Common data structures
1, String (string)
1. Basic use
-
Create string
# Create string str1 = str("lucky is a good man") # The basic type string will automatically change to string object type when used str1 = 'lucky is a nice man' -
operation
# String operation str3 = "lucky is a cool man" str4 = "lucky is a handsome man" # String addition (string splicing) str5 = str3 + str4 print("str5= %s"%(str5)) # String multiplication (duplicate string) str6 = str3 * 3 print("str6= %s"%(str6)) -
Member judgment
# Member judgment str7 = "lucky is a good man" print("lucky" in str7) -
Content acquisition
# Content acquisition str8 = "lucky is a good man" # Gets the contents of a string based on the subscript (index), starting with 0 # String [subscript] print(str8[2]) # Intercept a part of the string [start: stop] [start, stop) print(str8[1:4]) print(str8[1:]) print(str8[:4])
- formatted print

name = "lucky"
age = 18
height = 175.5
print("My name is%s,This year%d Age, height%f,Specific height%.1f" % (name, age, height, height))
# The content of known print is printed on one line by default, and another print will print on another line
# end defaults to \ n
print("lucky is a good", end="*")
print(" man")2. Common escape characters

str12 = "su\\nc\tk is a go\no m\"a'n"
print(str12)
# If there are a lot of characters in the string that need to be escaped, you need to add a lot of \. To simplify, python allows r "" to be used to indicate that the string inside "" does not escape by default
# \\\t\\
print("\\\t\\")
print("\\\\\\t\\\\")
print(r"\\\t\\")3. Compare sizes
Principle: get the characters from the left side of the two strings in order. Compare the two characters. Whose askoma value is large is which string is large. If it is equal, continue to compare the next one
str1 = "abc" str2 = "ab" print(str1 > str2)
4. Built in features
Note: the string itself cannot be changed
-
eval()
Prototype: eval(str)
Function: evaluate the string as a valid expression and return the result
Return value: calculated numbernum = eval("123") print(num, type(num)) # print(int("12+3")) #report errors print(eval("12+3")) print(eval("+123")) print(eval("-123")) print(eval("12-3")) print(eval("12*3")) #Note: errors will be reported if there are non numeric characters in the string (except for mathematical operators) # print(eval("12a3")) #report errors # print(eval("a123")) #report errors # print(eval("123a")) #report errors # It means that variables are OK a = "124" print(eval("a")) # print(eval("a+1")) #report errors -
len(string)
Prototype: len(str)
Function: calculate the length of the string (by the number of characters)
Parameter: a string
Return value: length of stringprint(len("lucky is a good man")) print(len("lucky is a good man Kai")) -
lower()
Prototype: lower()
Function: change all uppercase letters in the string to lowercasestr1 = "lucky Is a GoOd MAn!" str2 = str1.lower() print(str1) print(str2)
-
upper()
Prototype: upper()
Function: change all lowercase letters in the string to uppercasestr3 = "lucky Is a GoOd MAn!" str4 = str3.upper() print(str3) print(str4)
-
swapcase()
Prototype: swapcase()
Function: change the uppercase letters into lowercase and lowercase letters into uppercasestr5 = "lucky Is a GoOd MAn!" str6 = str5.swapcase() print(str5) print(str6)
-
capitalize()
Prototype: capitalize()
Function: change the first character in the string to uppercase and the rest to lowercasestr7 = "lucky Is a GoOd MAn!" str8 = str7.capitalize() print(str7) print(str8)
-
title()
Prototype: title()
Function: get "title" string, the first character of each word is uppercase, the rest is lowercasestr9 = "lucky Is a GoOd MAn!" str10 = str9.title() print(str10)
