Catalog
1. Preface
Based on the analysis of go1.12.5 version, the source code of map is mainly map.go in the first few files of map in runtime package.
The underlying implementation of map in go is hash table (the map in C + + is implemented by red black tree, while the new unordered_map in C++ 11 is similar to the map in go, which is implemented by hash). The data of go map is put into an ordered array of buckets, each bucket can hold up to 8 key/value pairs. The low order bits of the hash value (32 bits) of the key are used to locate the bucket in the array, while the high 8 bits are used to distinguish the key/value pairs in the bucket.
The basic unit in the hash table of go map is bucket. Each bucket can store up to 8 key value pairs. If it is exceeded, it will be linked to an additional overflow bucket. So go map is the basic data structure: hash array + key value array in bucket + overflow bucket list
When the hash table needs to be expanded beyond the threshold, a new array will be allocated, and the size of the new array is generally twice that of the old array. Here, the data is migrated from the old array to the new array without a full copy. go will dynamically move and evacuate in buckets each time the Map is read or written.
2. Data structure of go map
We first understand the basic data structure, and then look at the source code is much simpler.
2.1 core nodule
map is mainly implemented by two core structures: infrastructure and bucket
- hmap: infrastructure of map
- bmap: strictly speaking, hmap.buckets points to the array composed of buckets. The head of each bucket is bmap, followed by 8 key s, 8 value s, and finally an overflow pointer. The overflow pointer points to an additional bucket list for storing the overflow data
const ( // Key variables
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits // A bucket can store up to 8 key value pairs
loadFactorNum = 13 // Diffusion factor: loadFactorNum / loadFactorDen = 6.5.
loadFactorDen = 2 // That is, when the number of elements is > = (the number of hash buckets (2^hmp.B) * 6.5 / 8), the capacity expansion is triggered
)
// Basic data structure of map
type hmap struct {
count int // The len() function returns the count of element pairs stored in the map, so the len() time complexity of the map is O(1)
flags uint8 // Record several special bit marks, such as whether other threads are currently writing map s, and whether they are currently growing by the same size (expanding / shrinking?)
B uint8 // The number of hash buckets is 2^B
noverflow uint16 // Approximate number of buckets overflowed
hash0 uint32 // hash seeds
buckets unsafe.Pointer // Pointer to an array of 2^B buckets. The data exists here
oldbuckets unsafe.Pointer // Point to the old buckets array before expansion, only valid when the map grows
nevacuate uintptr // Counter indicating the progress of relocation after capacity expansion
extra *mapextra // Store the list of overflow buckets and the first address of the array of unused overflow buckets
}
// Realization structure of bucket
type bmap struct {
// The high byte of the hash value of each key in the tophash bucket
// Tophash [0] < mintophash indicates the evacuation status of the barrel
// In the current version, the value of bucketCnt is 8. A bucket can store up to 8 key value pairs
tophash [bucketCnt]uint8
// Special attention:
// When allocating memory, A larger memory space A will be applied. The first 8 bytes of A are bmap.
// Followed by 8 key s, 8 value s and 1 overflow pointer
// The bucket structure of map actually refers to memory space A
}
// The first input parameter of many functions in map.go is this structure. From the members' point of view, it is obvious that this structure indicates the necessary information such as key value pair and bucket size
// With the information of this structure, the code of map.go can be decoupled from the specific data type of the key value pair
// So map.go uses memory offset and unsafe.Pointer to access memory directly, without caring about the specific type of key or value
type maptype struct {
typ _type
key *_type
elem *_type
bucket *_type // internal type representing a hash bucket
keysize uint8 // size of key slot
valuesize uint8 // size of value slot
bucketsize uint16 // size of bucket
flags uint32
}C + + uses templates to generate map code according to different types.
golang transfers the type and size of key value pairs through the above-mentioned maptype structure, so map.go directly uses the pointer to operate the memory of corresponding size to realize a global map code which is applicable to different types of key value pairs at the same time. At this point, we can think that the code amount of the target file of go map will be smaller than that of C + + using template to realize map.
