Python Web Crawler (1) Getting Started
Libraries used: requestspip+BeautifulSoup4pip+tqdmpip+html5lib
python version: 3.8
Compilation environment: Jupyter Notebook (Anaconda3)
Tour: Chrome
Knowledge involved: HTML Hypertext Markup Language
, What is a crawl
1. Web Crawler (Web Crawler or Web Spider)
It is a program that automatically browses web pages and collects the required information. He can download web page data from the Internet for search engines, which is an important part of search engines.
- The crawler starts with the URL of the initial page and gets the URL on the initial page.
- In the process of crawling web pages, constantly pull new URL s from the current page into the queue;
- Until the stopping condition given by the system is satisfied
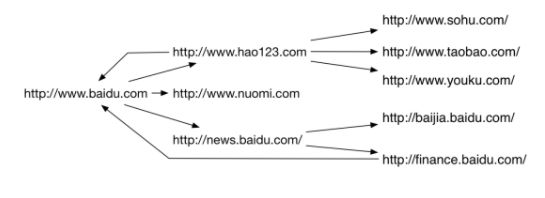
- Each node is a web page
- Each side is a hyperlink
- A web crawler is one that grabs interesting content from such a network diagram
2. Web Page Grabbing Strategy
Generally speaking, web crawling strategies can be divided into three categories:
-
Width first:
In the capture process, after the current level of search is completed, the next level of search is carried out
Features: The design and implementation of the algorithm is relatively simple. Fundamental idea: There is a high probability that a Web page within a certain connection distance from the initial URL will be subject-related.
-
Best priority:
The best priority search strategy predicts the similarity or relevance of candidate URLs to the target Web page according to a certain Web page analysis algorithm, and selects one or more URLs that have the best evaluation to capture. It only visits pages that have been predicted to be "useful" by page analysis algorithms
Features: The best-priority strategy is a locally optimal search, and many related pages on crawler-grabbing paths may be ignored.
-
Depth first:
Start from the start page, select a URL to enter, analyze the URL in this page, select one to enter again. Such a connection is grabbed one by one until the next route is processed.
Features: The algorithm design is relatively simple, but the value of the web page and PageRank decrease with each level of depth, so it is rarely used.
Depth-first causes trapped crawls in many cases, and the most common are breadth-first and best-first methods.
3. Classification of Web Crawlers
Generally speaking, web crawlers can be divided into the following four categories:
-
Universal Web Crawler:
Scalable Web Crawler crawls extend from seed URL s to the entire Web, collecting data for portal site search engines and large Web service providers.
Generic Web crawlers start with one or more initial seed URLs preset to obtain a list of URLs on the initial Web page, which are accessed and downloaded from the URL queue as they crawl.
-
Incremental crawls:
Incremental Web Crawler refers to a crawler that incrementally updates downloaded pages and crawls only newly generated or changed pages. It ensures to some extent that the pages crawled are as new as possible.
Incremental crawlers have two goals:
- Keep locally centrally stored pages up to date
- Improving the quality of hit pages on local pages
General commercial search engines such as Google,Baidu Baidu And so on, which are essentially incremental crawls.
-
Vertical crawls:
Also known as Focused Crawler, or Topical Crawler, refers to the selective crawling of web crawlers that crawl pages related to predefined topics. E-mail addresses, e-books, commodity prices, etc.
The key to crawling strategy implementation is to evaluate the importance of page content and links. Different methods calculate different importance, which results in different access order of links
-
Deep Web Crawler:
web pages that are hidden behind the search form and can only be obtained by submitting some keywords by the user.
The most important part of Deep Web crawling is form filling, which can be of two types:
- Form filling based on domain knowledge
- Form filling based on Web page structure analysis
4. Scope of use
- As a web collector of search engines, grab the entire Internet such as Google,Baidu Baidu And so on;
- As a vertical search engine, grab information on specific topics, such as video site bilibili bili, picture site Pixiv, and so on.
- Used as a detection tool for testing the front-end of a website to assess the robustness of the front-end code
4.1 Web Crawler Legality** (Robots Protocol)**
Robots protocol:
Also known as the Robot Protocol or the Crawler Protocol, this protocol stipulates the scope of web content grabbed by search engines, including whether or not web sites want to be grabbed by search engines and what content is not allowed to be grabbed, so web crawlers "consciously" grab or do not grab the web content accordingly. Since its launch, the Robots protocol has become an international practice for websites to protect sensitive data and privacy of their users.
- Robots protocol is implemented through robots.txt
- The robots.txt file should be placed in the network root directory
- When a crawler visits a site, it first checks to see if robots.txt exists in the root directory of the site, and if it does, the search robot follows the rules in the file to determine the extent of access. If the file does not exist, all crawlers will be able to access all password-protected pages on the site.
Robots.txt file syntax:
-
Grammar:
User-agent: |agent_name The **** here represents all search engine categories and is a wildcard character
Disallow: /dir_name / Defined here to prohibit crawling dir_ Files under name directory
Allow: /dir_name / Defined here to allow crawling dir_ The entire directory of name
-
Example:
User-agent: Googlebot
Allow: /folder1/myfile.html
Disallow: /folder1/
Only the content of the myfile.html page in the folder1 directory is allowed to be crawled.
5. Basic architecture of Crawlers
Web crawlers typically consist of four modules:
- URL Management Module
- Download module
- Parsing Module
- Storage module
-
SeedURLs: A crawler startup entry, usually a set of URLs
-
URL Queue:URL management module, responsible for managing and dispatching all URLs
-
Download modules, and for efficiency, crawlers are usually multiple parallel
-
Parsing module: parse valuable information from web pages and add newly discovered URLs to URLQueue
-
Storage module: Store data in a storage medium, usually a file or database
This diagram is written in mermaid and can be copied directly.
1. Code Instance - Grab One ACM Title Web Site Topic data for
1. Install necessary packages
- pip install requests
- pip install BeautifulSoup4
- pip install tqdm
- pip install html5lib
2. Analyzing websites
Open Web Site ACM Topic Website of Nanyang Polytechnic Institute http://www.51mxd.cn/ , right-click a topic, select Check, will jump directly to where the code is located
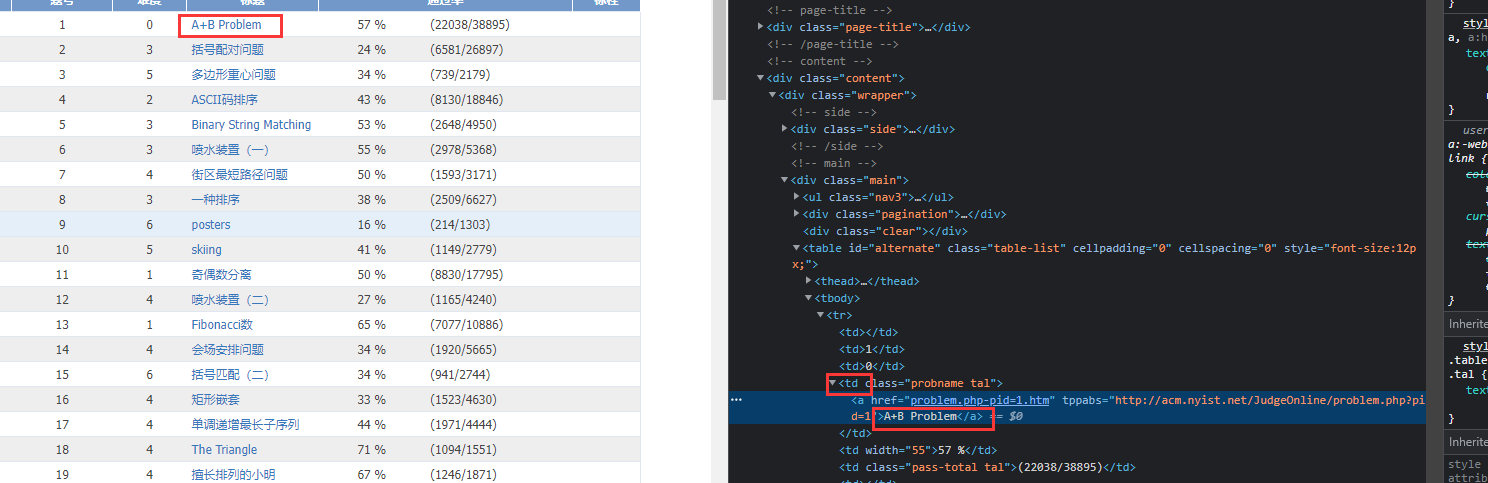
Most of the title information is found in the tag <td>, so crawl all TD content.
And the web address has too much content and needs to be paged, so to find the paged web address (click back and forth for 2 pages and 1 page), find the format of the web address as follows:
http://www.51mxd.cn/problemset.php-page=1.htm
problemset.php-page=X.htm stands for page X, so you need to write this when entering the web address:
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
3. Code
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# Simulate all kinds of browser access, unexpectedly, there is also a QQ viewer
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# Table Head
csvHeaders = ['Title', 'difficulty', 'Title', 'Pass rate', 'Pass Number/Total Submissions']
# Topic Data
subjects = []
# Crawl Topics
print('Title information crawling:\n')
for pages in tqdm(range(1, 1 + 1)):
# Website
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
# Get Web Content
r.raise_for_status()
# Code
r.encoding = 'utf-8'
# Create BeautifulSoup object
soup = BeautifulSoup(r.text, 'html5lib')
# Find all td Tags
td = soup.find_all('td')
subject = []
for t in td:
# Get values in columns and columns to form a row
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
#Store titles
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n Title information crawl completed!!!')
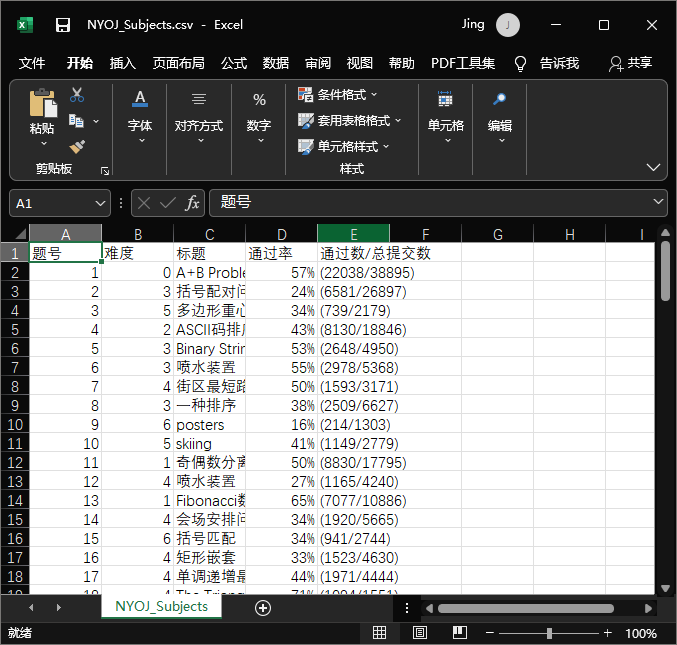
4. Operation effect:
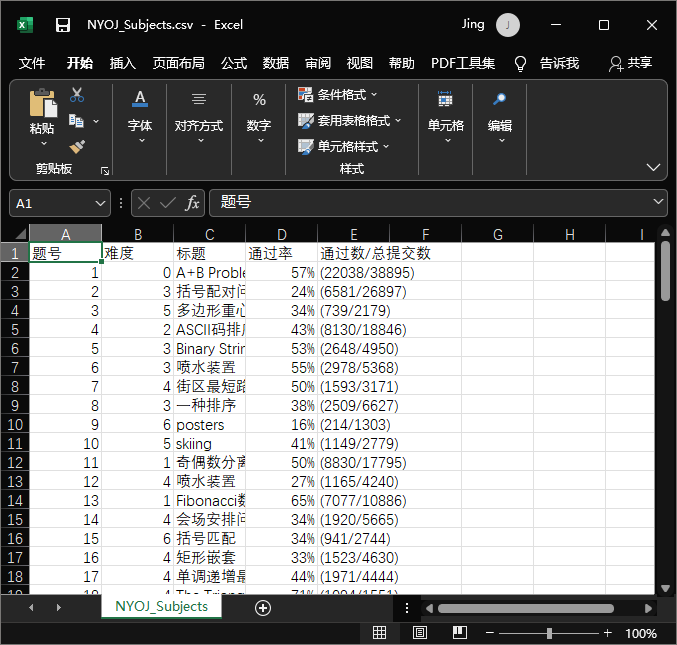
Contents retrieved from the <td>tag are stored in the csv file
2. Code Instances - Grab a batch of info notifications from news websites
1. Analysis Web Site
open News website of Chongqing Jiaotong University http://news.cqjtu.edu.cn/xxtz.htm
Right-click any news headline and click Check to navigate directly to its source code in the web page, which is what we need to crawl.
