Atomization treatment can be represented by the following model:
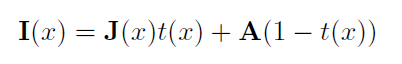
I (x): foggy picture
J (x): picture of defogging
A : Global atmospheric light
T (x): intermediate transformation mapping, depending on unknown depth information, medium transmission map
The previous defogging methods used regression method and artificially designed A priori conditions to estimate A or t(x), but the problem is that these two items are difficult to obtain in reality. The method used in this paper is to directly learn the residuals between the original map and the fog map.
Since hole convolution is widely used to aggregate context information to improve its effectiveness without sacrificing spatial resolution, we also use it to help obtain more accurate recovery results by covering more adjacent pixels. However, the original expansion convolution will produce the so-called "mesh artifact", because when the expansion rate is greater than 1, the adjacent cells in the output are calculated according to the completely independent set in the input. Therefore, the expanded convolution is analyzed by synthesis, and it is proposed to smooth the expanded convolution, which can greatly reduce this meshing artifact. Therefore, we also incorporate this idea into our context aggregation network. Because integrating different levels of functionality is usually beneficial for both low-level and high-level tasks. Therefore, this paper further proposes a gated subnet to determine the importance of different levels, and fuse them according to their corresponding importance weights.
Model
The encoder decoder model proposed in this paper mainly includes the following three parts:
- Auto encoder, down sampling at the last layer
- Smooth divided resblock inserted between encoder and decoder
- The decoder of the Gated Fusion network is added, symmetrically with the encoder, and the first layer is up sampled
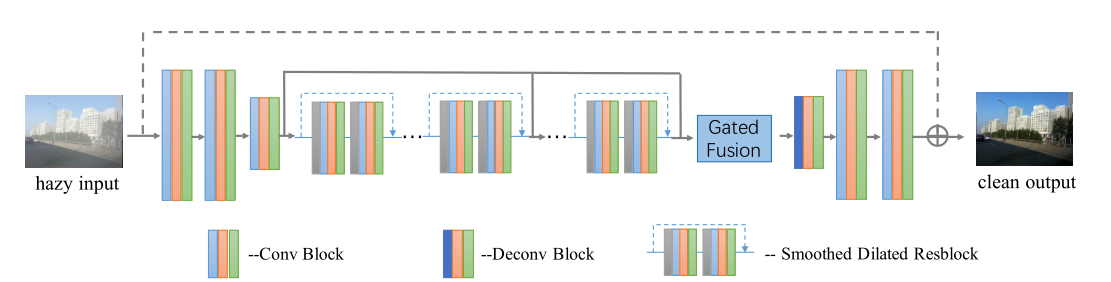
The model consists of three convolution blocks as the encoder, one deconvolution block and two convolution blocks as the decoder. Several smooth empty residual blocks are inserted between them to aggregate the context information without causing the illusion of meshing. In order to fuse different levels of functions, an additional gate fusion sub network needs to be used. At run time, GCANet will end-to-end predict the residual between the target clean image and the blurred input image.
Given a fuzzy input image, we first encode it into a feature graph through the encoder part, and then enhance them by aggregating more context information and fusing different levels of features without down sampling. Specifically, smooth extended convolution and additional gate subnet are used. Finally, the enhanced feature image is decoded back to the original image space to obtain the target haze residue. By adding it to the input blurred image, we will get the final fog free image.
Defogging process:
- Coded picture features
- Add context information to integrate different levels of features
- Decode the feature map to get the residual
- Add the residuals to the fog map to get the fog removal picture
The two most important contributions of the paper are:
- Smooth divided revolution is used to replace the original divided revolution and eliminate grid artifacts
- The gated fusion sub network is used to integrate the characteristics of different levels, which is beneficial to both low-level tasks and high-level tasks
Smooth divided convolution
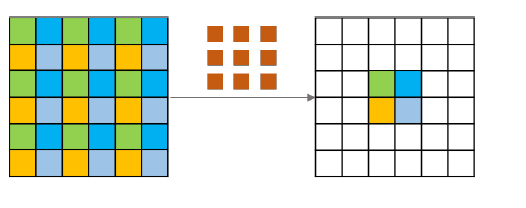
The four adjacent pixels in the next layer and their subordinate units in the previous layer are marked with four different colors respectively. We can easily find that these four neighbor pixels are related to a completely different set of previous units in the upper layer. In other words, in the extended convolution, there is no dependency between input units or output units. This is why it will potentially cause inconsistencies, namely mesh artifacts.
