2. Use a thread loop to execute, Thread.sleep(100) to control the thread execution to stop 100 ms at a time, prevent the cpu from overloading in the dead loop, generate 10 pieces of data in one second, use log4j to generate the corresponding log to the specified directory, where the log is generated every minute in a format yyy-MM-dd-HH-mm, such as: service.log.2016-10-13-11-32, and finally in the service.log.2016-13-11-32. Linux Start the java program with shell script.
3. Write shell script, and copy the log file generated one minute before the current time from the script generated by log4j to the folder monitored by flume. Pay attention to the fact that copying should add. COMPLETED to the file name in the past, and delete. COMPLETED after the completion of copying.
For example:
#First
cp ./log4j/service.log.2016-10-13-11-37 ./monitor/service.log.2016-10-13-11-37.COMPLETED
#Then
mv ./monitor/service.log.2016-10-13-11-37.COMPLETED ./monitor/service.log.2016-10-13-11-37The main thing is to prevent the source log files from copy ing too much for a long time, when flume throws exceptions, of course, you can also use another solution: direct move source log files to the directory monitored by flume, but this solution is not as good as the above one.
4. Configure the conf file of flume
5. Edit crontab to execute this script every minute to pull the source log file.
Environmental Science:
1. The virtual machine used is: VMware 12
2.centOS6.5
3. Hadoop 2.2.0 single node (main) test Use, so use a single node directly)
4.Flume 1.6.0 (flume-ng-1.5.0-cdh5.4.5, which was first used, and a method in the result configuration could not find throwing exceptions in this version of flume package, so we changed the version to fix it)
The java code is as follows:
Where you need to configure the log4j configuration file and add the dependency jar package of log4j
package com.lijie.test;
import java.util.UUID;
import org.apache.log4j.Logger;
public class DataProduct {
public static void main(String[] args) {
Thread t1 = new Thread(new A());
t1.start();
}
}
class A extends Thread {
private final Logger log = Logger.getLogger(A.class);
public void run() {
//Infinite cycle
while (true) {
//Random generation of a user uuid
UUID userId = UUID.randomUUID();
//Generate a random total user asset
int num = (int) (Math.random() * 10000000) + 100000;
//Generate a random county name
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 3; i++) {
char a = (char) (Math.random() * (90 - 65) + 65);
sb.append(a);
}
String xian = sb.toString();
//Generate a random town name
StringBuilder sb1 = new StringBuilder();
for (int i = 0; i < 3; i++) {
char a = (char) (Math.random() * (122 - 97) + 97);
sb1.append(a);
}
String zhen = sb1.toString();
//Generate log
log.info(userId + "####" + xian + "####" + zhen + "####" + num);
//Stop for 0.1 seconds.
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
log4j configuration file:
log4j.rootCategory=INFO, stdout , R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%t] %C.%M(%L) | %m%n
log4j.appender.R=org.apache.log4j.DailyRollingFileAppender
log4j.appender.R.File=/home/hadoop/log4j/service.log
log4j.appender.R.DatePattern = '.'yyyy-MM-dd-HH-mm
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%d %p [%t] %C.%M(%L) | %m%n
log4j.logger.com.xxx=DEBUG
