1, Git installation
windows installation: enter the website https://git-scm.com/ Download the installation, and then
cmd command line configuration
Go directly to Tencent software center to download!
> git config --global user.name "itnanls"
> git config --global user.email "itnanls@163.com"
#Check whether the information is written successfully
git config --list
ubuntu configuration: apt get install Git
centos configuration: yum install git
2, Theoretical basis
1. What is Git
So, simply put, what kind of system is Git?
Please note that the following content is very important. If you understand Git's idea and basic working principle, you will know why and be able to use it easily.
When learning Git, please try to clarify your existing understanding of other version management systems, such as CVS, Subversion or Perforce, which can help you avoid confusion when using tools.
Although Git is very similar to other version control systems, it has great differences in the storage and cognition of information. Understanding these differences will help to avoid confusion in use.
2. Three states
Now please note that if you want to learn more smoothly later, please remember the following concepts about GIT. Git has three states, and your file may be in one of them: committed, modified, and staged.
- Modified indicates that the file has been modified but has not been saved to the database.
- Staged indicates that the current version of a modified file is marked for inclusion in the next committed snapshot.
- Submitted indicates that the data has been safely stored in the local database.
This will make our Git project have three phases: workspace, staging area and Git directory.
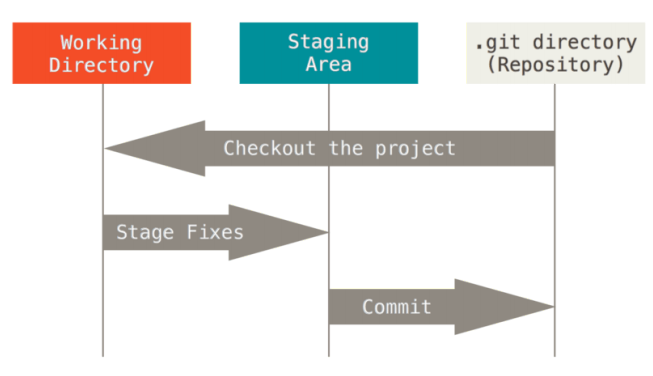
Working directory, staging area and Git warehouse
The workspace is the content extracted independently from a certain version of the project. These files extracted from the compressed database of Git warehouse are put on disk for you to use or modify.
The staging area is a file that holds the list of files to be submitted next time. It is generally in the Git warehouse directory. According to Git's terminology, it is called "index", but it is generally called "staging area".
The Git repository directory is where Git stores the metadata and object database of the project. This is the most important part of Git. When cloning the warehouse from other computers, the data here is copied.
The basic Git workflow is as follows:
- Modify the file in the workspace.
- Selectively save the changes you want to submit next time, which will only save the changed parts
Add points to staging area. - Commit the update, find the file in the staging area, and permanently store the snapshot in the Git directory.
If a specific version of the file is saved in the Git directory, it belongs to the submitted state. If the file has been modified and put into the staging area, it is in the staging state. If modifications have been made since the last check out but have not been placed in the staging area, it is in the modified status. In the Git basics chapter, you will learn more about the details of these States, and learn how to implement subsequent operations according to the file state, and how to skip staging and commit directly.
As mentioned above, if a file changes in each version, Git will copy and save the whole file. This design seems to consume more space, but it brings a lot of benefits and convenience in branch management.
3. Git guarantees integrity
All data in Git is calculated with a checksum before storage, and then referenced with a checksum. This means that it is impossible to change any file or directory contents without git's knowledge. This function is constructed at the bottom of GIT and is an indispensable part of GIT philosophy. If you lose information or damage files during transmission, GIT can find out.
The mechanism Git uses to calculate the checksum is called SHA-1 hash. This is a string of 40 hexadecimal characters (0-9 and a-f), calculated based on the content or directory structure of the file in Git. The SHA-1 hash looks like this:
24b9da6552252987aa493b52f8696cd6d3b00373
There are many cases where this hash value is used in Git, and you will often see this hash value. In fact, the information stored in the Git database is indexed by the hash value of the file content, not the file name.
3, Actual combat
1. Initialize Git
(1) Configuration before first running Git
Now that Git is installed on your system, you will want to do a few things to customize your git environment. Each computer only needs to be configured once, and the configuration information will be retained when the program is upgraded.
You can modify them at any time by running the command again.
Git comes with a git config tool to help set configuration variables that control git appearance and behavior.
On Windows systems, Git looks for the. gitconfig file in the $HOME directory (C:\Users$USER in general).
You can view all configurations and their files with the following command:
$ git config --list --show-origin
(2) User information
After installing Git, the first thing to do is to set up your user name and email address. This is important because each Git submission will use this information, which will be written into each submission and cannot be changed:
$ git config --global user.name "itnanls"
$ git config --global user.email "510180298@qq.com"
Again, if the -- global option is used, the command only needs to be run once, because Git will use that information no matter what you do on the system. When you want to use different user names and email addresses for a specific project, you can run the command without the -- global option in that project directory to configure it.
