1, First, let's see how Python can simply crawl the web page
1. Preparation
The beautiful soup4 and chardet modules used in the project belong to the three-party extension package. If not, please install pip by yourself. I use pycharm to do the installation. Next, I will simply use pycharm to install chardet and beautiful soup4
Follow the steps below in pycharm settings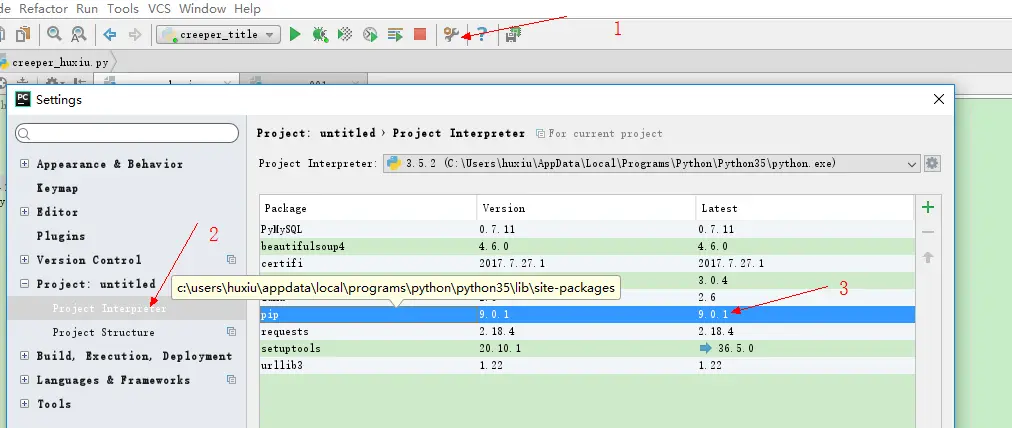
Search the extended class library as shown in the figure below. If we need to install chardet here, just search directly. Then click Install Package and beautiful soup4 to do the same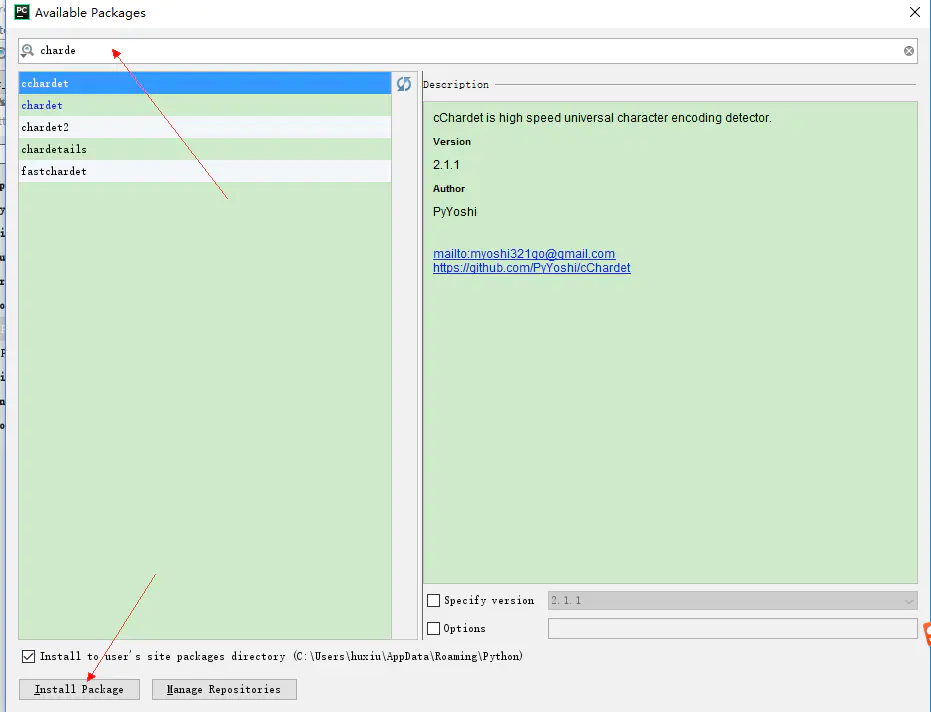
After successful installation, it will appear in the installation list, which means that we have successfully installed the web crawler extension library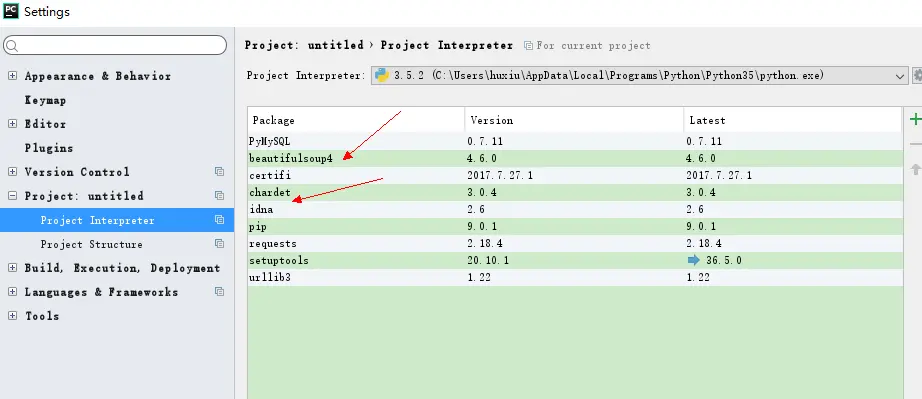
2, From shallow to deep, let's grab the web page first
Let's take the first page of a short book as an example: http://www.jianshu.com/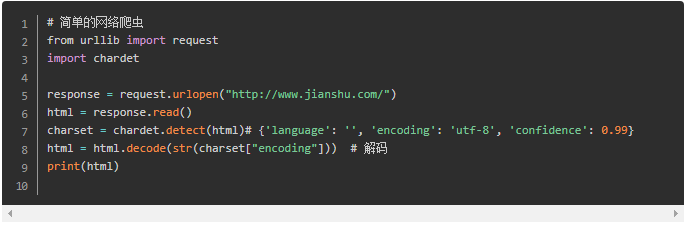
Because the html document is long, here is a simple part to show you
1.<!DOCTYPE html> 2.<!--[if IE 6]><html class="ie lt-ie8"><![endif]--> 3.<!--[if IE 7]><html class="ie lt-ie8"><![endif]--> 4.<!--[if IE 8]><html class="ie ie8"><![endif]--> 5.<!--[if IE 9]><html class="ie ie9"><![endif]--> 6.<!--[if !IE]><!--> <html> <!--<![endif]--> 7. 8.<head> 9. <meta charset="utf-8"> 10. 10.<meta http-equiv="X-UA-Compatible" content="IE=Edge"> 11.<meta name="viewport" content="width=device-width, initial-scale=1.0,user scalable=no"> 12. 