GPT-2 is an upgrade of GPT, and focuses more on why pretrain is useful. LM itself is a Multi-task Learner, and ZSL experiment is used to support this idea.
Article directory
I. Preface
Compared with GPT, GPT-2 has three main improvements: 1) big data; 2) big model; 3) a good insight. Readers who are not familiar with GPT can stamp Here.
Needless to say, the first two points are already reflected in the title of GPT-2, which is also an important point to implement the full text: Language Models are Unsupervised Multitask Learners, unlike the previous papers on Pretrain+Finetune, they just apply this idea, and then the experiment says: Oh, that's good, but there is no theoretical level. Sublimation.
This GPT-2, I see, feel that in the NLP field pretrain+finetune this set of processes why useful, but also have some different understanding.
The author's own understanding of this view is that the previous explanation of why pretrain is useful is speculation, and a good initialization point has been found. This is to say that LM naturally learns the information needed by supervised tasks in the process of learning, that is, LM itself is an unsupervised multi-task learner, which can prove why pretrain is useful for later tasks, that is, why it can find a good initialization point. More specifically, the task of supervision mentioned in the paper is only a subset of the sequence of language models. Here, the author fills in some examples, such as LM modeling for the sequence of "The translation of apple in Chinese is apple", which naturally learns the knowledge of translation, and modeling for the sequence of "Yao Ming's height is 2.26 meters", which naturally learns to ask questions. Answer relevant knowledge, and so on.
II. GPT-2 Principle
Understanding the above ideas, you can see the principle of GPT-2, although there is not much innovation in principle. This article mainly talks about the improvement points compared with GPT.
1. data set
The author crawled a large amount of corpus from the Internet to pretrain LM. Their final data set is called WebText, which has about 8 million documents and 40G texts. Wikipedia's data was also removed, because many of the tasks for ZSL are based on Wikipedia's corpus. This is the premise to ensure the task of ZSL.
PS: ZSL is Zero-shot Learning.
2. Input characterization
The input text is thrown directly into bpe without any preprocessing (such as case conversion, segmentation, etc.).
3. model
It's basically the same as GPT, but moves LayerNorm to the input of each layer and adds LayerNorm after the last attention layer. At the same time, when the residual layer is initialized, it is multiplied by 1/N1/ sqrt {N} 1/N, where N is the number of residual layers. Is residual an addition? Where are the parameters? The vocabulary expanded to 50257. The context length is extended from 512 to 1024, and batchsize to 512.
Three. Experiment.
The author uses several different size models, as shown in the following figure:
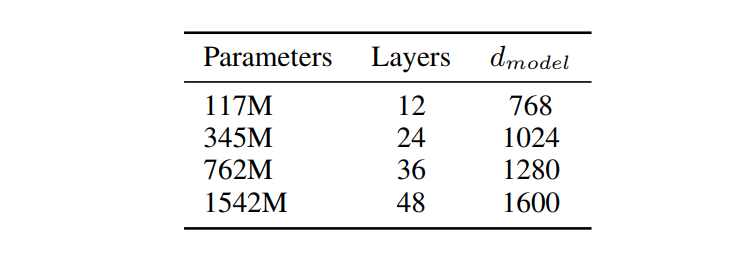
The author points out that the smallest model is GPT, the second smallest model and the large BERT model are of magnitude, and the largest model is called GPT-2. ** All models are under-fitted during LM training. ** It shows that the big data they crawled is still good!
The author directly sets up the pretrain model without finetune running all downstream NLP tasks, i.e. ZSL settings. The results are as follows:
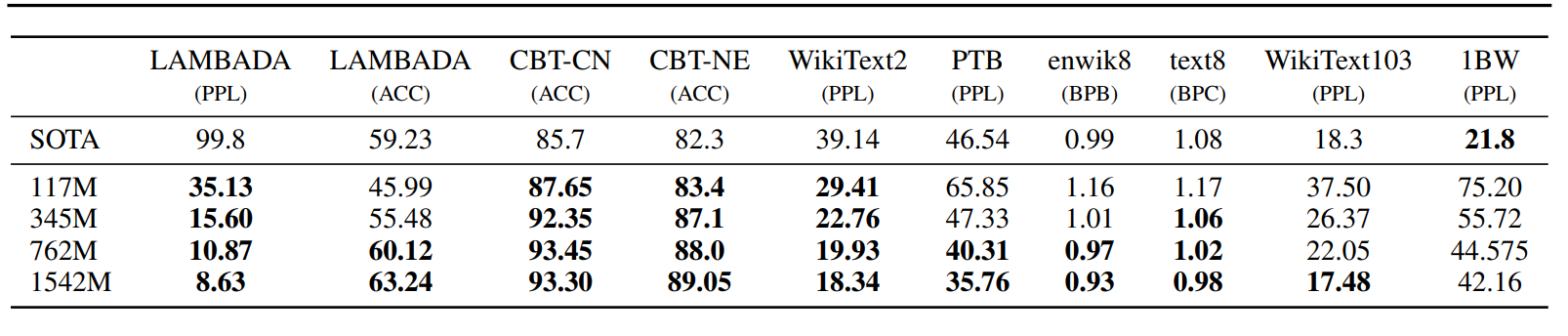
Here WikiText2, PTB, enwiki8, text8, WikiText103, 1BW are the data sets of several test language models; LAMBADA is the data set to test the ability to model long sentences, which is used to predict the last word of a sentence; CBT is used to test the performance of LM on different types of words, mainly Cloze task.