Many GUI tools will help you configure this information when you run it for the first time.
(3) Check configuration information
If you want to check your configuration, you can use the git config --list command to list all the configurations that Git can find at that time.
$ git config --list
user.name=John Doe
user.email=johndoe@example.com
color.status=auto
color.branch=auto
color.interactive=auto
color.diff=auto
...
You may see duplicate variable names because Git will read the same configuration from different files (for example: / etc/gitconfig and ~ /. Gitconfig). In this case, Git uses the last configuration of each variable it finds.
You can check one of Git's configurations by typing git config:
$ git config user.name
John Doe
(4) Try
Create a new folder in your own convenient disk. Take MyProject as an example. Note that the path does not contain Chinese characters. Open the cmd command window as follows:
Find an empty folder:
Right click ----- > > git bash here
//Initialize warehouse
51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study
$ git init
Initialized empty Git repository in
C:/Users/51018/Desktop/git-study/.git/
51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study
(master)
//Add a file
$ touch a.txt
$ echo 123 > a.txt
51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study
(master)
//Commit to cache
$ git add a.txt
51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study
(master)
//Submit to local warehouse
$ git commit -m 'first'
[master (root-commit) ac41d06] first
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 a.txt
51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study
(master)
(5) Get help
If you need help when using Git, there are three equivalent methods to find the comprehensive manual of Git commands (man page):
$ git help <verb>
$ git <verb> --help
For example, to get a manual of the git config command, execute
$ git help config
In addition, if you don't need a comprehensive manual and only need a quick reference to the available options, you can use the - h option to get a more concise "help" output:
$ git add -h
usage: git add [<options>] [--] <pathspec>...
-n, --dry-run dry run
-v, --verbose be verbose
-i, --interactive interactive picking
-p, --patch select hunks interactively
-e, --edit edit current diff and apply
-f, --force allow adding otherwise ignored files
-u, --update update tracked files
- -renormalize renormalize EOL of tracked files (implies -u)
-N, --intent-to-add record only the fact that the path will be added later
-A, --all add changes from all tracked and untracked files
- -ignore-removal ignore paths removed in the working tree (same as --no-all)
- -refresh don't add, only refresh the index
- -ignore-errors just skip files which cannot be added because of errors
- -ignore-missing check if - even missing - files are ignored in dry run
- -chmod (+|-)x override the executable bit of the listed files
2. Basic command
How do we know which files are newly added and which files have been added to the staging area? Can't we take a notebook and write it down? Of course not. As the greatest version control system in the world, Git already has a corresponding solution for the embarrassing situation you can encounter.
Anytime, anywhere
Use git status to view the current status
$ git status On branch master nothing to commit, working tree clean $ git add b.txt
If the code reports an error: git uploads an error - The file will have its original line
endings in your working directory
The reason is due to the difference of line breaks in the file.
Here you need to know the difference between CRLF and LF:
The newline character in windows is CRLF, while the newline character format in Unix is LF. git supports LF by default.
The above error report means that CRLF (i.e. carriage return and line feed) will be converted to Unix format (LF). These are warnings for converting file format and will not affect the use.
Generally, git will transfer CRLF to LF when commit ting code, and replace LF with CRLF when pull ing code.
Solution:
git rm -r --cached .
git config core.autocrlf false
Then upload the code again.
When it is true, Git will treat all files you add as text asking you for price, convert the end CRLF to LF, and then convert the LF format of the file to CRLF format during checkout.
When it is false, line endings does not make any changes, and the text file remains its original appearance.
When it is input, Git will convert CRLF to LF when it is add, but it is still lf when it is check, so it is not recommended to set this value in Windows operating system.
Enter the git status command, and the prompt is as follows:
51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study
(master)
$ echo 1234 > b.txt
51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study(master)
$ git add b.txt
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: b.txt
51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study
(master)
Untracked files indicates that there are untracked files (the red one below)
The so-called "untracked" files refer to those newly added files that have not been added to the staging area or submitted. They are in a state of impunity, but once you add them to the staging area or submit them to the Git warehouse, they begin to be "tracked" by Git.
The English in parentheses here is git's suggestion to us: use git add command to add the file to be submitted to the temporary storage area.
F:\MyProject>git add LICENSE
F:\MyProject>git status
On branch master
Changes to be committed:
(use "git reset HEAD ..." to unstage)
New file: license (green)
Add to the staging area again, and then execute git commit -m "b.txt" command:
Modify data
51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study
(master)
$ echo 123 > b.txt
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be
committed)
(use "git checkout -- <file>..." to discard
changes in working directory)
modified: b.txt
no changes added to commit (use "git add" and/or
"git commit -a")
51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study
(master)
After modifying the file, use git status to view the data.
git log view historical operation records
$ git log
commit 5da78a44017dda030d1fe273e2a470792534ba9a
(HEAD -> master)
Author: zhangnan <510180298@qq.com>
Date: Sat Mar 13 16:01:01 2021 +0800
123
commit c7c0e3bf6d64404e3e68632c24ca13eac38b02e2
Author: zhangnan <510180298@qq.com>
Date: Sat Mar 13 15:53:38 2021 +0800
first
51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study
(master)
d5a12d8a966da5bf36c1f4a080c5d507398f5f59 (HEAD ->master) first
In the result, head represents the current branch, and master represents the current branch of master. You can not press the following table.
