On infinite class
The first option: Recursion algorithm is also the most frequently used, and most open source programs do the same, but generally only use four levels of classification. The database structure design of this algorithm is the simplest. A field ID and a field FID (parent id) in the category table. In this way, we can judge the upper level content according to WHERE id = fid, and use recursion to the top level. Analysis: the infinite level designed by this kind of database can be said to be very hard to read, so most of the programs can be classified into 3-4 levels at most, which is enough to meet the needs, so that all the data can be read out at one time, and then the array or object can be recursive. The load itself is not too big. But if it is classified to a higher level, it is not desirable. So it seems that this kind of classification has the advantage that it is easy to add, delete and modify However, in terms of the secondary classification, this algorithm should be the first.
The second option: Set the fid field type to varchar, and put the parent id in this field, separated by symbols, such as: 1,3,6 In this way, it is easier to get the ID of each superior classification, and when querying the information under the classification, You can use: SELECT * FROM category WHERE pid LIKE "1,3%".
Analysis: compared with recursive algorithm, it has a great advantage in reading data. However, if you want to find all the parent or child classifications of the classification, the efficiency of query is not very high. At least you need to query twice. In a sense, I don't think it is in line with the design of database paradigm. If increasing to infinite level, it is necessary to consider whether the field meets the requirements, and it will be very troublesome to modify the classification and transfer the classification. For the time being, solutions similar to the second solution are used in our own projects. There is such a problem in my project with this scheme. If all data records reach tens of thousands or even more than 10W, the classification and orderly classification will be realized at one time, with low efficiency. It is very likely that the low efficiency of data code processing in the project. Now it's improving.
The third option: Infinite level classification -- improved preorder traversal tree So what characteristics should the ideal tree structure have? Data storage has small redundancy and strong intuitiveness; it is convenient to return the whole tree structure data; it can easily return a certain subtree (convenient for layered loading); it can quickly obtain the ancestral spectrum path of a node; it has high efficiency in inserting, deleting and moving nodes, etc. With these requirements, I searched a lot of data, found an ideal tree structure data storage and operation algorithm, and improved The Nested Set Model. Principle: Let's lay the trees out horizontally first. Start at the root node ("Food") and write 1 on his left. Then write 2 to the left of "Fruit" in the order of the tree (from top to bottom). In this way, you walk along the border of the tree (this is called "traversal"), and then write numbers on the left and right sides of each node at the same time. Finally, we go back to the root node "Food" and write 18 on the right. The following is the tree marked with numbers, and the sequence of traversal is marked with arrows.
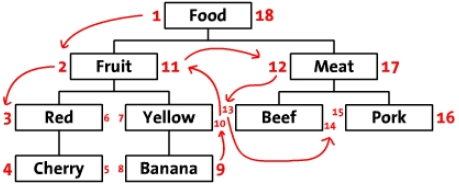
We call these numbers left and right (for example, the left value of "Food" is 1 and the right value is 18). As you can see, these numbers are on time for the relationship between each node. Because Red has two values, 3 and 6, it is a follow-up to the Food node that has a value of 1-18. Similarly, we can infer that all nodes with left value greater than 2 and right value less than 11 are the follow-up of "Fruit" nodes with 2-11. In this way, the structure of the tree is stored by left and right values. This method of calculating the nodes of the whole tree several times is called "improved preorder traversal tree" algorithm.
Table structure design:
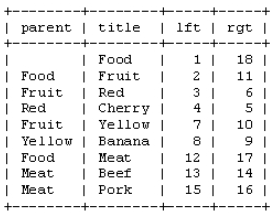
So how can we query all the classifications through an SQL statement, and if it is a subclass, it is required to type a few spaces in front to show that it is a subclass. It's easy to find out all the classifications: select * from category where LFT > 1 and LFT < 18 order by LFT, all the classifications will come out, but whose subclass is not clear, so what should we do? If we look at the figure carefully, we can see that if the right value of the first entry is larger than that of the second entry, then For example, if the right value of food is 18 and the right value of fruit is 11, then food is the parent of fruit, but also considering the multi-level directory. So we use an array to store the right value of the last record, and then compare it with the right value of this record. If the former is smaller than the latter, it means that it is not a parent-child relationship, so we use array_pop up the array, otherwise keep it, and then print the space according to the size of the array.