2.2 data structure chart
When the underlying map is created, an hmap structure will be initialized and A memory space of enough size A will be allocated at the same time. The front segment of A is used for hash array, and the back segment of A is reserved for overflow bucket. So hmap.buckets points to the hash array, which is the first address of A; hmap.extra.nextoflow initially points to the next bucket at the end of the hash array, which is the first reserved overflow bucket. Therefore, when A new overflow bucket needs to be used in A hash conflict, the reserved overflow bucket will be used first. Hmap.extra.nextoflow will offset backward in turn until all overflow buckets are used up, so it is possible to apply for A new overflow bucket space.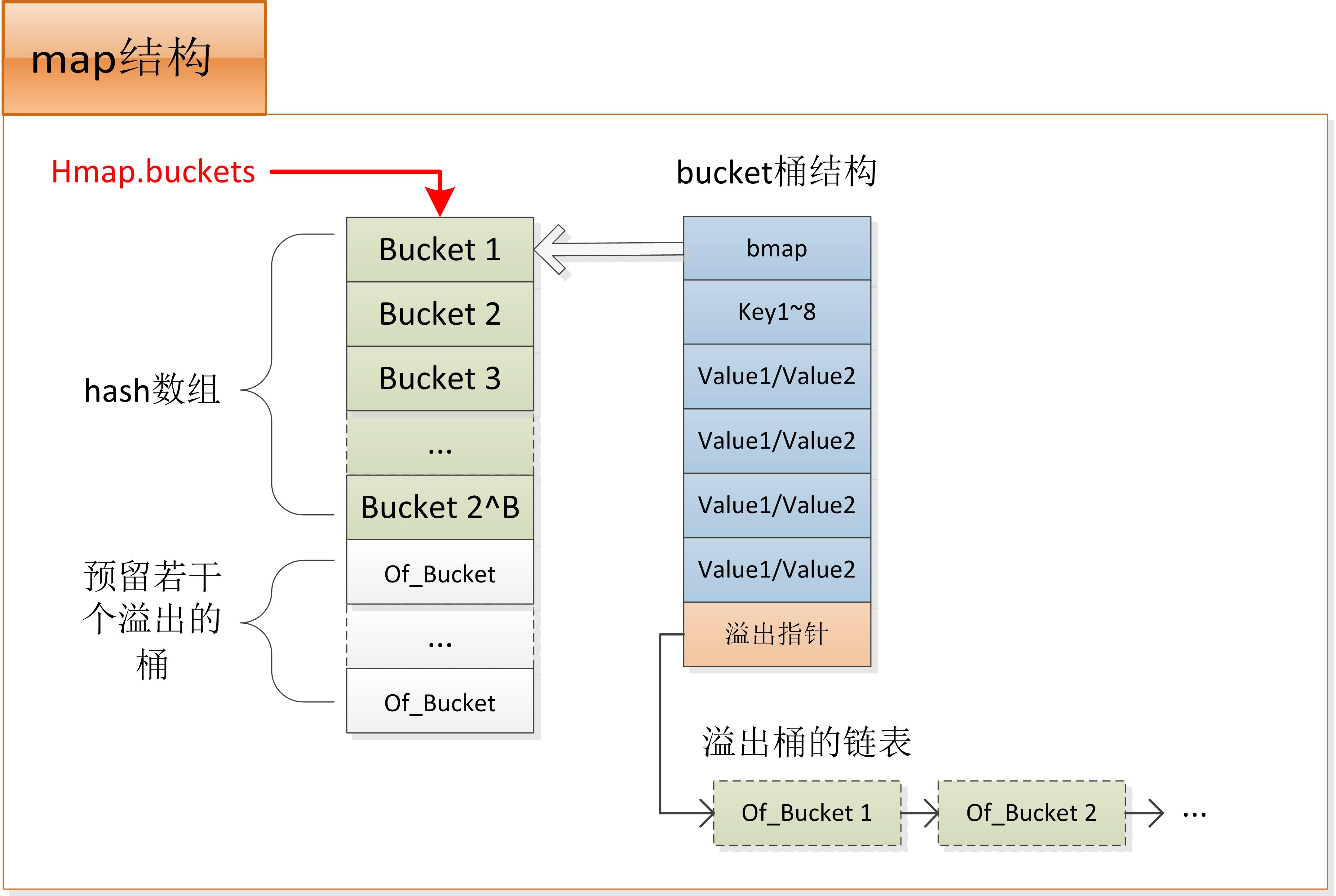
In the above figure, when an overflow bucket needs to be allocated, one of the reserved array of overflow buckets will be taken first and linked to the back of the linked list. At this time, memory does not need to be applied again. But when the reserved bucket is used up, a new memory needs to be applied for the overflow bucket.
