math/rand package crypto/rand package generates random numbers
- This part is supplementary and does not involve concurrency
1. math/rand package
- math/rand package implements the pseudo-random number generator
1.1 main methods
(1)func Seed(seed int64)
Set random seed. If not set, the default seed is (1)
(2)func Int() int
Returns a nonnegative pseudo-random int value
(3)func Int31() int32
Returns a nonnegative 31 bit pseudo-random number of type int32
(4)func Int63() int64
Returns a nonnegative 63 bit pseudo-random number of type int64
(5)func Intn(n int) int
Returns a pseudo-random int value with a value range of [0,n). If n < = 0, it will panic
(6)func Int31n(n int32) int32
Returns a pseudo-random int32 value with a value range of [0,n). If n < = 0, it will panic
(7)func Int63n(n int64) int64
Returns a pseudo-random int64 value with a value range of [0, n). If n < = 0, it will panic
(8)func Float32() float32
Returns a pseudo-random float32 value with a value range of [0.0, 1.0]
(9)func Float64() float64
Returns a pseudo-random float64 value with a value range of [0.0, 1.0]
(10)func Perm(n int) []int
Returns a pseudo-random slice of integers in the range [0,n) with n elements
1.2 example
package main
import (
"fmt"
"math/rand"
"time"
)
func main() {
rand.Seed(time.Now().Unix()) //If random seed is not set, the result will be the same every time
fmt.Println(rand.Intn(10))
fmt.Println(rand.Float64())
//Set random seed
rand.Seed(time.Now().UnixNano())
fmt.Println(rand.Intn(10))
fmt.Println(rand.Float64())
//Random number slice
fmt.Println(rand.Perm(5))
}
1.3. rand.Seed(time.Now().UnixNano()) function:
- Obtain random numbers without random seeds. Each traversal obtains some repeated random data
- rand.Seed(time.Now().UnixNano()) sets the random number seed. With this line of code, you can ensure that every random number is random
package main
import (
"fmt"
"math/rand"
"time"
)
func main() {
rand.Seed(time.Now().Unix()) // When we compile the code and execute the executable file, the random number generated remains unchanged, so we need to add this seed code
for i := 0; i <= 5; i++ {
r1 := rand.Int() // Number of int64 randomly generated
r2 := rand.Intn(10) // Specify a random number in the range, [0~max)
fmt.Println(r1, r2)
}
}
2. crypto/rand package
- The crypto/rand package implements a more secure random number generator for encryption and decryption
2.1 main methods
(1)func Int(rand io.Reader, max *big.Int) (n *big.Int, err error)
Returns a random value that obeys uniform distribution in the interval [0, max). If Max < = 0, it will panic
(2)func Prime(rand io.Reader, bits int) (p *big.Int, err error)
Returns a number with a specified word number (binary number), which is highly likely to be a prime number. If there is an error reading from rand, or bits < 2, an error will be returned
(3)func Read(b []byte) (n int, err error)
This function is an auxiliary function that calls Reader.Read using io.ReadFull. If and only if err == nil, the return value n == len(b)
2.2 code example
package main
import (
"crypto/rand"
"encoding/base64"
"fmt"
"math/big"
)
func main() {
//1,Int
n, err := rand.Int(rand.Reader, big.NewInt(128))
if err == nil {
fmt.Println("rand.Int: ", n, n.BitLen())
}
//2,Prime
p, err := rand.Prime(rand.Reader, 5)
if err == nil {
fmt.Println("rand.Prime: ", p)
}
//3,Read
b := make([]byte, 32)
m, err := rand.Read(b)
if err == nil {
fmt.Println("rand.Read: ", b[:m])
fmt.Println("rand.Read: ", base64.URLEncoding.EncodeToString(b))
}
}
Output results
rand.Int: 62 6 rand.Prime: 29 rand.Read: [94 77 69 89 129 128 135 213 37 53 73 101 0 33 186 128 123 230 56 129 32 168 95 61 61 128 176 133 26 168 52 56] rand.Read: Xk1FWYGAh9UlNUllACG6gHvmOIEgqF89PYCwhRqoNDg=
Concurrent programming in Go language
1. Concurrency and parallelism
-
Understanding concurrency and parallelism
- Concurrency: perform multiple tasks at the same time (you are chatting with two girlfriends on wechat).
- Parallel: perform multiple tasks at the same time (you and your friends are chatting with your girlfriend on wechat).
-
The concurrency of Go language is realized through goroutine.
- Goroutines are similar to threads and belong to user state threads. We can create thousands of goroutine s to work concurrently as needed.
- goroutine is scheduled by the runtime of Go language, while threads are scheduled by the operating system.
-
The Go language also provides a channel for communication between multiple goroutine s.
- goroutine and channel are the important implementation basis of CSP (communication sequential process) concurrency mode inherited by Go language.
2,goroutine
-
When we want to implement concurrent programming in java/c + +, we usually need to maintain a thread pool, wrap one task after another, and schedule threads to execute tasks and maintain context switching. All this usually consumes a lot of minds of programmers. Can there be a mechanism that programmers only need to define many tasks Let the system help us allocate these tasks to the CPU for concurrent execution?
-
Goroutine in go language is such a mechanism. The concept of goroutine is similar to thread, but goroutine is composed of go runtime Scheduling and management. Go programs will intelligently allocate tasks in goroutine to each CPU. Go language is called a modern programming language because it has built-in scheduling and context switching mechanisms at the language level.