-
center(width[, fillchar])
Function: returns a middle string with the specified width, fillchar is the fill string, and the default is space
print("lucky".center(20, "#")) -
ljust(width[, fillchar])
Function: returns a left aligned string with the specified width, fillchar is the fill string, and the default is space
print("lucky".ljust(20, "#")) -
rjust(width,[, fillchar])
Function: returns a right aligned string with the specified width, fillchar is the fill string, and the default is space
print("lucky".rjust(20, "#")) -
zfill (width)
Function: returns a right aligned string with the specified width, and fills 0 by default
print("lucky".zfill(20)) -
count(str[, beg= 0[,end=len(string)]])
Function: returns the number of times str appears in string. If be or end is specified, it returns the number of times in the specified range
str11 = "lucky is a very very good man very" print(str11.count("very")) print(str11.count("very", 13)) print(str11.count("very", 13, 25)) -
find(str[, beg=0[, end=len(string)]])
Function: check whether str is included in the string. By default, it looks from left to right. If it exists, it returns the first occurrence of the subscript. Otherwise, it returns - 1. If be or end is specified, it will be detected within the specified range
str12 = "lucky is a very very good man" print(str12.find("very")) # print(str12.find("nice")) -
index(str[, beg=0[, end=len(string)]])
Function: check whether str is included in the string. By default, it looks from left to right. If it exists, it returns the first occurrence of the subscript. Otherwise, it returns an exception (error report). If be or end is specified, it is detected within the specified range
str13 = "lucky is a very very good man" print(str13.index("very")) # print(str13.index("nice")) -
rfind(str[, beg=0[,end=len(string)]])
Function: check whether str is included in the string. By default, find from right to left. If it exists, return the first occurrence of the subscript. Otherwise, return - 1. If be or end is specified, detect within the specified range
-
str12 = "lucky is a very very good man" print(str12.rfind("very")) # print(str12.rfind("nice")) -
rindex(str[, beg=0[, end=len(string)]])
Function: check whether str is included in the string. By default, search from right to left. If it exists, return the first occurrence of the subscript. Otherwise, return an exception (error report). If be or end is specified, check within the specified range
str13 = "lucky is a very very good man" print(str13.rindex("very")) # print(str13.rindex("nice")) -
lstrip([char])
Function: cut off the characters specified on the left side of the string, the default is space
str14 = " lucky is a good man" str15 = str14.lstrip() print(str14) print(str15) str16 = "######lucky is a good man" str17 = str16.lstrip("#") print(str16) print(str17) -
rstrip([char])
Function: cut off the characters specified on the right and left of the characters. The default is space
str18 = "lucky is a good man " str19 = str18.rstrip() print(str18,"*") print(str19,"*")
-
strip([chars])
Function: executing lstrip and rstrip on strings
-
split(str=" "[, num=string.count(str)])
Function: cut the string according to str (silent space) to get a list, which is the collection of each word
str20 = "lucky is a good man" print(str20.split()) print(str20.split(" ")) str21 = "lucky####is##a#good#man" print(str21.split("#")) -
splitlines([keepends])
Function: cut by lines ('\ r', '\ r\n', '\ n'). If keeps is False, it does not contain line breaks, otherwise it contains line breaks