I saw the records of two submissions. -- pretty=oneline
The branch in head git is essentially just a variable pointer to the commit object. How does git know which branch you are currently working on? In fact, the answer is also very simple. It stores a special pointer called HEAD. In git, it is a pointer to the local branch you are working on. You can think of HEAD as an alias of the current branch.
$ git log --graph
3. Time goes back
There are two commands for fallback: reset and checkout
(1) Rollback snapshot
Note: a snapshot is the version submitted. Each version is called a snapshot.
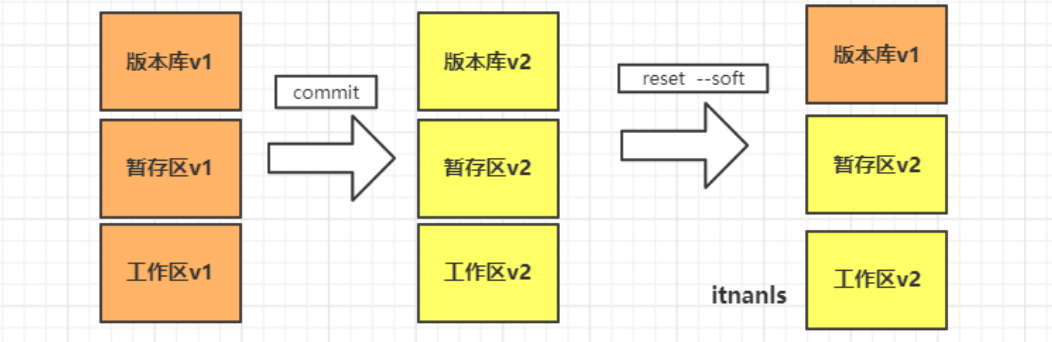
Now let's roll back the snapshot with the reset command and see what happened to the Git warehouse and the three trees.
Execute git reset HEAD ~ command:
Note: HEAD represents the latest snapshot submitted, while HEAD ~ represents the last snapshot of HEAD, and HEAD ~ ~ represents the last snapshot. If it represents the last 10 snapshots, HEAD ~10 can be used
At this time, our fast find rollback has reached the second tree number (staging area)
Remember: head always points to the current snapshot of the current branch
$ git --hard reset head~ 51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study (master) $ git log commit c7c0e3bf6d64404e3e68632c24ca13eac38b02e2 (HEAD -> master) Author: zhangnan <510180298@qq.com> Date: Sat Mar 13 15:53:38 2021 +0800 first 51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study (master)