By analyzing the hole convolution process, we can see that the four adjacent pixels output after convolution are independent of the dependent pixels in the upper layer (that is, there is no adjacent and equal dependency between pixels of the same color)
Therefore, before hole convolution, an operation of separating convolution with (2r-1) kernel is added, and the parameters of convolution are shared by all channels. "Separable" is a separable convolution idea, and "shared" means that all channels share convolution weights. After these operations, each feature point integrates the surrounding (2r-1) features. (r = expansion rate)
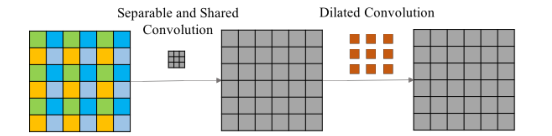
The four different points of the next layer in the figure are represented by different colors. It can be seen that they are related to completely different cell sets. We know that the image has local correlation. Similarly, the feature layer should also retain this feature, otherwise it will lead to meshing artifacts. In contrast, smooth expansion convolution adds additional separable and shared convolution layers between input units before expansion convolution . Interaction is added between input units before convolution or between output units after convolution, and all channels share convolution weights.
Gated fusion sub network
After learning the feature information, we can effectively train it by fusing it in an appropriate way. The method of this paper is to extract the feature maps f l, f m, f h from different levels of high, medium and low Input the gated fusion network, linearly combine the features according to the learning weights Ml, Mm, Mh ^ and send the weighted sum to the decoder to obtain the residual.
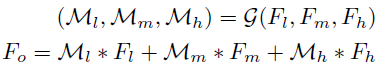
Original link: https://blog.csdn.net/weixin_37625243/article/details/102874243
GCANet.py
import torch
import torch.nn as nn
import torch.nn.functional as F
# SS convolution separate and shared convolution
class ShareSepConv(nn.Module):
def __init__(self, kernel_size):
super(ShareSepConv, self).__init__()
assert kernel_size % 2 == 1, 'kernel size should be odd' # When the assert condition is false, an error is reported
self.padding = (kernel_size - 1)//2
# The convolution kernel (weight) is defined manually. The element in the middle of the weight matrix is 1 and the rest is 0
weight_tensor = torch.zeros(1, 1, kernel_size, kernel_size)
weight_tensor[0, 0, (kernel_size-1)//2, (kernel_size-1)//2] = 1
# nn.Parameter: type conversion function, which converts a non trainable type Tensor into a trainable type parameter and binds the parameter to the module
self.weight = nn.Parameter(weight_tensor)
self.kernel_size = kernel_size
def forward(self, x):
inc = x.size(1) # Gets the number of channels for the input picture
# According to the definition of share and separable revolution, each channel of copy weights, x corresponds to the same weight,contiguous() function, so that it is aligned in the memory space after copying
# . expand automatically expands all dimensions with length 1 of the original tensor to the required length,
expand_weight = self.weight.expand(inc, 1, self.kernel_size, self.kernel_size).contiguous()
# Call F.conv2d for convolution
# It can be understood that nn.Conv2d is [2D convolution layer], and F.conv2d is [2D convolution operation]
return F.conv2d(x, expand_weight,
None, 1, self.padding, 1, inc) # group : inc
# Improved cavity convolution
class SmoothDilatedResidualBlock(nn.Module):
def __init__(self, channel_num, dilation=1, group=1):
super(SmoothDilatedResidualBlock, self).__init__()
# SS revolution is used for local information fusion before hole convolution
self.pre_conv1 = ShareSepConv(dilation*2-1)
# Void convolution
self.conv1 = nn.Conv2d(channel_num, channel_num, 3, 1, padding=dilation, dilation=dilation, groups=group, bias=False)
# Normalized layer num_features: the number of features from the expected input. Fine: Boolean value. When set to true, add learnable affine transformation parameters to the layer
self.norm1 = nn.InstanceNorm2d(channel_num, affine=True)
self.pre_conv2 = ShareSepConv(dilation*2-1)
self.conv2 = nn.Conv2d(channel_num, channel_num, 3, 1, padding=dilation, dilation=dilation, groups=group, bias=False)
self.norm2 = nn.InstanceNorm2d(channel_num, affine=True)
def forward(self, x):
# Residual connection
y = F.relu(self.norm1(self.conv1(self.pre_conv1(x))))
y = self.norm2(self.conv2(self.pre_conv2(y)))
return F.relu(x+y)
# Residual network
# Based on the idea of using direct mapping to connect different layers of the network, the residual network came into being
# A shortcut is added every two layers to form a residual block. This structure diagram has 7 residual blocks
class ResidualBlock(nn.Module):
def __init__(self, channel_num, dilation=1, group=1):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(channel_num, channel_num, 3, 1, padding=dilation, dilation=dilation, groups=group, bias=False)
self.norm1 = nn.InstanceNorm2d(channel_num, affine=True)
self.conv2 = nn.Conv2d(channel_num, channel_num, 3, 1, padding=dilation, dilation=dilation, groups=group, bias=False)
