Article catalog
- 1. Creating, Reading and Writing
- one point one Dataframe data framework
- one point two Series series
- one point three Reading reading reading data
- 2. Indexing, Selecting, Assigning
learn from https://www.kaggle.com/learn/pandas
Next: Getting started with Pandas 2 (DataFunctions+Maps+groupby+sort_values)
1. Creating, Reading and Writing
one point one Dataframe data framework
- Create a DataFrame, which is a table with a dictionary inside, key: [value_1,...,value_n]
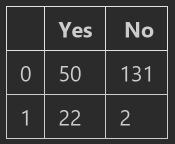
#%% # -*- coding:utf-8 -*- # @Python Version: 3.7 # @Time: 2020/5/16 21:10 # @Author: Michael Ming # @Website: https://michael.blog.csdn.net/ # @File: pandasExercise.ipynb # @Reference: https://www.kaggle.com/learn/pandas import pandas as pd #%% pd.DataFrame({'Yes':[50,22],"No":[131,2]})
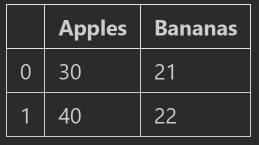
fruits = pd.DataFrame([[30, 21],[40, 22]], columns=['Apples', 'Bananas'])
- The value in the dictionary can also be: String