13.<!-- Start of Baidu Transcode --> 14.<meta http-equiv="Cache-Control" content="no-siteapp" /> 15.<meta http-equiv="Cache-Control" content="no-transform" /> 11. <meta name="applicable-device" content="pc,mobile"> 17.<meta name="MobileOptimized" content="width"/> 18.<meta name="HandheldFriendly" content="true"/> 19.<meta name="mobile-agent" content="format=html5;url=http://localhost/"> 20.<!-- End of Baidu Transcode --> 21. 12. <meta name="description" content="Jianshu is a high-quality creation community. Here, you can create a piece of essay, a photo, a poem, a painting, etc We believe that everyone is an artist in life and has infinite creativity."> 23.<meta name="keywords" content="A brief book,Jianshu official website,Graphic editing software,Simple book download,Graphic Creation,Creative software,Original community,novel,Prose,writing,read"> 24...........There's a lot left out
This is the introduction to Python 3. Is it very simple? I suggest you tap more times
3, Python 3 crawls pictures from the web page and saves them to a local folder
target
Crawling the pictures in Baidu Post Bar
Save the pictures locally. They are all girls' pictures
Not much to say, directly on the code, the comments in the code are very detailed. You can understand it by reading the notes carefully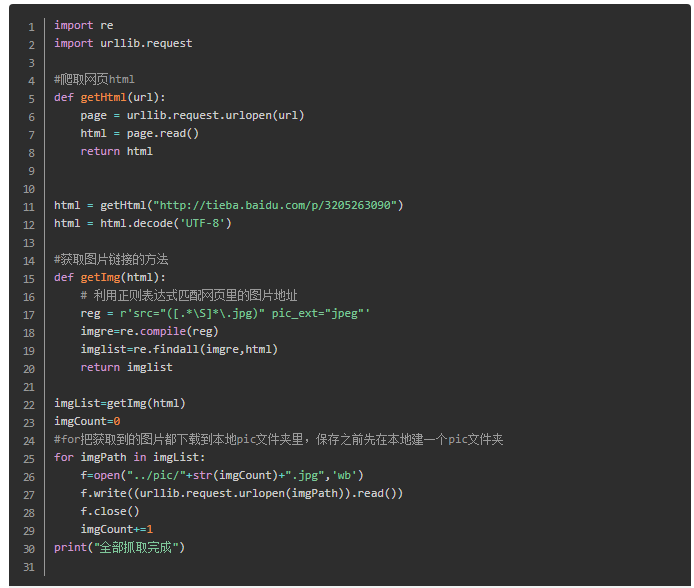
I can't wait to see what beautiful pictures I've got
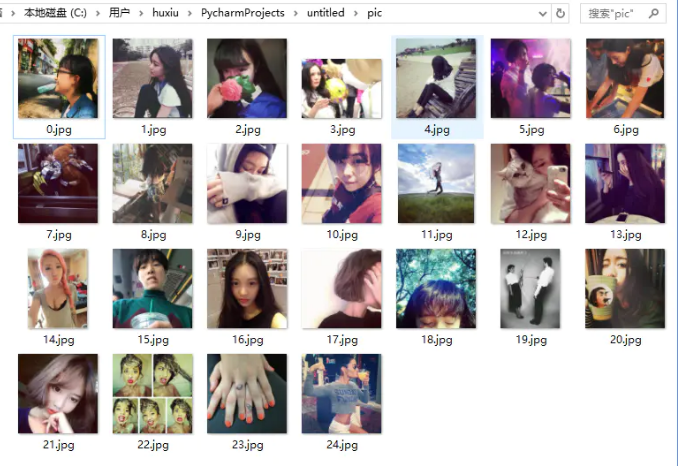
It's so easy to get the pictures of 24 girls. Is it very simple.
