Hello, everyone. All the following are my notes when I study teacher Han Ru's tutorial. Some contents have been deleted and modified. It is recommended that you read the original author's documents for learning. This article is only used as personal learning notes, and will be continuously modified on this basis in the future. When learning Go Web, you should be familiar with the basic grammar of Go language and relevant contents of computer network.
Learning links: https://www.chaindesk.cn/witbook/17/253
Reference book: Go Web programming Xie Mengjun
Chapter 12 regular expressions
Regular expression is a complex and powerful tool for pattern matching and text manipulation. Although regular expressions are less efficient than pure text matching, they are more flexible. According to its syntax rules, the matching pattern constructed on demand can filter almost any character combination you want from the original text. If you need to obtain data from some text data sources in Web development, you can extract meaningful text information from the original data source only by constructing the correct pattern string on demand according to its syntax rules.
The Go language provides official support for regular expressions through the regexp standard package. If you have used the regular related functions provided by other programming languages, you should not be too familiar with the Go language version, but there are some small differences between them, because Go implements the RE2 standard, except \ C, For detailed syntax description, refer to: http://code.google.com/p/re2/wiki/Syntax
In fact, for string processing, we can use the strings package to search (Contains, Index), replace and parse (Split, Join), but these are simple string operations. Their search is case sensitive and fixed strings. If we need to match the variable ones, we can't realize them, Of course, if the strings package can solve your problem, try to use it to solve it. Because they are simple enough, and their performance and readability will be better than regular.
If you remember, in the previous section of form validation, we have touched on regular processing, where we use it to verify whether the input information meets some preset conditions. One thing to note in use is that all characters are UTF-8 encoded. Next, let's learn more about the regexp package of Go language.
1. Match by regular
The regexp package contains three functions to judge whether it matches. If it matches, it returns true, otherwise it returns false
func Match(pattern string, b []byte) (matched bool, error error) func MatchReader(pattern string, r io.RuneReader) (matched bool, error error) func MatchString(pattern string, s string) (matched bool, error error)
The above three functions realize the same function, that is, to judge whether the pattern matches the input source. If it matches, it returns true. If there is an error in parsing the regular, it returns error. The input sources of the three functions are byte slice, RuneReader and string.
If you want to verify whether an input is an IP address, how to judge it? See the implementation below
func IsIP(ip string) (b bool) {
if m, _ := regexp.MatchString("^[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}$", ip); !m {
return false
}
return true
}
As like as two peas, we can see that the pattern of regexp is exactly the same as that of our regular system.
Let's take another example: when a user enters a string, we want to know whether it is a legal input:
func IsNum(num string)(b bool){
if m, _ := regexp.MatchString("^[0-9]+$", num); m {
return true
} else {
return false
}
}
Operation results:
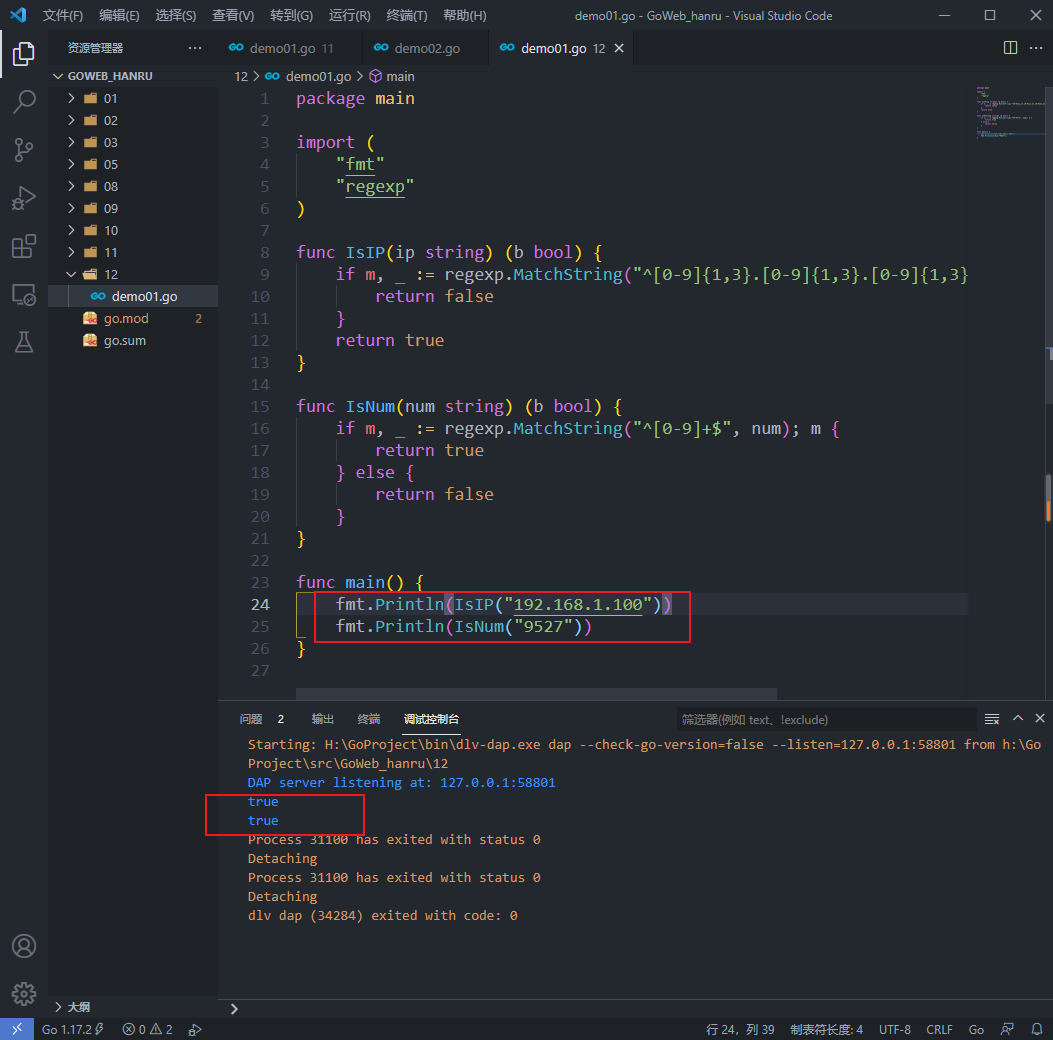
In the above two small examples, we use Match(Reader|String) to judge whether some strings meet our description requirements. They are very convenient to use.