pd.DataFrame({"Michael":['handsome','good'],"Ming":['love basketball','coding']})

- Index data, index=['index1','index2 ',...]
pd.DataFrame({"Michael":['handsome','good'],"Ming":['love basketball','coding']}, index=['people1 say','people2 say'])

one point two Series series
- Series is a series of data, which can be regarded as a list
pd.Series([5,2,0,1,3,1,4]) 0 5 1 2 2 0 3 1 4 3 5 1 6 4 dtype: int64
- You can also assign data to Series, but Series has no column name, only the total name
- DataFrame is essentially multiple Series glued together
pd.Series([30,40,50],index=['2018 sales volume','2019 sales volume','2020 sales volume'], name='Blog visits') 2018sales volume 30 2019sales volume 40 2020sales volume 50 Name: Blog visits, dtype: int64
one point three Reading reading reading data
- Read the csv ("comma separated values") file, pd.read_csv('file '), stored in a DataFrame
wine_rev = pd.read_csv("winemag-data-130k-v2.csv")
wine_rev.shape # size (129971, 14)
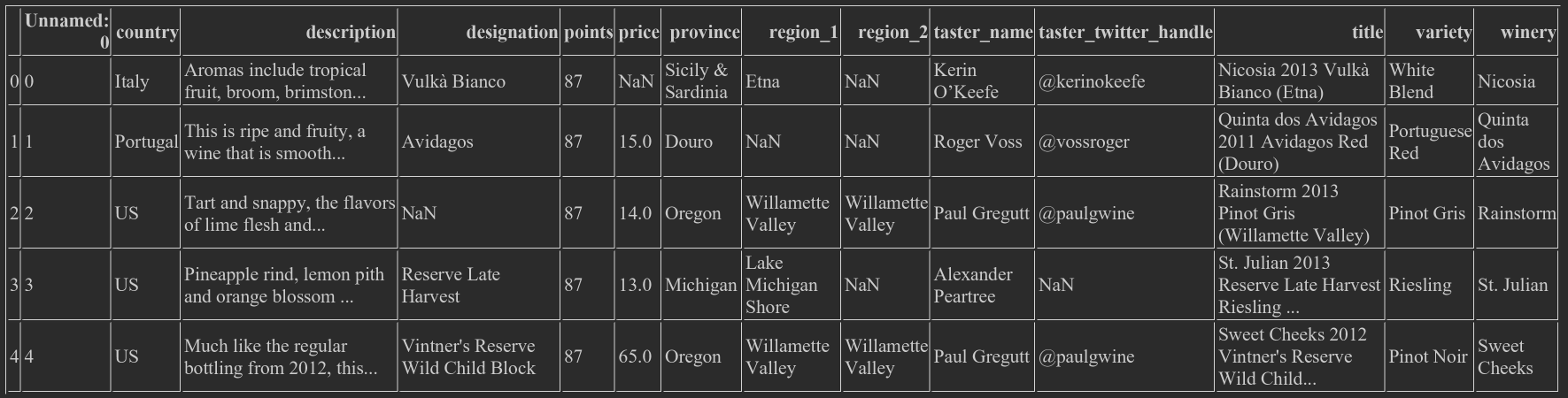
wine_rev.head() # View top 5 lines