self.norm2 = nn.InstanceNorm2d(channel_num, affine=True)
def forward(self, x):
y = F.relu(self.norm1(self.conv1(x)))
y = self.norm2(self.conv2(y))
return F.relu(x+y)
class GCANet(nn.Module):
def __init__(self, in_c=4, out_c=3, only_residual=True):
super(GCANet, self).__init__()
# Encoder: three-layer convolution, 64 channels, convolution kernel size 3 * 3, stripe = 1, padding=1
self.conv1 = nn.Conv2d(in_c, 64, 3, 1, 1, bias=False)
self.norm1 = nn.InstanceNorm2d(64, affine=True) # Instance Normalization
self.conv2 = nn.Conv2d(64, 64, 3, 1, 1, bias=False)
self.norm2 = nn.InstanceNorm2d(64, affine=True)
self.conv3 = nn.Conv2d(64, 64, 3, 2, 1, bias=False) # Down sampling with stripe = 2
self.norm3 = nn.InstanceNorm2d(64, affine=True)
# Middle layer: 7 layers of smooth divided revolution residual blocks, with void rates r of 2,2,2,4,4,4,1 and 64 channels respectively
self.res1 = SmoothDilatedResidualBlock(64, dilation=2)
self.res2 = SmoothDilatedResidualBlock(64, dilation=2)
self.res3 = SmoothDilatedResidualBlock(64, dilation=2)
self.res4 = SmoothDilatedResidualBlock(64, dilation=4)
self.res5 = SmoothDilatedResidualBlock(64, dilation=4)
self.res6 = SmoothDilatedResidualBlock(64, dilation=4)
self.res7 = ResidualBlock(64, dilation=1) # When the void rate is 1, the convolution kernel of the separated convolution is 1 * 1, which does not play the role of information fusion. Therefore, this layer degenerates into an ordinary residual network
# Gated fusion sub network: learn the weight of low, medium and high-level features
self.gate = nn.Conv2d(64 * 3, 3, 3, 1, 1, bias=True)
# Decoder: 1 deconvolution layer samples the feature map to the original resolution + 2 convolution layers restore the feature map to the original image space
self.deconv3 = nn.ConvTranspose2d(64, 64, 4, 2, 1) # Upsampling with stripe = 2
self.norm4 = nn.InstanceNorm2d(64, affine=True)
self.deconv2 = nn.Conv2d(64, 64, 3, 1, 1)
self.norm5 = nn.InstanceNorm2d(64, affine=True)
self.deconv1 = nn.Conv2d(64, out_c, 1) # 1 * 1 convolution kernel for dimension reduction
self.only_residual = only_residual
def forward(self, x):
# Encoder propagates forward and is activated using relu
y = F.relu(self.norm1(self.conv1(x)))
y = F.relu(self.norm2(self.conv2(y)))
y1 = F.relu(self.norm3(self.conv3(y))) # Low level information
# Middle layer
y = self.res1(y1)
y = self.res2(y)
y = self.res3(y)
y2 = self.res4(y) # Middle level information
y = self.res5(y2)
y = self.res6(y)
y3 = self.res7(y) # High level information
# Gated fusion sub network
gates = self.gate(torch.cat((y1, y2, y3), dim=1)) # Calculate the weight of low, medium and high-level features
gated_y = y1 * gates[:, [0], :, :] + y2 * gates[:, [1], :, :] + y3 * gates[:, [2], :, :] # Weighted sum of low, medium and high-level features
y = F.relu(self.norm4(self.deconv3(gated_y)))
y = F.relu(self.norm5(self.deconv2(y)))
if self.only_residual: # Defogging
y = self.deconv1(y)
else: # To rain
y = F.relu(self.deconv1(y))
return y
test.py
import os
import argparse
import numpy as np
from PIL import Image
import torch
from torch.autograd import Variable
from utils import make_dataset, edge_compute
# argpars is a python module: command line interpretation, parameters, and subcommand interpreter
parser = argparse.ArgumentParser()
parser.add_argument('--network', default='GCANet')
parser.add_argument('--task', default='dehaze', help='dehaze | derain')
parser.add_argument('--gpu_id', type=int, default=-1)
parser.add_argument('--indir', default='examples/')
parser.add_argument('--outdir', default='output')
opt = parser.parse_args()
assert opt.task in ['dehaze', 'derain']
## forget to regress the residue for deraining by mistake,
## which should be able to produce better results
opt.only_residual = opt.task == 'dehaze'
# Load the model and specify the input and output path
opt.model = 'models/wacv_gcanet_%s.pth' % opt.task
opt.use_cuda = opt.gpu_id >= 0
if not os.path.exists(opt.outdir):
os.makedirs(opt.outdir)
test_img_paths = make_dataset(opt.indir) # utils.py
# Initialization model
if opt.network == 'GCANet':
from GCANet import GCANet
# Input channel: 4 (including edge information); Output channel: 3 (RGB)
net = GCANet(in_c=4, out_c=3, only_residual=opt.only_residual)
else:
print('network structure %s not supported' % opt.network)
raise ValueError
# GPU or CPU
if opt.use_cuda:
torch.cuda.set_device(opt.gpu_id)
net.cuda()
else:
net.float() # Convert model data type to float
# Load parameters, map_location represents a function, torch.device, or dictionary, indicating how to remap the storage location
# Load the pre trained parameter weights into the new model
net.load_state_dict(torch.load(opt.model, map_location='cpu'))
# Do not enable BatchNormalization and dropout to ensure that BN and dropout do not change,
net.eval()
# Processing input
for img_path in test_img_paths:
img = Image.open(img_path).convert('RGB') # If. convert('RGB ') is not used for conversion, the read image is RGBA four channel, and channel A is transparent
im_w, im_h = img.size
if im_w % 4 != 0 or im_h % 4 != 0: # ??????????????
