to query Firefox Browser, as shown in the following figure (website toolbar):

Then click on the spider-like icon to see the following:
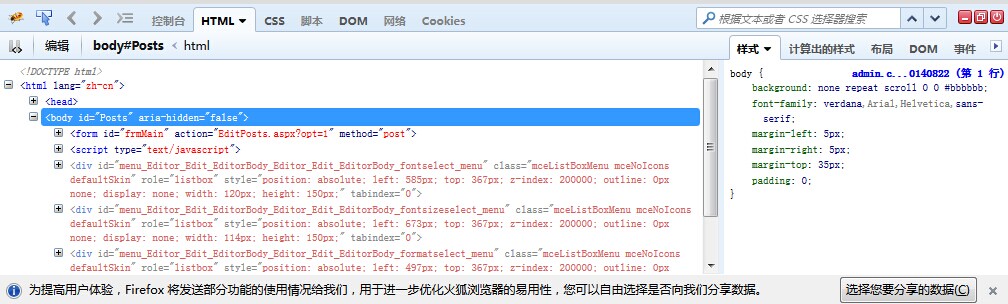
So you can see all the HTML tags, and then how to get the CSS path is relatively simple.
Click on the blue arrow to select the relevant content of the website.
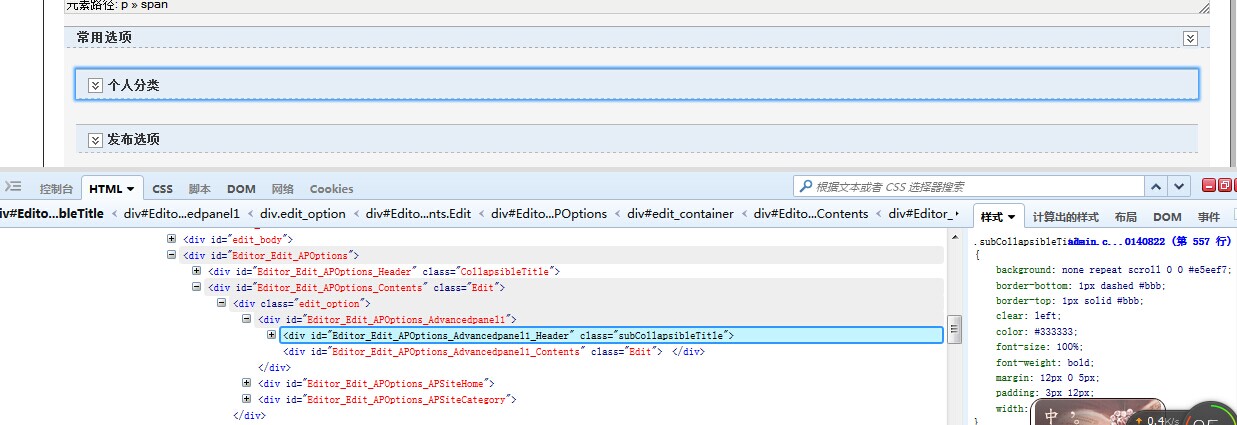
So the corresponding HTML is also selected, which is a step closer to getting the CCS path, and then click the right button to copy the CCS path. As follows:
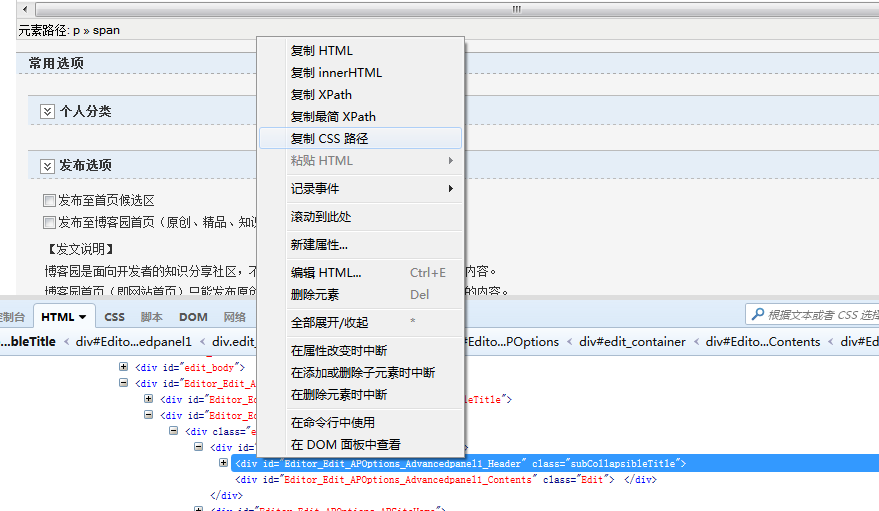
Just click on the copy CSS path. Copy the CSS path as follows:
html body#Posts form#frmMain table#BodyTable tbody tr td#Body div#Main div#Editor_Edit div#Editor_Edit_Contents div#edit_container div#Editor_Edit_APOptions div#Editor_Edit_APOptions_Contents.Edit div.edit_option div#Editor_Edit_APOptions_Advancedpanel1 div#Editor_Edit_APOptions_Advancedpanel1_Header.subCollapsibleTitle
We don't need to copy all these paths into our program. Otherwise, it's too responsible. We just need to put the last part of the nodes in the method above. We can read the corresponding content of the HTML tag. Here's a simple example to illustrate.
