Fully distributed cluster in installation mode
1. Introduction to fully distributed mode
Fully distributed refers to using multiple machines to build a complete distributed file system in a real environment. In the real world, hdfs Related daemons in are also distributed in different machines, such as: -1. namenode As far as possible, the daemon should be deployed separately in a machine with relatively good hardware performance. -2. One is deployed on every other machine datanode Daemon, general hardware environment. -3. secondarynamenode Daemons are best not to namenode On the same machine.
2 Platform Software Description
- operating system: win10/win7
- Virtual software: VMware14
- virtual machine:
host name IP
qianfeng01 192.168.10.101
qianfeng02 192.168.10.102
qianfeng03 192.168.10.103
- Package storage path: /root/
- Software installation path: /usr/local/
- Jdk: jdk-8u221-linux-x64.tar.gz
- Hadoop: hadoop-2.7.6.tar.gz
- user: root
Remember, remember, remember:
In the actual production environment, we will not use root Users to build and manage hdfs,Instead, use ordinary users. We only use it here for the convenience of learning root User.
Attention, attention, attention:
1.If you are from pseudo distributed, you'd better shut down the related daemons of pseudo distributed first: stop-all.sh
2.Delete the relevant settings of the original pseudo distributed
If the default path was used,It's no use now
If the original path is the same as the current fully distributed path,Because this is different from the previous initialization,And this file should be generated automatically by the system
To sum up:To delete namenode and datanode Directory of
3 daemon layout
We'll build a fully distributed hdfs, and by the way, build yarn. The layout of the daemons related to hdfs and yarn is as follows:
qianfeng01: namenode,datanode,ResourceManager,nodemanager qianfeng02: datanode,nodemanager,secondarynamenode qianfeng03: datanode,nodemanager
4 requirements and construction of fully distributed environment (key)
4.1 description of environmental requirements:
-1. The firewall of the three machines must be closed. -2. Ensure that the network configuration of the three machines is unblocked(NAT Mode, static IP,Host name configuration) -3. ensure/etc/hosts File configuration ip and hostname Mapping relationship of -4. Ensure that the password free login authentication of three machines is configured (cloning will be more convenient) -5. Ensure that all machines are time synchronized -6. jdk and hadoop Environment variable configuration for
4.2 turn off the firewall
[root@qianfeng01 ~]# systemctl stop firewalld [root@qianfeng01 ~]# systemctl disable firewalld [root@qianfeng01 ~]# systemctl stop NetworkManager [root@qianfeng01 ~]# systemctl disable NetworkManager #It is better to turn off SELinux, which is a security mechanism of linux system. Enter the file and set SELinux to disabled [root@qianfeng01 ~]# vi /etc/selinux/config ......... SELINUX=disabled .........
Situation Description: if three machines are installed, the firewalls of the three machines need to be turned off separately and set not to start up. If you are going to use cloning, just shut down qianfeng01 machine. The same is true for the following configuration.
4.3 static IP and hostname configuration
--1. Configure static IP(ensure NAT Mode) [root@qianfeng01 ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33 ............ BOOTPROTO=static #Change dhcp to static ............ ONBOOT=yes #Change no to yes IPADDR=192.168.10.101 #Add IPADDR attribute and ip address PREFIX=24 #Add NETMASK=255.255.255.0 or PREFIX=24 GATEWAY=192.168.10.2 #Add GATEWAY DNS1=114.114.114.114 #Add DNS1 and backup DNS DNS2=8.8.8.8 --2. service network restart [root@qianfeng01 ~]# systemctl restart network perhaps [root@qianfeng01 ~]# service network restart --3. Modify host name(If so, skip this step) [root@localhost ~]# hostnamectl set-hostname qianfeng01 perhaps [root@localhost ~]# vi /etc/hostname qianfeng01
Note: after configuring the ip and hostname, you'd better reboot
4.4 configure / etc/hosts file
[root@qianfeng01 ~]# vi /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.10.101 qianfeng01 #Add the mapping relationship between the static IP of this machine and the host name of this machine 192.168.10.102 qianfeng02 192.168.10.103 qianfeng03
4.5 password free login authentication
-1. use rsa Encryption technology to generate public and private keys. All the way back [root@qianfeng01 ~]# cd ~ [root@qianfeng01 ~]# ssh-keygen -t rsa -2. get into~/.ssh Directory, use ssh-copy-id command [root@qianfeng01 ~]# cd ~/.ssh [root@qianfeng01 .ssh]# ssh-copy-id root@qianfeng01 -3. Verify [hadoop@qianfeng01 .ssh]# ssh qianfeng01 #After you enter yes for the first execution below, you will not be prompted to enter the password [hadoop@qianfeng01 .ssh]# ssh localhost [hadoop@qianfeng01 .ssh]# ssh 0.0.0.0 Note: when the three machines are installed in advance, the public key file needs to be synchronized. If cloning technology is used. Then it is much more convenient to use the same set of key pairs.