- Index columns can be customized_ Col =, can be the sequence number of the column, or the name of the column
wine_rev = pd.read_csv("winemag-data-130k-v2.csv", index_col=0) wine_rev.head()
(the following figure has one less column than the above one, because the index column is defined as 0)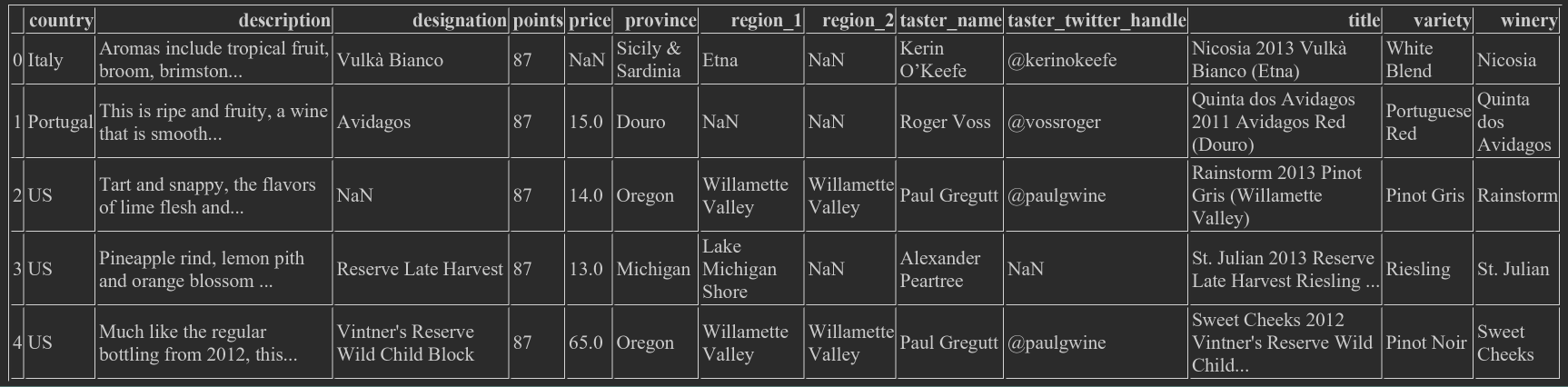
- Save, to_csv('xxx.csv )
wine_rev.to_csv('XXX.csv')
2. Indexing, Selecting, Assigning
two point one Access to python like mode
item.col_name # Disadvantage: cannot access the column with the name of space, [] operation can item['col_name']
wine_rev.country wine_rev['country'] 0 Italy 1 Portugal 2 US 3 US 4 US ... 129966 Germany 129967 US 129968 France 129969 France 129970 France Name: country, Length: 129971, dtype: object
wine_rev['country'][0] # 'Italy', first column, then row wine_rev.country[1] # 'Portugal'
two point two Unique access mode of pandas
2.2.1 Iloc access based on index
-
To select the first row of data in the DataFrame, we can use the following code:
