1. Installation address
1) Flume official website address
http://flume.apache.org/
2) Document view address
http://flume.apache.org/FlumeUserGuide.html
3) Download address
http://archive.apache.org/dist/flume/
2. Installation and deployment
1) Upload apache-flume-1.7.0-bin.tar.gz to the / opt/software directory of linux
2) Unzip apache-flume-1.7.0-bin.tar.gz to the directory / opt/module /
[hadoop@hadoop102 software]$ tar -zxf apache-flume-1.7.0-bin.tar.gz -C /opt/module/
3) Change the name of apache-flume-1.7.0-bin to flume
[hadoop@hadoop102 module]$ mv apache-flume-1.7.0-bin flume
4) Modify the file flume-env.sh.template under flume/conf to flume-env.sh, and configure the file flume-env.sh
[hadoop@hadoop102 conf]$ mv flume-env.sh.template flume-env.sh [hadoop@hadoop102 conf]$ vi flume-env.sh export JAVA_HOME=/opt/module/jdk1.8.0_144
3. Case realization
(1) Official case of monitoring port data
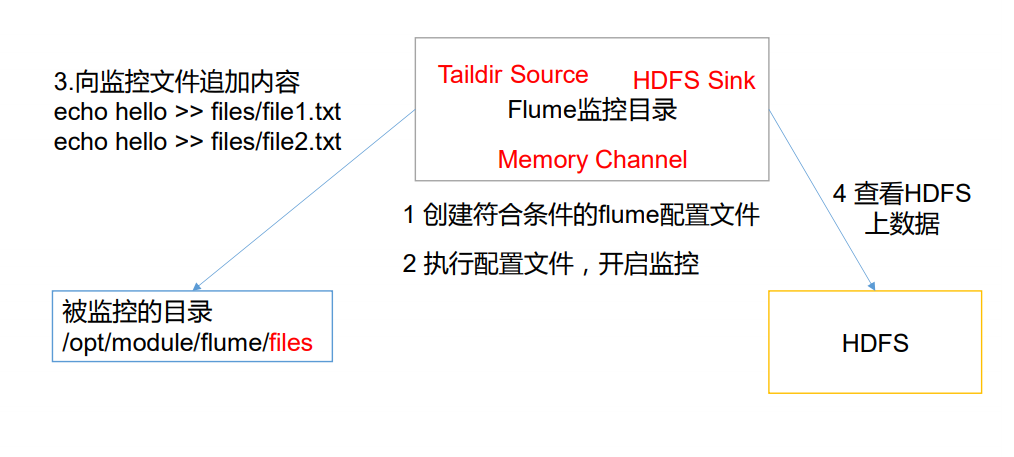
1) Case requirements: first, Flume monitors port 44444 of the machine, then sends a message to port 44444 of the machine through telnet tool, and finally Flume displays the monitored data on the console in real time.
2) Demand analysis: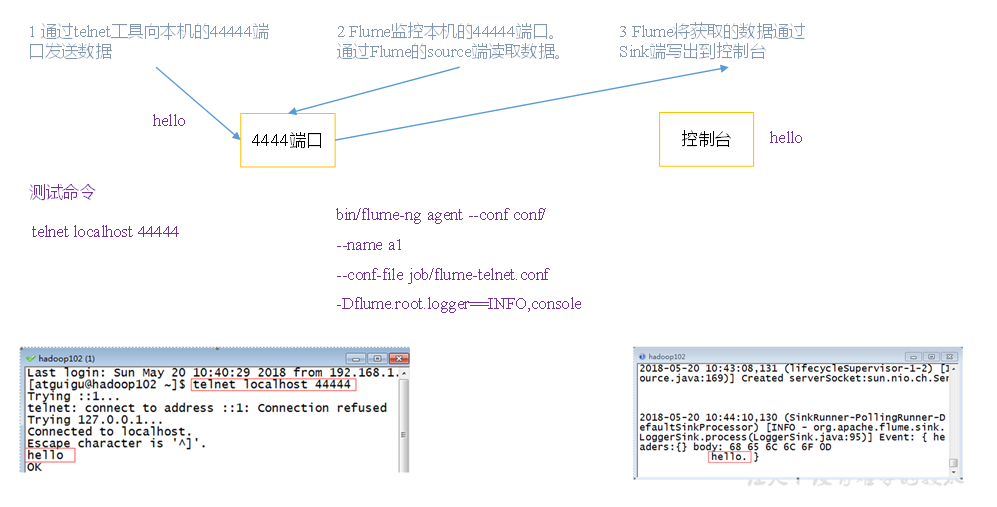
3) Implementation steps:
1. Install the netcat tool
[hadoop@hadoop102 software]$ sudo yum install -y nc
2. Judge whether port 44444 is occupied
[hadoop@hadoop102 flume-telnet]$ sudo netstat -tunlp | grep 44444
3. Create Flume Agent configuration file flume-netcat-logger.conf
Create the job folder in the flume directory and enter the job folder.
[hadoop@hadoop102 flume]$ mkdir job [hadoop@hadoop102 flume]$ cd job/
Create the Flume Agent configuration file flume-netcat-logger.conf under the job folder.
