This article is based on TiDB release-5.1 and needs to use versions after Go 1.16
My blog address: https://www.luozhiyun.com/archives/631
The so-called Hash Join is to select a table as the buildSide table to construct the hash table and another table as the probeSide table when joining; Then, for each row of data in the probeSide table, go to the hash table to find out whether there is matching data.
According to the above definition, it seems that Hash Join is easy to do. You just need to make a large map and traverse the data of the probeSide table for matching. But as an efficient database, what optimization will TiDB do in this process?
So take these questions before reading the article:
- Which table will become the buildSide table or the probeSide table?
- Does the hash table constructed from the buildSide table contain all the data of the buildSide table? Will there be no problem if the amount of data is too large?
- When the probeSide table matches the buildSide table, is it single thread matching or multi thread matching? If it is multi-threaded matching, how to allocate the matching data?
Let me use this example to explain:
CREATE TABLE test1 (a int , b int, c int, d int); CREATE TABLE test2 (a int , b int, c int, d int);
Then query the execution plan:
explain select * from test1 t1 join test1 t2 on t1.a= t2.a ; +-----------------------+--------+---------+-------------+--------------------------------------------------+ |id |estRows |task |access object|operator info | +-----------------------+--------+---------+-------------+--------------------------------------------------+ |HashJoin_8 |12487.50|root | |inner join, equal:[eq(test.test1.a, test.test1.a)]| |├─TableReader_15(Build)|9990.00 |root | |data:Selection_14 | |│ └─Selection_14 |9990.00 |cop[tikv]| |not(isnull(test.test1.a)) | |│ └─TableFullScan_13 |10000.00|cop[tikv]|table:t2 |keep order:false, stats:pseudo | |└─TableReader_12(Probe)|9990.00 |root | |data:Selection_11 | | └─Selection_11 |9990.00 |cop[tikv]| |not(isnull(test.test1.a)) | | └─TableFullScan_10 |10000.00|cop[tikv]|table:t1 |keep order:false, stats:pseudo | +-----------------------+--------+---------+-------------+--------------------------------------------------+
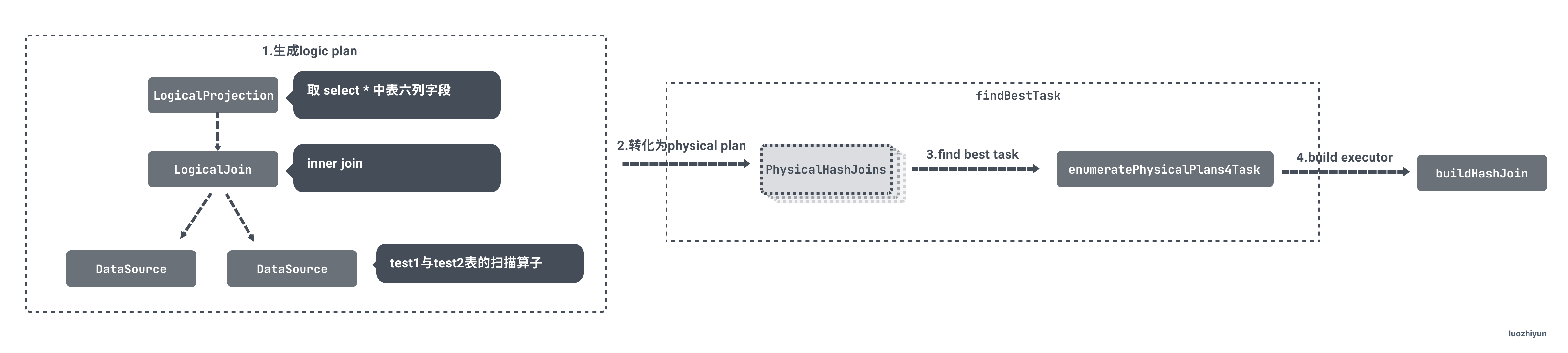
Building a Hash Join actuator
-
TiDB will first build the corresponding Logic Plan according to SQL;
-
Then, convert the Logic Plan to Physical Plan. Here, convert it to PhysicalHashJoin as the Physical Plan;
-
By comparing the costs of Physical Plan, finally select a Physical Plan construction executor with the lowest cost;
The reason why I want to talk about this is because when building the actuator through the Physical Plan, I will judge which table is used as the buildSide table or probeSide table;
Building a Physical Plan
Build Physical Plan in exhaust_ physical_ In the getHashJoins method of the plans.go file:
func (p *LogicalJoin) getHashJoins(prop *property.PhysicalProperty) []PhysicalPlan {
...
