preface
Channels is a type safe message queue. It acts as a pipeline between two goroutines, through which any resources will be exchanged synchronously. chan's ability to control goroutines interaction creates a Go synchronization mechanism. When the created chan has no capacity, it is called an unbuffered channel. Conversely, a chan created using capacity is called a buffered channel. To understand the synchronization behavior of goroutine interacting through chan, we need to know the type and state of the channel. The scenarios will vary depending on whether we use unbuffered or buffered channels, so let's discuss each scenario separately.
Use skills
Channel read / write feature (15 word formula)
First, let's review the features of Channel?
-
Send data to a nil channel, causing permanent blocking
-
Receiving data from a nil channel causes permanent blocking
-
Send data to a closed channel, causing panic
-
Receive data from a closed channel. If the buffer is empty, a zero value is returned
-
Unbuffered channels are synchronous, while buffered channels are asynchronous
The above five features are dead things, which can also be memorized through the formula: "empty read-write blocking, write off exception, read off empty zero".
Use of channel
Unbuffered Channels -- Unbuffered Channels
Unbuffered chan has no capacity, so two goroutines need to be prepared at the same time before any exchange. When goroutine attempts to send a resource to an unbuffered channel and no goroutine is waiting to receive the resource, the channel will lock the sending goroutine and make it wait. When goroutine attempts to receive from an unbuffered channel and no goroutine is waiting to send resources, the channel will lock the receiving goroutine and make it wait.
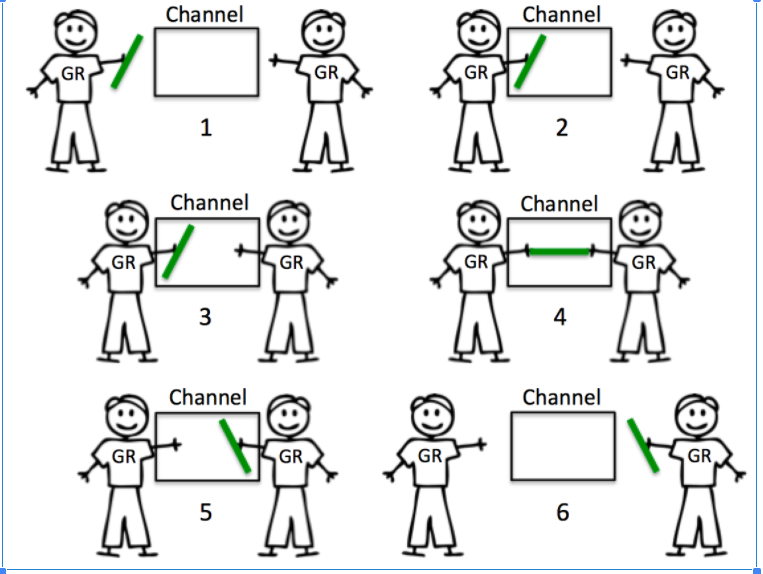
Synchronization is inherent in the interaction between sending and receiving. It can't happen without another. The essence of unbuffered channel is to ensure synchronization
example
ch := make(chan int)
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
ch <- 1
}()
go func() {
defer wg.Done()
id := <-ch
fmt.Println(id)
}()
wg.Wait()g2 must wait for the data sent by g1 to chen to be synchronized
A goroutine is blocked after sending the message foo because no receiver is ready. This behavior is well explained in the specification:
https://golang.org/ref/spec#Channel_types
If the capacity is zero or absent, the channel is unbuffered and communication succeeds only when both a sender and receiver are ready.
If the capacity is zero or does not exist, the channel is not buffered, and the communication can succeed only when both the sender and the receiver are ready.
https://golang.org/doc/effective_go.html#channels
If the channel is unbuffered, the sender blocks until the receiver has received the value
If the channel is not buffered, the sender will block until the receiver receives the value
Receive occurs before Send.
Benefits: 100% guaranteed.
Cost: unknown delay time.