3. Common operations of go map
3.1 create
When using make(map[k]v, hint) to create a map, the makemap() function will be called. The code logic is relatively simple.
It is worth noting that for the hash array created by makemap(), the space of the hash table is in front of the array. When hint > = 4, 2^(hint-4) buckets will be added later, and then several buckets will be added for memory page frame alignment (see the hash array part of the structure chart in Chapter 2.2)
Therefore, when creating a map, one-time memory allocation not only allocates the hash array of the user's expected size, but also appends a certain amount of reserved overflow buckets, and makes memory alignment, so that there are more than one stroke.
// make(map[k]v, hint), hint is the pre allocated size
// When not passing hint, such as creating a map with a default capacity of 0 with new, makemap only initializes the hmap structure, and does not allocate the hash array
func makemap(t *maptype, hint int, h *hmap) *hmap {
// Omit some codes
// Random hash seed
h.hash0 = fastrand()
// 2^h.B is the minimum power of 2 greater than hint * 6.5 (expansion factor)
B := uint8(0)
// Onloadfactor (hint, b) has only one line of code: return hint > bucketcnt & & uintptr (hint) > loadfactornum * (bucketshift (b) / loadfactorden)
// That is, the size of B should meet hint < = (2 ^ b) * 6.5
// A bucket can store 8 pairs of key values, so this means that the initial value of B is the minimum b value to ensure that the map can store hint pairs without expanding the capacity
for overLoadFactor(hint, B) {
B++
}
h.B = B
// Assign hash array here
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// makeBucketArray() pre allocates some overflow buckets after the hash array,
// H.extra.nexteoverflow is used to save the first address of the overflow bucket
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
// Assign hash array
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {
base := bucketShift(b) // base represents the number of buckets expected by the user, i.e. the real size of the hash array
nbuckets := base // nbuckets indicates the number of buckets actually allocated, > = base, which may append some overflow buckets as overflow reserve
if b >= 4 {
// A certain number of buckets are added here, and memory alignment is done
nbuckets += bucketShift(b - 4)
sz := t.bucket.size * nbuckets
up := roundupsize(sz)
if up != sz {
nbuckets = up / t.bucket.size
}
}
// The following code is to apply for memory space, which is omitted here
// Here, you can think about how to allocate the array space, which is actually n * sizeof (bucket), so:
// Each bucket is preceded by an 8-byte tophash array, followed by 8 key s, 8 value s, and finally an overflow pointer
// Sizeof (key) + 8 * sizeof (value) + 8
return buckets, nextOverflow
}3.2 insert or update
go map, call the mapassign() function.
Students may have learned about:
- go map needs to be initialized before it can be used. For null map insertion, panic will be used. The way the hmap pointer is passed determines that the map must be initialized before use
- go map does not support concurrent reading and writing. It will panic. If you have to be concurrent, use sync.Map or resolve the conflict yourself
The above two limitations can be found at the beginning of the mapassign() function:
- Check the validity of parameters and calculate the hash value
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// Students who are not familiar with pointer operation often step on the hole of null pointer when using pointer to transfer parameters
// Here, you can think about why h is not empty judgment?