joins := make([]PhysicalPlan, 0, 2)
switch p.JoinType {
case SemiJoin, AntiSemiJoin, LeftOuterSemiJoin, AntiLeftOuterSemiJoin:
joins = append(joins, p.getHashJoin(prop, 1, false))
case LeftOuterJoin:
joins = append(joins, p.getHashJoin(prop, 1, false))
joins = append(joins, p.getHashJoin(prop, 1, true))
case RightOuterJoin:
joins = append(joins, p.getHashJoin(prop, 0, false))
joins = append(joins, p.getHashJoin(prop, 0, true))
case InnerJoin:
joins = append(joins, p.getHashJoin(prop, 1, false))
joins = append(joins, p.getHashJoin(prop, 0, false))
}
return joins
}
This method will call getHashJoin method to create Physical Plan according to the type of Join. Multiple physicalhashjoins will be created here, and then a Physical Plan construction actuator with the least cost will be selected.
Note the following two parameters of getHashJoin:
func (p *LogicalJoin) getHashJoin(prop *property.PhysicalProperty, innerIdx int, useOuterToBuild bool) *PhysicalHashJoin
Later, the buildSide table or probeSide table will be determined according to innerIdx and useOuterToBuild;
Select the most efficient execution plan
After the Physical Plan is built, it will traverse the created Plan to obtain its cost:
func (p *baseLogicalPlan) enumeratePhysicalPlans4Task(physicalPlans []PhysicalPlan, prop *property.PhysicalProperty, addEnforcer bool, planCounter *PlanCounterTp) (task, int64, error) {
var bestTask task = invalidTask
childTasks := make([]task, 0, len(p.children))
for _, pp := range physicalPlans {
childTasks = childTasks[:0]
for j, child := range p.children {
childTask, cnt, err := child.findBestTask(pp.GetChildReqProps(j), &PlanCounterDisabled)
...
childTasks = append(childTasks, childTask)
}
// Combine best child tasks with parent physical plan.
curTask := pp.attach2Task(childTasks...)
...
// Get the most efficient one.
if curTask.cost() < bestTask.cost() || (bestTask.invalid() && !curTask.invalid()) {
bestTask = curTask
}
}
return bestTask, ...
}
Select the least expensive return from these plans.
Building an actuator from an execution plan
After the execution plan is obtained, a series of calls will be made to buildHashJoin to build HashJoinExec as the hash join executor:

Let's take a look at buildHashJoin:
func (b *executorBuilder) buildHashJoin(v *plannercore.PhysicalHashJoin) Executor {
// Build left table executor
leftExec := b.build(v.Children()[0])
if b.err != nil {
return nil
}
// Build right table executor
rightExec := b.build(v.Children()[1])
if b.err != nil {
return nil
}
// structure
e := &HashJoinExec{
baseExecutor: newBaseExecutor(b.ctx, v.Schema(), v.ID(), leftExec, rightExec),
concurrency: v.Concurrency,
// join type
joinType: v.JoinType,
isOuterJoin: v.JoinType.IsOuterJoin(),
useOuterToBuild: v.UseOuterToBuild,
}
...
//Select buildSideExec and probeSideExec
if v.UseOuterToBuild {
if v.InnerChildIdx == 1 { // left join InnerChildIdx =1
e.buildSideExec, e.buildKeys = leftExec, v.LeftJoinKeys
e.probeSideExec, e.probeKeys = rightExec, v.RightJoinKeys
e.outerFilter = v.LeftConditions
} else {
e.buildSideExec, e.buildKeys = rightExec, v.RightJoinKeys
e.probeSideExec, e.probeKeys = leftExec, v.LeftJoinKeys
e.outerFilter = v.RightConditions
}
} else {
if v.InnerChildIdx == 0 {
e.buildSideExec, e.buildKeys = leftExec, v.LeftJoinKeys
e.probeSideExec, e.probeKeys = rightExec, v.RightJoinKeys
e.outerFilter = v.RightConditions
} else {
e.buildSideExec, e.buildKeys = rightExec, v.RightJoinKeys
e.probeSideExec, e.probeKeys = leftExec, v.LeftJoinKeys
e.outerFilter = v.LeftConditions
}
}
childrenUsedSchema := markChildrenUsedCols(v.Schema(), v.Children()[0].Schema(), v.Children()[1].Schema())
e.joiners = make([]joiner, e.concurrency)
for i := uint(0); i < e.concurrency; i++ {
// Create joiner for Join matching
e.joiners[i] = newJoiner(b.ctx, v.JoinType, v.InnerChildIdx == 0, defaultValues,
v.OtherConditions, lhsTypes, rhsTypes, childrenUsedSchema)
}
...
return e
}
The main logic of this section is to build HashJoinExec according to the optimal Physical Plan.
