1, Numpy advantage
1. Introduction to ndarray
NumPy provides an N-dimensional array type ndarray, which describes a collection of "items" of the same type.
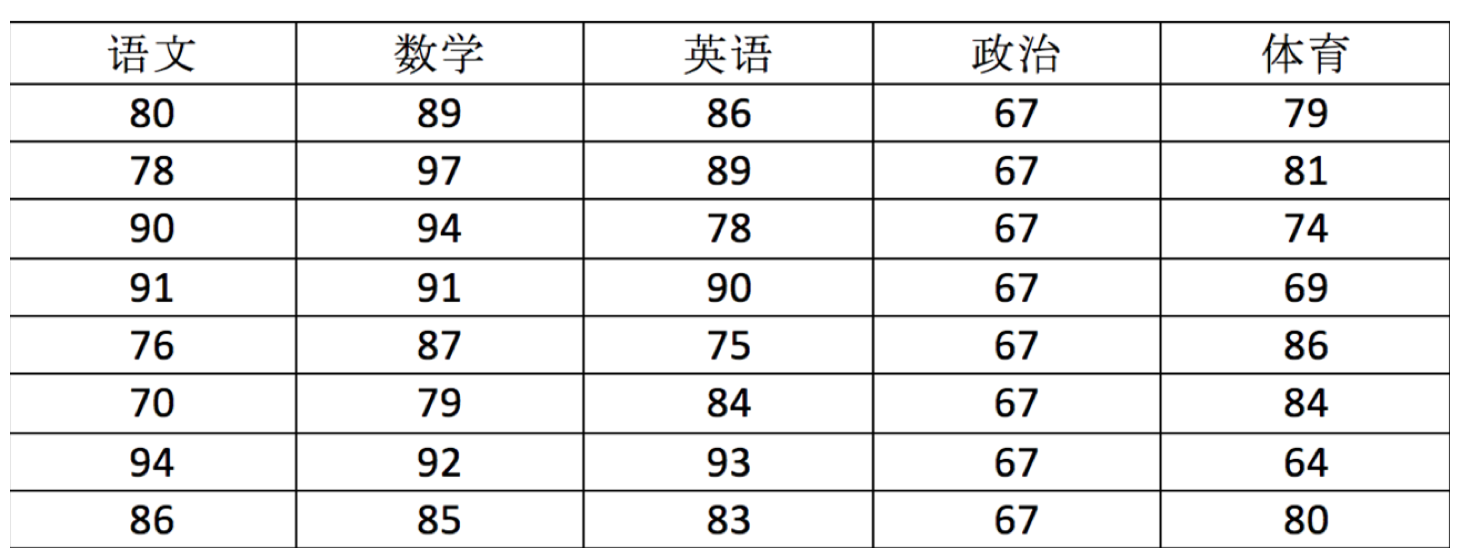
Store with ndarray:
import numpy as np # Create ndarray score = np.array( [[80, 89, 86, 67, 79], [78, 97, 89, 67, 81], [90, 94, 78, 67, 74], [91, 91, 90, 67, 69], [76, 87, 75, 67, 86], [70, 79, 84, 67, 84], [94, 92, 93, 67, 64], [86, 85, 83, 67, 80]]) score
Return result:
array([[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]])
Question: one dimensional arrays can be stored using Python lists, and multi-dimensional arrays can be realized through the nesting of lists. Why do you need to use Numpy's ndarray?
2. Comparison of operation efficiency between ndarray and Python native list
Here we realize the benefits of ndarray by running a piece of code
import random
import time
import numpy as np
a = []
for i in range(100000000):
a.append(random.random())
# Through the% time magic method, view the time taken for the current line of code to run once
%time sum1=sum(a)
b=np.array(a)
%time sum2=np.sum(b)
The first time shows the time calculated using native Python, and the second content uses numpy to calculate the time:
CPU times: user 852 ms, sys: 262 ms, total: 1.11 s Wall time: 1.13 s CPU times: user 133 ms, sys: 653 µs, total: 133 ms Wall time: 134 ms
From this, we can see that the calculation speed of ndarray is much faster and saves time.
The biggest feature of machine learning is a large number of data operations. Without a fast solution, python may not achieve good results in the field of machine learning.
Numpy is specially designed for ndarray operations and operations, so the storage efficiency and input-output performance of arrays are much better than those of nested lists in Python. The larger the array, the more obvious the advantages of numpy.