4, Python 3 crawls the news list of news websites
Here we only crawl the news title, news url, news picture link.
At present, the crawled data is only for display. After I finish the Python operation database, I will save the crawled data to the database.
It's a little more complicated here. Let's explain the distribution to you
Here we need to crawl to the html page first. Step 1: how to crawl the page
2 analyze the html tags we want to grab
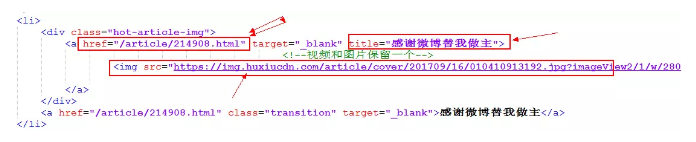
Analyze the information we want to grab in the above figure and then in the a tag and img tag in the div, so what we want to think about is how to get the information
We will use the beautiful soup4 library we imported here, the key code here
The allList obtained in the above code is the news list we want to obtain, as follows
1.[<div class="hot-article-img"> 2.<a href="/article/211390.html" target="_blank"> 3. 4.</a> 5.</div>, <div class="hot-article-img"> 6.<a href="/article/214982.html" target="_blank" title="TFBOYS Each member flies, and the ceiling of commercial value has been realized?"> 7.<!--Keep one video and one picture--> 8. 9.</a> 10.</div>, <div class="hot-article-img"> 11.<a href="/article/213703.html" target="_blank" title="Buyer's shop"> 12.<!--Keep one video and one picture--> 13. 14.</a> 15.</div>, <div class="hot-article-img"> 16<a href="/article/214679.html" target="_blank" title="iPhone X Officially tell us that mobile phones and cameras are starting to separate"> 17.<!--Keep one video and one picture--> 18. 19.</a> 20.</div>, <div class="hot-article-img"> 21.<a href="/article/214962.html" target="_blank" title="Credit has been overdrawn. LETV or Cheng jiayueting are abandoned"> 22.<!--Keep one video and one picture--> 23. 24.</a> 25.</div>, <div class="hot-article-img"> 26.<a href="/article/214867.html" target="_blank" title="Don't underestimate the "funny Nobel Prize", pay homage to curiosity"> 27.<!--Keep one video and one picture--> 28. 29.</a> 30.</div>, <div class="hot-article-img"> 31.<a href="/article/214954.html" target="_blank" title="10 There are more than one that changed the world years ago iPhone | start"> 32.<!--Keep one video and one picture--> 33. 34.</a> 35.</div>, <div class="hot-article-img"> 36.<a href="/article/214908.html" target="_blank" title="Thanks for Weibo"> 37.<!--Keep one video and one picture--> 38. 39.</a> 40.</div>, <div class="hot-article-img"> 41.<a href="/article/215001.html" target="_blank" title="Apple is sure to cancel the reward, but how much else do you think it's worth paying?"> 42.<!--Keep one video and one picture--> 43. 44.</a> 45.</div>, <div class="hot-article-img"> 46.<a href="/article/214969.html" target="_blank" title="The era of "full payment" for Chinese music is coming?"> 47.<!--Keep one video and one picture--> 48. 49.</a> 50.</div>, <div class="hot-article-img"> 51.<a href="/article/214964.html" target="_blank" title="The Enlightenment of Baili's delisting: how does "the king of shoes" keep away from the new generation of consumers"> 52.<!--Keep one video and one picture--> 53. 54.</a> 55.</div>]
Here, the data is captured, but it's too messy, and there are many things we don't want. Let's extract our effective information through traversal 3 extract valid information
1. Traverse the list to get valid information
2.for news in allList:
3. aaa = news.select('a')
4. Select only results with length greater than 0
5. if len(aaa) > 0:
6. Links to articles
7. try: if an exception is thrown, it means null
8. href = url + aaa[0]['href']
9. except Exception:
10. href=''
11. Article image url
12. try:
13. imgUrl = aaa[0].select('img')[0]['src']
14. except Exception:
15. imgUrl=""
16. News headlines
17. try:
18. title = aaa[0]['title']
19. except Exception:
20. title = "title is empty"
21. print("title", "title", "nURL:", href, "\ npicture address:", imgUrl)
22. print("==============================================================================================")
``
Exception handling is added here, mainly because some news may have no title, no url or picture. If we don't do exception handling, it may lead to the interruption of our crawling.