The main thing is that the buildSide table and probeSide table will be determined according to UseOuterToBuild and InnerChildIdx.
For example, when building the Physical Plan of left join:
func (p *LogicalJoin) getHashJoins(prop *property.PhysicalProperty) []PhysicalPlan {
...
joins := make([]PhysicalPlan, 0, 2)
switch p.JoinType {
case LeftOuterJoin:
joins = append(joins, p.getHashJoin(prop, 1, false))
joins = append(joins, p.getHashJoin(prop, 1, true))
...
}
return joins
}
In the passed in getHashJoin method, the first parameter represents InnerChildIdx and the second parameter represents UseOuterToBuild. Here, two physical plans will be generated, and then the optimal one will be calculated according to the cost;
When you enter the buildHashJoin method, you can find that the buildSide table and probeSide table are finally related to the Physical Plan:
func (b *executorBuilder) buildHashJoin(v *plannercore.PhysicalHashJoin) Executor {
...
//Select buildSideExec and probeSideExec
if v.UseOuterToBuild {
if v.InnerChildIdx == 1 { // left join InnerChildIdx =1
e.buildSideExec, e.buildKeys = leftExec, v.LeftJoinKeys
e.probeSideExec, e.probeKeys = rightExec, v.RightJoinKeys
e.outerFilter = v.LeftConditions
} else {
...
}
} else {
if v.InnerChildIdx == 0 {
...
} else {
e.buildSideExec, e.buildKeys = rightExec, v.RightJoinKeys
e.probeSideExec, e.probeKeys = leftExec, v.LeftJoinKeys
e.outerFilter = v.LeftConditions
}
}
...
return e
}
Run the Hash Join actuator

After building HashJoinExec, it comes to the step of obtaining data. TiDB will obtain a batch of data from the actuator at one time through the Next method. The specific method of obtaining data is in the Next of HashJoinExec.
func (e *HashJoinExec) Next(ctx context.Context, req *chunk.Chunk) (err error) {
if !e.prepared {
e.buildFinished = make(chan error, 1)
// Asynchronously build hashtable according to the data in buildSide table
go util.WithRecovery(func() {
defer trace.StartRegion(ctx, "HashJoinHashTableBuilder").End()
e.fetchAndBuildHashTable(ctx)
}, e.handleFetchAndBuildHashTablePanic)
// Read the probeSide table and match the hashtable built, and put the obtained data into joinResultCh
e.fetchAndProbeHashTable(ctx)
e.prepared = true
}
if e.isOuterJoin {
atomic.StoreInt64(&e.requiredRows, int64(req.RequiredRows()))
}
req.Reset()
// Get result data
result, ok := <-e.joinResultCh
if !ok {
return nil
}
if result.err != nil {
e.finished.Store(true)
return result.err
}
// Put the data returned into req Chunk
req.SwapColumns(result.chk)
result.src <- result.chk
return nil
}
The Next method obtains data in three steps:
- Call fetchAndBuildHashTable method to asynchronously build hashtable according to the data in buildSide table;
- Call the fetchAndProbeHashTable method to read the probeSide table and match the constructed hashtable, and get the data and put it into joinResultCh;
- Obtain data from joinResultCh;
fetchAndBuildHashTable build hash table
func (e *HashJoinExec) fetchAndBuildHashTable(ctx context.Context) {
...
buildSideResultCh := make(chan *chunk.Chunk, 1)
doneCh := make(chan struct{})
go util.WithRecovery(
func() {
defer trace.StartRegion(ctx, "HashJoinBuildSideFetcher").End()
// Get the data in the buildSide table and put the data into buildSideResultCh
e.fetchBuildSideRows(ctx, buildSideResultCh, doneCh)
}, ...,
)
// Read data from buildSideResultCh to build rowContainer
err := e.buildHashTableForList(buildSideResultCh)
if err != nil {
e.buildFinished <- errors.Trace(err)
close(doneCh)
}
...
}
Here, the process of building a hash map is divided into two parts:
- Asynchronously call fetchBuildSideRows to get the data in the buildSide table and put it into buildSideResultCh;
- Read data from buildSideResultCh to build rowContainer, which is equivalent to the place where hash map stores data.
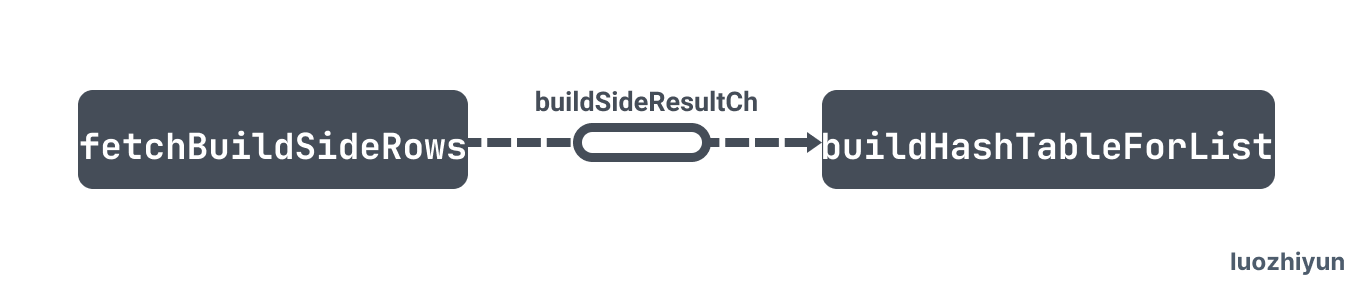
Let's take a look at buildHashTableForList:
func (e *HashJoinExec) buildHashTableForList(buildSideResultCh <-chan *chunk.Chunk) error {
e.rowContainer = newHashRowContainer(e.ctx, int(e.buildSideEstCount), hCtx)
...
// Read channel data
for chk := range buildSideResultCh {
if e.finished.Load().(bool) {
return nil
}
if !e.useOuterToBuild {
// Save data into rowContainer
err = e.rowContainer.PutChunk(chk, e.isNullEQ)
} else {
...
}
if err != nil {
return err
}
}
return nil
}
Here, the chunk data will be stored in the rowContainer through putsink.
func (c *hashRowContainer) PutChunk(chk *chunk.Chunk, ignoreNulls []bool) error {
return c.PutChunkSelected(chk, nil, ignoreNulls)
}
func (c *hashRowContainer) PutChunkSelected(chk *chunk.Chunk, selected, ignoreNulls []bool) error {
start := time.Now()
defer func() { c.stat.buildTableElapse += time.Since(start) }()
chkIdx := uint32(c.rowContainer.NumChunks())
// Store the data in the RowContainer. If there is no space in the memory, it will be stored in the disk
err := c.rowContainer.Add(chk)
if err != nil {
return err
}
numRows := chk.NumRows()
c.hCtx.initHash(numRows)
hCtx := c.hCtx
// Build a hash value based on the column value in the chunk
for keyIdx, colIdx := range c.hCtx.keyColIdx {
ignoreNull := len(ignoreNulls) > keyIdx && ignoreNulls[keyIdx]
err := codec.HashChunkSelected(c.sc, hCtx.hashVals, chk, hCtx.allTypes[colIdx], colIdx, hCtx.buf, hCtx.hasNull, selected, ignoreNull)
if err != nil {
return errors.Trace(err)
}
}
// Build a hash table based on the hash value
for i := 0; i < numRows; i++ {
if (selected != nil && !selected[i]) || c.hCtx.hasNull[i] {
continue
}
key := c.hCtx.hashVals[i].Sum64()
rowPtr := chunk.RowPtr{ChkIdx: chkIdx, RowIdx: uint32(i)}
c.hashTable.Put(key, rowPtr)
}
return nil
}
For rowContainer, data storage is divided into two parts: one is to store chunk data in records or recordsInDisk of rowContainer; The other part is to build a hash table to store the key value and take the index of the data as the value.
func (c *RowContainer) Add(chk *Chunk) (err error) {
...
// If the memory is full, it is written to disk
if c.alreadySpilled() {
if c.m.spillError != nil {
return c.m.spillError
}
err = c.m.recordsInDisk.Add(chk)
} else {
// Otherwise, write to memory
c.m.records.Add(chk)
}
return
}
RowContainer will determine whether to save disk or memory according to memory usage.
Multi thread execution hash Join
The hash Join process is executed through the fetchAndProbeHashTable method. This method is interesting and shows us how to use chanel for data transfer in multithreading.