-
In Go language programming, you don't need to write processes, threads and collaborations by yourself. There is only one skill in your skill package - goroutine. When you need to make a task execute concurrently, you just need to package the task into a function and open a goroutine to execute the function. It's so simple and rough.
2.1. Use goroutine
-
Using goroutine in go language is very simple. You can create a goroutine for a function by adding the go keyword in front of the function call.
-
A goroutine must correspond to a function. You can create multiple goroutines to execute the same function.
2.2. Start a single goroutine
- The way to start goroutine is very simple. You only need to add a go keyword in front of the called functions (ordinary functions and anonymous functions).
The following example: the output result is only main, because the execution of the main() function is over, and the gorouting started by the main() function is also over
func hello() {
fmt.Println("hello world")
}
// Program startup is actually creating a main gorouting to execute
func main() {
go hello() // When calling a function, you can start a gorouting by adding the go keyword in front of it. (start a gorouting to run the function separately)
fmt.Println("main") // Only main is output because this line of code executes too fast. After main is output, the function execution ends.
}
The result is
main
- We add sleep after the main function to delay the end time, as follows
func hello() {
fmt.Println("hello world")
}
// Program startup is actually creating a main gorouting to execute
func main() {
go hello() // When calling a function, you can start a gorouting by adding the go keyword in front of it. (start a gorouting to run the function separately)
fmt.Println("main")
time.Sleep(1)
}
The output is
main hello world
2.3. sync.WaitGroup synchronization gorouting
- It is so simple to implement concurrency in Go language. We can also start multiple goroutine s.
- sync.WaitGroup can synchronize with gorouting. After running, the main gorouting will end
- The Add() method of sync.WaitGroup will count + 1 every time a gorouting is started
- For the Down() method of sync.WaitGroup, the count will be - 1 every time a gorouting ends
- Wait() method of sync.WaitGroup, waiting for all gorouting s to be executed
Example: sync.WaitGroup is used here to synchronize goroutine (better than sleep)
var wg sync.WaitGroup
func hello(i int) {
defer wg.Done() // Registration at the end of goroutine - 1
fmt.Println("Hello Goroutine!", i)
}
func main() {
for i := 0; i < 10; i++ {
wg.Add(1) // Start a goroutine to register + 1
go hello(i)
}
wg.Wait() // Wait wg for the counter to decrease to zero
}
Output results
Hello Goroutine! 0 Hello Goroutine! 9 Hello Goroutine! 4 Hello Goroutine! 1 Hello Goroutine! 2 Hello Goroutine! 3 Hello Goroutine! 6 Hello Goroutine! 5 Hello Goroutine! 7 Hello Goroutine! 8 // If you execute the above code several times, you will find that the order of numbers printed each time is inconsistent. This is because 10 goroutines are executed concurrently, and the scheduling of goroutines is random.
3. goroutine and thread
3.1. Scalable stack
- OS threads (operating system threads) generally have fixed stack memory (usually 2MB). A goroutine stack has only a small stack (typically 2KB) at the beginning of its life cycle. The goroutine stack is not fixed. It can be increased and reduced as needed. The stack size limit of goroutine can reach 1GB, although it is rarely used. Therefore, it is also possible to create about 100000 goroutines in Go language at a time.
3.2 goroutine scheduling
-
GPM is the implementation of go language runtime level. It is a set of scheduling system implemented by go language itself. It is different from operating system scheduling OS threads.
-
G is a goroutine, which not only stores the goroutine information, but also the binding with the P.
-
P manages a group of goroutine queues. P will store the context (function pointer, stack address and address boundary) of the current goroutine operation. P will make some scheduling for the goroutine queues it manages (such as pausing goroutines that occupy a long CPU time, goroutines that continue to run, etc.). When its own queue is consumed, it will go to the global queue to get it, If the global queue is also consumed, it will grab tasks from other p queues.
-
M (machine) is the virtual of the kernel thread of the operating system by the Go runtime. M and the kernel thread are generally mapped one by one, and a root is finally executed on M; It's real work
-
P and m generally correspond to each other. Their relationship is that P manages a group of G to mount and run on M. When a G is blocked on an M for a long time, the runtime will create a new m, and the P where the blocked G is located will mount other G on the new m. Reclaim the old m when the old G is blocked or considered dead.
-
The number of P is set by runtime.GOMAXPROCS (maximum 256). After Go1.5, it defaults to the number of physical threads. When the concurrency is large, some p and M will be added, but not too much. If the switching is too frequent, the gain is not worth the loss.
-
-
In terms of thread scheduling alone, the advantage of Go language over other languages is that OS threads are scheduled by the OS kernel, while goroutine is scheduled by the Go runtime's own scheduler, which uses a technology called m:n scheduling (multiplexing / scheduling m goroutines to n OS threads).
- One of its characteristics is that goroutine scheduling is completed in the user state, which does not involve frequent switching between kernel state and user state, including memory allocation and release. A large memory pool is maintained in the user state, and the malloc function of the system is not called directly (unless the memory pool needs to be changed). The cost is much lower than that of scheduling OS threads.
- On the other hand, it makes full use of multi-core hardware resources, approximately divides several goroutines on physical threads, and the ultra lightweight goroutines ensure the performance of go scheduling.
Reference address: https://www.cnblogs.com/sunsky303/p/9705727.html
3.3. Setting of the maximum number of threads used by GOMAXPROCS
- The Go runtime scheduler uses the GOMAXPROCS parameter to determine how many OS threads need to be used to execute Go code at the same time. The default value is the number of CPU cores on the machine. For example, on an 8-core machine, the scheduler will schedule the Go code to 8 OS threads at the same time (GOMAXPROCS is n in m:n scheduling).