-
wine_rev.iloc[0]
country Italy description Aromas include tropical fruit, broom, brimston... designation Vulkà Bianco points 87 price NaN province Sicily & Sardinia region_1 Etna region_2 NaN taster_name Kerin O'Keefe taster_twitter_handle @kerinokeefe title Nicosia 2013 Vulkà Bianco (Etna) variety White Blend winery Nicosia Name: 0, dtype: object
loc and iloc are both row first and column second, which is the opposite of the python operation above
- wine_rev.iloc[:,0], get the first column,: indicates all
0 Italy 1 Portugal 2 US 3 US 4 US ... 129966 Germany 129967 US 129968 France 129969 France 129970 France Name: country, Length: 129971, dtype: object
- wine_rev.iloc[:3,0],: 3 for [0:3) row 0,1,2
0 Italy 1 Portugal 2 US Name: country, dtype: object
- You can also use the discrete list to get lines, wine_rev.iloc[[1,2],0]
1 Portugal 2 US Name: country, dtype: object
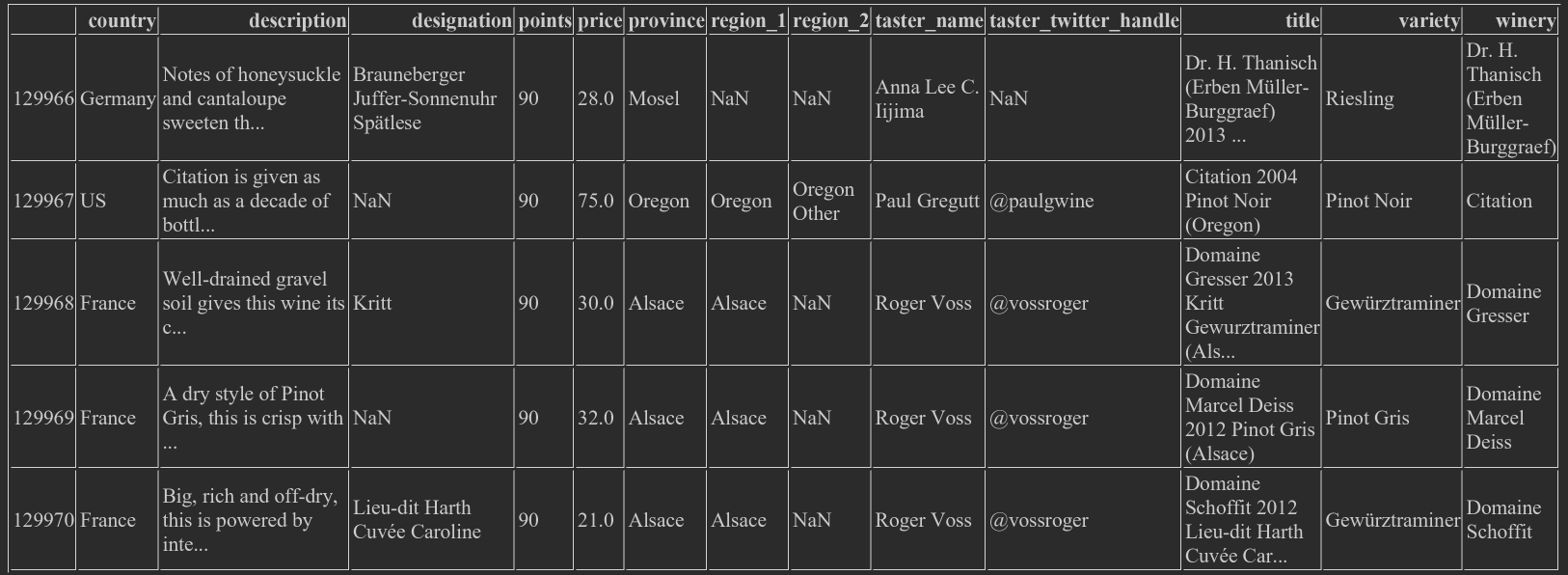
- Take the last few lines, wine_rev.iloc[-5:], line 5 to the end
2.2.2 LOC access based on label