The above content is quoted from: https://www.cnblogs.com/badboys/p/9945296.html
For more information about the third design, please click to see the original, because it is too complex (too heavy) and is not used frequently.
Leading out pain points
Infinite level classification (parent-child) is a common table design. Each design method not only highlights the advantages, but also brings defects, such as:
- The first scheme: only parent in table design_ ID field, easy to write data, trouble: query trouble, many projects using ORM are forced to use SQL to solve the scenario;
- The second scheme: the redundant sub level id in the table design is easy to query, and the trouble is: it needs to be recalculated when adding / updating / deleting;
- The third scheme is to store left and right value codes in table design;
The design of the first scheme is the simplest. On this basis, we use FreeSql to implement totreelist (memory processing tree type) and astreecate (recursive down / up query), so as to meet the daily use of the public.
About FreeSql
FreeSql is a powerful object relational mapping technology (O/RM). It supports. NETCore 2.1 + or. NETFramework 4.0 + or Xamarin. It is hosted in github with MIT open-source protocol, with 4528 unit tests, 151K nuget downloads, and MySql/SqlServer/PostgreSQL/Oracle/Sqlite / Dayun / Renmin Jincang / Shenzhou general / Access;
Source address: https://github.com/dotnetcore/FreeSql

The author said: each function represents his hair!
Step 1: define navigation properties
Among the FreeSql navigation properties, there is a setting method for parent-child relationship. ToTreeList/AsTreeCte depends on this setting, as follows:
public class Area { [Column(IsPrimary = true)] public string Code { get; set; } public string Name { get; set; } public virtual string ParentCode { get; set; } [Navigate(nameof(ParentCode)), JsonIgnore] //JsonIgnore is json.net Characteristics of public Area Parent { get; set; } [Navigate(nameof(ParentCode))] public List<Area> Childs { get; set; } }
About navigation properties
Define the Parent property. In the expression, you can:
fsql.Select<Area>() .Where(a => a.Parent.Parent.Parent.Name == "China") .First();
To define the children attribute, in an expression, you can (subquery):
fsql.Select<Area>() .Where(a => a.Childs.AsSelect().Any(c => c.Name == "Beijing")) .First();
To define the children property, you can also use the [cascade storage],[greedy loading] And so on.
Add test data
fsql.Delete<Area>().Where("1=1").ExecuteAffrows(); var repo = fsql.GetRepository<Area>(); repo.DbContextOptions.EnableAddOrUpdateNavigateList = true; repo.DbContextOptions.NoneParameter = true; repo.Insert(new Area { Code = "100000", Name = "China", Childs = new List<Area>(new[] { new Area { Code = "110000", Name = "Beijing", Childs = new List<Area>(new[] { new Area{ Code="110100", Name = "Beijing" }, new Area{ Code="110101", Name = "Dongcheng District" }, }) } }) });
Step 2: use ToTreeList to return tree data
After the parent-child attribute is configured, you can use it as follows:
var t1 = fsql.Select<Area>().ToTreeList(); Assert.Single(t1); Assert.Equal("100000", t1[0].Code); Assert.Single(t1[0].Childs); Assert.Equal("110000", t1[0].Childs[0].Code); Assert.Equal(2, t1[0].Childs[0].Childs.Count); Assert.Equal("110100", t1[0].Childs[0].Childs[0].Code); Assert.Equal("110101", t1[0].Childs[0].Childs[1].Code);
The query data is originally flat. The ToTreeList method processes the returned flat data in memory as a tree List.