Buffered Channels
Buffer channels have capacity, so they can behave a little differently. When goroutine attempts to send resources to the buffer channel and the channel is full, the channel will lock goroutine and wait until the buffer becomes available. If there is space in the channel, the transmission can be carried out immediately, and the channel can continue to move forward. When goroutine attempts to receive from the buffer channel, and the buffer channel is empty, the channel will lock goroutine and wait until the resource is sent
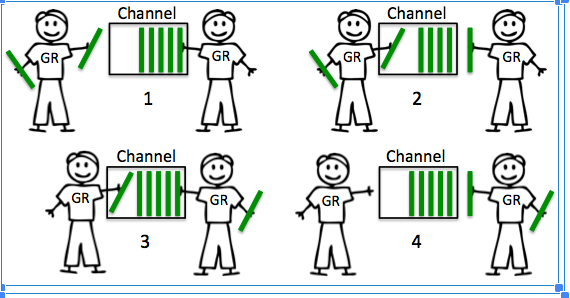
ch := make(chan int,2)
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
ch <- 1
ch <- 2
}()
go func() {
defer wg.Done()
id := <-ch
id1 := <-ch
fmt.Println(id,id1)
}()
wg.Wait()Delay due to insufficient buffer size
No, the bigger the cache, the better. See the following example
//give up
func main() {
const cap = 5
ch := make(chan int,cap)
go func() {
for p := range ch{
fmt.Println("Received:",p)
}
}()
const work = 20
for i := 0; i < work; i++ {
select {
case ch <- i:
fmt.Println("afferent--",i)
default:
fmt.Println("drep")
}
}
}If the cache is full, the data written in the next time will be lost, causing an impact
Let's look at the following example. What's the short processing time?
package bench
import (
"sync"
"sync/atomic"
"testing"
)
func BenchmarkWithNoBuffer(b *testing.B) {
benchmarkWithBuffer(b, 0)
}
func BenchmarkWithBufferSizeOf1(b *testing.B) {
benchmarkWithBuffer(b, 1)
}
func BenchmarkWithBufferSizeEqualsToNumberOfWorker(b *testing.B) {
benchmarkWithBuffer(b, 5)
}
func BenchmarkWithBufferSizeExceedsNumberOfWorker(b *testing.B) {
benchmarkWithBuffer(b, 25)
}
func benchmarkWithBuffer(b *testing.B, size int) {
for i := 0; i < b.N; i++ {
c := make(chan uint32, size)
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
for i := uint32(0); i < 1000; i++ {
c <- i%2
}
close(c)
}()
var total uint32
for w := 0; w < 5; w++ {
wg.Add(1)
go func() {
defer wg.Done()
for {
v, ok := <-c
if !ok {
break
}
atomic.AddUint32(&total, v)
}
}()
}
wg.Wait()
}
}goos: windows goarch: amd64 pkg: 03-go-concurrency/sync_test/07 BenchmarkWithNoBuffer BenchmarkWithNoBuffer-6 4297 3527 02 ns/op BenchmarkWithBufferSizeOf1 BenchmarkWithBufferSizeOf1-6 4297 2780 72 ns/op BenchmarkWithBufferSizeEqualsToNumberOfWorker BenchmarkWithBufferSizeEqualsToNumberOfWorker-6 6015 2104 72 ns/op BenchmarkWithBufferSizeExceedsNumberOfWorker BenchmarkWithBufferSizeExceedsNumberOfWorker-6 8594 1412 05 ns/op PASS
A properly sized buffer can really make your application faster! Let's analyze the trace of the benchmark to determine the location of the delay.
Send occurs before Receive.
Benefit: less latency.
Cost: data arrival is not guaranteed. The larger the buffer, the smaller the guaranteed arrival. When buffer = 1, you are guaranteed to delay a message.
Three examples
Timing out
timeout := make(chan bool, 1)
ch := make(chan int, 1)
go func() {
time.Sleep(1 * time.Second)
timeout <- true
}()
select {
case <-ch:
// a read from ch has occurred
case <-timeout:
// the read from ch has timed out
}A good example is timeout. Although the Go channel does not directly support them, they are easy to implement. Say we want to receive ch from the channel, but it will take up to one second to get the value. We will first create a signaling channel and start a channel that is asleep before sending a signal through the channel
Then, we can use the select statement to receive from CH or timeout. If nothing reaches the ch after one second, select the timeout case and abandon the attempt to read from the ch.