func (e *HashJoinExec) fetchAndProbeHashTable(ctx context.Context) {
// Initialize the data transfer channel
e.initializeForProbe()
e.joinWorkerWaitGroup.Add(1)
// Circularly obtain the data in the ProbeSide table and store the data in the probeSideResult channel
go util.WithRecovery(func() {
defer trace.StartRegion(ctx, "HashJoinProbeSideFetcher").End()
e.fetchProbeSideChunks(ctx)
}, e.handleProbeSideFetcherPanic)
probeKeyColIdx := make([]int, len(e.probeKeys))
for i := range e.probeKeys {
probeKeyColIdx[i] = e.probeKeys[i].Index
}
// Start multiple join workers to match the data between the buildSide table and the ProbeSide table
for i := uint(0); i < e.concurrency; i++ {
e.joinWorkerWaitGroup.Add(1)
workID := i
go util.WithRecovery(func() {
defer trace.StartRegion(ctx, "HashJoinWorker").End()
e.runJoinWorker(workID, probeKeyColIdx)
}, e.handleJoinWorkerPanic)
}
go util.WithRecovery(e.waitJoinWorkersAndCloseResultChan, nil)
}
The whole hash Join execution is divided into three parts:
- Since the hash Join process is processed through multiple threads, the channel will be used for data transfer. Therefore, the first step is to call initializeForProbe to initialize the data transfer channel;
- Then, fetchProbeSideChunks will be called asynchronously to obtain data from the ProbeSide table;
- Next, start multiple threads, call runJoinWorker method, and start multiple join workers to hash Join;
It should be noted that the thread that queries the probeSide table data here is called probeSideExec worker; The thread executing the join matching is called the join worker. Its number is determined by concurrency. The default is 5.
initializeForProbe
Let's take a look at initializeForProbe first:
func (e *HashJoinExec) initializeForProbe() {
// Used by probeSideExec worker to save probeSide table data for association with join worker
e.probeResultChs = make([]chan *chunk.Chunk, e.concurrency)
for i := uint(0); i < e.concurrency; i++ {
e.probeResultChs[i] = make(chan *chunk.Chunk, 1)
}
// Used to reuse chunks used by join workers to probesideexec workers
e.probeChkResourceCh = make(chan *probeChkResource, e.concurrency)
for i := uint(0); i < e.concurrency; i++ {
e.probeChkResourceCh <- &probeChkResource{
chk: newFirstChunk(e.probeSideExec),
dest: e.probeResultChs[i],
}
}
// Used to pass reusable join result chunks from main thread to join worker
e.joinChkResourceCh = make([]chan *chunk.Chunk, e.concurrency)
for i := uint(0); i < e.concurrency; i++ {
e.joinChkResourceCh[i] = make(chan *chunk.Chunk, 1)
e.joinChkResourceCh[i] <- newFirstChunk(e)
}
// Used to pass the join result chunks from the join worker to the main thread
e.joinResultCh = make(chan *hashjoinWorkerResult, e.concurrency+1)
}
This method mainly initializes four channel objects.
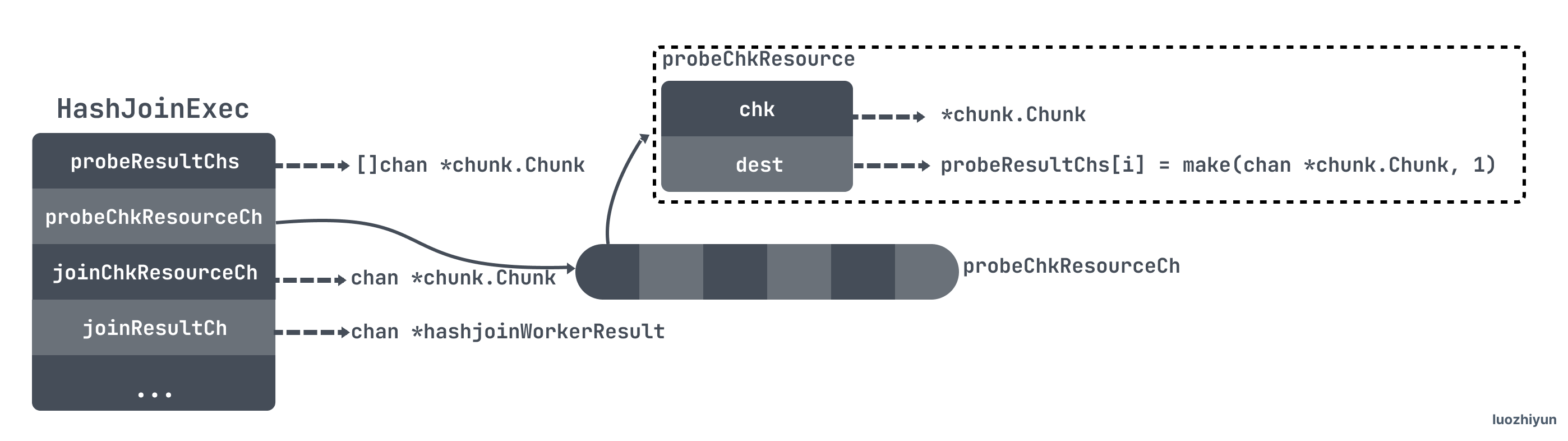
probeResultChs: used to save the data found in the probeSide table;
probeChkResourceCh: used to reuse chunks used by join workers to probesideexec workers;
joinChkResourceCh: it is also used to pass chunks, mainly for reuse of join worker s;
joinResultCh: used to pass the matching result of join worker to main thread;
fetchProbeSideChunks
Let's take another look at the process of asynchronous fetchProbeSideChunks:
func (e *HashJoinExec) fetchProbeSideChunks(ctx context.Context) {
for {
...