log4j.logger.controllers=DEBUG
log4j.logger.vo=DEBUG
log4j.logger.notifiers=DEBUG
log4j.logger.com.opensymphony.oscache=WARN
log4j.logger.net.sf.navigator=WARN
log4j.logger.org.apache.commons=WARN
log4j.logger.org.apache.struts=WARN
log4j.logger.org.displaytag=WARN
log4j.logger.org.springframework=WARN
log4j.logger.org.apache.velocity=FATALStart the shell script start.sh of the java program
APP_HOME=/home/hadoop/myjar
APP_CLASSPATH=$APP_HOME/bin
jarList=$(ls $APP_CLASSPATH|grep jar)
echo $jarList
for i in $jarList
do
APP_CLASSPATH="$APP_CLASSPATH/$i":
done
echo $APP_CLASSPATH
export CLASSPATH=$CLASSPATH:$APP_CLASSPATH
echo $CLASSPATH
java -Xms50m -Xmx250m com.lijie.test.DataProduct
echo Linux Test Endshell script mvlog.sh that pulls source logs regularly
#! /bin/bash
DIR=$(cd `dirname $0`; pwd)
mydate=`date +%Y-%m-%d-%H-%M -d '-1 minutes'`
logName="service.log"
monitorDir="/home/hadoop/monitor/"
filePath="${DIR}"/log4j/""
fileName="${logName}"".""${mydate}"
echo "File address:${filePath}"
echo "File name:${fileName}"
if [ -f "${monitorDir}""${fileName}" ]
then
echo "File exists, delete file"
rm -rf "${monitorDir}""${fileName}"
fi
echo "Start copying files"
cp "${filePath}${fileName}" "${monitorDir}${fileName}"".COMPLETED"
echo "Log Replication Completed, Change Name"
mv "${monitorDir}${fileName}"".COMPLETED" "${monitorDir}${fileName}"
echo "Log renaming completed"
exitflume configuration file:
#agent name, source, channel, sink name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#Specific definition of source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/hadoop/monitor
#Specific definition of channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 100
#Specific definition sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.80.123:9000/flume/%Y%m%d
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#Documents are not generated according to the number of entries
a1.sinks.k1.hdfs.rollCount = 0
#Generate a file when the file on HDFS reaches 128M
a1.sinks.k1.hdfs.rollSize = 134217728
#Files on HDFS generate a file in 60 seconds
a1.sinks.k1.hdfs.rollInterval = 60
#Assemble source, channel, sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1Start the command of flume:
../bin/flume-ng agent -n a1 -c conf -f ./flume-conf.properties -Dflume.root.logger=DEBUG,consoleConfiguration of crontab
#First crontab-e edits the following code and saves it
* * * * * sh /home/hadoop/mvlog.sh
#Then start the crontab service
service crond startOnce you're ready, execute the java program
sh ./start.sh
Generate the following log files: 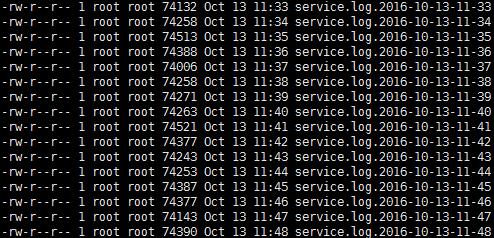
The content of the log: 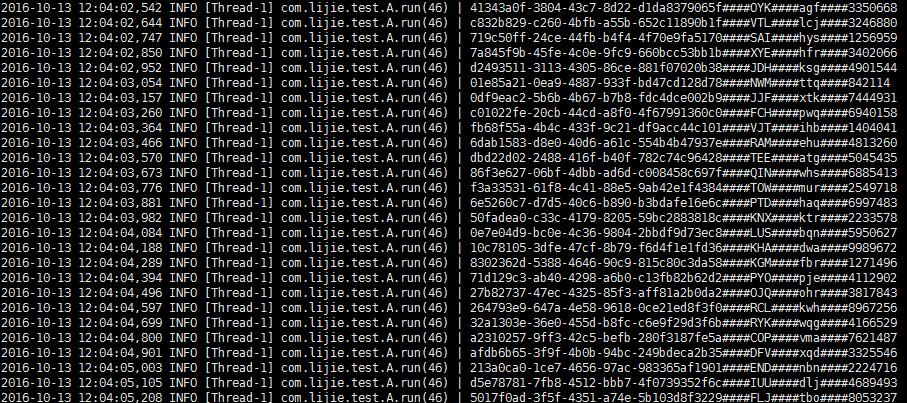
Timing tasks will pull the logs from this directory into the monitor directory, flume will collect, and the phone will add the. COMPLETED suffix to the file name when it is finished: 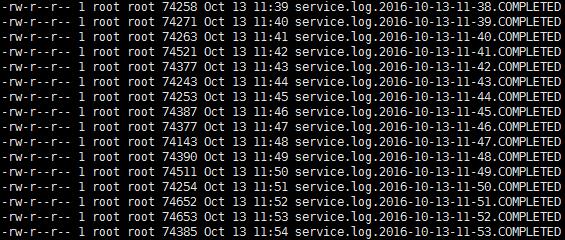
Under the flume of hdfs, a directory formatted for that day's time is generated, and the collected data is put into that directory: 
java code has been generating log files, crontab pulls the log every minute to the directory under flume monitoring, flume will collect the file to hdfs, such a simple flume monitoring spoolDir log to the whole process of HDFS small Demo is implemented.