- In Go language, you can set the number of CPU logical cores occupied by the current program during concurrency through the runtime.GOMAXPROCS() function.
- Before Go1.5, single core execution was used by default. After Go1.5, all CPU logical cores are used by default
Example: setting the maximum number of threads to 1 means that only one thread works, so the two gorouting s in the following example are ordered and executed one by one
var wg sync.WaitGroup
func f1() {
defer wg.Done()
for i := 0; i < 5; i++ {
fmt.Printf("A: %d\n", i)
}
}
func f2() {
defer wg.Done()
for i := 0; i < 5; i++ {
fmt.Printf("B: %d\n", i)
}
}
func main() {
// Set the maximum number of threads to 1. If it is not set, the maximum number of threads of the system will be turned on by default
runtime.GOMAXPROCS(1)
// Set the count value to 2 and start two gorouting s
wg.Add(2)
go f1()
go f2()
wg.Wait()
}
Output results
B: 0 B: 1 B: 2 B: 3 B: 4 A: 0 A: 1 A: 2 A: 3 A: 4
Example 2: if the number of threads is set to more than 2, multiple goroutings can be found to execute concurrently. The number of concurrent goroutings is 2
The output results are as follows
B: 0 B: 1 A: 0 B: 2 A: 1 B: 3 A: 2 B: 4 A: 3 A: 4
- Relationship between operating system threads and goroutine in Go language:
- One operating system thread has multiple goroutine s for the application user state.
- go programs can use multiple operating system threads at the same time.
- goroutine and OS threads are many to many, i.e. m:n (m gorouting s are allocated to n OS threads for execution)
4,channel
-
Simply executing functions concurrently is meaningless. Functions need to exchange data between functions to reflect the significance of concurrent execution of functions.
-
Although shared memory can be used for data exchange, shared memory is prone to race problems in different goroutine s. In order to ensure the correctness of data exchange, the memory must be locked with mutex, which is bound to cause performance problems.
-
The concurrency model of Go language is CSP (Communication Sequential Processes), which advocates sharing memory through communication rather than sharing memory.
-
If goroutine is the concurrent executor of Go program, channel is the connection between them. Channel is a communication mechanism that allows one goroutine to send a specific value to another goroutine.
-
Channel in Go language is a special type. The channel is like a conveyor belt or queue. It always follows the First In First Out rule to ensure the order of sending and receiving data. Each channel is a conduit of a specific type, that is, the element type needs to be specified when declaring the channel.
4.1. channel type
- Channel is a type and a reference type. You need to specify the element type in the channel.
- The format for declaring the channel type is as follows:
- var variable chan element type
Example:
var ch1 chan int // Declare a channel that passes an integer var ch2 chan bool // Declare a channel that passes a Boolean var ch3 chan []int // Declare a channel that passes int slices
4.2. Create a channel
1. Note:
- A channel is a reference type and cannot be used directly. It is directly declared as a null value nil of the channel type.
- The declared channel can only be used after it is initialized with the make function.
var ch chan int fmt.Println(ch) // <nil>
2. The format of creating a channel is as follows:
- The buffer size of channel is optional.
make(chan Element type, [Buffer size])
- Example:
ch4 := make(chan int) ch5 := make(chan bool) ch6 := make(chan []int)
func main() {
ch1 := make(chan int)
fmt.Println(ch1) // 0xc00005c060
}
Function of buffer: with a buffer, data can be sent to the buffer and wait for the receiver to receive. If there is no buffer, you need to receive and send.
4.3. channel operation
- The channel has three operations: send, receive and close.
- The < - symbol is used for both sending and receiving.
Example:
# First define a channel ch := make(chan int) # Send to send the value to the defined channel ch <- 10 // Send 10 to ch # Receive: receives a value from a channel x := <- ch // Receives the value from ch and assigns it to the variable x <-ch // Receive values from ch, ignoring results # To close the channel, we call the built-in close function to close the channel. close(ch)
-
Supplement:
- The thing to note about closing the channel is that the channel needs to be closed only when the receiver is notified that all data of goroutine has been sent.
- The channel can be recycled by the garbage collection mechanism. It is different from closing the file. Closing the file after the operation is necessary, but closing the channel is not necessary.
-
The closed channel has the following characteristics:
1. Sending a value to a closed channel will result in panic.
2. Receiving a closed channel will get the value until the channel is empty.
3. Performing a receive operation on a closed channel with no value will result in a corresponding type of zero value.
4. Closing a closed channel will cause panic.
4.4 non buffered channel
Unbuffered channels are also called blocked channels.
The following example: this code can be compiled, but errors will occur during execution:
func main() {
ch := make(chan int)
ch <- 10
fmt.Println("Sent successfully")
}
Errors are reported as follows
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.main()
.../src/github.com/Q1mi/studygo/day06/channel02/main.go:8 +0x54
- The reason for deadlock error is:
- Because we use ch: = make (Chan int) to create an unbuffered channel. Unbuffered channels can send values only when someone receives them. Just as there is no express cabinet and collection point in your community, the courier must send this item to you when calling you. In short, the unbuffered channel must be received before sending. Therefore, ch < - 10 in the above code sends the value to the channel but does not receive it, forming a deadlock.