The timeout channel is buffered with a space of 1, allowing the timeout channel to be sent to the channel and then exit. Goroutine does not know (or care) whether it receives a value. This means that goroutine will not stay here forever if ch reception occurs before timeout. The timeout channel will eventually be released by the garbage collector.
woker worker model
import (
"errors"
"fmt"
"runtime"
"sync"
"sync/atomic"
)
//Interface
type PoolWorker interface {
DoWork(WorkRoutine int)
}
//poolWork is passed to the queue of work to be performed.
type Poolwork struct {
work PoolWorker //Tasks to be performed
resultChannel chan error //Task return information
}
var ErrCapacity = errors.New("Thread Pool At Capacity")
type WorkPool struct {
shutdownQueueChannel chan string // Close the channel of the queue
shutdownWorkChannel chan struct{} // Close the working channel
shutdownWaitGroup sync.WaitGroup //Used to close an existing work
queueChannel chan Poolwork // The channel used to synchronize access to the queue.
workChannel chan PoolWorker //Channels for working
queuedWorkNum int32 // Number of jobs queued
activeRoutinesNum int32 //Number of active work
queueCapacityNum int32 // The maximum number of items that can be stored in the queue.
}
func New(WorkRoutinesNum int,queueCapacityNum int32) *WorkPool {
workPool := WorkPool{
shutdownQueueChannel: make(chan string),
shutdownWorkChannel: make(chan struct{}),
queueChannel: make(chan Poolwork),
workChannel: make(chan PoolWorker),
queuedWorkNum: 0,
activeRoutinesNum: 0,
queueCapacityNum: queueCapacityNum,
}
//Open group
workPool.shutdownWaitGroup.Add(WorkRoutinesNum)
//Start work
for i := 0; i < WorkRoutinesNum; i++ {
go workPool.workRoutine(i)
}
//Start queue
go workPool.queueRoutine()
return &workPool
}
//stop it
func (this *WorkPool) Shutdown() (err error) {
//Capture error
defer func() {
if r := recover(); r != nil {
buf := make([]byte, 10000)
runtime.Stack(buf, false)
fmt.Println(string(buf))
err = fmt.Errorf("%v", r)
}
}()
fmt.Println("Shutdown : Queue Routine")
//Notify the process accepting the task to stop
this.shutdownQueueChannel <- "down"
//After the task acceptance process returns
<-this.shutdownQueueChannel
//Close the shutdown queuechannel
close(this.shutdownQueueChannel)
//accept an assignment
close(this.queueChannel)
//Close working Routine
close(this.shutdownWorkChannel)
//Waiting for work process reduction
this.shutdownWaitGroup.Wait()
//Close working chen
close(this.workChannel)
return err
}
//work
func (this *WorkPool) workRoutine(workRoutineId int) {
for {
select {
case <-this.shutdownWorkChannel: //Accept close
fmt.Println("workRoutine : ",workRoutineId,"Ending")
this.shutdownWaitGroup.Done() //Reduce synergy
return
case item := <- this.workChannel: //accept an assignment
this.doWork(item,workRoutineId)
break
}
}
}
//Perform tasks
func (this *WorkPool) doWork(work PoolWorker,workRoutineId int) {
defer fmt.Println("Execution complete")
defer atomic.AddInt32(&this.activeRoutinesNum,-1) //Reduction of work coordination
atomic.AddInt32(&this.activeRoutinesNum,1) //Increase of work coordination process
atomic.AddInt32(&this.queuedWorkNum,-1) //Waiting task reduction
work.DoWork(workRoutineId)
}
//Add task
func (this *WorkPool) PostWork (goRoutine string,worker PoolWorker) (err error) {
defer fmt.Println("goRoutine err: ",err)
poolwork := Poolwork{work: worker,resultChannel: make(chan error)}
this.queueChannel <- poolwork //Add task to task chen
err = <- poolwork.resultChannel //Synchronization wait error
close(poolwork.resultChannel) //Close result chen
return err //Return error
}
func (this *WorkPool) queueRoutine() {
for {
select {
case <-this.shutdownQueueChannel: //Accept task chen termination signal
fmt.Println("Terminate accepting tasks")
this.shutdownQueueChannel <- "down" //Reply received termination signal
return
case queueItem := <- this.queueChannel: //Accept tasks synchronously
//Whether the maximum number of items that can be stored in the processing task queue has been reached.