Effective information after filtering
Title title is empty url: https://www.huxiu.com/article/211390.html Photo address: https://img.huxiucdn.com/article/cover/201708/22/173535862821.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg ============================================================================================== The members of TFBOYS fly separately, and the ceiling of commercial value has appeared? url: https://www.huxiu.com/article/214982.html Photo address: https://img.huxiucdn.com/article/cover/201709/17/094856378420.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg ============================================================================================== Title buyer's shop url: https://www.huxiu.com/article/213703.html Photo address: https://img.huxiucdn.com/article/cover/201709/17/122655034450.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg ============================================================================================== The iPhone X officially tells us that mobile phones and cameras are beginning to diverge url: https://www.huxiu.com/article/214679.html Photo address: https://img.huxiucdn.com/article/cover/201709/14/182151300292.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg ============================================================================================== Credit has been overdrawn. LETV or Cheng jiayueting abandon their son url: https://www.huxiu.com/article/214962.html Photo address: https://img.huxiucdn.com/article/cover/201709/16/210518696352.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg ============================================================================================== Don't underestimate the "funny Nobel Prize", pay homage to curiosity url: https://www.huxiu.com/article/214867.html Photo address: https://img.huxiucdn.com/article/cover/201709/15/180620783020.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg ============================================================================================== The iPhone is not the only one that changed the world 10 years ago url: https://www.huxiu.com/article/214954.html Photo address: https://img.huxiucdn.com/article/cover/201709/16/162049096015.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg ============================================================================================== Thanks for Weibo url: https://www.huxiu.com/article/214908.html Photo address: https://img.huxiucdn.com/article/cover/201709/16/010410913192.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg ============================================================================================== Apple confirmed to cancel the reward, but how much else do you think it's worth paying? url: https://www.huxiu.com/article/215001.html Photo address: https://img.huxiucdn.com/article/cover/201709/17/154147105217.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg ============================================================================================== The era of "full payment" for Chinese music is coming? url: https://www.huxiu.com/article/214969.html Photo address: https://img.huxiucdn.com/article/cover/201709/17/101218317953.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg ============================================================================================== The Enlightenment of Baili's delisting: how does "the first generation of shoes king" keep away from the new generation of consumers url: https://www.huxiu.com/article/214964.html Photo address: https://img.huxiucdn.com/article/cover/201709/16/213400162818.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg ==============================================================================================
Here we grab the news information of news website, and the whole code will be pasted below
from bs4 import BeautifulSoup from urllib import request import chardet url = "https://www.huxiu.com" response = request.urlopen(url) html = response.read() charset = chardet.detect(html) html = html.decode(str(charset["encoding"])) # Set the encoding method of the captured html # Use profiler for html.parser soup = BeautifulSoup(html, 'html.parser') # Get a node of each class = hot article img allList = soup.select('.hot-article-img') #Traverse the list for valid information for news in allList: aaa = news.select('a') # Select only results with length greater than 0 if len(aaa) > 0: # Article links try:#If an exception is thrown, it means null href = url + aaa[0]['href'] except Exception: href='' # Article image url try: imgUrl = aaa[0].select('img')[0]['src'] except Exception: imgUrl="" # News headlines try: title = aaa[0]['title'] except Exception: title = "Title is empty" print("title",title,"\nurl: ",href,"\n Photo address:",imgUrl) print("==============================================================================================" //We also need to save the data to the database when the data is obtained. As long as the data is stored in our database and there is data in the database, we can do the following data analysis and processing, or use these crawled articles to provide the app with a news api interface //Finally, I'd like to share some small benefits with you //Link: https://pan.baidu.com/s/1sMxwTn7P2lhvzvWRwBjFrQ //Extraction code: kt2v //The link is easy to be reported expired. If it fails, add penguins654234959 Take it