- Solution: enable a gorouting to receive values. The example is as follows
func recv(c chan int) {
ret := <-c
fmt.Println("Received successfully", ret)
}
func main() {
ch := make(chan int)
go recv(ch) // Enable goroutine to receive values from the channel
ch <- 10
fmt.Println("Sent successfully")
}
Supplement:
-
The sending operation on the unbuffered channel will be blocked until another goroutine performs the receiving operation on the channel. At this time, the value can be sent successfully, and the two goroutines will continue to execute. Conversely, if the receive operation is performed first, the receiver's goroutine will block until another goroutine sends a value on the channel.
-
Using unbuffered channels for communication will result in goroutine synchronization of sending and receiving. Therefore, the unbuffered channel is also called the synchronous channel.
4.5 buffered channel
-
Another way to solve the above problem is to use channels with buffers. We can specify the capacity of the channel when initializing the channel with the make function.
-
As long as the capacity of the channel is greater than zero, the channel is a buffered channel. The capacity of the channel indicates the number of elements that can be stored in the channel. Just like the express cabinet in your community has only so many grids. When the grid is full, it can't fit, and it's blocked. When someone else takes one, the courier can put one in it.
-
We can use the built-in len function to obtain the number of elements in the channel and the cap function to obtain the capacity of the channel, although we rarely do so.
Example:
func main() {
ch := make(chan int, 1) // Create a buffered channel with a capacity of 1
ch <- 10
fmt.Println("Sent successfully")
}
# Similarly, if the capacity is 1, only one data can be temporarily stored. If the data is not received and a data is sent to the channel, an error will be reported
4.6 cyclic values from channels
- When sending data to the channel, we can close the channel through the close function.
- When the channel is closed, sending a value to the channel will trigger panic. The operation of taking values from the channel will first get the values in the channel, and then the obtained values are always zero values of the corresponding type.
- How to judge whether a channel is closed? There are two ways:
- Method 1: use two variables to receive the value sent by the channel. When the channel is closed, ok in the following example is false
- In this way, the channel needs to be closed manually after the value is taken
- In this way, when the channel we get the value has no value, the variable receiving the value will return a null value of the corresponding value type, and the ok variable will return false
- Method 2: use for range to traverse the channel. When the channel is closed, it will exit for range. This method is more commonly used
- Method 1: use two variables to receive the value sent by the channel. When the channel is closed, ok in the following example is false
Example:
// channel exercise
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
// Turn on goroutine to send the number from 0 to 100 to ch1
go func() {
for i := 0; i < 10; i++ {
ch1 <- i
}
close(ch1)
}()
// Turn on goroutine to receive the value from ch1 and send the square of the value to ch2
go func() {
for {
i, ok := <-ch1 // After the channel is closed, the value is ok=false
if !ok {
break
}
ch2 <- i * i
}
close(ch2)
}()
// Receive print values from ch2 in the main goroutine
for i := range ch2 { // The for range loop exits when the channel is closed
fmt.Println(i)
}
}
Output results
0 1 4 9 16 25 36 49 64 81
Example explanation: the difference between for range and for I, OK: = < - Chan
/*
In the following example, f2 cannot use range to traverse the value in the channel, because if range is used, f1 and f2 are executed at the same time. At this time, channel ch2 in f2 closes the ch2 channel directly after it does not obtain the value in f1, resulting in an error that the value in channel ch1 has no receiver
- Solution: use the ok method to traverse the values in the received ch1 channel. After all the values are sent to ch1, the ch1 channel will be closed. ok will return false and exit the cycle. At the same time, the values in the ch1 channel have been passed to ch2. After exiting the cycle, the ch2 channel will also be closed.
- f1 When executed simultaneously with f2, each value passed in channel ch1 will be received by ch2. There is no need to define the cache size, but ch2 is traversed by for range only after all the values of ch1 are received, so caching is required
*/
func f1(ch1 chan int) {
defer wg.Done()
for i := 0; i < 10; i++ {
ch1 <- i
}
close(ch1)
}
func f2(ch1, ch2 chan int) {
defer wg.Done()
for {
i, ok := <-ch1
if !ok {
break
}
ch2 <- i * i
}
// close(ch2)
once.Do(func() { close(ch2) }) // Use the Do() method in sync.Once to ensure that the function in parentheses is executed only once, that is, when we call f2 function many times, close(ch2) is executed only once
}
func main() {
wg.Add(3)
go f1(ch1)
go f2(ch1, ch2)
go f2(ch1, ch2)
wg.Wait()
for x := range ch2 {
fmt.Println(x)
}
}
4.7 one way channel
- Sometimes we will pass the channel as a parameter between multiple task functions. Many times, when we use the channel in different task functions, we will restrict it. For example, we can only send or receive the channel in the function.
- The Go language provides a one-way channel to handle this situation.
- Unidirectional channels are mostly used for function parameters (to ensure that only one operation can be performed on the channel passed in the function)
- Chan < - int is a write only one-way channel (only int type values can be written to it), which can be sent but not received;
- < - Chan int is a read-only one-way channel (only int type values can be read from it). It can receive but not send.