1 /// <summary> 2 /// Analysis of each recruitment information 3 /// </summary> 4 /// <param name="Url"></param> 5 private void GetJobInfoFromUrl(object Url) 6 { 7 try 8 { 9 JobInfo info = new JobInfo(); 10 info.Url = Url.ToString(); 11 //--Obtain HTML content 12 string html =AnalyzeHTML.GetHtml(Url.ToString(), Encoding.UTF8); 13 if (string.IsNullOrEmpty(html)) { return; } 14 //--Job title 15 IEnumerable<HtmlNode> NodesMainContent1 = AnalyzeHTML.GetHtmlInfo(html, "div.title-info h1"); 16 if(NodesMainContent1.Count()>0) 17 { 18 info.Position = NodesMainContent1.ToArray()[0].InnerText; 19 } 20 //--Corporate name 21 IEnumerable<HtmlNode> NodesMainContent2 = AnalyzeHTML.GetHtmlInfo(html, "div.title-info h3"); 22 if (NodesMainContent2.Count() > 0) 23 { 24 info.Company = NodesMainContent2.ToArray()[0].InnerText; 25 } 26 //--Company nature/company size 27 IEnumerable<HtmlNode> NodesMainContent4 = AnalyzeHTML.GetHtmlInfo(html, "div.content.content-word ul li"); 28 if (NodesMainContent4.Count() > 0) 29 { 30 foreach (var item in NodesMainContent4) 31 { 32 if (item.InnerHtml.Contains("Nature of enterprise")) 33 { 34 string nature = item.InnerText; 35 nature = nature.Replace("Enterprise nature:", ""); 36 info.Nature = nature; 37 } 38 if (item.InnerHtml.Contains("Enterprise scale")) 39 { 40 string scale = item.InnerText; 41 scale = scale.Replace("Enterprise size:", ""); 42 info.Scale = scale; 43 } 44 } 45 } 46 else//Second Analysis of the Nature and Scale of Enterprises 47 { 48 IEnumerable<HtmlNode> NodesMainContent4_1 = AnalyzeHTML.GetHtmlInfo(html, "div.right-post-top div.content.content-word"); 49 if (NodesMainContent4_1.Count() > 0) 50 { 51 foreach (var item_1 in NodesMainContent4_1) 52 { 53 string[] arr = item_1.InnerText.Split("\r\n".ToCharArray(), StringSplitOptions.RemoveEmptyEntries); 54 if (arr != null && arr.Length > 0) 55 { 56 foreach (string str in arr) 57 { 58 if (str.Trim().Contains("Nature")) 59 { 60 info.Nature = str.Replace("Nature:", "").Trim(); 61 } 62 if (str.Trim().Contains("scale")) 63 { 64 info.Scale = str.Replace("Scale:", "").Trim(); 65 } 66 } 67 } 68 } 69 } 70 } 71 //--Hands-on background 72 IEnumerable<HtmlNode> NodesMainContent5 = AnalyzeHTML.GetHtmlInfo(html, "div.resume.clearfix span.noborder"); 73 if (NodesMainContent5.Count() > 0) 74 { 75 info.Experience = NodesMainContent5.ToArray()[0].InnerText; 76 } 77 //--Company address/Minimum academic qualifications 78 IEnumerable<HtmlNode> NodesMainContent6 = AnalyzeHTML.GetHtmlInfo(html, "div.resume.clearfix"); 79 if (NodesMainContent6.Count() > 0) 80 { 81 foreach (var item in NodesMainContent6) 82 { 83 string lable = Regex.Replace(item.InnerHtml, "\\s", ""); 84 lable = lable.Replace("<span>", ""); 85 string[] arr = lable.Split("</span>".ToCharArray(), StringSplitOptions.RemoveEmptyEntries); 86 if (arr != null && arr.Length > 2) 87 { 88 info.Address = arr[0];//Company address 89 info.Education = arr[1];//Minimum academic qualifications 90 } 91 } 92 } 93 //--A monthly salary 94 IEnumerable<HtmlNode> NodesMainContent7 = AnalyzeHTML.GetHtmlInfo(html, "div.job-title-left p.job-main-title"); 95 if (NodesMainContent7.Count() > 0) 96 { 97 info.Salary = NodesMainContent7.ToArray()[0].InnerText; 98 } 99 //--Release time 100 IEnumerable<HtmlNode> NodesMainContent8 = AnalyzeHTML.GetHtmlInfo(html, "div.job-title-left p.release-time em"); 101 if (NodesMainContent8.Count() > 0) 102 { 103 info.Time = NodesMainContent8.ToArray()[0].InnerText; 104 } 105 //-- 106 if (GetJobEnd != null) 107 { 108 GetJobEnd("", info); 109 } 110 } 111 catch (Exception exMsg) 112 { 113 throw new Exception(exMsg.Message); 114 } 115 }
The above method is also to analyze the content of a recruitment website label, but can not see the complex regular expression to intercept HTML label, so it seems more concise and simple code, and a whole configuration page can cope with the problem of constantly changing website label, so it seems that it is a very simple thing to grab other people's website data, O()_ ) Oha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha-ha
The above only represent personal views!!! If you are interested in adding QQ group together: (18684 1119), participate in discussion and learning exchanges.