[ { "ParentCode": null, "Childs": [ { "ParentCode": "100000", "Childs": [ { "ParentCode": "110000", "Childs": [], "Code": "110100", "Name": "Beijing" }, { "ParentCode": "110000", "Childs": [], "Code": "110101", "Name": "Dongcheng District" } ], "Code": "110000", "Name": "Beijing" } ], "Code": "100000", "Name": "China" } ]
Step 3: use AsTreeCte to query recursively
If we do not design infinite level classification table with data redundancy, recursive query is indispensable. AsTreeCte is exactly the encapsulation of recursive query. Method Parameter Description:
| parameter | describe |
|---|---|
| (optional) pathSelector | Path content selection, you can set query return: China - > Beijing - > Dongcheng District |
| (optional) up | False (default): recursive query from parent to child, true: recursive query from child to parent |
| (optional) pathSeparator | Set the connector of pathSelector, default: - > |
| (optional) level | Set recursion level |
Database passing the test: MySQL 8.0, SqlServer, PostgreSQL, Oracle, Sqlite, Dayun, Renmin Jincang
Pose 1: astreecate() + totreelist
var t2 = fsql.Select<Area>() .Where(a => a.Name == "China") .AsTreeCte() //Query all records under China .OrderBy(a => a.Code) .ToTreeList(); //You can use ToList if you don't have to (see pose 2) Assert.Single(t2); Assert.Equal("100000", t2[0].Code); Assert.Single(t2[0].Childs); Assert.Equal("110000", t2[0].Childs[0].Code); Assert.Equal(2, t2[0].Childs[0].Childs.Count); Assert.Equal("110100", t2[0].Childs[0].Childs[0].Code); Assert.Equal("110101", t2[0].Childs[0].Childs[1].Code); // WITH "as_tree_cte" // as // ( // SELECT 0 as cte_level, a."Code", a."Name", a."ParentCode" // FROM "Area" a // WHERE (a."Name" = 'China') // union all // SELECT wct1.cte_level + 1 as cte_level, wct2."Code", wct2."Name", wct2."ParentCode" // FROM "as_tree_cte" wct1 // INNER JOIN "Area" wct2 ON wct2."ParentCode" = wct1."Code" // ) // SELECT a."Code", a."Name", a."ParentCode" // FROM "as_tree_cte" a // ORDER BY a."Code"
Pose 2: AsTreeCte() + ToList
var t3 = fsql.Select<Area>() .Where(a => a.Name == "China") .AsTreeCte() .OrderBy(a => a.Code) .ToList(); Assert.Equal(4, t3.Count); Assert.Equal("100000", t3[0].Code); Assert.Equal("110000", t3[1].Code); Assert.Equal("110100", t3[2].Code); Assert.Equal("110101", t3[3].Code); //Execute the same SQL as pose I
Pose 3: astreecate (pathselector) + tolist
How do I return to the hidden field after setting the pathSelector parameter?
var t4 = fsql.Select<Area>() .Where(a => a.Name == "China") .AsTreeCte(a => a.Name + "[" + a.Code + "]") .OrderBy(a => a.Code) .ToList(a => new { item = a, level = Convert.ToInt32("a.cte_level"), path = "a.cte_path" }); Assert.Equal(4, t4.Count); Assert.Equal("100000", t4[0].item.Code); Assert.Equal("110000", t4[1].item.Code); Assert.Equal("110100", t4[2].item.Code); Assert.Equal("110101", t4[3].item.Code); Assert.Equal("China[100000]", t4[0].path); Assert.Equal("China[100000] -> Beijing[110000]", t4[1].path); Assert.Equal("China[100000] -> Beijing[110000] -> Beijing[110100]", t4[2].path); Assert.Equal("China[100000] -> Beijing[110000] -> Dongcheng District[110101]", t4[3].path); // WITH "as_tree_cte" // as // ( // SELECT 0 as cte_level, a."Name" || '[' || a."Code" || ']' as cte_path, a."Code", a."Name", a."ParentCode" // FROM "Area" a // WHERE (a."Name" = 'China') // union all // SELECT wct1.cte_level + 1 as cte_level, wct1.cte_path || ' -> ' || wct2."Name" || '[' || wct2."Code" || ']' as cte_path, wct2."Code", wct2."Name", wct2."ParentCode" // FROM "as_tree_cte" wct1 // INNER JOIN "Area" wct2 ON wct2."ParentCode" = wct1."Code" // ) // SELECT a."Code" as1, a."Name" as2, a."ParentCode" as5, a.cte_level as6, a.cte_path as7 // FROM "as_tree_cte" a // ORDER BY a."Code"
More poses... Please try according to the code comments
Source address: https://github.com/dotnetcore/FreeSql