It is possible to convert a two-way channel into a one-way channel in any assignment operation, but the reverse is not possible
- It is possible to convert a two-way channel into a one-way channel in any assignment operation, but the reverse is not possible
Example:
// Write only unidirectional channel type Chan < - int
func counter(out chan<- int) {
for i := 0; i < 10; i++ {
out <- i
}
close(out)
}
// Write only unidirectional channel type Chan < - int
func squarer(out chan<- int, in <-chan int) {
for i := range in {
out <- i * i
}
close(out)
}
// Read only one-way channel type < - Chan int
func printer(in <-chan int) {
for i := range in {
fmt.Println(i)
}
}
func main() {
var out = make(chan int)
var in = make(chan int)
go counter(out) // Open a coroutine to write the value to the out channel
go squarer(in, out) // Open another co process to calculate the value in the out channel and write it to the in channel
printer(in) // Use range to read the value in the in channel
}
4.8 channel summary
Common channel exceptions are summarized as follows:
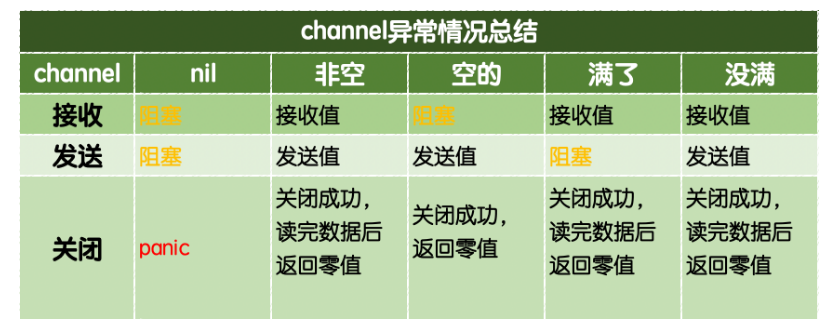
Closing a closed channel will also cause panic.
5. worker pool (goroutine pool)
- In work, we usually use the worker pool mode, which can specify the number of goroutines to start, to control the number of goroutines and prevent goroutines from leaking and soaring.
func worker(id int, jobs <-chan int, results chan<- int) {
for j := range jobs {
fmt.Printf("worker:%d start job:%d\n", id, j)
time.Sleep(time.Second)
fmt.Printf("worker:%d end job:%d\n", id, j)
results <- j * 2
}
}
func main() {
jobs := make(chan int, 10)
results := make(chan int, 10)
// Open three goroutine s, that is, open three workers
for w := 1; w <= 3; w++ {
go worker(w, jobs, results)
}
// 5 tasks, passing in 5 values to the channel
for j := 1; j <= 5; j++ {
jobs <- j
}
close(jobs)
// Output results
for a := 1; a <= 5; a++ {
<-results // The value of result is accepted, but the value is not used
}
}
Output: there are three worker s to perform work
worker:3 start job:1 worker:1 start job:2 worker:2 start job:3 worker:1 end job:2 worker:1 start job:4 worker:3 end job:1 worker:3 start job:5 worker:2 end job:3 worker:3 end job:5 worker:1 end job:4
6. select multiplexing
- In some scenarios, we need to receive data from multiple channels at the same time. When receiving data, the channel will be blocked if there is no data to receive. You may write the following code to implement it by traversal, as follows:
for{
// Try to receive a value from ch1, and if it is not OK, continue down
data, ok := <-ch1
// Attempt to receive value from ch2
data, ok := <-ch2
...
}
# This method does not achieve the effect of randomly taking values from a channel, but is still executed downward in sequence
- Although the above method can meet the requirements of receiving values from multiple channels, the operation performance will be much worse. To cope with this scenario, Go has a built-in select keyword, which can respond to the operations of multiple channels at the same time.
- The use of select is similar to a switch statement. It has a series of case branches and a default branch.
- Each case corresponds to the communication (receiving or sending) process of a channel.
- select will wait until the communication operation of a case is completed, and the statement corresponding to the case branch will be executed.
- The specific format is as follows:
select{
case <-ch1:
...
case data := <-ch2:
...
case ch3<-data:
...
default:
Default action
}
Example: use select to randomly match and execute from the following two case s
- Use select to randomly match and execute from the following two case s
- In the first cycle, two cases are randomly matched. There is no value in ch1 of the first case. Execute the second case and send 0 to the channel.
- In the second cycle, since the buffer of the channel is only 1, only one value can be placed, so the second case cannot be matched. Continue to send the value and execute the case with the first value.
- The third time... The nth time, and so on
func main() {
fmt.Println()
var ch1 = make(chan int, 1)
for i := 0; i < 10; i++ {
select {
case x := <-ch1:
fmt.Println(x)
case ch1 <- i:
}
}
}
Output results
0 2 4 6 8
- Using the select statement can improve the readability of the code.
- It can process the send / receive operation of one or more channel s.
- If multiple case s are satisfied at the same time, select will randomly select one.
- select {} without case will wait all the time and can be used to block the main function.
- Usage scenario: randomly take values from one channel at a time
7. Concurrent security and locks
- Sometimes in Go code, multiple goroutine s may operate a resource (critical area) at the same time, which will lead to race (data race).
- Compared with examples in real life, crossroads are competed by cars from all directions; And the bathroom on the train was competed by the people in the carriage.
Example: in the following code, we have enabled two goroutines to accumulate the value of variable x. when these two goroutines access and modify the X variable, there will be data competition, resulting in the final result inconsistent with the expectation. (there is a problem with the execution on windows. If you can't see the effect, use mac)
var x int64
var wg sync.WaitGroup
func add() {
for i := 0; i < 5000; i++ {
x = x + 1
}
wg.Done()
}
func main() {
wg.Add(2)
go add()
go add()
wg.Wait()
fmt.Println(x)
}
7.1. Mutex
- Mutex is a common method to control the access of shared resources. It can ensure that only one goroutine can access shared resources at the same time. Mutex type of sync package is used to implement mutex in Go language.