As you can see, there is only one record left.
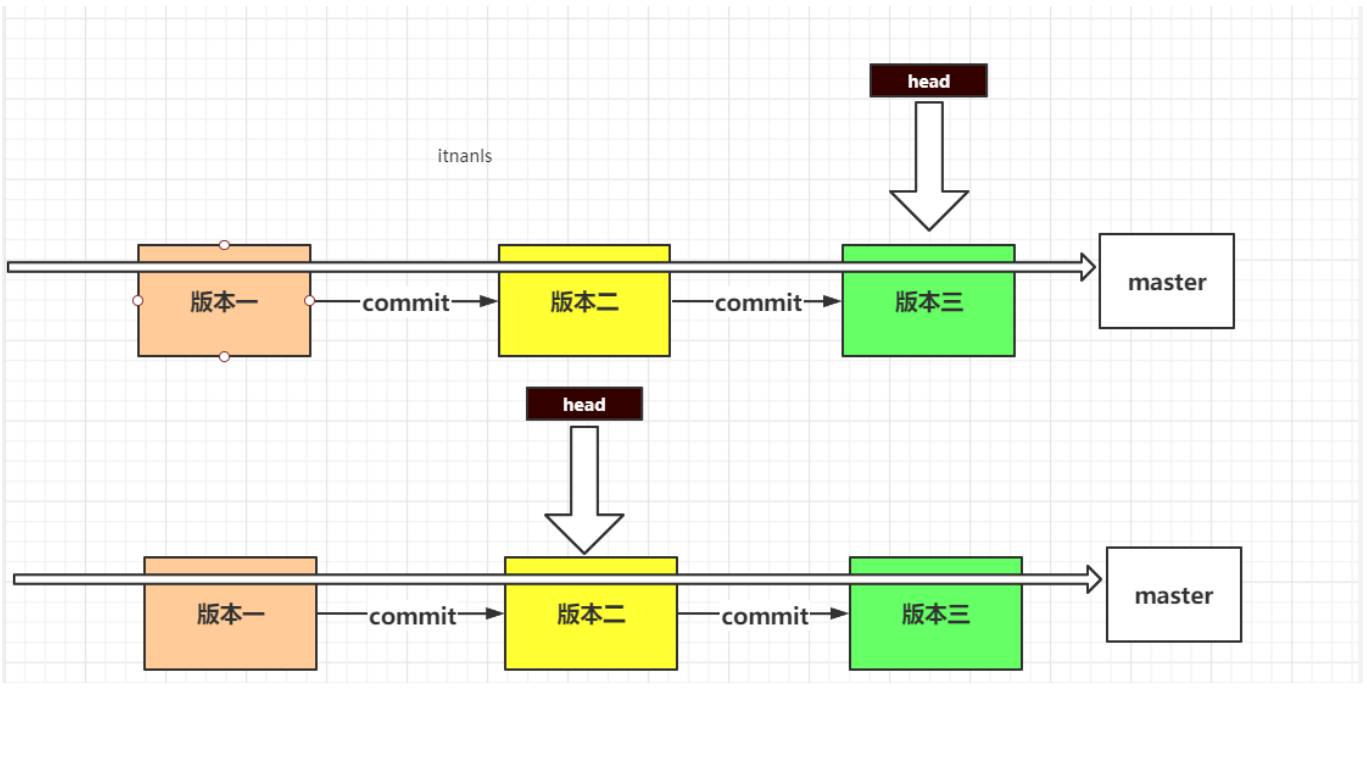
Parameter selection:
-- hard: fallback version library, staging area, workspace. (therefore, the modified code is gone and should be used with caution)
-reset not only moves the direction of the HEAD and scrolls the snapshot back to the staging area, but also restores the files in the staging area to the working directory.
--- mixed: fallback version library, staging area. (– mixed is the default parameter of git reset, that is, the parameter when no parameter is added)
--- soft: fallback version library.
This is equivalent to moving only the point of the HEAD, but does not roll back the snapshot to the staging area.
This is equivalent to undoing the last commit.
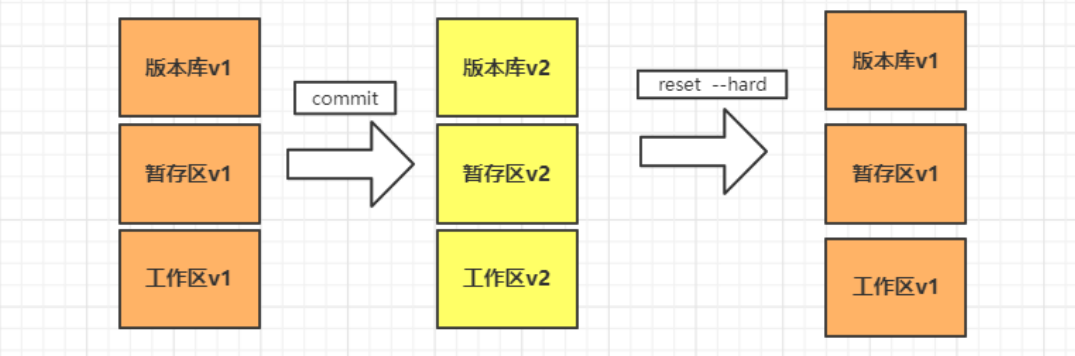
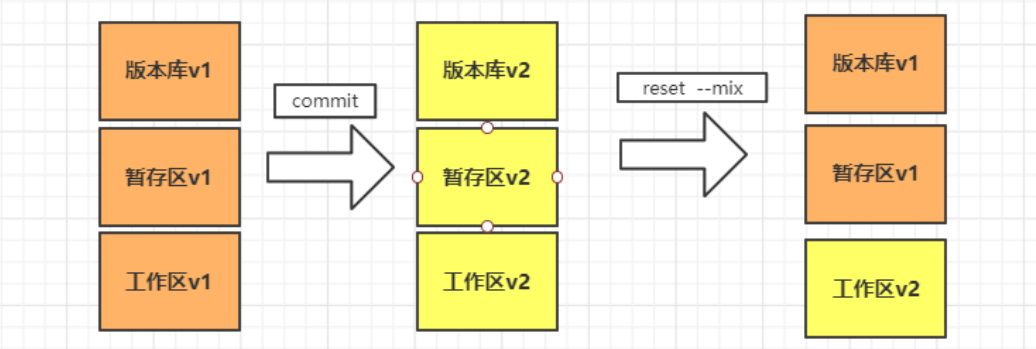
(2) Rollback specified snapshot
reset can roll back not only the specified snapshot, but also individual files.
The command format is:
git reset --hard
c7c0e3bf6d64404e3e68632c24ca13eac38b02e2
In this way, it will ignore the step of moving the direction of the HEAD (because you only roll back part of the snapshot, not the whole snapshot, so the direction of the HEAD should not be changed), and directly roll back the specified file of the specified snapshot to the staging area.
You can not only roll back, but also roll forward!
What needs to be emphasized here is that reset is not only a "retro" command. It can not only go back to the past, but also go to the "future".