// If you have to support empty map here and automatically initialize when the map is detected to be empty, what should you do?
// Tip: pointer to pointer
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// When concurrent write is detected, throw an exception
// Note: the concurrency detection of go map is pseudo detection, which does not guarantee that all concurrency will be detected. And this thing is tested during operation.
// Therefore, when there are concurrent requirements for map, sync.map should be used instead of normal map to block concurrent conflicts by locking
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
hash := alg.hash(key, uintptr(h.hash0)) // Here we get the hash value of uint32
h.flags ^= hashWriting // Set the Writing flag. The flag will not be cleared until the key is written to the buckets
if h.buckets == nil { // map cannot be empty, but hash array can be initially empty, which will be initialized here
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
...
}- Locate the key position in the hash table
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
again:
bucket := hash & bucketMask(h.B) // Here, we use the low order bits of the hash value to locate the subscript offset of the hash array
if h.growing() {
growWork(t, h, bucket) // This is the expansion and reduction of map. We will talk about it separately in Chapter 4
}
// By subscript bucket, offset and locate to specific bucket
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
top := tophash(hash) // Here, the 8-bit high is used to locate the key value pair in the barrel
...
}- Further locate the bucket where the key can be inserted and the position in the bucket
- Two rounds of loops, the outer loop traverses the hash bucket and the overflow list it points to, and the inner loop traverses the bucket (at most 8 key value pairs for a bucket)
- It's possible that the buckets on the list are full. At this time, the inserti is nil. Step 4 will link a new overflow bucket in
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
var inserti *uint8 // tophash insertion location
var insertk unsafe.Pointer // key insertion location
var val unsafe.Pointer // value insertion location
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && inserti == nil {
// Find a space. First record the insertion position of tophash, key and value
// But you have to traverse to determine if you want to insert it in this position, because there may be duplicate elements after it
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
}
if b.tophash[i] == emptyRest {
break bucketloop // Traverse the entire overflow list and exit the loop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if !alg.equal(key, k) {
continue
}
// Go here to find a duplicate key in the map, update the key value, and skip to step 5
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
goto done // Skip to step 5 after updating the Key
}
ovf := b.overflow(t)
if ovf == nil {
break // Traverse the entire overflow list and find no space to insert. End the cycle and add another overflow bucket
}
b = ovf // Continue to traverse the next overflow bucket
}
...
}- Insert key
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
// Let's go back to Chapter 4
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
if inserti == nil { // inserti == nil indicates that no vacancy was found in the previous step. The whole list is full. Add a new overflow bucket here
newb := h.newoverflow(t, b) // Allocate a new overflow bucket, preferentially use the overflow bucket reserved in Chapter 3.1, and allocate a new bucket memory when it is used up
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
val = add(insertk, bucketCnt*uintptr(t.keysize))
}
// When the type size of key or value exceeds a certain value, the bucket only stores the pointer of key or value. Allocate space here and take pointer
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectvalue() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(val) = vmem
}
typedmemmove(t.key, insertk, key) // Insert the key in the corresponding position in the barrel
*inserti = top // Insert the top hash, the high 8 bits of the hash value
h.count++ // New key value pair is inserted, number of h.count + 1
...
}- End insertion
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
done:
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
h.flags &^= hashWriting // Releasing the hashWriting flag bit
if t.indirectvalue() {
val = *((*unsafe.Pointer)(val))
}
return val // Returns a pointer to the position where value can be inserted. Note that value has not been inserted yet
}- Just plug in the tophash and key, and it's over? value hasn't been inserted yet
- Yes, mapassign() only inserts tophash and key, and returns val pointer. The compiler will use assembly to insert value into val after calling mapassign()
- Is google's grumpy operation to reduce the number of value transfers?