- Using a mutex lock can ensure that only one goroutine enters the critical zone at the same time, and the other goroutines are waiting for the lock; When the mutex is released, the waiting goroutines can acquire the lock and enter the critical area. When multiple goroutines wait for a lock at the same time, the wake-up strategy is random.
var x int64
var wg sync.WaitGroup
var lock sync.Mutex // Define a mutex
func add() {
for i := 0; i < 5000; i++ {
lock.Lock() // Lock
x = x + 1
lock.Unlock() // Unlock
}
wg.Done()
}
func main() {
wg.Add(2)
go add()
go add()
wg.Wait()
fmt.Println(x)
}
7.2. Read write mutex
-
Mutually exclusive locks are completely mutually exclusive, but there are many actual scenarios where there are more reads and less writes. When we read a resource concurrently and do not involve resource modification, it is not necessary to lock. In this scenario, using read-write locks is a better choice. Read write locks use the RWMutex type in the sync package in the Go language.
-
There are two kinds of read-write locks: read lock and write lock.
- When a goroutine acquires a read lock, other goroutines will continue to acquire a lock if they acquire a read lock,
- If the write lock is obtained, it will wait; When a goroutine acquires a write lock, other goroutines will wait whether they acquire a read lock or a write lock.
- That is, when a gorouting obtains a read lock, other goroutings can still read it; However, if a gorouting acquires a write lock, other goroutings cannot be read or written (to prevent the user from updating the write when reading, resulting in the read being not the latest)
var (
x int64
wg sync.WaitGroup
lock sync.Mutex
rwlock sync.RWMutex // Define read / write lock
)
func write() {
// lock.Lock() / / add mutex lock
rwlock.Lock() // Write lock
x = x + 1
time.Sleep(10 * time.Millisecond) // Assume that the read operation takes 10 milliseconds
rwlock.Unlock() // Write unlock
// lock.Unlock() / / unlock the mutex
wg.Done()
}
func read() {
// lock.Lock() / / add mutex lock
rwlock.RLock() // Read lock
time.Sleep(time.Millisecond) // Suppose the read operation takes 1 ms
rwlock.RUnlock() // Interpretation lock
// lock.Unlock() / / unlock the mutex
wg.Done()
}
func main() {
start := time.Now()
for i := 0; i < 10; i++ {
wg.Add(1)
go write()
}
for i := 0; i < 1000; i++ {
wg.Add(1)
go read()
}
wg.Wait()
end := time.Now()
fmt.Println(end.Sub(start))
}
7.3,sync.WaitGroup
- It is certainly inappropriate to use time.Sleep rigidly in the code. Sync. Waitgroup can be used in Go language to synchronize concurrent tasks. sync.WaitGroup
- sync.WaitGroup internally maintains a counter whose value can be increased and decreased.
- For example, when we start N concurrent tasks, we increase the counter value by N. When each task is completed, the counter is decremented by 1 by calling the Done() method. Wait for the execution of concurrent tasks by calling Wait(). When the counter value is 0, it indicates that all concurrent tasks have been completed.
| Method name | function |
|---|---|
| (wg * WaitGroup) Add(delta int) | Counter + delta |
| (wg *WaitGroup) Done() | Counter-1 |
| (wg *WaitGroup) Wait() | Blocks until the counter becomes 0 |
Example
var wg sync.WaitGroup
func hello() {
defer wg.Done()
fmt.Println("Hello Goroutine!")
}
func main() {
wg.Add(1)
go hello() // Start another goroutine to execute the hello function
fmt.Println("main goroutine done!")
wg.Wait()
}
It should be noted that sync.WaitGroup is a structure, and the pointer should be passed when passing.
7.4,sync.Once
-
In many programming scenarios, we need to ensure that certain operations are executed only once in high concurrency scenarios, such as loading the configuration file only once, closing the channel only once, etc.
-
The sync package in the Go language provides a solution for a scenario that is executed only once: sync.Once.
-
sync.Once has only one Do method, and the Do() method can only receive a function with no parameters and no return value. Its signature is as follows:
func (o *Once) Do(f func()) {} (Note: if the function f to be executed needs to pass parameters, it needs to be used with closures.)
1. Example of loading a configuration file:
- It is a good practice to delay an expensive initialization operation until it is actually used. Because initializing a variable in advance (such as completing initialization in init function) will increase the startup time of the program, and it may not be used in the actual execution process, the initialization operation is not necessary. Examples are as follows:
var icons map[string]image.Image
func loadIcons() {
icons = map[string]image.Image{
"left": loadIcon("left.png"),
"up": loadIcon("up.png"),
"right": loadIcon("right.png"),
"down": loadIcon("down.png"),
}
}
// Icon is not concurrency safe when called by multiple goroutine s
func Icon(name string) image.Image {
if icons == nil {
loadIcons()
}
return icons[name]
}
- When multiple goroutines call Icon functions concurrently, it is not concurrent and safe. Modern compilers and CPU s may freely rearrange the order of accessing memory on the basis of ensuring that each goroutine meets the serial consistency. The loadIcons function may be rearranged to the following results:
func loadIcons() {
icons = make(map[string]image.Image)
icons["left"] = loadIcon("left.png")
icons["up"] = loadIcon("up.png")
icons["right"] = loadIcon("right.png")
icons["down"] = loadIcon("down.png")
}
-
In this case, even if it is judged that the icons are not nil, it does not mean that the variable initialization is completed. Considering this situation, the way we can think of is to add mutexes to ensure that other goroutine operations will not be performed when initializing icons, but doing so will cause performance problems.