The only prerequisite is that you need to know the ID number of the specified snapshot.
What if you accidentally close the command window and don't remember the ID number? Command:
git reflog
Version ID number of each operation recorded by Git
$ git reset --hard 7ce4954
4. Version comparison
(1) Staging area and work tree
Objective: To compare the differences between versions
Add content to the existing file b.txt:
$ git diff diff --git a/b.txt b/b.txt index 9ab39d5..4d37a8a 100644 --- a/b.txt +++ b/b.txt @@ -2,3 +2,4 @@ 1212 123123123 234234234 +Manual valve
Now let's explain the meaning of each line above:
The first line: diff --git a/b.txt b/b.txt indicates that the comparison is the b.txt stored in the temporary storage area and the working directory
The second line: index 9ab39d5... 4d37a8a 100644 indicates that the ID s of the corresponding files are 9ab39d5 and 4d37a8a respectively, the temporary storage area on the left and the current directory behind. The last 100644 specifies the file type and permissions
Line 3: - a/b.txt
- indicates that the file is old (stored in the staging area)
The fourth line: + + + b/b.txt + + + indicates that the file is a new file (stored in the work area)
The fifth line: @ @ - 2,3 + 2,4 @ @ starts and ends with @ @, the "-" in the middle represents the old file, "+" represents the new file, and the number behind represents "start line number, display line number"
Content: + represents new lines - represents fewer lines
Directly execute the git diff command to compare the file contents of the temporary storage area and the working directory:
(2) Work tree and latest submission
$ git diff head warning: LF will be replaced by CRLF in b.txt. The file will have its original line endings in your working directory diff --git a/b.txt b/b.txt new file mode 100644 index 0000000..4d37a8a --- /dev/null +++ b/b.txt @@ -0,0 +1,5 @@ +123 +1212 +123123123 +234234234 +Manual valve 51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study (master)
(3) Two historical snapshots
$ git diff 5da78a4 c7c0e3b diff --git a/b.txt b/b.txt deleted file mode 100644 index 81c545e..0000000 --- a/b.txt +++ /dev/null @@ -1 +0,0 @@ -1234
(4) Compare warehouse and staging area
$ git diff --cached c7c0e3b diff --git a/b.txt b/b.txt new file mode 100644 index 0000000..9ab39d5 --- /dev/null +++ b/b.txt @@ -0,0 +1,4 @@ +123 +1212 +123123123 +234234234
5. Delete file
What if you accidentally delete a file?
Now manually delete the b.txt file from the working directory, and then execute
git status command:
$ git status
On branch master
Changes not staged for commit:
(use "git add/rm ..." to update what will be
committed)
(use "git checkout – ..." to discard
changes in working directory)
deleted: b.txt
no changes added to commit (use "git add" and/or
"git commit -a")
Reminder: use the checkout command to restore files in the staging area to the working directory:
$ git checkout – b.txt
The file will be returned again.
So how to delete a file completely?
If you accidentally download the wrong file to the working directory and then accidentally submit it to the Git warehouse:
Add a new c.txt file
51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study (master) $ echo 123 > c.txt 51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study (master) $ git add . 51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study (master) $ git commit -m 'third' [master 3bd84d8] third 1 file changed, 1 insertion(+) create mode 100644 c.txt
There are other ways:
Execute the git rm a.txt command:
$ git rm c.txt
rm 'c.txt'
At this time, the c.txt in the working directory has been deleted
51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study (master) $ ls a.txt b.txt mintty.exe.stackdump
However, when you execute the git status command, you still find that Git still refuses to let go:
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
deleted: c.txt
It means that it found something called c.txt in the snapshot of the warehouse, but it seems to be missing in the staging area and the current directory!
At this time, you can execute git reset --soft HEAD ~ command to roll back the snapshot to the previous location and resubmit it:
Note: the rm command deletes only the files in the working directory and staging area (that is, cancel tracking and will not be included in version management when submitting next time)
The contents of buffer and work tree are inconsistent. How to delete them
- Modify b.txt to add to buffer
- Modify b.txt again
- git rm c.txt
$ echo 123 > b.txt 51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study(master) $ git add b.txt 51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study (master) $ echo 123 > b.txt 51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study(master) $ git rm b.txt error: the following file has changes staged in the index: b.txt (use --cached to keep the file, or -f to force removal)
Because there are two files with the same name with different contents, who knows whether you have to delete them when you find out? I'd better remind you. Don't wait for an error and rely on the machine... According to the prompt, execute git rm -f b.txt to delete both.
I just want to delete the files in the staging area and keep the working directory. What should I do?
ps: execute git rm --cached file name command.
6. Rename file
Rename the file directly in the working directory, and an error occurs when executing git status:
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: b.txt
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be
committed)
(use "git checkout -- <file>..." to discard
changes in working directory)
deleted: b.txt
Untracked files:
(use "git add <file>..." to include in what will
be committed)
n.txt
The correct posture should be:
$ git mv b.txt c.txt
51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study
(master)
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
renamed: b.txt -> c.txt
7. Ignore file
How can Git recognize files in certain formats and then autonomously not track them? For example, there are three files 1.temp, 2.temp and 3.temp in the working directory. We don't want the files with the suffix temp to be tracked, but every time git status is executed, it will appear:
Solution: create a file named. gitignore in the working directory.
