The creation of index file, an important part of the full text, can be realized through Lucene.
Create index basic process
- Select a folder as the directory for index output.
- Create index output stream object
- Read the data source, encapsulate the document object, and define the attributes of the document object according to the domain attributes.
- Through the output stream object, the result of inverted index calculation is output to the directory under the specified directory to complete the index creation.
Code demonstration
The notes are written in more detail, but there is no more explanation:
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
import java.io.IOException;
import java.nio.file.Path;
import java.nio.file.Paths;
public class CreateIndexTest {
@Test
public void createIndex() throws IOException {
//Specify a file output directory
Path path= Paths.get("d:/test/index");
//Give the path to FSDirectory to complete the path management. When the path does not exist, FSDirectory will help you create it
FSDirectory fsDirectory=FSDirectory.open(path);
//Create index output stream configuration object
IndexWriterConfig indexWriterConfig=new IndexWriterConfig(new SmartChineseAnalyzer());
//Configure the mode of the index file OpenMode.CREATE : New OpenMode.APPEND : append OpenMode.CREATE_OR_APPEND: new or append
indexWriterConfig.setOpenMode(IndexWriterConfig.OpenMode.CREATE);
//With the output flow configuration object, you can create an index output flow. You need two parameters, path management object and index configuration object
IndexWriter indexWriter=new IndexWriter(fsDirectory,indexWriterConfig);
//To create document objects, we use the "full text retrieval technology" introduced before_ The example in inverted index algorithm completes the creation of document objects:
//Article address: https://blog.csdn.net/zhaoliwen/article/details/106736495
/*id:did1
title:Global and new coronavirus coexist for a long time, what should China do
origin:National Express
content:The long-term existence of new coronavirus will bring many changes to human society. How should China prepare for this*/
/* id:did2
title:China and Brazil launch cooperation on new coronavirus vaccine
origin:Xinhua news agency client
content:Sao Paulo will work with Chinese laboratories to produce and test the new coronavirus vaccine.*/
Document did1=new Document();
did1.add(new TextField("title","Global and new coronavirus coexist for a long time, what should China do",Field.Store.YES));
did1.add(new StringField("origin","National Express",Field.Store.YES));
did1.add(new TextField("content","The long-term existence of new coronavirus will bring many changes to human society. How should China prepare for this",Field.Store.YES));
Document did2=new Document();
did2.add(new TextField("title","China and Brazil launch cooperation on new coronavirus vaccine",Field.Store.YES));
did2.add(new StringField("origin","Xinhua news agency client",Field.Store.YES));
did2.add(new TextField("content","Sao Paulo will cooperate with Chinese laboratories to produce and test the new coronavirus vaccine",Field.Store.YES));
//Give the document object to the index output stream object
indexWriter.addDocument(did1);
indexWriter.addDocument(did2);
//Complete the final creation
indexWriter.commit();
}
}
In the index output path, we can see that Lucene has finished creating the index. As described in the above code, FSDirectory automatically creates a directory that does not exist: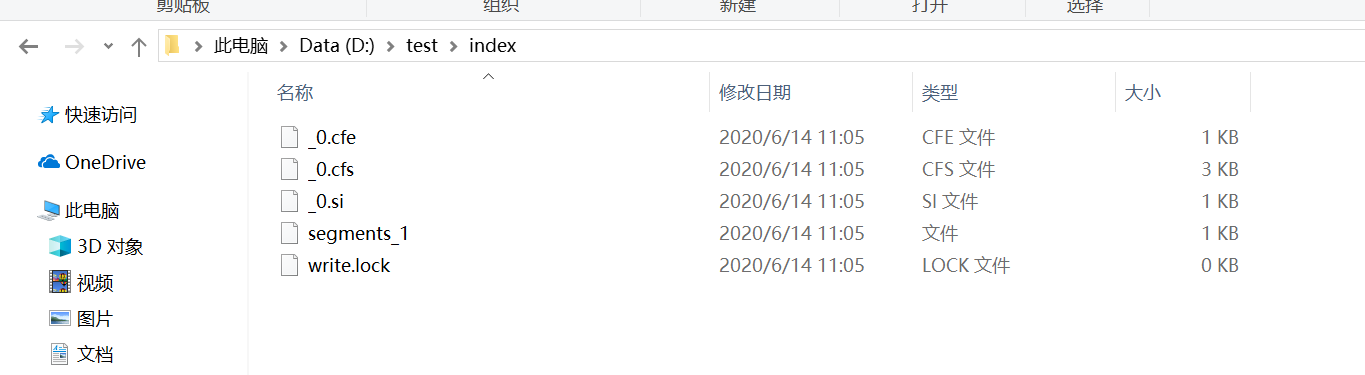
View index file
Because index files are not text files, but binary files recognized and managed by Lucene. Just like the MP4 file needs to be played by the player, the binary file here can also be read by the tool software: luke
Software download address: https://download.csdn.net/download/zhaoliwen/12521746
Luke is a small tool developed in java language. It does not need to be installed. After decompression, click it directly luke.bat To run. It can be used to view binary index files, documents and other contents created by Lucene.