-
The example code of using sync.Once transformation is as follows:
var icons map[string]image.Image
var loadIconsOnce sync.Once
func loadIcons() {
icons = map[string]image.Image{
"left": loadIcon("left.png"),
"up": loadIcon("up.png"),
"right": loadIcon("right.png"),
"down": loadIcon("down.png"),
}
}
// Icon is concurrency safe
func Icon(name string) image.Image {
loadIconsOnce.Do(loadIcons)
return icons[name]
}
2. Concurrent secure singleton mode
The following is a single instance mode of concurrency security with sync.Once:
package singleton
import (
"sync"
)
type singleton struct {}
var instance *singleton
var once sync.Once
func GetInstance() *singleton {
once.Do(func() {
instance = &singleton{}
})
return instance
}
sync.Once actually contains a mutex and a Boolean value. The mutex ensures the security of Boolean values and data, and the Boolean value is used to record whether the initialization is completed. This design can ensure that the initialization operation is concurrent and safe, and the initialization operation will not be executed many times.
7.5,sync.Map
- The built-in map in the Go language is not concurrency safe. (there will be an error when the map is operated concurrently)
Look at the following example: when I operate a map concurrently, if the concurrency is less than 20 gorouting s, generally there will be no problem, but if it exceeds 20, an error will occur
var m = make(map[string]int)
func get(key string) int {
return m[key]
}
func set(key string, value int) {
m[key] = value
}
func main() {
wg := sync.WaitGroup{}
// for i := 0; i < 20; i++ {
for i := 0; i < 21; i++ { // If we open 21 gorouting s at this time, an error will be reported
wg.Add(1)
go func(n int) {
key := strconv.Itoa(n)
set(key, n)
fmt.Printf("k=:%v,v:=%v\n", key, get(key))
wg.Done()
}(i)
}
wg.Wait()
}
Errors are reported as follows:
goroutine 25 [semacquire]:
internal/poll.runtime_Semacquire(0x9)
E:/GolangPATH/src/runtime/sema.go:61 +0x25
internal/poll.(*fdMutex).rwlock(0xc00007a280, 0xf4)
E:/GolangPATH/src/internal/poll/fd_mutex.go:154 +0xd2
internal/poll.(*FD).writeLock(...)
E:/GolangPATH/src/internal/poll/fd_mutex.go:239
internal/poll.(*FD).Write(0xc00007a280, {0xc00008e140, 0xc, 0x10})
E:/GolangPATH/src/internal/poll/fd_windows.go:598 +0x6c
os.(*File).write(...)
E:/GolangPATH/src/os/file_posix.go:49
os.(*File).Write(0xc000006018, {0xc00008e140, 0xc, 0xc000135f98})
E:/GolangPATH/src/os/file.go:176 +0x65
fmt.Fprintf({0x137ee0, 0xc000006018}, {0x117b7d, 0xc}, {0xc000135f98, 0x2, 0x2})
E:/GolangPATH/src/fmt/print.go:205 +0x9b
fmt.Printf(...)
E:/GolangPATH/src/fmt/print.go:213
main.main.func1(0x12)
E:/GoProject/src/gitee.com/LTP/test/main.go:27 +0x11b
created by main.main
E:/GoProject/src/gitee.com/LTP/test/main.go:24 +0x38
-
There may be no problem when the above code starts a small number of goroutine s. When there is more concurrency, the above code will report a fatal error: concurrent map writes error.
-
In such a scenario, you need to lock the map to ensure concurrency security
- The sync package of Go language provides a concurrent secure version of map – sync.Map out of the box.
- Out of the box means that you can use it directly without using the make function initialization like the built-in map.
- Meanwhile, sync.Map has built-in operation methods such as Store, Load, LoadOrStore, Delete and Range.
An example of using sync.Map {} is as follows: if you need to perform concurrent operations on a map, you can use sync.Map {}
// Define a secure map in the sync package (somewhat different from the built-in map)
var m = sync.Map{}
func main() {
wg := sync.WaitGroup{}
for i := 0; i < 25; i++ {
wg.Add(1)
go func(value int) {
key := strconv.Itoa(value)
// The Store() method of sync.Map {} is used to store key value pairs. Parameter 1 is the new key and parameter 2 is the corresponding value. (map[key] = value corresponding to the built-in map)
m.Store(key, value)
// The Load() method of sync.Map {} is used to get the value of the corresponding key. (corresponding to the value of the built-in map = map [key])
v, ok := m.Load(key)
if !ok {
fmt.Println("map Failed to get value")
return
}
fmt.Printf("k=:%v,v:=%v\n", key, v)
wg.Done()
}(i)
}
wg.Wait()
}
8. Atomic operation
- In the above code, we implement synchronization through lock operation.
- The bottom layer of the locking mechanism is based on atomic operation, which is generally implemented directly through CPU instructions.
- Atomic operations in Go language are provided by the built-in standard library sync/atomic.