if atomic.AddInt32(&this.queuedWorkNum,0) == this.queueCapacityNum{
queueItem.resultChannel <- ErrCapacity
break
}
atomic.AddInt32(&this.queuedWorkNum,1) //Increase the maximum number of items stored
this.workChannel <- queueItem.work //Deliver to work chen
queueItem.resultChannel <- nil // Return nil
break
}
}
}The following is the logic of the call. Please note that the workflow should not be opened too much
type MyTask struct {
Name string
OrderId int
WP *workpool.WorkPool
}
func (mt *MyTask) DoWork(workRoutine int) {
fmt.Println(mt.Name)
fmt.Printf("*******> WR: %d QW : %d AR: %d\n",
workRoutine,
1,
2)
fmt.Println(mt.OrderId)
time.Sleep(100 * time.Millisecond)
}
func main() {
runtime.GOMAXPROCS(runtime .NumCPU())
workPool := workpool.New(runtime.NumCPU() * 3, 100)
task := MyTask{
Name: "A" + strconv.Itoa(1),
OrderId : 1,
WP: workPool,
}
err := workPool.PostWork("main",&task)
workPool.Shutdown()
fmt.Println(err)
}summary
When using channels (or concurrency), it is important to understand and understand the signaling attributes surrounding guarantees, channel states, and transmissions. They will help guide you through the best behavior required for the concurrent programs and algorithms you are writing. They will help you find errors and sniff out potential error codes.
stages close their outbound channels when all the send operations are done.
When all sending operations are completed, stages closes their outbound channels.
stages keep receiving values from inbound channels until those channels are closed or the senders are unblocked.
The phase keeps receiving values from inbound channels until they are closed or unblocked by the sender.
Pipelines unblock senders either by ensuring there's enough buffer for all the values that are sent or by explicitly signalling senders when the receiver may abandon the channel.
The pipeline can unblock the sender by ensuring that there is sufficient buffer to accommodate all transmitted values, or by explicitly sending the sender's signal when the receiver may abandon the channel
- Use channels to orchestrate and coordinate goroutine.
- Focus on channel properties rather than data sharing.
- Signaling with or without data.
- Question their use for synchronous access to shared state.
- In some cases, the channel can be simpler, but it is initially questionable.
- Unbuffered channel:
- Reception occurs before transmission.
- Advantages: 100% guarantee that the signal has been received.
- Cost: unknown delay when receiving signal.
- Buffer channel:
- Sending occurs before receiving.
- Benefits: reduce blocking delay between signals.
- Cost: there is no guarantee when the signal will be received.
- The larger the buffer, the less guaranteed.
- A buffer of 1 can provide you with a guarantee of delayed sending.
Design concept
- If any given Send on the channel can cause the Send goroutine to block:
- Buffered channels greater than 1 are not allowed.
- Buffers greater than 1 must have a reason / measure.
- You must know what happens when sending goroutine blocking.
- Buffered channels greater than 1 are not allowed.
- If any given Send on the channel does not cause the Send goroutine to block:
- You have the exact number of buffers per send.
- Fan out mode
- You measured the maximum size of the buffer.
- Drop pattern
- You have the exact number of buffers per send.
- Fewer buffers means more.
- Do not consider performance when considering buffers.
- Buffers can help reduce blocking delays between signals.
- Reducing blocking latency to zero does not necessarily mean better throughput.
- If a buffer provides you with good enough throughput, keep it.
- The problem buffer is greater than 1 and the size is measured.
- Find the smallest buffer that may provide good enough throughput.
literature
https://medium.com/a-journey-with-go/go-buffered-and-unbuffered-channels-29a107c00268
https://www.ardanlabs.com/blog/2014/02/the-nature-of-channels-in-go.htm
https://www.ardanlabs.com/blog/2013/10/my-channel-select-bug.html
https://blog.golang.org/concurrency-timeouts
https://blog.golang.org/pipelines
https://talks.golang.org/2013/advconc.slide#1
https://github.com/go-kratos/kratos/tree/master/pkg/sync