Then you find that windows doesn't allow you to create files starting with a dot (.) in the file manager at all. Windows needs to create a file starting with (.) in the command line window. Execute the echo *. Temp >. gitignore command to create a. gitignore file
File, and let Git ignore all files with. temp suffix:
$ echo *.temp > .gitignore
$ echo *.temp > .gitignore
Create a.temp in the working directory
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
renamed: b.txt -> c.txt
Untracked files:
(use "git add <file>..." to include in what will
be committed)
.gitignore
51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study
(master)
Well, Git has ignored all *. temp files (you can also put. gitignore
Files are also ignored).
8. Create and switch branches
(1) What is a branch?
Assuming that your big project has been launched (millions of people are using it), after a period of time, you suddenly feel that you should add some new functions, but for the sake of insurance, you can't develop directly on the current project. At this time, you need to create branches.
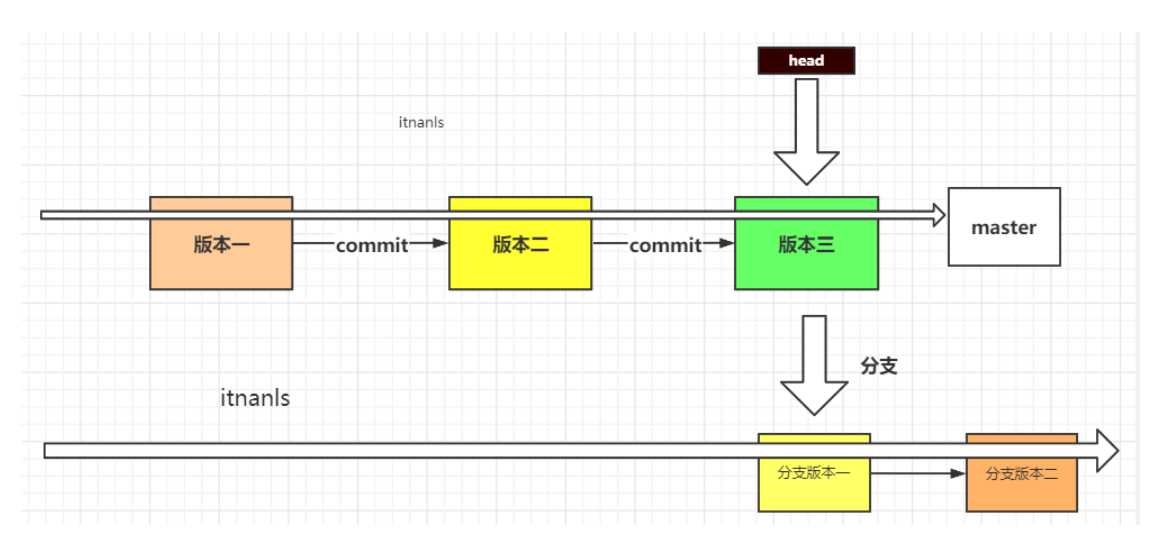
For other version control systems, creating a branch often requires completely creating a copy of the source code directory. The larger the project, the more time it takes; Since each node of Git is already a complete project, you only need to create one more "pointer" (like master) to point to the beginning of the branch.
(2) Create branch
Execute git status to view the status:
$ git status
On branch master
To create a branch, use the git branch branch branch name command:
$ git branch feature01
There is no prompt indicating that the branch creation is successful (generally, it will not fail unless you are reminded of the creation of a branch with the same name). At this time, you can execute the GIT log -- modify command to view it;
If you want to display in the "compact version", you can add an -- online option (that is, GIT log -- modify -- online), so that only one line is used to display a snapshot record.
$ git log
commit 432621d36faf270eae133cfe2e976fc99df479a5
(HEAD -> master, feature01)
Author: zhangnan <510180298@qq.com>
Date: Sat Mar 13 17:43:53 2021 +0800
1
commit 4c9e83b6d4ca3ca3d8b0b77bb5aca614dd755413
Author: zhangnan <510180298@qq.com>
Date: Sat Mar 13 17:11:51 2021 +0800
123
You can see that there is an additional one behind the latest snapshot (head - > master, feature01)
It means that there are two branches at present, one is the master branch and the other is the new feature we just created. Then the HEAD pointer still points to the default master branch.