8.1 atomic package
| method | explain |
|---|---|
| func LoadInt32(addr *int32) (val int32) func LoadInt64(addr *int64) (val int64) func LoadUint32(addr *uint32) (val uint32) func LoadUint64(addr *uint64) (val uint64) func LoadUintptr(addr *uintptr) (val uintptr) func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer) | read operation |
| func StoreInt32(addr *int32, val int32) func StoreInt64(addr *int64, val int64) func StoreUint32(addr *uint32, val uint32) func StoreUint64(addr *uint64, val uint64) func StoreUintptr(addr *uintptr, val uintptr) func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer) | Write operation |
| func AddInt32(addr *int32, delta int32) (new int32) func AddInt64(addr *int64, delta int64) (new int64) func AddUint32(addr *uint32, delta uint32) (new uint32) func AddUint64(addr *uint64, delta uint64) (new uint64) func AddUintptr(addr *uintptr, delta uintptr) (new uintptr) | Modify operation |
| func SwapInt32(addr *int32, new int32) (old int32) func SwapInt64(addr *int64, new int64) (old int64) func SwapUint32(addr *uint32, new uint32) (old uint32) func SwapUint64(addr *uint64, new uint64) (old uint64) func SwapUintptr(addr *uintptr, new uintptr) (old uintptr) func SwapPointer(addr *unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer) | Exchange operation |
| func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool) func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool) func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool) func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool) func CompareAndSwapUintptr(addr *uintptr, old, new uintptr) (swapped bool) func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool) | Compare and exchange operations |
Example: in the following example, a security lock is used to + 1 the variable x.
- Atomic operations the atomic package directly provides a method for adding int64 numbers
var lock sync.Mutex
var x int64
var wg sync.WaitGroup
func f() {
lock.Lock()
x++
wg.Done()
lock.Unlock()
}
func main() {
wg.Add(1000)
for i := 0; i < 1000; i++ {
go f()
}
wg.Wait()
fmt.Println(x)
}
Example 2: modify the above example to add int64 numbers using the methods in the atomic package
- Atomic.addint64 (& X, 1) parameter 1 is a variable pointer of int64 type, and parameter 2 represents the number incremented each time (here, x increments by 1 every time, x + +)
var x int64
var wg sync.WaitGroup
func f() {
defer wg.Done()
atomic.AddInt64(&x, 1)
}
func main() {
wg.Add(1000)
for i := 0; i < 1000; i++ {
go f()
}
wg.Wait()
fmt.Println(x) // 1000
}
Example 3: compare and exchange usage
func main() {
// Compare and exchange
var num = int64(100)
// atomic.CompareAndSwapInt64(), pass the pointer of int64 type variable into parameter 1 and compare the value of parameter 2. If they are equal, then exchange the values and assign the value of parameter 3 to the variable
ok := atomic.CompareAndSwapInt64(&num, 100, 10)
if !ok {
fmt.Println("The values of variables are not equal")
return
}
fmt.Println(num)
}
Example 4: let's fill in an example to compare the performance of mutual exclusion and atomic operation.
package main
import (
"fmt"
"sync"
"sync/atomic"
"time"
)
type Counter interface {
Inc()
Load() int64
}
// Ordinary Edition
type CommonCounter struct {
counter int64
}
func (c CommonCounter) Inc() {
c.counter++
}
func (c CommonCounter) Load() int64 {
return c.counter
}
// Mutex version
type MutexCounter struct {
counter int64
lock sync.Mutex
}
func (m *MutexCounter) Inc() {
m.lock.Lock()
defer m.lock.Unlock()
m.counter++
}
func (m *MutexCounter) Load() int64 {
m.lock.Lock()
defer m.lock.Unlock()
return m.counter
}
// Atomic operation Edition
type AtomicCounter struct {
counter int64
}
func (a *AtomicCounter) Inc() {
atomic.AddInt64(&a.counter, 1)
}
func (a *AtomicCounter) Load() int64 {
return atomic.LoadInt64(&a.counter)
}
func test(c Counter) {
var wg sync.WaitGroup
start := time.Now()
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
c.Inc()
wg.Done()
}()
}
wg.Wait()
end := time.Now()
fmt.Println(c.Load(), end.Sub(start))
}
func main() {
c1 := CommonCounter{} // Non concurrent security
test(c1)
c2 := MutexCounter{} // Concurrency security using mutex
test(&c2)
c3 := AtomicCounter{} // Concurrency is safe and more efficient than mutex
test(&c3)
}
- Atomic package provides the underlying atomic memory operation, which is very useful for the implementation of synchronization algorithm. These functions must be used with caution. In addition to some special underlying applications, it is better to use the function / type of channel or sync package to achieve synchronization.
practice
- gorouting and channel are used to calculate the sum of int64 random numbers
- 1. Turn on gorouting to randomly generate int64 bit random numbers and send them to jobchan
- 2. Open 24 gorouting worms. jobchan takes out random numbers, calculates the sum of their digits, and sends the results to resultchan
- 3. The main gorouting takes the result from resultChan and prints it to
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
type job struct {
value int64
}
type result struct {
job *job
sum int64
}
var jobChan = make(chan *job, 100)
var resultChan = make(chan *result, 100)
var wg sync.WaitGroup
func f1(jc chan<- *job) {
defer wg.Done()
for {
num := rand.Int63n(100)
// fmt.Println(num)
newJob := &job{
value: num,
}
jc <- newJob
time.Sleep(500 * time.Millisecond)
}
}
func f2(ret chan *result, jc <-chan *job) {
defer wg.Done()
// Obtain the random number from jobChan, and obtain the number of bits of the random number for summation calculation
for {
sum := int64(0)
job := <-jc
n := job.value
for n > 0 {
sum += (n % 10)
n = n / 10
}
newret := &result{
job: job,
sum: sum,
}
ret <- newret
}
}
func main() {
wg.Add(1)
go f1(jobChan)
// time.Sleep(10 * time.Second)
wg.Add(10)
for i := 0; i < 10; i++ {
go f2(resultChan, jobChan)
}
for i := range resultChan {
fmt.Println(i.job.value, i.sum)
}
wg.Wait()
}