Select the output path of the index here: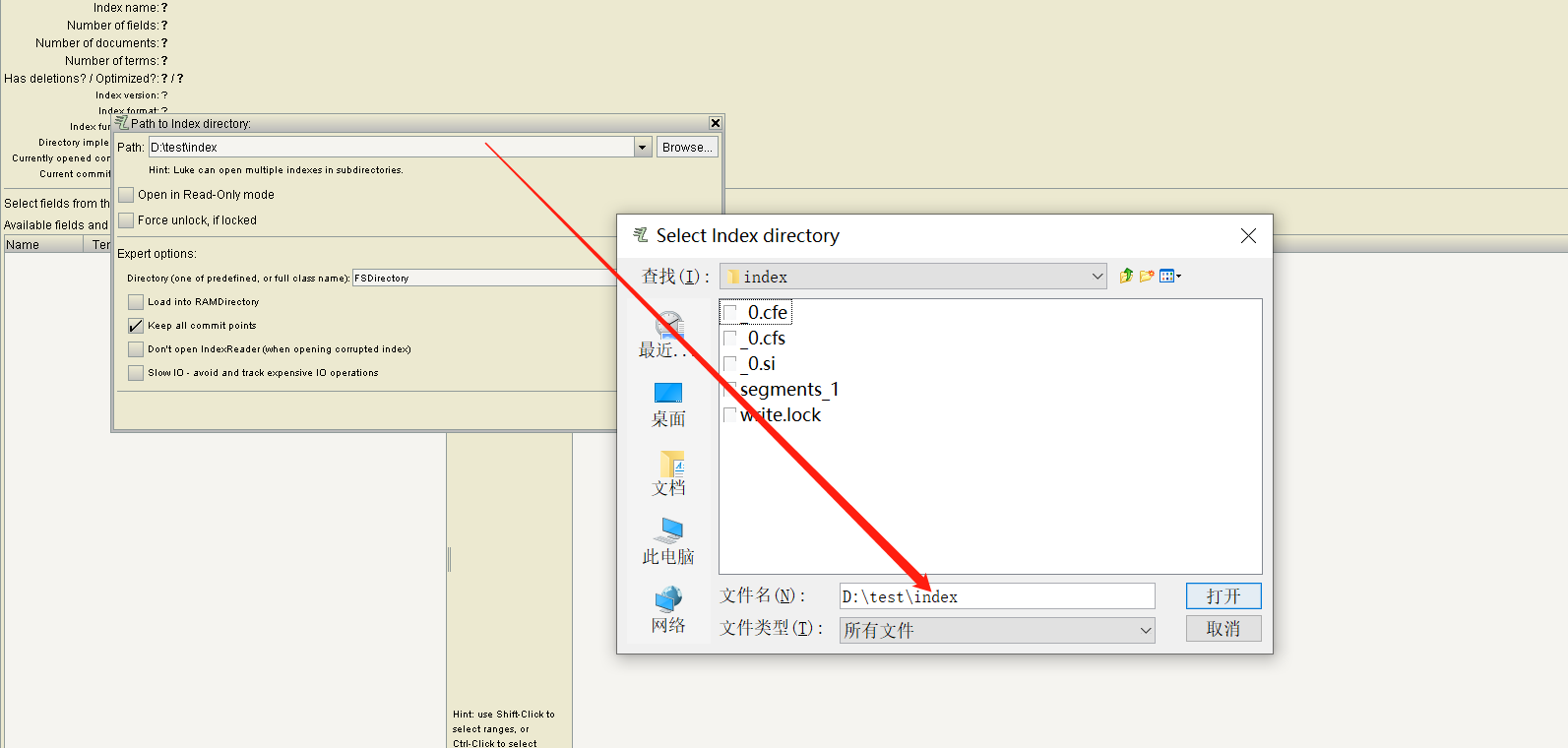
Here is the index file created by lucene through the word items separated by the smartchinese analyzer word