var probeSideResource *probeChkResource
select {
case <-e.closeCh:
return
case probeSideResource, ok = <-e.probeChkResourceCh:
}
// Get available chunk s
probeSideResult := probeSideResource.chk
if e.isOuterJoin {
required := int(atomic.LoadInt64(&e.requiredRows))
probeSideResult.SetRequiredRows(required, e.maxChunkSize)
}
// Get data and store it in probeSideResult
err := Next(ctx, e.probeSideExec, probeSideResult)
...
//Put chunk.Chunk with data into dest channel
probeSideResource.dest <- probeSideResult
}
}
After understanding the functions of each channel, it is easy to understand that this is mainly to get the available chunk, then call Next to put the data in chunk, and finally put chunk into dest channel.
runJoinWorker
Finally, let's take a look at the implementation of Join Worker:
func (e *HashJoinExec) runJoinWorker(workerID uint, probeKeyColIdx []int) {
...
var (
probeSideResult *chunk.Chunk
selected = make([]bool, 0, chunk.InitialCapacity)
)
// Get hashjoinWorkerResult
ok, joinResult := e.getNewJoinResult(workerID)
if !ok {
return
}
emptyProbeSideResult := &probeChkResource{
dest: e.probeResultChs[workerID],
}
hCtx := &hashContext{
allTypes: e.probeTypes,
keyColIdx: probeKeyColIdx,
}
// Loop to get probeSideResult
for ok := true; ok; {
if e.finished.Load().(bool) {
break
}
select {
case <-e.closeCh:
return
// probeResultChs stores the data queried by probeSideExec worker
case probeSideResult, ok = <-e.probeResultChs[workerID]:
}
if !ok {
break
}
// Put the data matching the join into the chunk of the join result
ok, joinResult = e.join2Chunk(workerID, probeSideResult, hCtx, joinResult, selected)
if !ok {
break
}
// After use, reset the chunk and put the probeChkResourceCh back to the probeSideExec worker
probeSideResult.Reset()
emptyProbeSideResult.chk = probeSideResult
e.probeChkResourceCh <- emptyProbeSideResult
}
...
}
Because probeSideExec worker puts data in probeResultChs, it loops to get the data in it, and then calls join2Chunk to match the data.
func (e *HashJoinExec) join2Chunk(workerID uint, probeSideChk *chunk.Chunk, hCtx *hashContext, joinResult *hashjoinWorkerResult,
selected []bool) (ok bool, _ *hashjoinWorkerResult) {
var err error
// Verify whether the data queried by probeSide chunk can be used for matching
selected, err = expression.VectorizedFilter(e.ctx, e.outerFilter, chunk.NewIterator4Chunk(probeSideChk), selected)
if err != nil {
joinResult.err = err
return false, joinResult
}
//hash of probeSide table for matching
hCtx.initHash(probeSideChk.NumRows())
for keyIdx, i := range hCtx.keyColIdx {
ignoreNull := len(e.isNullEQ) > keyIdx && e.isNullEQ[keyIdx]
err = codec.HashChunkSelected(e.rowContainer.sc, hCtx.hashVals, probeSideChk, hCtx.allTypes[i], i, hCtx.buf, hCtx.hasNull, selected, ignoreNull)
if err != nil {
joinResult.err = err
return false, joinResult
}
}
//Traverse the row records queried in the probeSide table
for i := range selected {
...