4.6 time synchronization
Can refer to Linux Time synchronization in the document or build a LAN time server.
4.7 install Jdk and Hadoop and configure relevant environment variables
-1. Upload and unzip two packages [root@qianfeng01 ~]# tar -zxvf jdk-8u221-linux-x64.tar.gz -C /usr/local/ [root@qianfeng01 ~]# tar -zxvf hadoop-2.7.6.tar.gz -C /usr/local/ -2. get into local In, rename the two software [root@qianfeng01 ~]# cd /usr/local/ [root@qianfeng01 local]# mv 1.8.0_221/ jdk [root@qianfeng01 local]# mv hadoop-2.7.6/ hadoop -3. Configure environment variables [hadoop@qianfeng01 local]# vi /etc/profile .....ellipsis........... #java environment export JAVA_HOME=/usr/local/jdk export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH #hadoop environment export HADOOP_HOME=/usr/local/hadoop export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
5 Hadoop configuration file
5.1 extract four default profiles
Step 1: unzip the Hadoop installation package to a directory on the pc side, and then create a default directory in hadoop-2.7.6 directory to store the default configuration file.
Step 2: enter the doc subdirectory in the share directory of hadoop and search default.xml. copy the following four default XML files to the default directory for later viewing

5.2 $HADOOP_ User defined configuration files in the home / etc / Hadoop / directory
- core-site.xml - hdfs-site.xml - mapred-site.xml copy mapred-site.xml.template Come from - yarn-site.xml
5.3 priority of attributes
Properties in code>xxx-site.xml>xxx-default.xml
6 fully distributed file configuration (key)
Description before configuration: 1.Let's go first qianfeng01 Configuration on machine node hadoop Related properties of. 2.stay<value></value>Values between cannot have spaces
6.1 configuring the core-site.xml file
[root@qianfeng01 ~]# cd $HADOOP_HOME/etc/hadoop/
[root@qianfeng01 hadoop]# vi core-site.xml
<configuration>
<!-- hdfs Address name: schame,ip,port-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://qianfeng01:8020</value>
</property>
<!-- hdfs The base path of the, which is dependent on other attributes -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
Reference: core-default.xml
6.2 reconfigure hdfs-site.xml file
[root@qianfeng01 hadoop]# vi hdfs-site.xml
<configuration>
<!-- namenode Metadata file managed by daemon fsimage Storage location-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<!-- determine DFS Where should a data node store its blocks on the local file system-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<!-- Number of copies of block-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- Block size(128M),The following units are bytes-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- secondarynamenode Daemon http Address: host name and port number. Reference daemon layout-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>qianfeng02:50090</value>
</property>
<!-- namenode Daemon http Address: host name and port number. Reference daemon layout-->
<property>
<name>dfs.namenode.http-address</name>
<value>qianfeng01:50070</value>
</property>
</configuration>
Reference: hdfs-default.xml
6.3 then configure the mapred-site.xml file
If you only need to set up HDFS, you only need to configure the core-site.xml and hdfs-site.xml files, but the MapReduce we will learn in two days needs YARN resource manager. Therefore, here, we configure the relevant files in advance.