2. Get content via regular
Match mode can only be used to judge strings, but cannot intercept a part of strings, filter strings, or extract a batch of qualified strings. If you want to meet these requirements, you need to use the complex pattern of regular expressions.
We often need some crawler programs. Let's take the crawler as an example to illustrate how to use regular to filter or intercept the captured data:
package main
import (
"io/ioutil"
"regexp"
"strings"
"net/http"
"fmt"
)
func main() {
resp, err := http.Get("http://www.baidu.com")
if err != nil {
fmt.Println("http get error.")
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println("http read error")
return
}
src := string(body)
fmt.Println(src)
fmt.Println("--------------------------------------------------------")
//Convert all HTML tags to lowercase
re, _ := regexp.Compile("\\<[\\S\\s]+?\\>")
src = re.ReplaceAllStringFunc(src, strings.ToLower)
//Remove STYLE
re, _ = regexp.Compile("\\<style[\\S\\s]+?\\</style\\>")
src = re.ReplaceAllString(src, "")
//Remove SCRIPT
re, _ = regexp.Compile("\\<script[\\S\\s]+?\\</script\\>")
src = re.ReplaceAllString(src, "")
//Remove all HTML code in angle brackets and replace with line breaks
re, _ = regexp.Compile("\\<[\\S\\s]+?\\>")
src = re.ReplaceAllString(src, "\n")
//Remove continuous line breaks
re, _ = regexp.Compile("\\s{2,}")
src = re.ReplaceAllString(src, "\n")
fmt.Println(strings.TrimSpace(src))
}
As can be seen from this example, the first thing to use complex regular expressions is Compile, which will analyze whether the regular expression is legal. If it is correct, it will return a Regexp, and then you can use the returned Regexp to perform the required operations on any string.
There are several ways to parse regular expressions:
func Compile(expr string) (*Regexp, error) func CompilePOSIX(expr string) (*Regexp, error) func MustCompile(str string) *Regexp func MustCompilePOSIX(str string) *Regexp
The difference between CompilePOSIX and Compile is that POSIX Must use POSIX syntax, which uses the leftmost and longest search method, while Compile only uses the leftmost search method (for example, when [a-z]{2,4} such a regular expression is applied to the text string "aa09aaa88aaaa", CompilePOSIX returns AAAA, while Compile returns aa). The prefix is represented by the function of Must. When parsing the regular syntax, if the matching pattern string does not meet the correct grammar, it will directly panic, and the one without Must will only return an error.
