preface
- 🔗 Running environment: Python 3
- 🚩 Author: Classmate K
- 📚 From column: Matplotlib tutorial
- 🧿 Excellent column: Introduction to Python 100 questions
- 🔥 Recommended column: Introduction to Xiaobai deep learning
- 🥇 Selected columns: 100 cases of deep learning
Everybody, I'm classmate K!
Recently, a film "Changjin Lake" has become a hot circle of friends. It has been by various Amway. I don't want to go to the cinema to dominate a couple seat alone. I'll honestly analyze the film review and see everyone's "impressions", right~

First locate the target page
https://movie.douban.com/subject/25845392/comments
On the crawler, grab the following four fields
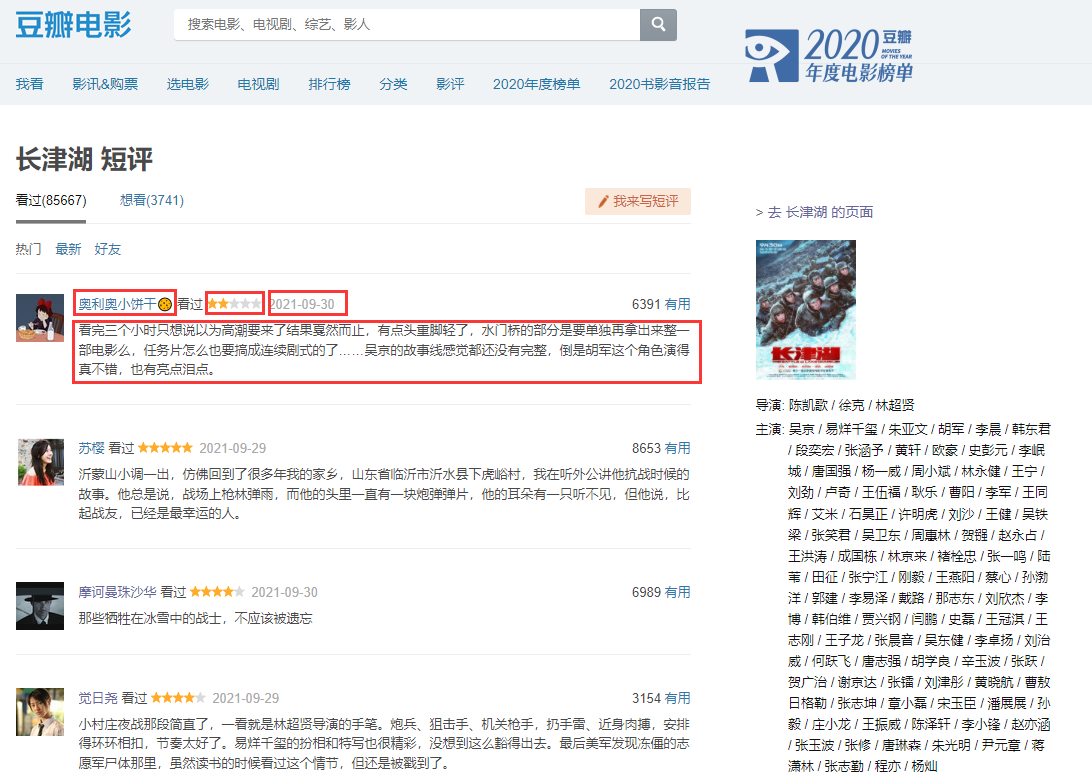
Then use pandas to import data and do simple processing
import pandas as pd
import os
file_path = os.path.join("douban.csv")
#Read columns A and B in the test.csv file. If the usecols parameter is not set, all data will be read by default.
df = pd.read_csv(open(file_path,'r',encoding='utf-8'), names=["user name","Star review","Comment time","comment"])
df.head()
| user name | Star review | Comment time | comment | |
|---|---|---|---|---|
| 0 | Still van tesey | it 's not bad | 2021-09-30 10:23:06 | A little disappointed, the plot can be said to be nothing, or the characterization as usual, as always, so sensational, the first battle is better than the second |
| 1 | Oreo cookies 🍪 | Poor | 2021-09-30 15:13:40 | After three hours, I just want to say that I thought the climax was coming, and the result suddenly stopped. I nodded heavily and my feet were light. The part of Watergate bridge should be taken out alone |
| 2 | High quality connoisseur | Poor | 2021-09-26 21:17:48 | I went to see some movies. It's worth the ticket price. It's OK to watch it for three hours. The war drama is easy to paralyze my eyes, but it's also exciting. I don't like red hydantoin |
| 3 | Wu: 30 | it 's not bad | 2021-09-27 18:16:24 | Just tell the truth: \ n1. The film is too long and very unfriendly to the audience. War scenes can be reduced, and soldiers can play with each other |
| 4 | xi-xia | it 's not bad | 2021-09-30 11:11:45 | The length of the battle scene and the weak logical connection of the plot are really numb at the end. It's better to limit the film length to two hours. |
star_num = df.Star review.value_counts() star_num = star_num.sort_index() star_num
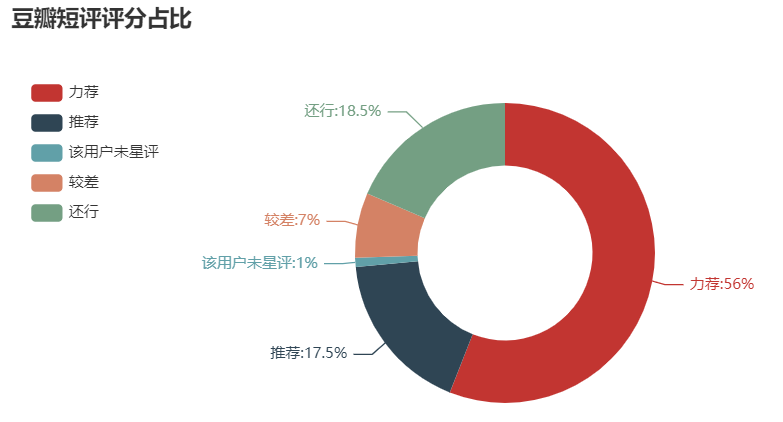
recommend strongly one hundred and twelve recommend 35 The user did not comment 2 Poor fourteen it 's not bad thirty-seven Name: Star review, dtype: int64
Proportion of Douban short comment score
from pyecharts.charts import Pie, Bar, Line, Page
from pyecharts import options as opts
from pyecharts.globals import SymbolType
# Data pair
data_pair = [list(z) for z in zip([i for i in star_num.index], star_num.values.tolist())]
# Pie chart
pie1 = Pie(init_opts=opts.InitOpts(width='800px', height='400px'))
