preface
stay Flink of big data (Part I) In this paper, we introduce the characteristics, architecture, two-stage submission and data flow of Flink. This paper introduces the unique operator of Flink and the case of implementing WordCount with Flink
1, split and select operators
The split operator splits a DataStream into two or more datastreams according to some characteristics.
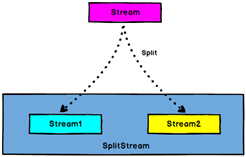
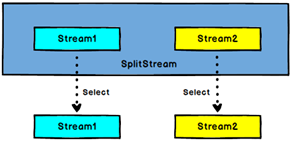
The Select operator obtains one or more datastreams from a SplitStream.
The code is as follows:
//Cut according to the label
val splitStream:SplitStream[Startuplog] = startuplogDstream.split{
startuplog =>
var flag:List[String] = null;
if(startuplog.ch == "appstore"){
flag = List("apple","usa")
}else if(startuplog.ch == "huawei"){
flag = List("android","china")
}else{
flag = List("android","other")
}
flag
}//Divide the data into multiple streams according to the label columns in the data stream
val appleStream:DataStream[Startuplog] = startuplogDstream.select("apple","china")
val otherStream:DataStream[Startuplog] = startuplogDstream.select("other")
//As required, the segmented stream is obtained for subsequent processing
2, Connect and CoMap operators
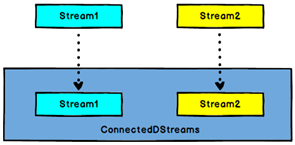
The Connect operator connects two data streams that maintain their types. After the two data streams are connected, they are only placed in the same stream, and their respective data and forms remain unchanged. The two streams are independent of each other.
The COMAP and coflatmap operators act on ConnectedStreams. Their functions are the same as those of map and flatMap, and map and flatMap are processed for each Stream in ConnectedStreams respectively.
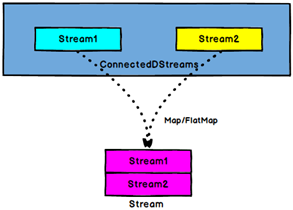
Note: map/flatMap should specify how to combine multiple data streams, that is, specify different functions for different streams, and the return type of the function must be the same and consistent with the final return type. Ordinary map/flatMap can be used directly because it is only for the same data stream;
The code is as follows:
val conStream:ConnectedStreams[Startuplog,Startuplog] = appleStream.connect(otherStream) val allStream:DataStream[String] = conStream.map( //Each stream must specify a function, and the return type of the function must be consistent with the required type (here is String) (startuplog1:Startuplog) => startuplog1.ch (startuplog2:Startuplog) => startuplog2.ch )
3, union operator
Union two or more datastreams to generate a new DataStream containing all DataStream elements. Note: if you union a DataStream with itself, you will see that each element appears twice in the new DataStream.
The code is as follows:
val unionStream:DataStream[Startuplog] = appleStream.union(otherStream)
when merging data streams, union can merge directly without requiring the same data stream types, while connect needs to put the data stream into a large stream for data type conversion before merging. At the same time, * * connect can only merge two data streams at a time, while union can merge multiple data streams.
4, WordCount case
4.1 offline data
The code is as follows:
// Create an env environment variable
val env = ExecutionEnvironment.getExecutionEnvironment
val textDataSet: DataSet[String] = env.readTextFile("D:\\data\\1.txt")
val aggset: AggregateDataSet[(String, Int)] = textDataSet.flatMap(_.split(" ")).map((_,1)).groupBy(0).sum(1)
aggset.print()
4.2 online data
The code is as follows:
// Create an env environment variable
val env = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream: DataStream[String] = env.socketTextStream("hadoop1",7777)
val aggStream: DataStream[(String, Int)] = dataStream.flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1)
aggStream.print()
env.execute() //Online data needs to be added with execution
summary
stay Flink of big data (Part I) In this paper, we introduce the characteristics, architecture, two-stage submission and data flow of Flink. This paper introduces the unique operator of Flink and the case of implementing WordCount with Flink. If there is anything to be added or insufficient, I hope you can point out that we can make progress together.