Thinking: why can ndarray be so fast?
3. Advantages of ndarray
3.1 memory block style
How is ndarray different from the native python list? Please see a figure:
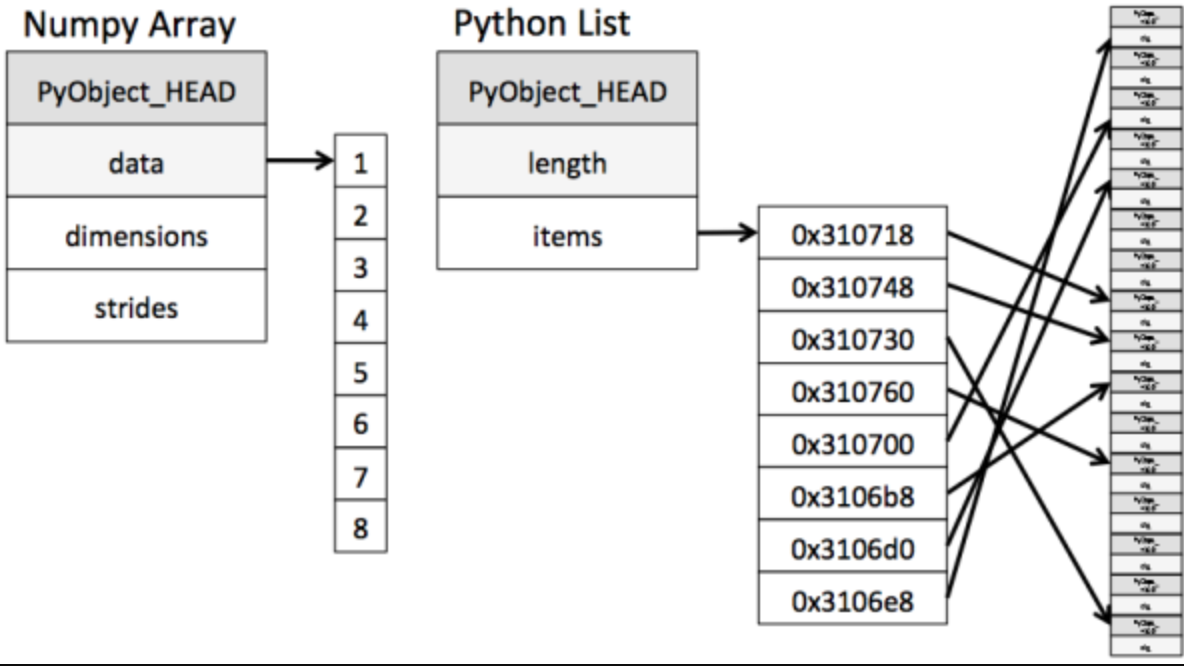
We can see from the figure that when ndarray stores data, the data and data addresses are continuous, which makes the batch operation of array elements faster.
This is because the types of all elements in the ndarray are the same, and the element types in the python list are arbitrary. Therefore, the memory of the ndarray can be continuous when storing elements, while the python native list can only find the next element through addressing. Although this also leads to the fact that the ndarray of numpy is inferior to the python native list in terms of general performance, in scientific calculation, Numpy's ndarray can eliminate many circular statements, and the code is much simpler than Python's native list.
3.2 ndarray supports parallelization (vectorization)
Numpy has built-in parallel computing function. When the system has multiple cores, numpy will automatically perform parallel computing when doing some computing
3.3 is much more efficient than pure Python code
The bottom layer of Numpy is written in C language, and the GIL (global interpreter lock) is released internally. Its operation speed on the array is not limited by the Python interpreter. Therefore, its efficiency is much higher than that of pure Python code.
2, N-dimensional array - ndarray
1. Properties of ndarray
Array properties reflect the information inherent in the array itself.
| Attribute name | Attribute interpretation |
|---|---|
| ndarray.shape | Tuple of array dimension |
| ndarray.ndim | Array dimension |
| ndarray.size | Number of elements in the array |
| ndarray.itemsize | Length of an array element (bytes) |
| ndarray.dtype | Type of array element |
2. Shape of ndarray
First create some arrays.