if !selected[i] || hCtx.hasNull[i] { // process unmatched probe side rows
e.joiners[workerID].onMissMatch(false, probeSideChk.GetRow(i), joinResult.chk)
} else { // process matched probe side rows
// Get probeKey and probeRow of row record
probeKey, probeRow := hCtx.hashVals[i].Sum64(), probeSideChk.GetRow(i)
ok, joinResult = e.joinMatchedProbeSideRow2Chunk(workerID, probeKey, probeRow, hCtx, joinResult)
if !ok {
return false, joinResult
}
}
// If the chunk of the joinResult is full, put the data into the joinResultCh and retrieve the joinResult again
if joinResult.chk.IsFull() {
e.joinResultCh <- joinResult
ok, joinResult = e.getNewJoinResult(workerID)
if !ok {
return false, joinResult
}
}
}
return true, joinResult
}
Data matching can also be roughly divided into the following steps:
- Verify whether the data queried by probeSide chunk can be used for matching;
- Get the data row of probeSide chunk and hash it for matching;
- Traverse the probeSide chunk table for the matching data, and call joinMatchedProbeSideRow2Chunk to obtain the matching successful data and fill it in the joinResult;
func (e *HashJoinExec) join2Chunk(workerID uint, probeSideChk *chunk.Chunk, hCtx *hashContext, joinResult *hashjoinWorkerResult,
selected []bool) (ok bool, _ *hashjoinWorkerResult) {
var err error
// Verify whether the data queried by probeSide chunk can be used for matching
selected, err = expression.VectorizedFilter(e.ctx, e.outerFilter, chunk.NewIterator4Chunk(probeSideChk), selected)
if err != nil {
joinResult.err = err
return false, joinResult
}
//hash of probeSide table for matching
hCtx.initHash(probeSideChk.NumRows())
for keyIdx, i := range hCtx.keyColIdx {
ignoreNull := len(e.isNullEQ) > keyIdx && e.isNullEQ[keyIdx]
err = codec.HashChunkSelected(e.rowContainer.sc, hCtx.hashVals, probeSideChk, hCtx.allTypes[i], i, hCtx.buf, hCtx.hasNull, selected, ignoreNull)
if err != nil {
joinResult.err = err
return false, joinResult
}
}
//Traverse the row records queried in the probeSide table
for i := range selected {
...
if !selected[i] || hCtx.hasNull[i] { // process unmatched probe side rows
e.joiners[workerID].onMissMatch(false, probeSideChk.GetRow(i), joinResult.chk)
} else { // process matched probe side rows
// Get probeKey and probeRow of row record
probeKey, probeRow := hCtx.hashVals[i].Sum64(), probeSideChk.GetRow(i)
// Data matching
ok, joinResult = e.joinMatchedProbeSideRow2Chunk(workerID, probeKey, probeRow, hCtx, joinResult)
if !ok {
return false, joinResult
}
}
// If the chunk of the joinResult is full, put the data into the joinResultCh and retrieve the joinResult again
if joinResult.chk.IsFull() {
e.joinResultCh <- joinResult
ok, joinResult = e.getNewJoinResult(workerID)
if !ok {
return false, joinResult
}
}
}
return true, joinResult
}
join2Chunk will judge whether all the data returned by probeSide chunk can be matched according to the filter conditions, so as to reduce the amount of data matching;
If it can be matched, the probeKey and probeRow of the probeSide chunk record line will be passed into joinMatchedProbeSideRow2Chunk for data matching.
func (e *HashJoinExec) joinMatchedProbeSideRow2Chunk(workerID uint, probeKey uint64, probeSideRow chunk.Row, hCtx *hashContext,
joinResult *hashjoinWorkerResult) (bool, *hashjoinWorkerResult) {
// Matching data from buildSide table
buildSideRows, _, err := e.rowContainer.GetMatchedRowsAndPtrs(probeKey, probeSideRow, hCtx)
if err != nil {
joinResult.err = err
return false, joinResult
}
//Indicates that there is no matching data, which is returned directly
if len(buildSideRows) == 0 {
e.joiners[workerID].onMissMatch(false, probeSideRow, joinResult.chk)
return true, joinResult
}
iter := chunk.NewIterator4Slice(buildSideRows)
hasMatch, hasNull, ok := false, false, false
// add the data on the matching to the joinResult chunk
for iter.Begin(); iter.Current() != iter.End(); {
matched, isNull, err := e.joiners[workerID].tryToMatchInners(probeSideRow, iter, joinResult.chk)
if err != nil {
joinResult.err = err
return false, joinResult
}
if joinResult.chk.IsFull() {
e.joinResultCh <- joinResult
ok, joinResult = e.getNewJoinResult(workerID)
if !ok {
return false, joinResult
}
}
}
...
return true, joinResult
}
joinMatchedProbeSideRow2Chunk will get data from the rowContainer. If it cannot get the data, it will be returned directly. If it gets the data, it will store the data in the joinResult chunk.