- wine_rev.loc[0, 'country'], rows can also use [0,1] to represent discrete rows, and columns cannot use index
'Italy'
- wine_ rev.loc [: 3, 'country'], different from iloc, where line 3 is included, and LOC contains the last
0 Italy 1 Portugal 2 US 3 US Name: country, dtype: object
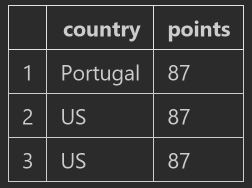
- wine_ rev.loc [1: 3, ['country ',' points']], multiple columns are enclosed in a list
- The advantages of LOC, such as the line with the string index, df.loc ['apples':'positions'] can be selected
two point three set_ Index() set index column
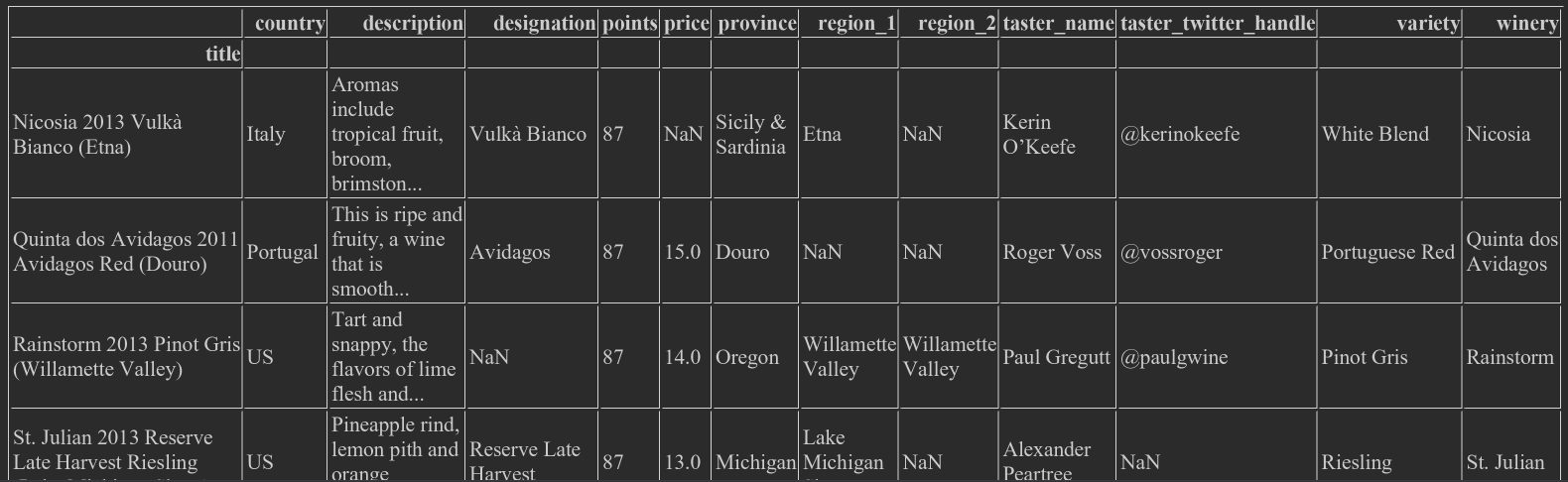
- set_index() can reset the index, wine_rev.set_index("title")
two point four Conditional selection
2.4.1 Boolean &, |==
- wine_ rev.country =='US', find by country, generate Series of True/False, which can be used for loc
0 False 1 False 2 True 3 True 4 True ... 129966 False 129967 True 129968 False 129969 False 129970 False Name: country, Length: 129971, dtype: bool
- wine_ rev.loc [wine_ rev.country =='US'], select all US lines

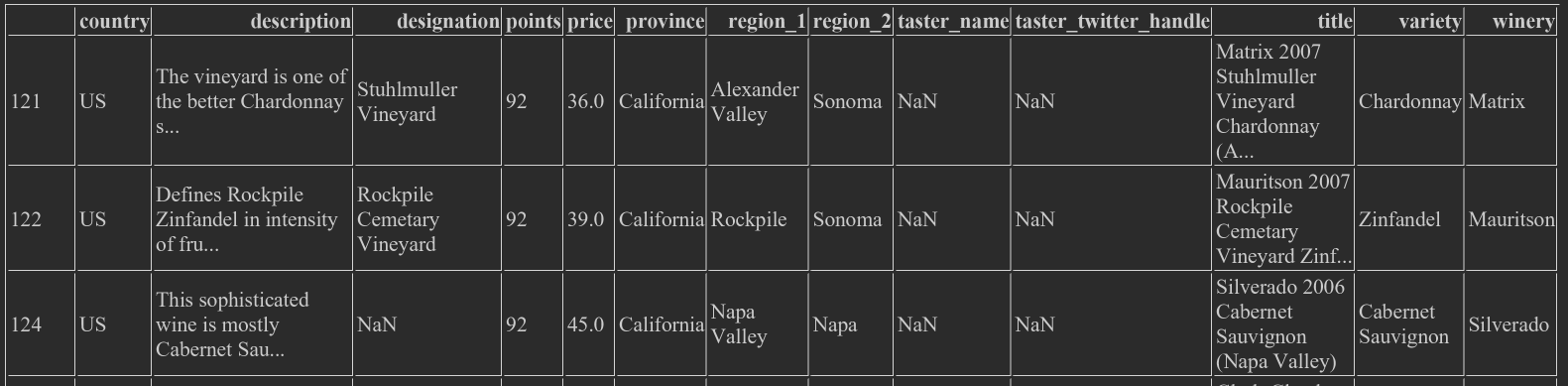
- wine_ rev.loc [(wine_ rev.country == 'US') & (wine_ rev.points >=90)], US's & with a score of more than 90
- You can also use | to represent or (like C + + bit operators)
2.4.2 Pandas built-in symbols isin, isnull, notnull
- wine_rev.loc[wine_rev.country.isin(['US','Italy ']]), select only rows of US and Italy
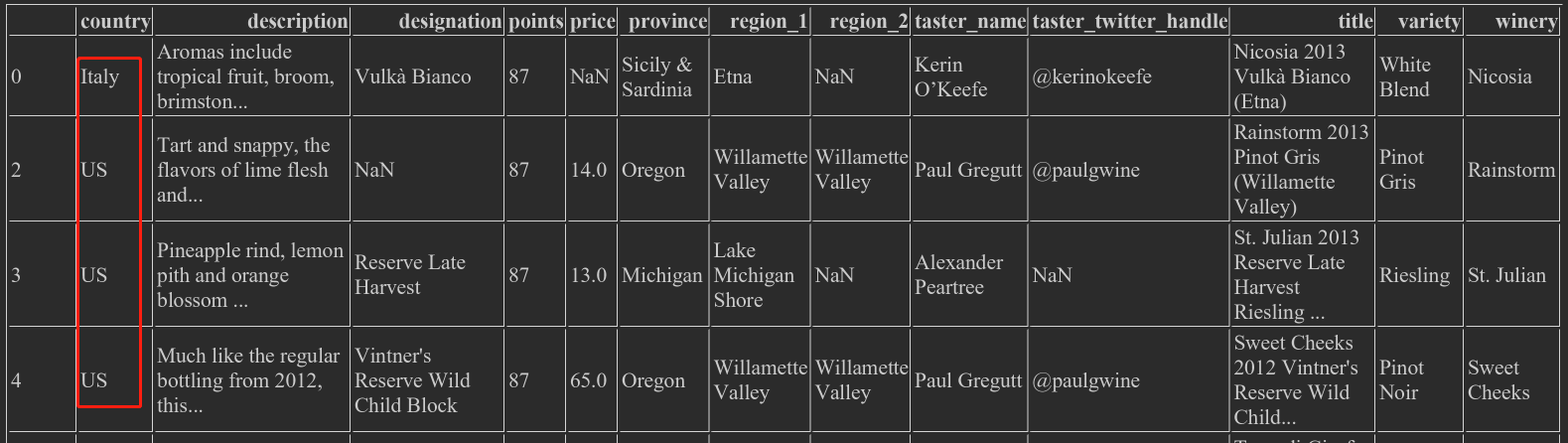
- wine_rev.loc[wine_rev.price.notnull(), price is not empty
- wine_rev.loc[wine_rev.price.isnull(), with NaN price
two point five Assigning data assignment
2.5.1 Assignment constant
- wine_ Rev ['critical '] ='michael', adding a new column
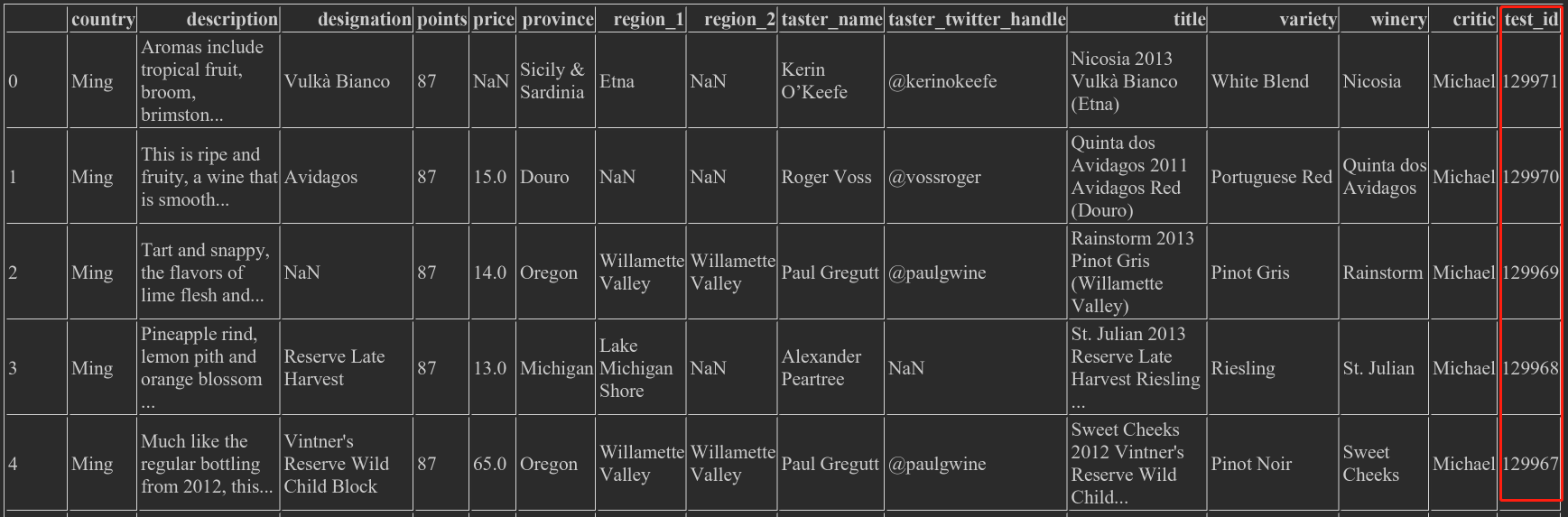
- wine_ rev.country ='Ming', the value of the existing column will be directly overwritten
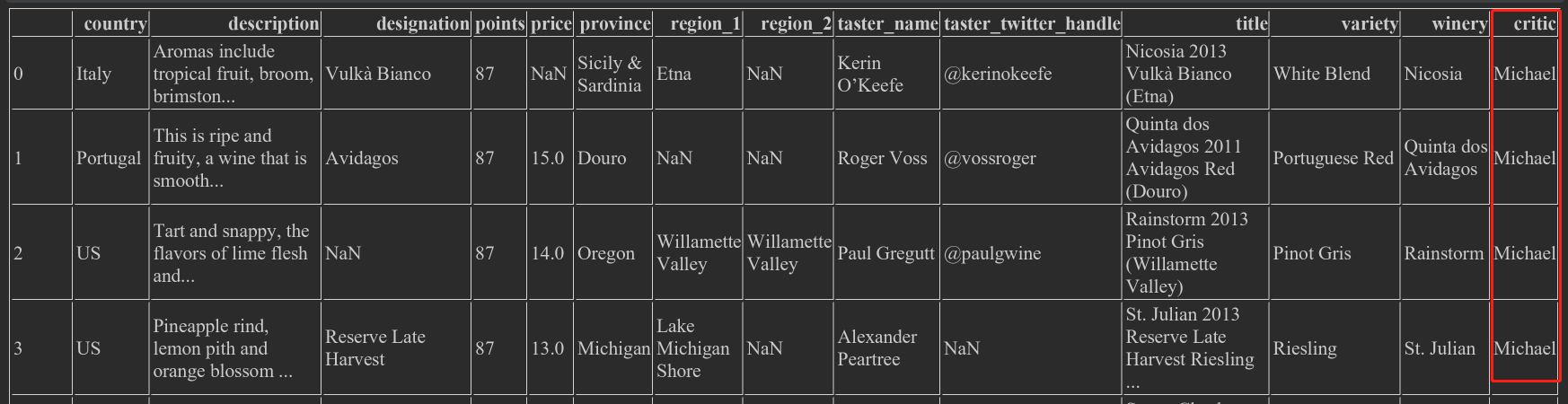
2.5.2 Sequence of assignment iterations
- wine_rev['test_id'] = range(len(wine_rev),0,-1)
Next: Getting started with Pandas 2 (DataFunctions+Maps+groupby+sort_values)