$ git log --decorate --oneline
432621d (HEAD -> master, feature01) 1
4c9e83b 123
8af2e68 secong
c7c0e3b first
Therefore, the current snapshot in the warehouse should be as follows: head -- > > master feature01
(3) Switch branch
Now we need to switch the working environment to the newly created feature and use the checkout command we wanted to stop talking about before. Execute git checkout feature command:
$ git checkout feature01 Switched to branch 'feature01' 51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study (feature01) $ git status On branch feature01 nothing to commit, working tree clean
Now let's make a submission (there is still a changed file in the staging area that has not been submitted):
Create d.txt file
$ git add d.txt 51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study (feature01) $ git commit -am 'feature01' [feature01 f5e0b68] feature01 1 file changed, 1 insertion(+) create mode 100644 d.txt
Now the snapshot in the warehouse should be maozi (the submitted snapshot is managed by the branch pointed to by the current HEAD pointer):
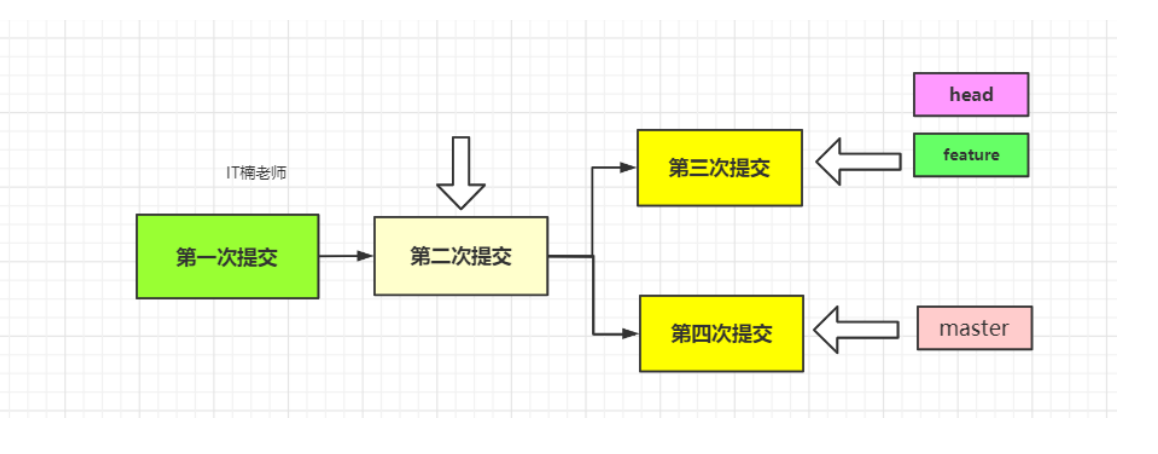
Then we switch the HEAD pointer back to the master branch:
51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study (feature01) $ ls a.temp a.txt c.txt d.txt mintty.exe.stackdump 51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study (feature01) $ git checkout master Switched to branch 'master' 51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study (master) $ ls a.temp a.txt c.txt mintty.exe.stackdump
Careful friends will find that the last modification to README.md file has disappeared because our working directory has returned to the master branch:
Submit separately in different branches
9. Merge branch
Create a new warehouse
// Initialize a warehouse $ git init // Create an a.txt file and modify its contents $ touch a.txt // Submit this branch $ git add a.txt $ git commit -m 'master' // Cut out a branch $ git branch feature1 // Switch to this branch $ git checkout feature1 Switched to branch 'feature1' // Modify the contents of a.txt at will . . . // Switch back to the main branch $ git checkout master Switched to branch 'master' // Merge branch $ git merge feature1 Updating 540e027..cae5dfc Fast-forward a.txt | 8 +++++++- 1 file changed, 7 insertions(+), 1 deletion(-)
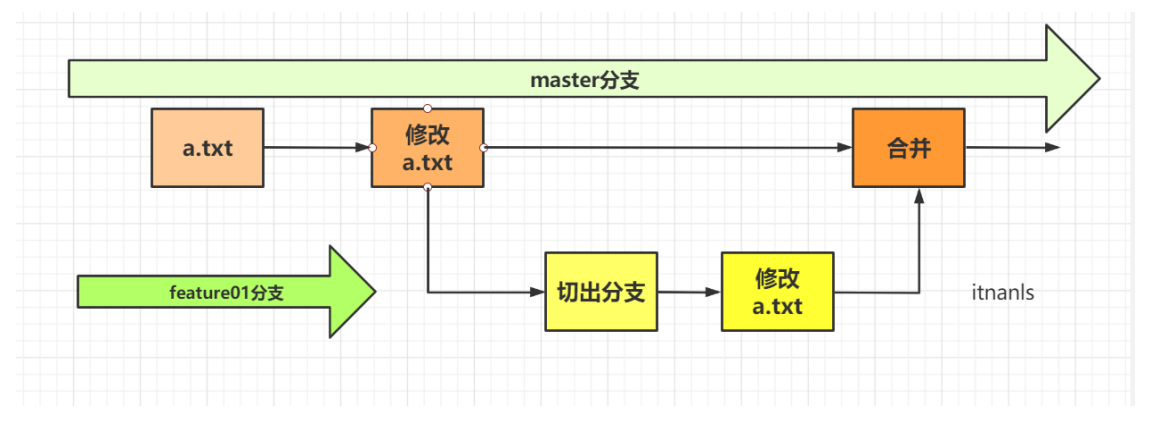
When the mission of a sub branch is completed, it should return to the main branch.