3.3 delete
- Similar to inserting, the previous steps are to judge the parameters and status, locate the key value location, and then clear the corresponding memory. Don't expand. Here are some key points:
- hashWriting flag will also be set during deletion
- When the key/value is too large, a pointer is stored in the hash table. At this time, soft delete is used. Set the pointer to nil, and the data is handed over to gc for deletion. Of course, this is the internal processing of map, the outer layer is imperceptible, and all you get are value copies
- Whether the Key/value is a value type or a pointer type, the deletion only affects the hash table, and the data obtained by the outer layer is not affected. Especially for pointer type, the outer pointer can still be used
- Because the way to locate the key position is to find the tophash, the key is to delete the tophash
- map first sets the tophash[i] of the corresponding location to emphasis one, indicating that the location has been deleted
- If tophash[i] is not the last of the entire linked list, only the emptyOne flag will be set, and the location will be deleted but not released. This location cannot be used for subsequent insertion operations
- If tophash[i] is the last valid node in the list, then set all the positions marked as emptyOne at the back of the list to emptyRest. The location set to emptyRest can be used in subsequent insert operations.
- In this way, a small amount of space is used to avoid the data movement in bucket list and bucket. In fact, once the go data is inserted into the bucket's exact location, the map will no longer move the data's location in the bucket.
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
...
b.tophash[i] = emptyOne // Mark delete first
// If b.tophash[i] is not the last element, the pit will be occupied temporarily. The emptyOne tag cannot be inserted into a new element temporarily (see inserting functions in Chapter 3.2)
if i == bucketCnt-1 {
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
if b.tophash[i+1] != emptyRest {
goto notLast
}
}
for { // If b.tophash[i] is the last element, set the end of the emptyOne all clear to emptyRest
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break // beginning of initial bucket, we're done.
}
// Find previous bucket, continue at its last entry.
c := b
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}
...
}3.4 search
The lookup operation is implemented by a set of functions beginning with mapacess. Before inserting or deleting the previous chapters, you need to locate and find the elements. The logic is similar and simple. Let's not go into details:
- Mapacess1(): search through Key, return value pointer, used for Val: = map [Key]. Returns a 0 value of type value when not found.
- Mapacesses2(): returns the value pointer through key search, and the sign of success of bool type search. It is used for Val, OK: = map [key]. Returns a 0 value of type value when not found.
- Mapacessk(): search by key, return key and value pointer, used for the range. Null pointer when not found
- Mapacess1 ﹐ fat(), which encapsulates mapacess1(), the difference is that mapacess1 ﹐ fat() has more zero parameters and returns zero if it is not found
- Mapacess2 ﹤ fat(), which is also the encapsulation of mapacess1(). Compared with mapacess1 ﹐ fat(), this function adds a flag to determine whether the search is successful
3.5 range iteration
The iteration of map is realized by the structure of hiter and two corresponding auxiliary functions. The Hier structure is created and passed in by the compiler before calling auxiliary functions, and the result of each iteration is also passed back by the Hier structure. The it below is the pointer variable of the hiter structure.
3.5.1 initialize iterator mapiterinit()
The mapiterinit() function mainly determines where we start iterating, and why we start iterating from, rather than directly from the hash array header? go programming language seems to mention that the position of data inserted in the hash table changes every time (actually because of the implementation, on the one hand, the hash seed is random, which results in different hash values of the same data in different map variables; on the other hand, even in the same map variable, the position of data deletion and RE addition may also change, because in the same bucket and In order to prevent the user from depending on the order of each iteration, the map author simply makes the order of each iteration of the same map random.
The implementation method of iterative sequence random is also simple, starting directly from a random position:
- it.startBucket: This is the offset of the hash array, indicating that the traversal starts from this bucket
- it.offset: This is the offset in the bucket, which means that the traversal of each bucket starts from this offset
Thus, the map traversal process is as follows:
- Starting from the bucket it.startBucket in the hash array, first traverse the hash bucket, and then the overflow list of the bucket.
- After that, the hash array offset + 1 to continue the previous step.