The author also tested some other tasks, such as the reasoning task Winograd Schema Challange. The results are as follows:
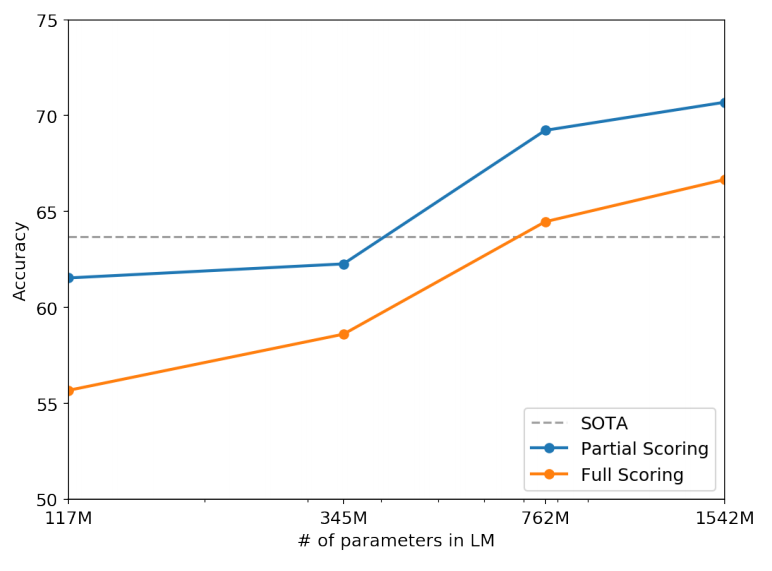
There are also tasks such as reading and understanding CoQA, abstract, translation and QA, such as the results of the abstract:
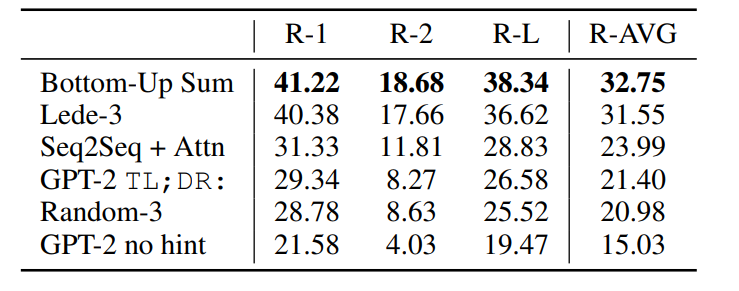
Finally, the author gives a table explaining the difficulty of training, which is used to show that the text coincidence between the training set and the test set of these tasks is high, so the effect of SoTA should be discounted, while the training data used here in GPT-2 has a lower coincidence with the test set, so it can better explain the effect of GPT-2.

IV. Implementation of TensorFlow
Look at the meaning of the source code, as with GPT, there is no Pretrain training code, and in the example only gives the part of text continuation. But still does not affect the author want to explore, so here from pretrain's model structure and text continuation generation. In fact, according to the focus of GPT-2's paper, it is to prove that Pretrain LM can use ZSL to accomplish other tasks, so the two parts of the source code given here are actually enough for practical application!
1. Model structure
In terms of model structure, the main body is similar to GPT, which is the decoder form of transformer, but it is expanded in scale. The specific code is as follows:
def model(hparams, X, past=None, scope='model', reuse=False): with tf.variable_scope(scope, reuse=reuse): results = {} batch, sequence = shape_list(X) # Embedding wpe = tf.get_variable('wpe', [hparams.n_ctx, hparams.n_embd], initializer=tf.random_normal_initializer(stddev=0.01)) wte = tf.get_variable('wte', [hparams.n_vocab, hparams.n_embd], initializer=tf.random_normal_initializer(stddev=0.02)) past_length = 0 if past is None else tf.shape(past)[-2] h = tf.gather(wte, X) + tf.gather(wpe, positions_for(X, past_length)) # Transformer presents = [] pasts = tf.unstack(past, axis=1) if past is not None else [None] * hparams.n_layer assert len(pasts) == hparams.n_layer for layer, past in enumerate(pasts): h, present = block(h, 'h%d' % layer, past=past, hparams=hparams) presents.append(present) results['present'] = tf.stack(presents, axis=1) h = norm(h, 'ln_f') # Language model loss. Do tokens <n predict token n? h_flat = tf.reshape(h, [batch*sequence, hparams.n_embd]) logits = tf.matmul(h_flat, wte, transpose_b=True) logits = tf.reshape(logits, [batch, sequence, hparams.n_vocab]) results['logits'] = logits return results
The code as a whole is still very clear, which is divided into three steps:
- Embedding layer: wpe and wte here represent position embedding and token embedding respectively.