$ git log --decorate --all --graph --online fatal: unrecognized argument: --online 51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study (feature01) $ git log --decorate --all --graph --oneline * b134862 (HEAD -> feature01) feature01 * f5e0b68 feature01 | * baccb7f (master) master |/ * 432621d 1 * 4c9e83b 123 * 8af2e68 secong * c7c0e3b first
Merge branches we use the merge command and execute the git merge feature01 command to merge the feature branches into the branch (master) where the HEAD is located:
Step 1: cut out a feature2 branch and modify the data in the first row of a.txt in the master branch,
// Cut out a branch first $ git branch feature2 // In the master branch, modify the data in the first row of a.txt $ git add a.txt //Submit master branch $ git commit -m 'master' // Switch to feature2 branch $ git checkout feature2 Switched to branch 'feature2' // Similarly, modify the first row of data in a.txt $ git add a.txt // Submit $ git commit -m feature2 [feature2 0ebb84a] feature2 1 file changed, 1 insertion(+), 1 deletion(-) // Switch to the master branch $ git checkout master Switched to branch 'master' // Merge feature2 onto the master branch $ git merge feature2 // Something's wrong Auto-merging a.txt CONFLICT (content): Merge conflict in a.txt Automatic merge failed; fix conflicts and then commit the result. a.txt The content becomes as follows: <<<<<<< HEAD 123123 ======= 123345 >>>>>>> feature2
This means that you need to resolve the conflict before Git can merge.
The so-called conflict is nothing more than that there are files with the same name but different contents in two branches. Git doesn't know which one you want to discard or keep, so you need to decide for yourself. At this time, executing the git status command will also display the conflicts you need to resolve:
$ git status
On branch master
You have unmerged paths.
(fix conflicts and run "git commit")
(use "git merge --abort" to abort the merge)
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: a.txt
no changes added to commit (use "git add" and/or
"git commit -a")
Taking "=======" as the boundary, the content from "< < < head" to "> > > > > > feature" indicates the feature branches to be merged. The content between them is the place of conflict.
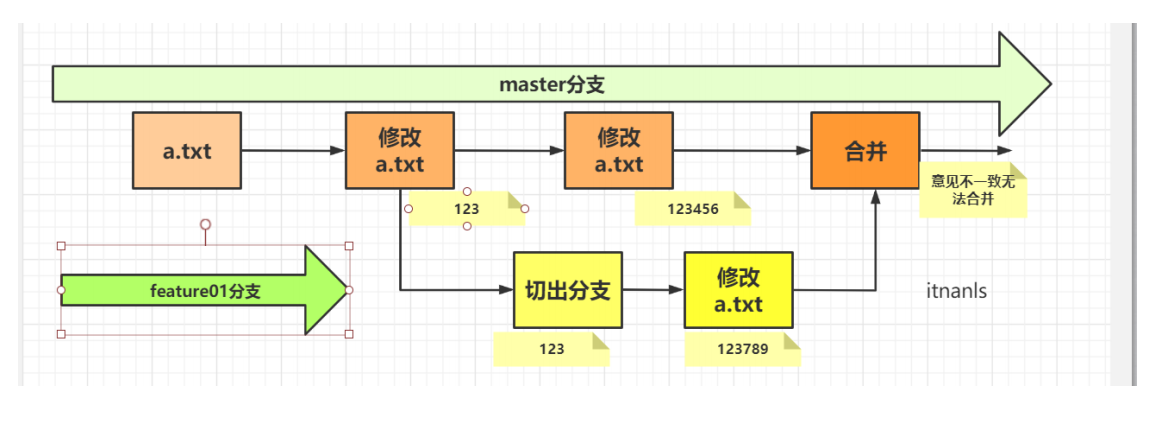
We need to modify it manually:
123123 51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study (master|MERGING) $ git add a.txt 51018@DESKTOP-6R8BLO2 MINGW64 ~/Desktop/git-study (master|MERGING) $ git commit -m 'Conflict resolution' [master 569943e] Conflict resolution
10. Delete branch
When a function is developed and successfully merged into the main branch, we should delete the branch
Use git branch -d branch name command:
Execute git log -- modify -- all -- graph -- oneline command:
Because Git's branching principle is actually recorded through a pointer, the creation and deletion of branches are almost instantaneous.
Note: if you try to delete an unmerged branch, Git will prompt you "the branch is not completely merged. If you are sure to delete it, please use git branch -D branch name command.
11. Variable base
When we develop a function, there may be countless local commits. In fact, you only want to display a complete submission record after each function test on your master branch. Other submission records do not want to be kept on your master branch in the future, so rebase will be a good choice, He can combine multiple local commitments into one commitment during rebase, and modify the description of the commitment
//Merge the first two commit s
git rebase -i head~~
//Merge the submission of this commit in the latest commit
git rebaser -i hash value