[root@qianfeng01 hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@qianfeng01 hadoop]# vi mapred-site.xml
<configuration>
<!-- appoint mapreduce use yarn Resource Manager-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- Configure the address of the job history server-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>qianfeng01:10020</value>
</property>
<!-- Configure the of the job history server http address-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>qianfeng01:19888</value>
</property>
</configuration>
Reference: mapred-default.xml
6.4 configure the yarn-site.xml file
[root@qianfeng01 hadoop]# vi yarn-site.xml
<configuration>
<!-- appoint yarn of shuffle technology-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- appoint resourcemanager Host name of-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>qianfeng01</value>
</property>
<!--The following options-->
<!--appoint shuffle Corresponding class -->
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!--to configure resourcemanager Internal mailing address of-->
<property>
<name>yarn.resourcemanager.address</name>
<value>qianfeng01:8032</value>
</property>
<!--to configure resourcemanager of scheduler Internal mailing address of-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>qianfeng01:8030</value>
</property>
<!--to configure resoucemanager Internal communication address of resource scheduling-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>qianfeng01:8031</value>
</property>
<!--to configure resourcemanager The internal mailing address of the administrator-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>qianfeng01:8033</value>
</property>
<!--to configure resourcemanager of web ui Monitoring page for-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>qianfeng01:8088</value>
</property>
</configuration>
Reference: yarn-default.xml
6.5 configuring hadoop-env.sh script file
[root@qianfeng01 hadoop]# vi hadoop-env.sh ......... # The java implementation to use. export JAVA_HOME=/usr/local/jdk .........
6.6 configuring slave files
This file is used to specify the host name of the machine node where the datanode daemon is located
[root@qianfeng01 hadoop]# vi slaves qianfeng01 qianfeng02 qianfeng03
6.7 configuration yarn-env.sh file,
This file can not be configured, but it is better to modify the jdk environment of yarn
[root@qianfeng01 hadoop]# vi yarn-env.sh ......... # some Java parameters export JAVA_HOME=/usr/local/jdk if [ "$JAVA_HOME" != "" ]; then #echo "run java in $JAVA_HOME" JAVA_HOME=$JAVA_HOME fi .........
7 configuration description of the other two machines
After configuring the hadoop related files on qianfeng01 machine, we have the following two ways to configure hadoop on other machines
Method 1: "scp" for synchronization
Tip: this method is applicable to scenes where multiple virtual machines have been built in advance. --1. synchronization hadoop reach slave On node [root@qianfeng01 ~]# cd /usr/local [root@qianfeng01 local]# scp -r ./hadoop qianfeng02:/usr/local/ [root@qianfeng01 local]# scp -r ./hadoop qianfeng03:/usr/local/ --2. synchronization/etc/profile reach slave On node [root@qianfeng01 local]# scp /etc/profile qianfeng02:/etc/ [root@qianfeng01 local]# scp /etc/profile qianfeng03:/etc/ --3. If slave On node jdk It's not installed. Don't forget to sync jdk. --4. Check if the synchronization is complete/etc/hosts file
**Method 2: * * clone qianfeng01 virtual machine
Tip: this method is applicable to those that have not been installed slave Virtual machine scenario. By cloning qianfeng01 Node to clone one qianfeng02 and qianfeng03 Machine node, this method does not need to repeatedly install the environment and configuration files, which is very efficient and saves most of the time(The secret key pairs without secret authentication are the same set). --1. Open a newly cloned virtual machine and modify the host name [root@qianfeng01 ~]# hostnamectl set-hostname qianfeng02 --2. modify ip address [root@qianfeng01 ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33 .........ellipsis......... IPADDR=192.168.10.102 <==Change to qianfeng02 Corresponding ip address .........ellipsis........ --3. service network restart [root@qianfeng01 ~]# systemctl restart network --4. Repeat the above 1 for other newly cloned virtual machines~3 step --5. Verification of secret free login from qianfeng01 On the machine, connect every other node to verify whether the password free is working well, and remove the first query step --6. Suggestion: after restarting the network service for each machine, it is best to reboot once.