str22 = """good nice cool handsome """ print(str22.splitlines()) print(str22.splitlines(False)) print(str22.splitlines(True))
-
join(seq)
Function: specify string elements in character splicing list
str23 = "lucky is a good man" li = str23.split() str24 = "##".join(li) print(str24)
-
max(str)
Function: returns the largest character in the string
print(max("abcdef")) -
min(str)
Function: returns the smallest character in a string
print(min("abcdef")) -
replace(old, new[, max])
Function: replace old in string with new. If max value is not specified, replace all. If max value is specified, replace no more than max times
str25 = "lucky is a good good good man" str26 = str25.replace("good", "cool") print(str26) -
maketrans()
Function: create conversion table of character mapping
t = str.maketrans("un", "ab") -
translate(table, deletechars="")
Function: convert characters according to the given conversion table
str27 = "lucky is a good man" str28 = str27.translate(t) print(str28)
-
isalpha()
Function: returns true if the string has at least one character and all characters are English letters, false otherwise
print("abc".isalpha()) print("ab1c".isalpha()) -
isalnum()
Function: returns true if the string has at least one character and all characters are English letters or numbers, false otherwise
print("abc1".isalnum()) print("abc".isalnum()) print("1234".isalnum()) -
isupper()
Function: returns true if the string has at least one character and all the letters are uppercase, false otherwise
print("12AB".isupper()) print("12ABc".isupper()) -
islower()
Function: returns true if the string has at least one character and all letters are lowercase, false otherwise
-
istitle()
Function: returns true if the string is titled, false otherwise
-
isdigit()
Function: returns true if the string contains only numbers, false otherwise
print("1234".isdigit()) print("1234a".isdigit()) -
isnumeric()
Function: returns true if the string contains only numbers, false otherwise
-
isdecimal()
Function: check whether the string contains only decimal digits
-
isspace()
Function: returns true if the string contains only blank characters, false otherwise
print("".isspace()) print(" ".isspace()) print("\t".isspace()) print("\n".isspace()) print("\r".isspace()) print("\r\n".isspace()) print(" abc".isspace()) -
startswith(str[, beg=0[,end=len(string)]])
Function: check whether the string starts with str, if yes, return true; otherwise, return false, and specify the range
str29 = "lucky is a good man" print(str29.startswith("kaige")) -
endswith(suffix, beg=0, end=len(string))
Function: check whether the string ends in str, if yes, return true; otherwise, return false, and specify the range
-
encode(encoding='UTF-8',errors='strict')
Function: Code in the encoding format specified by encoding. If there is an error, a ValueError exception will be reported, unless the value specified by errors is ignore or replace -
str30 = "lucky A good man" str31 = str30.encode() print(str31, type(str31))
-
bytes.decode(encoding="utf-8", errors="strict")
Function: decode in the format specified by encoding. Note that the format used in decoding should be the same as that used in encoding
str32 = str31.decode("GBK", errors="ignore") print(str32, type(str32)) -
ord()
Function: get integer representation of characters
print(ord("a")) -
chr()
Function: change the number code to the corresponding character
print(chr(97))
-
str()
Function: convert to string
num1 = 10 str33 = str(num1) print(str33, type(str33))
Two. list
1. When do I use lists?
-
reflection
Store 5 people's ages and average them