After knowing how to create a Regexp, let's take a look at the methods provided by this struct to assist us in operating strings. First, let's look at the following functions for searching:
func (re *Regexp) Find(b []byte) []byte func (re *Regexp) FindAll(b []byte, n int) [][]byte func (re *Regexp) FindAllIndex(b []byte, n int) [][]int func (re *Regexp) FindAllString(s string, n int) []string func (re *Regexp) FindAllStringIndex(s string, n int) [][]int func (re *Regexp) FindAllStringSubmatch(s string, n int) [][]string func (re *Regexp) FindAllStringSubmatchIndex(s string, n int) [][]int func (re *Regexp) FindAllSubmatch(b []byte, n int) [][][]byte func (re *Regexp) FindAllSubmatchIndex(b []byte, n int) [][]int func (re *Regexp) FindIndex(b []byte) (loc []int) func (re *Regexp) FindReaderIndex(r io.RuneReader) (loc []int) func (re *Regexp) FindReaderSubmatchIndex(r io.RuneReader) []int func (re *Regexp) FindString(s string) string func (re *Regexp) FindStringIndex(s string) (loc []int) func (re *Regexp) FindStringSubmatch(s string) []string func (re *Regexp) FindStringSubmatchIndex(s string) []int func (re *Regexp) FindSubmatch(b []byte) [][]byte func (re *Regexp) FindSubmatchIndex(b []byte) []int
The above 18 functions can be further simplified into the following functions according to different input sources (byte slice, string and io.RuneReader). The other functions are basically the same except that the input sources are different:
func (re *Regexp) Find(b []byte) []byte func (re *Regexp) FindAll(b []byte, n int) [][]byte func (re *Regexp) FindAllIndex(b []byte, n int) [][]int func (re *Regexp) FindAllSubmatch(b []byte, n int) [][][]byte func (re *Regexp) FindAllSubmatchIndex(b []byte, n int) [][]int func (re *Regexp) FindIndex(b []byte) (loc []int) func (re *Regexp) FindSubmatch(b []byte) [][]byte func (re *Regexp) FindSubmatchIndex(b []byte) []int
For the use of these functions, let's take the following example:
package main
import (
"regexp"
"fmt"
)
func main() {
a := "I am learning Go language"
re, _ := regexp.Compile("[a-z]{2,4}")
//Find the first regular
one := re.Find([]byte(a))
fmt.Println("Find:", string(one))
//Find all slices that conform to the rule. If n is less than 0, all matching strings will be returned, or the specified length will be returned
all := re.FindAll([]byte(a), -1)
fmt.Println("FindAll", all)
//Find the qualified index position, start position and end position
index := re.FindIndex([]byte(a))
fmt.Println("FindIndex", index)
//Find all index positions that meet the conditions, n as above
allindex := re.FindAllIndex([]byte(a), -1)
fmt.Println("FindAllIndex", allindex)
re2, _ := regexp.Compile("am(.*)lang(.*)")
//Find Submatch and return the array. The first element is all matched elements, the second element is in the first () and the third element is in the second ()
//The first element of the output below is "am learning Go language"
//The second element is "learning Go". Note the output with spaces
//The third element is "uage"
submatch := re2.FindSubmatch([]byte(a))
fmt.Println("FindSubmatch", submatch)
for _, v := range submatch {
fmt.Println(string(v))
}
//The definition is the same as FindIndex above
submatchindex := re2.FindSubmatchIndex([]byte(a))
fmt.Println(submatchindex)
//FindAllSubmatch to find all matching submatches
submatchall := re2.FindAllSubmatch([]byte(a), -1)
fmt.Println(submatchall)
//FindAllSubmatchIndex to find the index that matches all words
submatchallindex := re2.FindAllSubmatchIndex([]byte(a), -1)
fmt.Println(submatchallindex)
}
Operation results:
Find: am FindAll [[97 109] [108 101 97 114] [110 105 110 103] [108 97 110 103] [117 97 103 101]] FindIndex [2 4] FindAllIndex [[2 4] [5 9] [9 13] [17 21] [21 25]] FindSubmatch [[97 109 32 108 101 97 114 110 105 110 103 32 71 111 32 108 97 110 103 117 97 103 101] [32 108 101 97 114 110 105 110 103 32 71 111 32] [117 97 103 101]] am learning Go language learning Go uage [2 25 4 17 21 25] [[[97 109 32 108 101 97 114 110 105 110 103 32 71 111 32 108 97 110 103 117 97 103 101] [32 108 101 97 114 110 105 110 103 32 71 111 32] [117 97 103 101]]] [[2 25 4 17 21 25]]
As like as two peas, the Regexp function is defined as three functions, which are exactly the same as the external functions of the same name. In fact, the external functions are called the three functions of Regexp.
func (re *Regexp) Match(b []byte) bool func (re *Regexp) MatchReader(r io.RuneReader) bool func (re *Regexp) MatchString(s string) bool
Next, let's learn how replacement functions operate?
func (re *Regexp) ReplaceAll(src, repl []byte) []byte func (re *Regexp) ReplaceAllFunc(src []byte, repl func([]byte) []byte) []byte func (re *Regexp) ReplaceAllLiteral(src, repl []byte) []byte func (re *Regexp) ReplaceAllLiteralString(src, repl string) string func (re *Regexp) ReplaceAllString(src, repl string) string func (re *Regexp) ReplaceAllStringFunc(src string, repl func(string) string) string
We have detailed application examples of these replacement functions in the example of catching web pages above,
Next, let's take a look at the explanation of Expand:
func (re *Regexp) Expand(dst []byte, template []byte, src []byte, match []int) []byte func (re *Regexp) ExpandString(dst []byte, template string, src string, match []int) []byte
So what is this expansion for? Take the following example:
package main
import (
"regexp"
"fmt"
)
func main() {
src := []byte(`
call hello alice
hello bob
call hello eve
`)
pat := regexp.MustCompile(`(?m)(call)\s+(?P<cmd>\w+)\s+(?P<arg>.+)\s*$`)
res := []byte{}
for _, s := range pat.FindAllSubmatchIndex(src, -1) {
res = pat.Expand(res, []byte("$cmd('$arg')\n"), src, s)
}
fmt.Println(string(res))
}
Operation results:
hello('alice')
hello('eve')
So far, we have all introduced the regexp package of Go language. Through the introduction and demonstration of its main functions, I believe you should be able to carry out some basic regular operations through the regexp package of Go language.