- Transformer layer: The core here is still the block function, which will be discussed later. Note that there is still no mask part of the incoming length, which is rougher than what was done in previous GPT s.
- Output layer: After getting the representation of each timestep, it's the familiar software Max layer, where tie's strategy is still used, and when mapping to the vocabulary, the parameters of token embedding are still used.
As for the block part, the decoder part of transformer is implemented in the following way:
def block(x, scope, *, past, hparams): with tf.variable_scope(scope): nx = x.shape[-1].value a, present = attn(norm(x, 'ln_1'), 'attn', nx, past=past, hparams=hparams) x = x + a m = mlp(norm(x, 'ln_2'), 'mlp', nx*4, hparams=hparams) x = x + m return x, present
The main difference between GPT and norm is that GPT does norm after residual.
Here are two details to implement attn and mlp as follows:
def attn(x, scope, n_state, *, past, hparams): assert x.shape.ndims == 3 # Should be [batch, sequence, features] assert n_state % hparams.n_head == 0 if past is not None: assert past.shape.ndims == 5 # Should be [batch, 2, heads, sequence, features], where 2 is [k, v] def split_heads(x): # From [batch, sequence, features] to [batch, heads, sequence, features] return tf.transpose(split_states(x, hparams.n_head), [0, 2, 1, 3]) def merge_heads(x): # Reverse of split_heads return merge_states(tf.transpose(x, [0, 2, 1, 3])) def mask_attn_weights(w): # w has shape [batch, heads, dst_sequence, src_sequence], where information flows from src to dst. _, _, nd, ns = shape_list(w) b = attention_mask(nd, ns, dtype=w.dtype) b = tf.reshape(b, [1, 1, nd, ns]) w = w*b - tf.cast(1e10, w.dtype)*(1-b) return w def multihead_attn(q, k, v): # q, k, v have shape [batch, heads, sequence, features] w = tf.matmul(q, k, transpose_b=True) w = w * tf.rsqrt(tf.cast(v.shape[-1].value, w.dtype)) w = mask_attn_weights(w) w = softmax(w)g a = tf.matmul(w, v) return a with tf.variable_scope(scope): c = conv1d(x, 'c_attn', n_state*3) qg, k, v = map(split_heads, tf.split(c, 3, axis=2)) present = tf.stack([k, v], axis=1) if past is not None: pk, pv = tf.unstack(past, axis=1) k = tf.concat([pk, k], axis=-2) v = tf.concat([pv, v], axis=-2) a = multihead_attn(q, k, v) a = merge_heads(a) a = conv1d(a, 'c_proj', n_state) return a, present def mlp(x, scope, n_state, *, hparams): with tf.variable_scope(scope): nx = x.shape[-1].value h = gelu(conv1d(x, 'c_fc', n_state)) h2 = conv1d(h, 'c_proj', nx) return h2
The gelu activation function is still used here in feed forward.
2. Text continuation
In fact, the main purpose of this paper is to use LM to generate the next function automatically. The main body's part is in the following function:
def body(past, prev, output): next_outputs = step(hparams, prev[:, tf.newaxis], past=past) logits = next_outputs['logits'][:, -1, :] / tf.to_float(temperature) logits = top_k_logits(logits, k=top_k) samples = tf.multinomial(logits, num_samples=1, output_dtype=tf.int32) return [ tf.concat([past, next_outputs['presents']], axis=-2), tf.squeeze(samples, axis=[1]), tf.concat([output, samples], axis=1), ] def step(hparams, tokens, past=None): lm_output = model.model(hparams=hparams, X=tokens, past=past, reuse=tf.AUTO_REUSE) logits = lm_output['logits'][:, :, :hparams.n_vocab] presents = lm_output['present'] presents.set_shape(model.past_shape(hparams=hparams, batch_size=batch_size)) return { 'logits': logits, 'presents': presents, }
It can be seen that the process is: 1. Generating the next output (step function) according to the current context; 2. Selecting the output of Top-k; 3. Sampling one output as the next continuation according to the current probability distribution.
Five. Conclusion
advantage
- Collected a large corpus of WebText, even a large model like GPT-2 is still in an under-fitting state.
- The largest GPT-2 model, with 1.5B parameters, has been tested on many tasks with ZSL, and 7/8 tasks have reached SoTA.
- Given the pre-trained parameters, although only TensorFlow's, it should not be difficult to convert to other ones.
insufficient
- No pretrain training code was released, and the finetune section only listed the continuation section.
- Only a small pre-training parameter of 117M is given, which may be used for improper purposes or understandable.
Portal
Papers: https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
Source code: https://github.com/openai/gpt-2 (TensorFlow)
https://github.com/huggingface/pytorch-pretrained-BERT (PyTorch, although its name is BERT, has a GPT-2 implementation.)
Official blog: https://openai.com/blog/better-language-models/