breaker: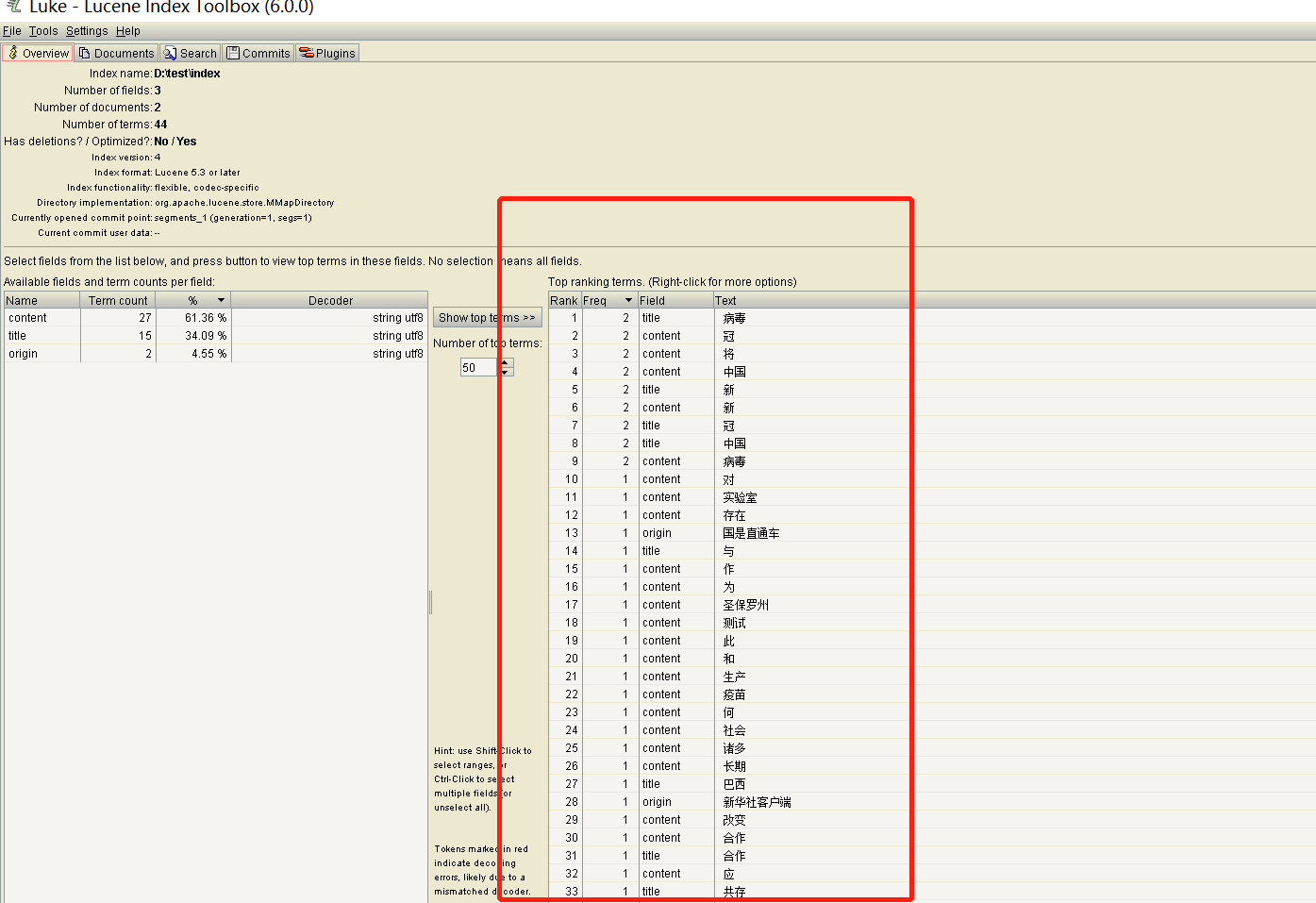
SmartChineseAnalyzer word breaker is not good for Chinese processing. If you are interested in it, you can download the jar package and replace it in your code.