8 format NameNode
**1) * * run the command on the qianfeng01 machine
[root@qianfeng01 ~]# hdfs namenode -format
**2) * * interpretation of formatting related information
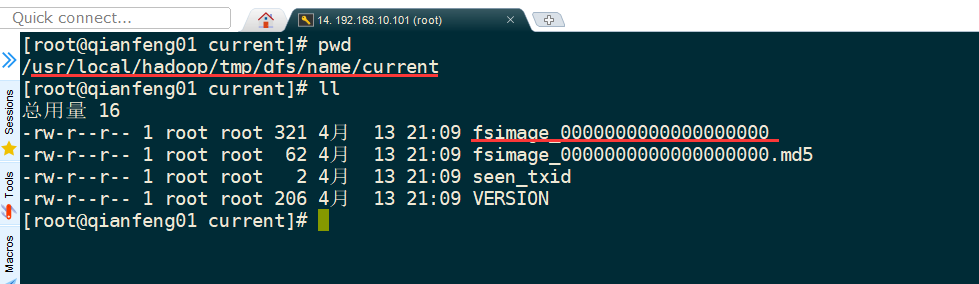
--1. Generate a cluster unique identifier:clusterid --2. Generate a block pool unique identifier:blockPoolId --3. generate namenode Process management content(fsimage)Storage path for: Default profile properties hadoop.tmp.dir Generated under the specified path dfs/name catalogue --4. Generate image file fsimage,Records the metadata of the root path of the distributed file system --5. You can check other information, such as the number of copies of blocks and the number of clusters fsOwner Wait.
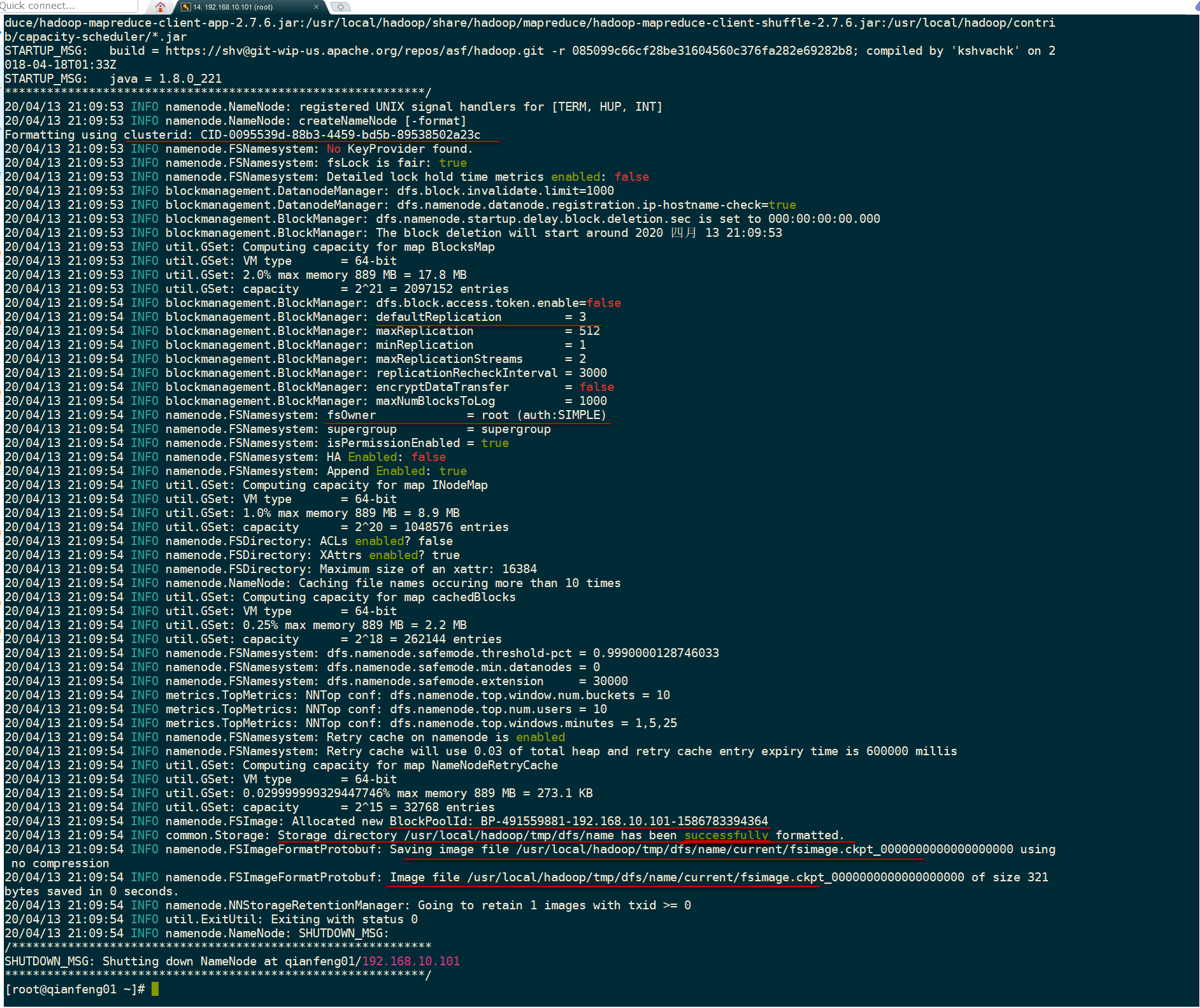
**3) * * view contents in the directory
9 start the cluster
9.1 introduction to startup script and shutdown script
1. Startup script -- start-dfs.sh :Used to start hdfs Cluster script -- start-yarn.sh :Used to start yarn Daemon -- start-all.sh :Used to start hdfs and yarn 2. Close script -- stop-dfs.sh :For closing hdfs Cluster script -- stop-yarn.sh :For closing yarn Daemon -- stop-all.sh :For closing hdfs and yarn 3. Single daemon script -- hadoop-daemons.sh :Used to start or shut down separately hdfs Script for one of the daemons -- hadoop-daemon.sh :Used to start or shut down separately hdfs Script for one of the daemons reg: hadoop-daemon.sh [start|stop] [namenode|datanode|secondarynamenode] -- yarn-daemons.sh :Used to start or shut down separately hdfs Script for one of the daemons -- yarn-daemon.sh :Used to start or shut down separately hdfs Script for one of the daemons reg: yarn-daemon.sh [start|stop] [resourcemanager|nodemanager]
9.2 start hdfs
**1) * * use start-dfs.sh to start hdfs. Reference picture

**2) * * startup process analysis:
- Start the daemon of the distributed file system on each machine node in the cluster
One namenode and resourcemanager as well as secondarynamenode
Multiple datanode and nodemanager
- stay namenode Generated under the directory of daemon management content edit log file
- In each datanode Generated under the node ${hadoop.tmp.dir}/dfs/data catalogue,Refer to the following figure:
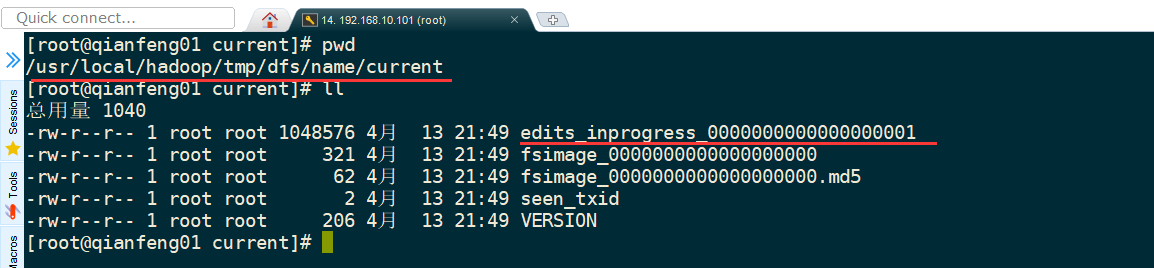
Attention, attention, attention