- Traversing each bucket, whether hash bucket or overflow bucket, starts with the it.offset offset offset. (if it's just a random bucket at the beginning, the range result is still orderly; but each bucket is added with it.offset offset offset, and the output result is a bit confusing. You can try to range the same map several times by yourself.)
- When the iterator returns to the position of it.startBucket after a cycle, the traversal ends.
func mapiterinit(t *maptype, h *hmap, it *hiter) {
...
// Start with a random offset
r := uintptr(fastrand())
if h.B > 31-bucketCntBits {
r += uintptr(fastrand()) << 31
}
it.startBucket = r & bucketMask(h.B)
it.offset = uint8(r >> h.B & (bucketCnt - 1))
...
mapiternext(it) // Initializing the iterator also returns the first pair of key/value
}3.5.2 iterative process mapiternext()
The process of the iteration cycle in the previous section is very clear. Here we show several important parameters:
- it.startBucket: the starting bucket
- it.offset: offset at the beginning of each bucket
- it.bptr: currently traversed bucket
- it.i: the number of key value pairs that it.bptr has traversed. i is initially 0. When i=8, it means that this bucket has traversed. Move it.bptr to the next bucket
- it.key: results of each iteration
- it.value: the result of each iteration
In addition, the iteration also needs to pay attention to the expansion and reduction of capacity:
- If it is growing after the start of the iteration, the current logic does not handle this situation, and the iteration may be abnormal. Well, go map does not support concurrency.
- If it's growing first and then iterating, it's possible. In this case, first check whether the bucket corresponding to the key is evacuated in the old hash table. If not, traverse the old bucket. If already evacuated, traverse the bucket corresponding to the new hash table.
4. Capacity expansion and reduction of go map
4.1 basic principle of capacity expansion
The capacity expansion and reduction of go map are all grow th related functions. Here, the capacity expansion is true and the capacity reduction is false. I will explain later. Let's first look at the trigger conditions:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
...
}
// If onloadfactor() returns true, the capacity expansion will be triggered, that is, the count of map is greater than the number of hash buckets (2^B)*6.5
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}
// tooManyOverflowBuckets(), as the name suggests, too many overflow buckets trigger shrink
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}map only triggers whether to expand or shrink the capacity in the insert element, namely mapassign() function. The condition is the above code:
- Condition 1: not currently growing
- Condition 2-1: trigger capacity expansion: the data amount count of map is greater than the number of hash buckets (2^B)*6.5. Note that (2^B) here is only the hash array size, excluding the overflow bucket
- Condition 2-2: trigger shrink: the number of overflowing buckets noverflow > = 32768 (1 < < 15) or > = hash array size.
Observe the triggered code carefully. The expansion and reduction are the same function. How can this be done? At the beginning of hashGrow(), it will first determine whether the expansion conditions are met. If it is met, it means that the expansion is this time. If it is not met, it must be triggered by the expansion conditions. The main difference between the remaining logic of capacity expansion and capacity reduction is the capacity change, that is, the hmap.B parameter. When capacity expansion is B+1, the capacity of hash table will be doubled. When capacity reduction is performed, the capacity of hash table will not change.
- h.oldbuckets: points to the old hash array, i.e. the current h.buckets
- h.buckets: points to the newly created hash array
The main work triggered here has been completed. Next is how to move the elements to the new hash table. If a full migration is done now, it is obvious that the map will be occupied for a long time (concurrency is not supported). So the work of relocation is asynchronous incremental relocation.
In the insert and delete functions, the following code is used to perform a move every time the insert and delete operations occur:
if h.growing() { // Currently in relocation status
growWork(t, h, bucket) // Call move function
}
func growWork(t *maptype, h *hmap, bucket uintptr) {
// Move the barrels that need to be handled at present
evacuate(t, h, bucket&h.oldbucketmask())
if h.growing() { // Move another bucket
evacuate(t, h, h.nevacuate)
}
}- Every time an insert or delete is performed, growWork will be called to move 0-2 hash buckets (it is possible that the 2 buckets that need to be moved this time have been moved before this)
- The relocation is based on the hash bucket, including the corresponding hash bucket and the overflow list of this bucket
- The delete d element (emptyone flag) will be discarded (this is the key to volume reduction)
4.2 why is it called "pseudo shrinkage"? How to realize "true shrinkage"?