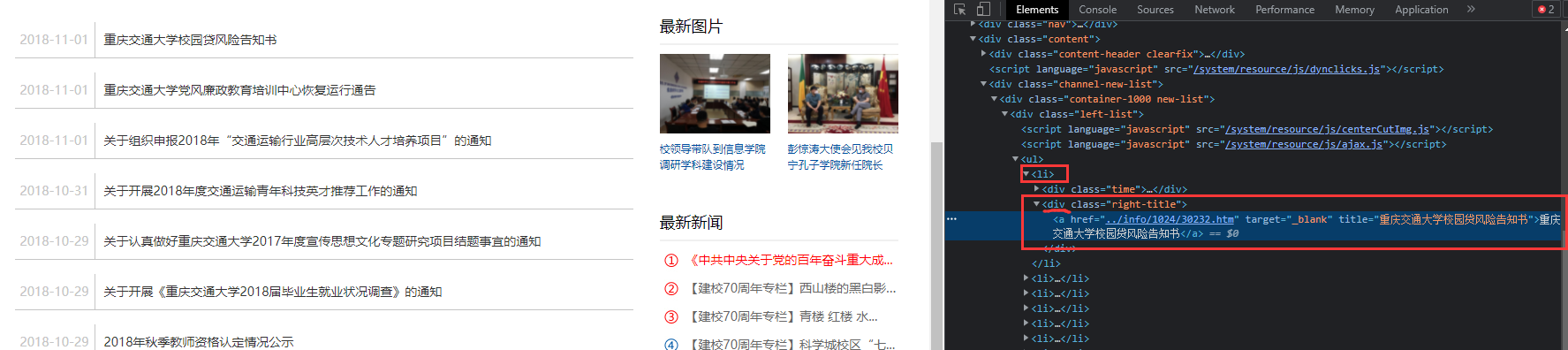
We found that both the headline and the release time are in the <div> tag, which is also included in a <li> tag. Then we can find all the <li> tags and find the appropriate <div> tags from inside.
Also note that pages have page numbers: http://news.cqjtu.edu.cn/xxtz/{pages}.htm
2. Code
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
import urllib.request, urllib.error # Develop a URL to get web page data
# All news
subjects = []
# Simulate browser access
Headers = { # Simulate browser header information
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.53"
}
# Table Head
csvHeaders = ['time', 'Title']
print('Information crawling:\n')
for pages in tqdm(range(1, 65 + 1)):
# Make a request
request = urllib.request.Request(f'http://news.cqjtu.edu.cn/xxtz/{pages}.htm', headers=Headers)
html = ""
# Get page content if request succeeds
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
# Parse Web Page
soup = BeautifulSoup(html, 'html5lib')
# Store a news item
subject = []
# Find all li Tags
li = soup.find_all('li')
for l in li:
# Find div tags that meet the criteria
if l.find_all('div',class_="time") is not None and l.find_all('div',class_="right-title") is not None:
# time
for time in l.find_all('div',class_="time"):
subject.append(time.string)
# Title
for title in l.find_all('div',class_="right-title"):
for t in title.find_all('a',target="_blank"):
subject.append(t.string)
if subject:
print(subject)
subjects.append(subject)
subject = []
# Save data
with open('CQJTUnews.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n Information crawl complete!!!')
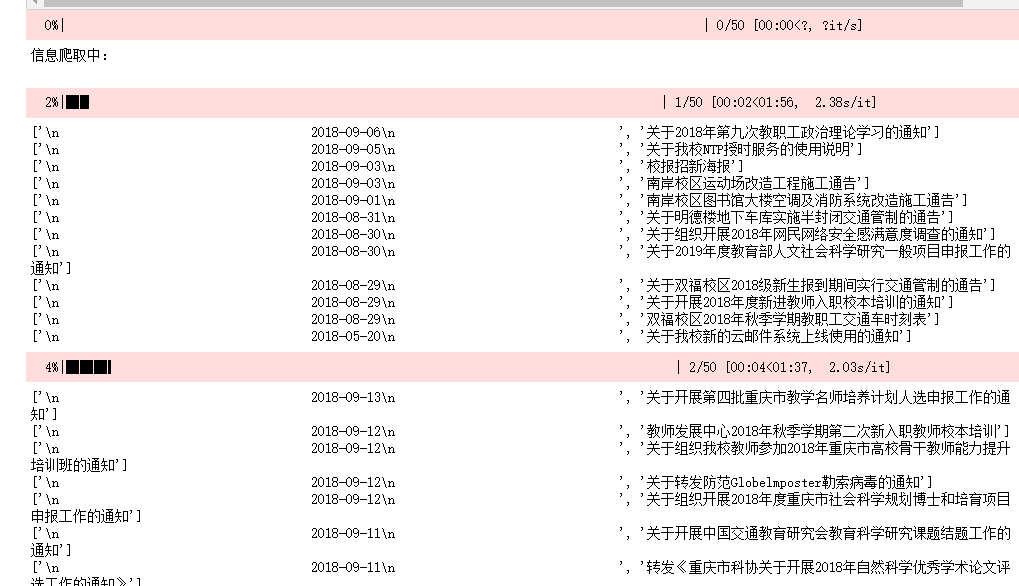
3. Operation effect
The crawled content is saved in a csv file.
3. Summary
With crawlers, we can easily get some up-to-date information without squatting manually anymore. If the program has been running on a cloud server, and the received messages are updated and forwarded to the mobile device in real time, it is very convenient to be a news app.
There are two premises for learning crawlers at the same time, one is to master the basic python syntax, the other is to master the basic front-end knowledge: HTML hypertext markup language.