If the daemons on which machine are not enabled, check the log corresponding to the daemons on which machine log file,Note that the log suffix of the prompt when the startup script runs is*.out,And what we're looking at is*.log File. Location of this file: ${HADOOP_HOME}/logs/in
**3) * * jps view process
--1. stay qianfeng01 Run on jps Instructions, there will be the following processes namenode datanode --2. stay qianfeng02 Run on jps Instructions, there will be the following processes secondarynamenode datanode --3. stay qianfeng03 Run on jps Instructions, there will be the following processes datanode
9.3 starting yarn
**1) * * use the start-yarn.sh script, refer to the picture

**2) * * jps view
--1. stay qianfeng01 Run on jps Instructions, the following processes will be added resoucemanager nodemanager --2. stay qianfeng02 Run on jps Instructions, the following processes will be added nodemanager --3. stay qianfeng03 Run on jps Instructions, the following processes will be added nodemanager
9.4 webui view
1. http://192.168.10.101:50070 2. http://192.168.10.101:8088
10 program case demonstration: wordcount
1) Prepare two files for statistics and store them in ~ / data /
--1. establish data catalogue [root@qianfeng01 hadoop]# mkdir ~/data --2. Upload the following two files to data Directory - poetry1.txt - poetry2.txt
2) Create storage directory on hdfs
[root@qianfeng01 hadoop]# hdfs dfs -mkdir /input
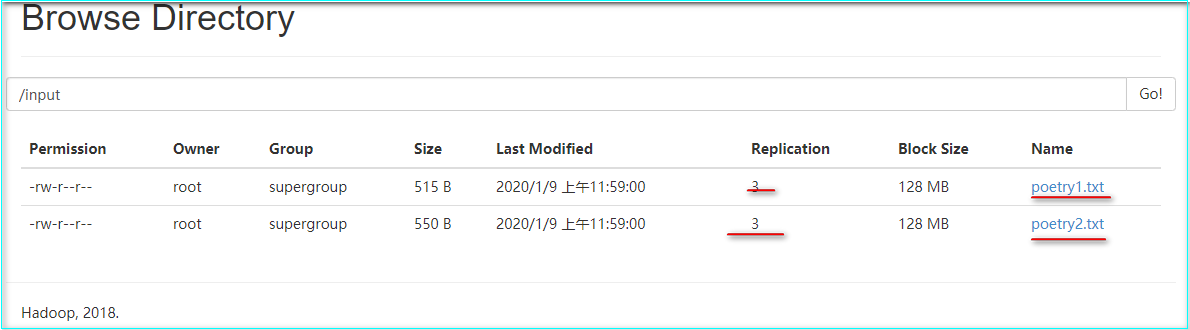
3) Upload the from the local file system to hdfs and check it on the web
[root@qianfeng01 hadoop]$ hdfs dfs -put ~/data/poetry* /input/
4) Run the built-in word statistics program wordcount
[root@qianfeng01 hadoop]# cd $HADOOP_HOME [root@qianfeng01 hadoop]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /input /output
5) View webui
6) View part-r-00000 file
[root@qianfeng01 hadoop]# hdfs dfs -cat /output/part-r-00000
11 interpretation of startup script (optional)
1. start-all.sh 2. start-dfs.sh 3. hadoop-daemon.sh Refer to my blog: https://blog.csdn.net/Michael__One/article/details/86141142
12. The cluster daemon cannot be started
1. When formatting the cluster, the error reason is reported
- Improper use by current user
- /etc/hosts The mapping relationship in is filled in incorrectly
- Secret free login authentication exception
- jdk Environment variable configuration error
- The firewall is not turned off