age1 = 18 age2 = 19 age3 = 20 age4 = 21 age5 = 22
-
reflection
Store age of 100 people
-
solve
Use list
2. Basic use
-
essence
Is an ordered set
-
Create list
''' Create list Format: list name = [element 1, element 2 , element n] ''' #Create an empty list li1 = [] print(li1, type(li1)) #Create a list with elements #Note: the types of elements in the list can be different, but this situation will not exist in future development li2 = [1, 2, 3, 4, 5, "good", True] print(li2)
-
Access to list elements
# Access to list elements li3 = [1,2,3,4,5] # Add elements to the end of the list li3.append(6) # Get element list name [subscript] print(li3[2]) # print(li3[9]) #Subscript out of range, overflow # print(li3[-1]) # The subscript can be negative, - 1 indicates the subscript of the last element, - 2 indicates the penultimate, and so on # Modify element list name [subscript] = value li3[2] = 33 # li3[6] = 10 #Subscript does not exist print(li3) # Intercept list print(li3[1:3]) print(li3[1:]) print(li3[:3])
-
List operation
# List addition (list combination) li4 = [1,2,3] li5 = [4,5,6] li6 = li4 +li5 print(li6)
# Multiply list (duplicate list) li7 = [7,8,9] li8 = li7 * 3 print(li7) print(li8)
# Member judgment li9 = [1,2,3] print(1 in li9) print(4 in li9)
3. 2D list
Concept: an element in a list is a list of one bit lists
Essence: one dimensional list
li1 = [[1,2,3],
[4,5,6],
[7,8,9]]
print(li1[1][1])4. Built in features
-
append(obj)
Add a new element at the end of the list
li1 = [1,2,3,4,5] li1.append(6) li1.append([7,8,9]) print(li1)
-
extend(seq)
Append more than one element at the end of the list
li2 = [1,2,3,4,5] li2.extend([6,7,8]) print(li2)
-
insert(index, obj)
Insert the element obj into the list by subscript, the original data will not be overwritten, and the original data will be moved backward in order
li3 = [1,2,3,4,5] li3.insert(2, 100) print(li3)
-
pop(index=-1)
Remove the specified subscript element in the list, remove the last one by default, and return the deleted data
li4 = [1,2,3,4,5] data = li4.pop() print(data, li4)
-
remove(obj)
Remove the first occurrence of obj element in the list
li5 = [1,2,3,4,5,2,4,2,5,6,7] li5.remove(2) print(li5)
-
clear()
clear list
li6 = [1,2,3,4,5] li6.clear() print(li6)
-
count(obj)
Returns the number of times the element obj appears in the list
li7 = [1,2,3,4,5,2,4,2,5,6,7] print(li7.count(2))
-
len(seq)
Returns the number of elements in the list
li8 = [1,2,3,4,5] print(len(li8))
-
index(obj)
Get the subscript of the first occurrence of an element in the list, otherwise a ValueError exception will be thrown
li9 = [1,2,3,4,5,2,4,2,5,6,7] print(li9.index(2))
-
max(seq)
Returns the largest element in the list
print(max([2,3,4,1,4,6,7,3]))
-
min(seq)
Returns the smallest element in the list
-
reverse()
List reverse
li10 = [1,2,3,4,5] li10.reverse() print(li10)
-
sort()
Sort the list elements according to the rules given by func function. The default is ascending
li11 = [2,1,3,5,4] li11.sort() print(li11)
-
list(seq)
Convert other types of collections to list types
str1 = "lucky" li12 = list(str1) print(li12, type(li12))
5. Memory problems
-
assignment
- ==And is
num1 = 1 num2 = 1 print(id(num1), id(num2)) print(num1 == num2) print(num1 is num2) num3 = 401 num4 = 401 print(id(num3), id(num4)) print(num3 == num4) print(num3 is num4)
- assignment
a = [1,2,3,4,5] b = a print(id(a), id(b)) print(a == b) print(a is b)
c = [1,2,3,4,5,[7,100,9]] d = c print(c == d) print(c is d) c[5][0] = 60 print(c) print(d)
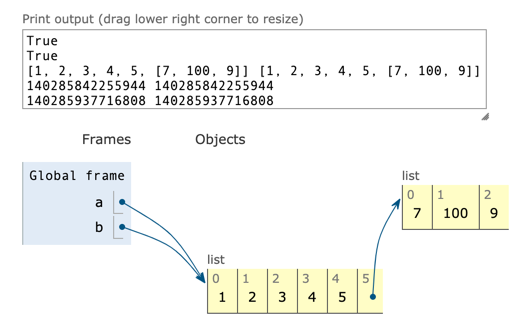
-
Light copy
Copy only surface elements
from copy import copy a = [1,2,3,4,5] b = copy(a) print(id(a), id(b)) print(a == b) print(a is b) c = [1,2,3,[4,5,6]] d = copy(c) print(id(c), id(d)) print(c == d) print(c is d) print(id(c[3]), id(d[3])) print(c[3] == d[3]) print(c[3] is d[3])
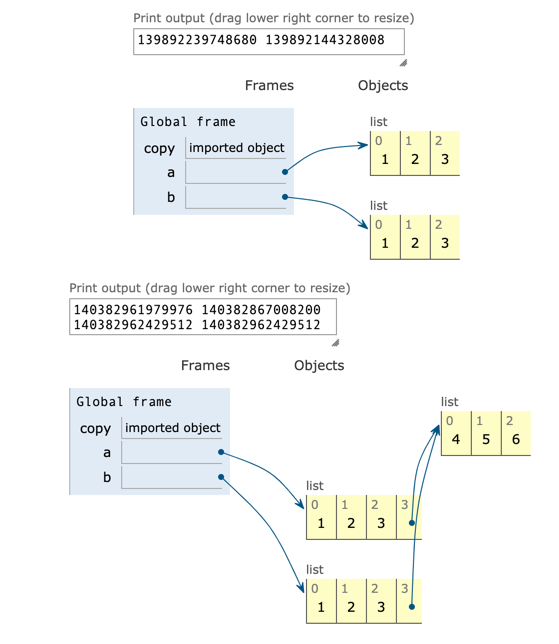
-
Deep copy
Note: no matter the deep copy or the shallow copy, a new content space will be generated in the memory (recreate the copied content in the memory)
The premise that the two are different: there is another list in the element
Note: deep copy recreates all child elements in memory
from copy import deepcopy a = [1,2,3,4,5] b = deepcopy(a) print(id(a), id(b)) print(a == b) print(a is b) c = [1,2,3,4,5,[6,7,8]] d = deepcopy(c) print(id(c), id(d)) print(c == d) print(c is d) print(id(c[5]), id(d[5])) print(c[5] == d[5]) print(c[5] is d[5])
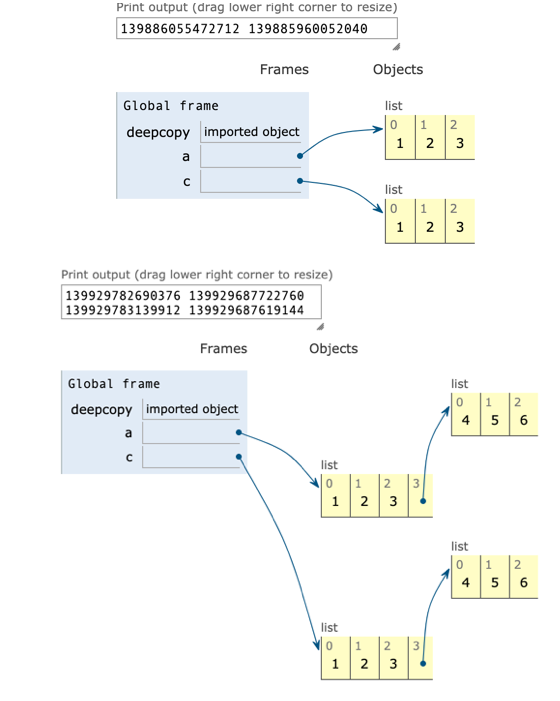
3, Tuple tuple
1. Overview
-
essence
Ordered set
-
characteristic
- Very similar to list
- Once initialized, it cannot be modified
- Use parentheses
2. Basic use
-
establish
''' Create format: Tuple name = (element 1, element 2 , element n) ''' #Create empty ancestor t1 = () print(t1, type(t1)) #Create tuples with elements. The element types of tuples can be different t2 = (1,2,3,4,5) print(t2) #To create a tuple with one element, you need to add a comma t3 = (1,) print(t3, type(t3))
-
Tuple element access
# Value tuple name [subscript] t4 = (1,2,3,4,5) print(t4[2]) # print(t4[7]) #Subscript out of range print(t4[-1]) # print(t4[-7]) #Subscript out of range # Note: the element cannot be modified, but if the tuple element is of list type, the element in the list can be modified t5 = (1,2,3,4,5,[6,7,8]) # t5[3] = 100 # report errors # t5[5] = [1,2,3] # report errors t5[5][0] = 60 print(t5)
-
Tuple operation
t6 = (1,2,3) t7 = (4,5,6) t8 = t6 + t7 print(t8, t6, t7) print(t6 * 3)
-
Tuple truncation
t9 = (1,2,3,4,5,6,7,8,9,0) print(t9[3:7]) print(t9[3:]) print(t9[:7]) print(t9[3:-2])
-
Tuple symmetric assignment
# For functions to return multiple return values num1, num2 = (1, 2) # If there is only one placeholder, you can omit the parentheses, but it is better not to omit them print("num1 = %d"%num1) print("num2 = %d"%(num2))
3. Operation method
-
len(seq)
print(len((1,2,3,4)))
-
max()
-
min()
-
tuple(seq)
Convert sets of other types to tuple types
print(tuple("lucky")) print(tuple([1,2,3,4]))
4, dict dictionary
1. Overview
-
concept
Using the form of key value pair to store data has extremely fast search speed
-
characteristic
-
key in dictionary must be unique
-
Key value pairs are unordered
-
key must be immutable
a: Strings and numbers are immutable, and can be used as key s (generally strings)
b: The list is variable and cannot be used as a key
-
-
reflection
Save a student's information (name, student number, gender, age, height, weight)
str1 = "lucky#1#male#18#173.5#80" li1 = ["lucky", 1, "male", 18, 173.5, 80] t1 = ("lucky", 1, "male", 18, 173.5, 80) -
Problem solving
Using dictionaries
Definition format: dictionary name = {key1:value1, key2:value2 ,keyn:valuen}
2. Basic use
-
establish
# Create a dictionary to save a student's information stu1 = {"name": "lucky", "age": 18, "sex": "male", "height": 173.5, "weight":80, "id": 1} stu2 = {"name": "liudh", "age": 57, "sex": "male", "height": 180, "weight":75, "id": 2} stus = [stu1, stu2] -
ACCESS Dictionary values
stu3 = {"name": "lucky", "age": 18, "sex": "male", "height": 173.5, "weight":80, "id": 1} # Get dictionary name [key] print(stu3["name"]) # print(stu3["money"]) #Error will be reported when getting non-existent property value # Get dictionary name.get(key) print(stu3.get("age")) print(stu3.get("money")) # Get the nonexistent property and get None money = stu3.get("money") if money: print("money = %d"%money) else: print("No, money attribute") -
Add key value pair
# Add key value pairs. If no key is added, some will be modified stu3["nikeName"] = "kaige" stu3["age"] = 16
-
delete
stu3.pop("nikeName") print(stu3)
3. Compare list with dict
-
list
Advantages: small memory space occupied, little memory wasted
Disadvantage: the efficiency of finding and inserting will decrease with the increase of elements
-
dict
Advantages: the speed of searching and inserting is extremely fast, and the efficiency will not be reduced with the increase of key value
Disadvantages: need to occupy a large amount of memory, memory waste too much
5, Set set
1. Overview
Feature: similar to dict, it is a set of key s (no value is stored)
Essence: disordered and unrepeated set
2. Basic use
-
establish
#Create: need a list or tuple as the input set s1 = set([1,2,3,4,5]) print(s1, type(s1)) s2 = set((1,2,3,4,5)) print(s2, type(s2)) s3 = set("lucky") print(s3, type(s3)) -
effect
# Function: List de duplication li1 = [1,2,4,6,7,5,4,3,22,2,3,46,7,8,1,3,5] s4 = set(li1) li2 = list(s4) print(li2)
-
add to
s5 = set([1,2,3,4,5]) # Cannot insert a number element directly # s5.update(6) # report errors # s5.update([6,7,8]) # s5.update((6,7,8)) # s5.update("678") s5.update([(6,7,8)]) print(s5) -
delete
s6 = set([1,2,3,4,5]) # Delete from left data = s6.pop() print(data, s6) # Delete by element, if the element does not have an exception reporting KeyError s6.remove(4) # s6.remove(7) print(s6)
-
ergodic
s7 = set([1,2,3,4,5]) for key in s7: print("--------", key) for index, key in enumerate(s7): print(index, key)
3. Intersection and union
s8 = set([1,2,3,4,5]) s9 = set([3,4,5,6,7]) #intersection print(s8 & s9) #Union print(s8 | s9)
6, Null
Note: is a special value in python, represented by None
Note: None cannot be understood as 0, because 0 is meaningful, and None has no practical significance
effect:
1. When defining a variable, you do not know what the initial value is to be assigned. You can write the assignment as None. Assign when you have a certain value
2. If no data is found in the dictionary, a None will be returned
c = None print(c)
7, Variable type problem
The type of variable should be determined according to the corresponding data. The type of variable is variable
a = 1 print(a, type(a)) a = "lucky" print(a, type(a)) a = True print(a, type(a))
8, Type conversion
1,list/tuple/string->set
s1 = set([1,2,3,4,5])
s2 = set((1,2,3,4,5))
s3 = set("lucky")
print(s1, s2, s3)2,tuple/set/string ->list
l1 = list((1,2,3,4,5))
l2 = list(set([1,2,3,4,5]))
l3 = list("lucky")
print(l1, l2, l3)3,list/set/string->tuple
t1 = tuple([1,2,3,4,5])
t2 = tuple(set([1,2,3,4,5]))
t3 = tuple("lucky")
print(t1, t2, t3)9, Mutable and immutable objects
1. Description
In python, strings, tuples, and numbers are immutable objects, while list and dict are modifiable objects
2. Immutable type
The data in the value corresponding to the variable cannot be modified. If it is modified, a new value will be generated to allocate the new memory space
Immutable type:
-
Value (int,float,bool)
-
String (string)
- tuple

Result: two different storage addresses
3. Variable type
The data in the value corresponding to the variable can be modified, but the memory address remains unchanged
Variable type:
List (list)
Dictionary (dict)
Set (set)

Result: two identical storage addresses
['Liu Bei', 'Guan Yu', 'Zhang Fei', 'Zhao Yun']
Result: two identical storage addresses
{'name': 'Liu Bei','age': 20}