[hadoop@hadoop102 job]$ vim flume-netcat-logger.conf
Add the following to the flume-netcat-logger.conf file.
a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 a1.sinks.k1.type = logger a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1

(2) Read local files to HDFS cases in real time
1) Case requirements: monitor Hive logs in real time and upload them to HDFS
2) Demand analysis: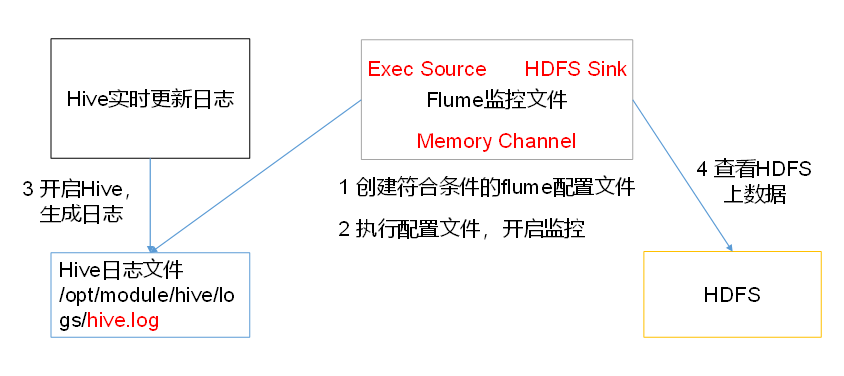
3) Implementation steps:
1. Flume must hold Hadoop related jar package to output data to HDFS
Put commons-configuration-1.6.jar
hadoop-auth-2.7.2.jar,
hadoop-common-2.7.2.jar,
hadoop-hdfs-2.7.2.jar,
commons-io-2.4.jar,
htrace-core-3.1.0-incubating.jar
Copy to the folder / opt/module/flume/lib.
2. Create flume-file-hdfs.conf file
create a file
[hadoop@hadoop102 job]$ touch flume-file-hdfs.conf
Note: to read files in a Linux system, execute the command according to the rules of the Linux command. Because Hive log is in Linux system, the type of read file is selected: exec means execute. Represents executing a Linux command to read a file.
[hadoop@hadoop102 job]$ vim flume-file-hdfs.conf
Add the following
a2.sources = r2 a2.sinks = k2 a2.channels = c2 a2.sources.r2.type = exec a2.sources.r2.command = tail -F /opt/module/hive/logs/hive.log a2.sources.r2.shell = /bin/bash -c a2.sinks.k2.type = hdfs a2.sinks.k2.hdfs.path = hdfs://hadoop102:9000/flume/%Y%m%d/%H #Prefix of uploaded file a2.sinks.k2.hdfs.filePrefix = logs- #Scroll folders by time a2.sinks.k2.hdfs.round = true #How many time units to create a new folder a2.sinks.k2.hdfs.roundValue = 1 #Redefining time units a2.sinks.k2.hdfs.roundUnit = hour #Use local time stamp or not a2.sinks.k2.hdfs.useLocalTimeStamp = true #How many events are accumulated before flush to HDFS once a2.sinks.k2.hdfs.batchSize = 1000 #Set file type to support compression a2.sinks.k2.hdfs.fileType = DataStream #How often to generate a new file a2.sinks.k2.hdfs.rollInterval = 600 #Set the scroll size for each file a2.sinks.k2.hdfs.rollSize = 134217700 #Scrolling of files is independent of the number of events a2.sinks.k2.hdfs.rollCount = 0 #Minimum redundancy a2.sinks.k2.hdfs.minBlockReplicas = 1 a2.channels.c2.type = memory a2.channels.c2.capacity = 1000 a2.channels.c2.transactionCapacity = 100 a2.sources.r2.channels = c2 a2.sinks.k2.channel = c2

3. Perform monitoring configuration
[hadoop@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a2 -f job/flume-file-hdfs.conf
4. Open Hadoop and Hive and operate Hive to generate logs
[hadoop@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh [hadoop@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh [hadoop@hadoop102 hive]$ bin/hive hive (default)>
(3) Real time reading of directory file to HDFS case
1) Case requirement: use Flume to monitor files in the entire directory
2) Demand analysis:
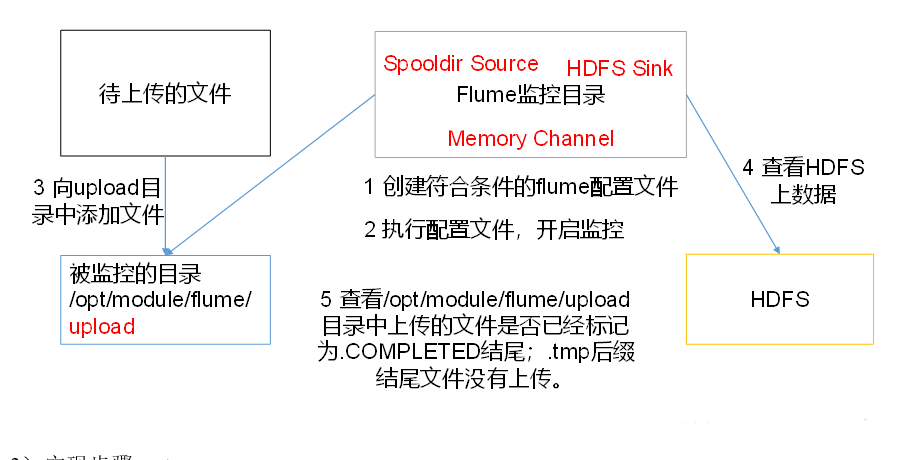
(4) Multiple additional files in real-time monitoring directory
Exec source is suitable for monitoring a real-time appended file, but it cannot guarantee that the data will not be lost; Spooldir
Source can ensure that the data is not lost and the breakpoint can be renewed, but the delay is high and it cannot be monitored in real time; Taildir
Source can not only realize the breakpoint continuous transmission, but also ensure the data not to be lost, and can also conduct real-time monitoring.
1) Case requirements: use Flume to monitor the real-time appending files of the entire directory and upload them to HDFS
2) Demand analysis: