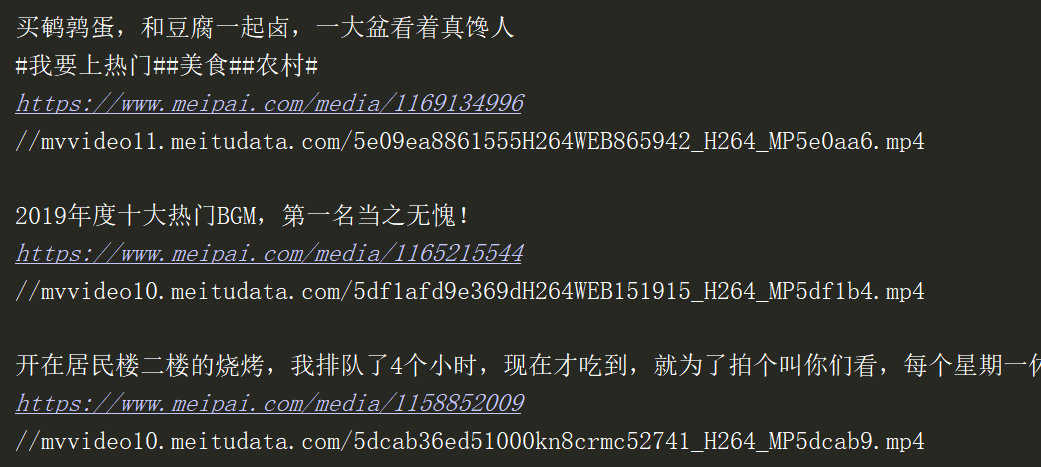
Find the label of the video link. This div is not in the source code

adopt Fiddler grabs the bag , find which js file generated the div of class="mp-h5-player-layer-video"

Open the corresponding js file, breakpoint it, and find the way to generate src
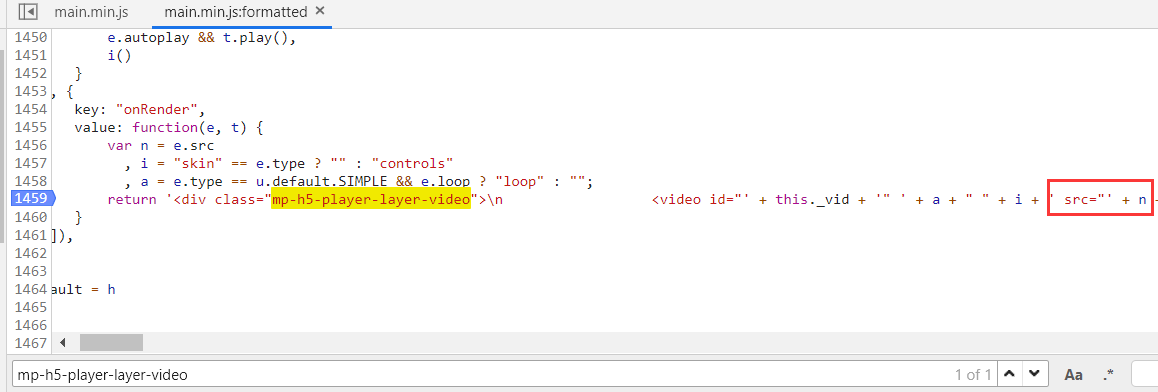
Find the src parameter in this position

At this point, you need to find the source of the string, and then simulate this method
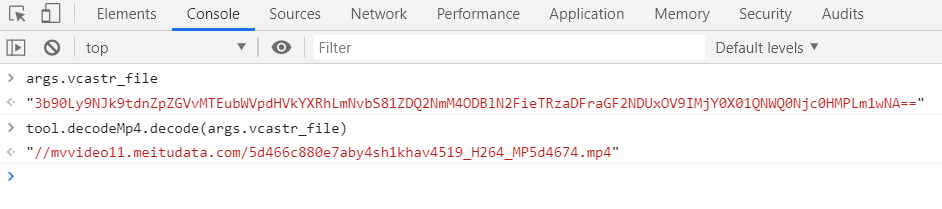
Finally, we found that the string existed in the web page from the very beginning

When a web page is requested, the corresponding string of the video is extracted, and then the URL can be obtained through the simulated method
import threading
import requests
import base64
import re
# Decrypt video URL
def Decrypt_video_url(content):
str_start = content[4:]
list_temp = []
list_temp.extend(content[:4])
list_temp.reverse()
hex = ''.join(list_temp)
dec = str(int(hex, 16))
list_temp1 = []
list_temp1.extend(dec[:2])
pre = list_temp1
list_temp2 = []
list_temp2.extend(dec[2:])
tail = list_temp2
str0 = str_start[:int(pre[0])]
str1 = str_start[int(pre[0]):int(pre[0]) + int(pre[1])]
result1 = str0 + str_start[int(pre[0]):].replace(str1, '')
tail[0] = len(result1) - int(tail[0]) - int(tail[1])
a = result1[:int(tail[0])]
b = result1[int(tail[0]):int(tail[0]) + int(tail[1])]
c = (a + result1[int(tail[0]):].replace(b, ''))
return base64.b64decode(c).decode()
# Get the content of a web page
def Page_text(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:21.0) Gecko/20130331 Firefox/21.0'
}
return requests.get(url, headers=headers).text
# Parsing a single web page
def Parse_url(video_title, url_tail):
page_url = 'https://www.meipai.com' + url_tail
video_page = Page_text(page_url)
# Get the encrypted URL of the video
data_video = re.findall(r'data-video="(.*?)"', video_page, re.S)[0]
video_url = Decrypt_video_url(data_video)
print("{}\n{}\n{}\n".format(video_title, page_url, video_url))
def Get_url(url):
index_page = Page_text(url)
# Title of each video
videos_title = re.findall(r'class="content-l-p pa" title="(.*?)">', index_page, re.S)
# URL of each playing page
urls = re.findall(r'<div class="layer-black pa"></div>\n\s*<a hidefocus href="(.*?)"', index_page, re.S)
t_list = []
for video_title, url_tail in zip(videos_title, urls):
t = threading.Thread(name='GetUrl', target=Parse_url, args=(video_title, url_tail,))
t_list.append(t)
for i in t_list:
i.start()
if __name__ == '__main__':
Get_url('https://www.meipai.com/')