Now we can explain why I call the reduction of map pseudo reduction: because the reduction is only for the case of too many overflow buckets, the size of the hash array is the same when the reduction is triggered, that is, the space occupied by the hash array is only increased or not decreased. In other words, if we delete all the elements that have grown to a large map one by one, the memory space occupied by the hash table will not be released.
So if you want to realize "true shrink", you need to realize shrink and move by yourself, that is, to create a smaller map, and move the elements of the map that need to shrink one by one:
// go map shrink code example
myMap := make(map[int]int, 1000000)
// Suppose we insert bigMap many times, and then delete it many times. At this time, the number of elements in bigMap is far smaller than the hash table size
// And then we start to shrink
smallMap := make(map[int]int, len(myMap))
for k, v := range myMap {
smallMap[k] = v
}
myMap = smallMap // After the shrink is completed, the original map is discarded by us and sent to gc for cleaning5 Q & a key knowledge points
5.1 basic principles
- The bottom layer is the hash implementation. The data structure is hash array + bucket + overflow bucket list. Each bucket can store up to 8 key value pairs
- The principle of search and insert: the hash value (low-order bit) of key is the same as the number of buckets, and the hash bucket of key is obtained. Then the high 8 bits of key are compared with the top hash [i] in bucket. If the same, the key value is further compared. If the key value is the same, the key value is found
- go map does not support concurrency. Insert, delete, move and other operations will set the writing flag, and concurrent direct panic will be detected
- Each time the hash table is doubled, the hash table only increases
- Limited capacity reduction is supported. The delete operation only sets the delete flag bit. The space to release the overflow bucket depends on triggering capacity reduction.
- Map must be initialized before use, otherwise panic: the initialized map is made (map [key] value) or make(map[key]value, hint). new or var xxx map[key]value are uninitialized and can be used directly.
5.2 time and space complexity analysis
Time complexity. go map is a hash implementation. Regardless of the specific principle, the time complexity of Jianghu routine hash implementation is called O(1):
- Under normal conditions, and regardless of the capacity expansion state, the complexity O(1): locate the bucket as O(1) by hash value, with a bucket of up to 8 elements. A reasonable hash algorithm should be able to hash the elements relatively evenly, so the overflow list (if any) will not be too long. Therefore, although locating the key on the bucket and overflow list is traversal, considering the small number, it can be considered as O(1)
- Normally, in the capacity expansion state, the complexity is also O(1): compared with the previous state, the capacity expansion will increase the time consumption of moving up to 2 barrels and overflow list. When the overflow list is not too long, the complexity can also be considered as O(1)
- In the extreme case, the hash is very uneven, most of the data is concentrated on a Hash list, and the complexity is reduced to O(n).
The hash algorithm used in go should be very mature, and the extreme situation will not be considered temporarily. So the time complexity of go map should be O(1)
Spatial complexity analysis:
First of all, we don't consider the space waste caused by deleting a large number of elements (in this case, go is left to the programmer to solve by himself). We only consider one space utilization of a map in a growing state:
Because the number of overflow buckets exceeds the number of hash buckets, the capacity reduction will be triggered, so the worst case is that the data is concentrated on a chain, the hash table is basically empty, and the space is wasted O(n).
In the best case, the data is uniformly hashed on the hash table without element overflow. At this time, the best spatial complexity is determined by the diffusion factor. Currently, the diffusion factor of go is determined by the global variable, that is, loadFactorNum/loadFactorDen = 6.5. That is, when each hash bucket is allocated to more than 6.5 elements on average, the capacity expansion starts. So the minimum space waste is (8-6.5) / 8 = 0.1875, that is O(0.1875n)
Conclusion: the spatial complexity of go map is between O (0.1875n) and O (n).