- Error in configuration file
2. namenode Reason why the process did not start:
- Improper use by current user
- Forget to delete when reformatting ${hadoop.tmp.dir}Contents under directory
- Network shock, resulting in edit Log file transactions ID Serial number discontinuity
- Error in configuration file
3. datanode Causes of problems
- /etc/hosts The mapping relationship in is filled in incorrectly
- Secret free login exception
- Forget to delete when reformatting ${hadoop.tmp.dir}The contents of the directory cause datanode The unique identifier of is not in the new cluster.
4. Solution to the above problem: reformat
If you want to reformat, first close the daemon of the cluster, and then delete the daemon on each machine ${hadoop.tmp.dir}Specify all the contents under the path, and then format: it's best to also logs The contents in the directory are also cleared, because the log contents are already the log information of the previous abandoned cluster, and it is useless to keep them.
## 12. The cluster daemon cannot be started
```properties
1. When formatting the cluster, the error reason is reported
- Improper use by current user
- /etc/hosts The mapping relationship in is filled in incorrectly
- Secret free login authentication exception
- jdk Environment variable configuration error
- The firewall is not turned off
- Error in configuration file
2. namenode Reason why the process did not start:
- Improper use by current user
- Forget to delete when reformatting ${hadoop.tmp.dir}Contents under directory
- Network shock, resulting in edit Log file transactions ID Serial number discontinuity
- Error in configuration file
3. datanode Causes of problems
- /etc/hosts The mapping relationship in is filled in incorrectly
- Secret free login exception
- Forget to delete when reformatting ${hadoop.tmp.dir}The contents of the directory cause datanode The unique identifier of is not in the new cluster.
4. Solution to the above problem: reformat
If you want to reformat, first close the daemon of the cluster, and then delete the daemon on each machine ${hadoop.tmp.dir}Specify all the contents under the path, and then format: it's best to also logs The contents in the directory are also cleared, because the log contents are already the log information of the previous abandoned cluster, and it is useless to keep them.