pie1.add('', data_pair, radius=['35%', '60%'])
pie1.set_global_opts(title_opts=opts.TitleOpts(title='Proportion of Douban short comment score'),
legend_opts=opts.LegendOpts(orient='vertical', pos_top='15%', pos_left='2%')
)
pie1.set_series_opts(label_opts=opts.LabelOpts(formatter='{b}:{d}%'))
pie1.render_notebook()
Trend chart of comments
# Line chart
line1 = Line(init_opts=opts.InitOpts(width='800px', height='400px'))
line1.add_xaxis(comment_date.index.tolist())
line1.add_yaxis('', comment_date.values.tolist(),
#areastyle_opts=opts.AreaStyleOpts(opacity=0.5),
label_opts=opts.LabelOpts(is_show=False))
line1.set_global_opts(title_opts=opts.TitleOpts(title='Trend chart of comments'),
# toolbox_opts=opts.ToolboxOpts(),
visualmap_opts=opts.VisualMapOpts(max_=140))
line1.set_series_opts(linestyle_opts=opts.LineStyleOpts(width=4))
line1.render_notebook()
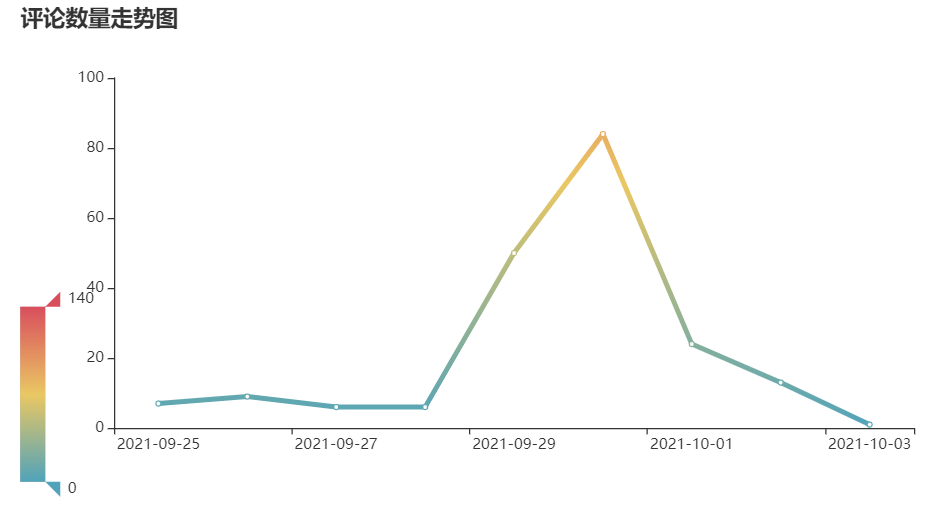
It was released on September 30 and began to build momentum on September 29. It peaked on September 30, but it seems that the momentum of No. 1 has greatly decreased.
Word cloud picture
positive
import jieba
def get_cut_words(content_series):
# Read in stoplist
stop_words = []
with open(r"hit_stopwords.txt", 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# Add keyword
my_words = ['Changjin Lake', 'a volunteer']
for i in my_words:
jieba.add_word(i)
# Custom stop words
my_stop_words = ['film',"Changjin Lake","Warfare"]
stop_words.extend(my_stop_words)
# participle
word_num = jieba.lcut(content_series.str.cat(sep='. '), cut_all=False)
# Conditional filtering
word_num_selected = [i for i in word_num if i not in stop_words and len(i)>=2]
return word_num_selected
text1 = get_cut_words(content_series=df[(df.Star review=='recommend strongly')|(df.Star review=='recommend')]['comment']) text1[:5]
['sacrifice', 'Ice and snow', 'warrior', 'should', 'forget']
import stylecloud
from IPython.display import Image # Used to display local pictures in jupyter lab
# Draw word cloud
stylecloud.gen_stylecloud(text=' '.join(text1),
max_words=1000,
collocations=False,
font_path=r'Classic variety Brief.ttf',
icon_name='fas fa-thumbs-up',
size=360,
output_name='Cloud chart of Douban positive scoring words.png')
Image(filename='Cloud chart of Douban positive scoring words.png')

negative
text2 = get_cut_words(content_series=df[(df.Star review=='it 's not bad')|(df.Star review=='Poor')]['comment']) text2[:5]
['somewhat', 'disappointment', 'plot', 'as always', 'character']
# Draw word cloud
stylecloud.gen_stylecloud(text=' '.join(text2),
max_words=1000,
collocations=False,
font_path=r'Classic variety Brief.ttf',
icon_name='fas fa-thumbs-down',
size=350,
output_name='Cloud chart of Douban negative scoring words.png')
Image(filename='Cloud chart of Douban negative scoring words.png')

🔥 Pay attention to the official account below (K classmate) reply: get your source code.