The following is a flowchart to explain the whole hash matching process:
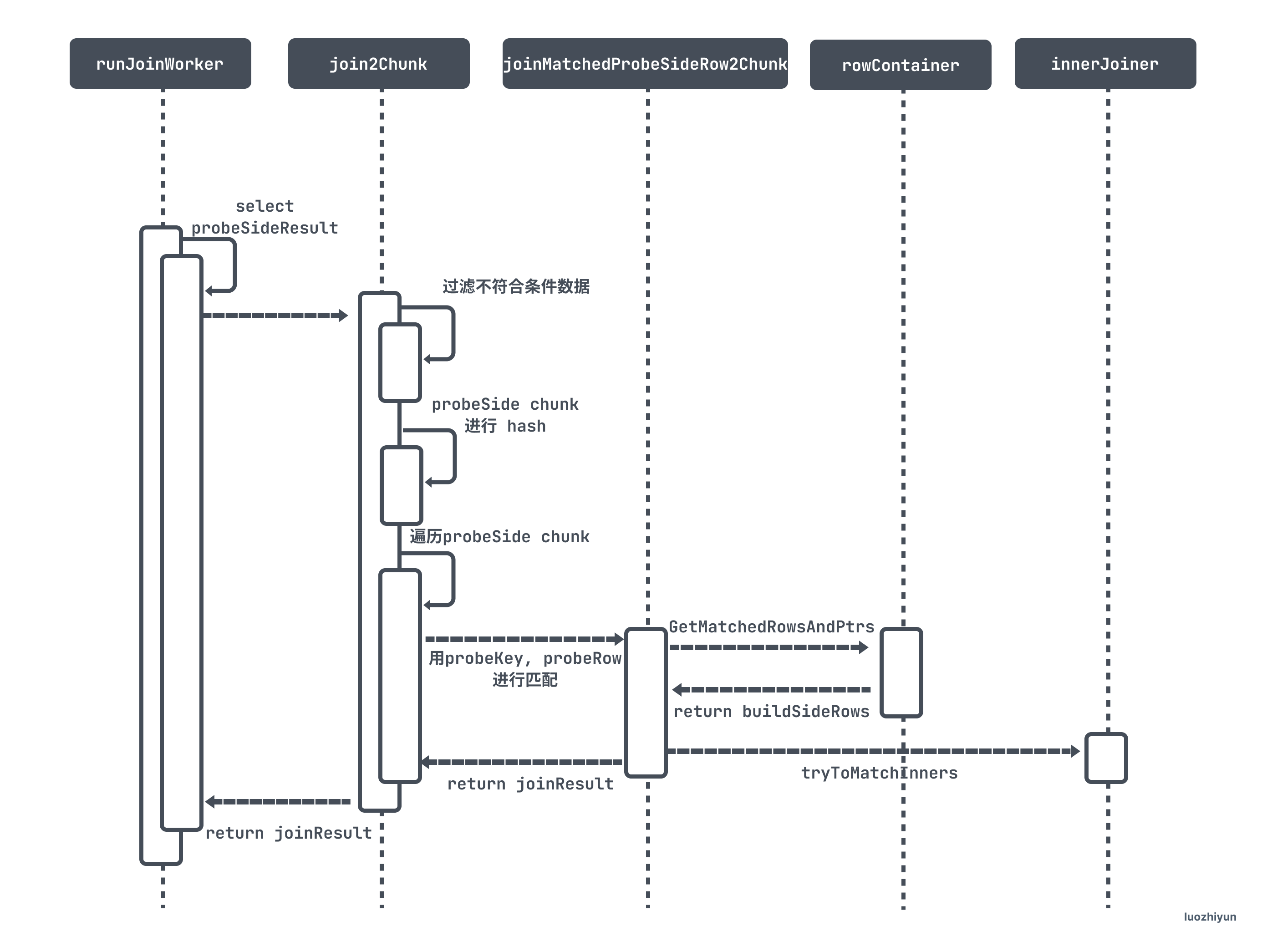
On the whole, the matching logic of Join Worker is:
- Obtain data from probeSide table to probeSideResource;
- Check the hash table according to the data of probeSideResource, and match the probeSide table with the buildSide table;
- Write the data on the matching to the joinResult chunk;
- Finally, the data of joinResult is brushed into joinResultCh and sent to Main Thread;
summary
This article basically makes a comprehensive analysis from building the hash join executor to running the HashJoinExec executor.
Back to the question at the beginning:
-
Which table will become the buildSide table or the probeSide table?
This is determined by the optimizer. When creating a Physical Plan, multiple plans will be created, and then the Plan created will be traversed to obtain the one with the lowest cost.
-
Does the hash table constructed from the buildSide table contain all the data of the buildSide table? Will there be no problem if the amount of data is too large?
The hash table constructed by the buildSide table contains all the data, but here in TiDB, the hash table and data items are separated; The data is the records stored in the rowContainer. If the amount of data is too large, it will be dropped through recordsInDisk; The hash table is stored in the hashTable of the rowContainer;
-
When the probeSide table matches the buildSide table, is it single thread matching or multi thread matching? If it is multi-threaded matching, how to allocate the matching data?
The matching is multi-threaded, and the default concurrency is 5; Data transfer between them is through channel. When obtaining data, each will obtain channel from probeResultChs array according to its own thread id and subscribe to the data therein;
Reference
https://pingcap.com/zh/blog/tidb-source-code-reading-9
https://github.com/xieyu/blog/blob/master/src/tidb/hash-join.md