img = img.resize((int(im_w // 4 * 4), int (im_h / / 4 * 4)) # converts the height and width of the image to an integer multiple of 4
img = np.array(img).astype('float') # Converts the height and width of img to the type of array
img_data = torch.from_numpy(img.transpose((2, 0, 1))).float() # (coordinate x, coordinate y, channel) - > (channel, coordinate x, coordinate y), and convert to tensor type
edge_data = edge_compute(img_data) # Calculate edge information
# Data centralization [0255] - [128127], torch.cat is to splice two tensor s together, dim = 0, which means splicing by dimension, equal to 1, splicing by column
# The function of unsqueeze() is to increase the dimension of a given tensor. unsqueeze(dim) is to add one dimension to the tensor where the dimension number is dim
in_data = torch.cat((img_data, edge_data), dim=0).unsqueeze(0) - 128
# GPU OR CPU
in_data = in_data.cuda() if opt.use_cuda else in_data.float()
with torch.no_grad():
pred = net(Variable(in_data))
# Round: round clamp: truncated when greater than or less than the threshold (input, min, max, out=None)
if opt.only_residual: # Defogging image = original image + predicted value (residual)
out_img_data = (pred.data[0].cpu().float() + img_data).round().clamp(0, 255)
else: # Rain removal image = predicted value
out_img_data = pred.data[0].cpu().float().round().clamp(0, 255)
# Save picture
out_img = Image.fromarray(out_img_data.numpy().astype(np.uint8).transpose(1, 2, 0)) # Convert array type to image format
out_img.save(os.path.join(opt.outdir, os.path.splitext(os.path.basename(img_path))[0] + '_%s.png' % opt.task))
utils.py
import os
import torch
IMG_EXTENSIONS = [
'.jpg', '.JPG', '.jpeg', '.JPEG',
'.png', '.PNG', '.ppm', '.PPM', '.bmp', '.BMP',
]
# In Python, there are two functions, the startswitch() function and the endswitch() function, which have very similar functions,
# The startswitch() function determines whether the text starts with a character, and the endswitch() function determines whether the text ends with a character. Its return value is Boolean. If it is True, it returns True, otherwise it returns False.
def is_image_file(filename):
return any(filename.endswith(extension) for extension in IMG_EXTENSIONS)
def make_dataset(dir): # Save the preprocessed foggy image to the array
images = []
assert os.path.isdir(dir), '%s is not a valid directory' % dir # Determine whether it is a directory
for root, _, fnames in sorted(os.walk(dir)): # Returns a triple of all (sub) folders (root, dirs, files)
for fname in fnames:
if is_image_file(fname):
path = os.path.join(root, fname)
images.append(path)
return images
# Calculate the edge information of the image
def edge_compute(x): # reason??????
# After passing the parameter to torch.abs, return the absolute value of the input parameter as the output. The input parameter must be a variable of Tensor data type.
x_diffx = torch.abs(x[:,:,1:] - x[:,:,:-1])
x_diffy = torch.abs(x[:,1:,:] - x[:,:-1,:])
y = x.new(x.size())
y.fill_(0)
y[:,:,1:] += x_diffx
y[:,:,:-1] += x_diffx
y[:,1:,:] += x_diffy
y[:,:-1,:] += x_diffy
y = torch.sum(y,0,keepdim=True)/3
y /= 4
return y