# Create arrays of different shapes >>> a = np.array([[1,2,3],[4,5,6]]) >>> b = np.array([1,2,3,4]) >>> c = np.array([[[1,2,3],[4,5,6]],[[1,2,3],[4,5,6]]])
Print out shapes separately
>>> a.shape >>> b.shape >>> c.shape (2, 3) # Two dimensional array (4,) # One dimensional array (2, 2, 3) # 3D array
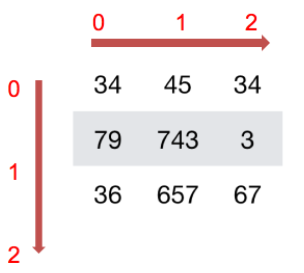
How to understand the shape of an array?
2D array:
3D array:
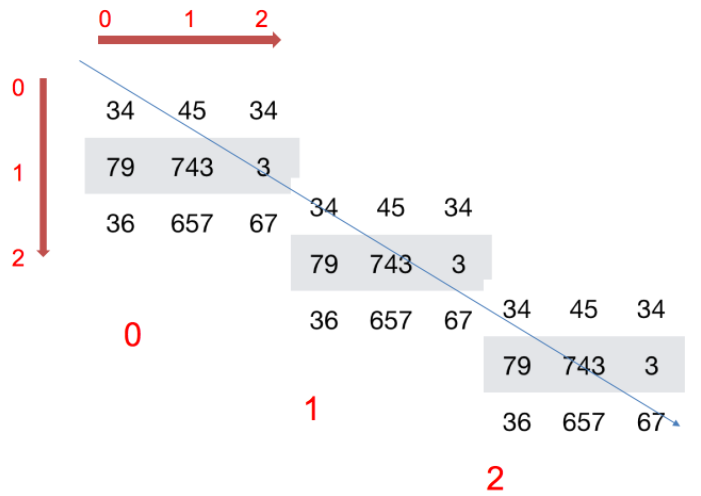
3. Type of ndarray
>>> type(score.dtype) <type 'numpy.dtype'>
Dtype is numpy.dtype. Let's see what types are available for arrays
| name | describe | Abbreviation |
|---|---|---|
| np.bool | Boolean type (True or False) stored in one byte | 'b' |
| np.int8 | One byte size, - 128 to 127 | 'i' |
| np.int16 | Integer, - 32768 to 32767 | 'i2' |
| np.int32 | Integer, - 2 ^ 31 to 2 ^ 32 - 1 | 'i4' |
| np.int64 | Integer, - 2 ^ 63 to 2 ^ 63 - 1 | 'i8' |
| np.uint8 | Unsigned integer, 0 to 255 | 'u' |
| np.uint16 | Unsigned integer, 0 to 65535 | 'u2' |
| np.uint32 | Unsigned integer, 0 to 2 ^ 32 - 1 | 'u4' |
| np.uint64 | Unsigned integer, 0 to 2 ^ 64 - 1 | 'u8' |
| np.float16 | Semi precision floating point number: 16 bits, sign 1 bit, index 5 bits, precision 10 bits | 'f2' |
| np.float32 | Single precision floating point number: 32 bits, sign 1 bit, exponent 8 bits, precision 23 bits | 'f4' |
| np.float64 | Double precision floating point number: 64 bits, sign 1 bit, index 11 bits, precision 52 bits | 'f8' |
| np.complex64 | Complex number, which represents the real part and imaginary part with two 32-bit floating-point numbers respectively | 'c8' |
| np.complex128 | Complex numbers, representing the real part and imaginary part with two 64 bit floating-point numbers respectively | 'c16' |
| np.object_ | python object | 'O' |
| np.string_ | character string | 'S' |
| np.unicode_ | unicode type | 'U' |
Specify the type when creating an array
>>> a = np.array([[1, 2, 3],[4, 5, 6]], dtype=np.float32)
>>> a.dtype
dtype('float32')
>>> arr = np.array(['python', 'tensorflow', 'scikit-learn', 'numpy'], dtype = np.string_)
>>> arr
array([b'python', b'tensorflow', b'scikit-learn', b'numpy'], dtype='|S12')
Note: if not specified, integer defaults to int64 and decimal defaults to float64
3, Basic operation
1. Method of generating array
1.1 generate an array of 0 and 1
- np.ones(shape, dtype)
- np.ones_like(a, dtype)
- np.zeros(shape, dtype)
- np.zeros_like(a, dtype)