introduction
Flink provides a special Kafka connector to read or write data to Kafka topic. Flink Kafka Consumer integrates Flink's Checkpoint mechanism to provide exactly once processing semantics. For this reason, Flink does not completely rely on tracking the offset of Kafka consumption group, but tracks and checks the offset internally.
When we use Spark Streaming, Flink and other computing frameworks for real-time data processing, using Kafka as a publish and subscribe message system has become a standard configuration. Spark Streaming and Flink both provide corresponding Kafka consumers, which are very convenient to use. Just set Kafka parameters and add Kafka Source. If you really think that things are so easy and your mother doesn't have to worry about your study anymore, it's really too young too simple things naive. This paper takes Flink's Kafka Source as the discussion object. First, start with the basic use, and then analyze the source code one by one, and remove the mysterious veil of Flink Kafka connector for you.
It is worth noting that this paper assumes that the reader has the relevant knowledge of Kafka, and the relevant details of Kafka are not within the scope of this paper.
Introduction to Flink Kafka Consumer
There are many versions of Flink Kafka Connector. You can select the corresponding package (maven artifact id) and class name according to your Kafka and Flink versions. Flink version 1.10 and Kafka version 2.3.4 are involved in this article. Maven provided by Flink depends on the class name, as shown in the following table:

Demo example
Add Maven dependency
<!--This article uses a general-purpose connector--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_2.11</artifactId> <version>1.10.0</version> </dependency>
Simple code case
public class KafkaConnector {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
// Enable checkpoint with an interval of milliseconds
senv.enableCheckpointing(5000L);
// Select status backend
senv.setStateBackend((StateBackend) new FsStateBackend("file:///E://checkpoint"));
//senv.setStateBackend((StateBackend) new FsStateBackend("hdfs://kms-1:8020/checkpoint"));
Properties props = new Properties();
// kafka broker address
props.put("bootstrap.servers", "kms-2:9092,kms-3:9092,kms-4:9092");
// Only Kafka version 0.8 needs to be configured
props.put("zookeeper.connect", "kms-2:2181,kms-3:2181,kms-4:2181");
// Consumer group
props.put("group.id", "test");
// Automatic offset submission
props.put("enable.auto.commit", true);
// Offset commit interval, in milliseconds
props.put("auto.commit.interval.ms", 5000);
// key serializer for kafka message
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// value serializer for kafka message
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// Specify where kafka's consumers start consuming data
// There are three ways,
// #earliest
// When there are submitted offsets under each partition, consumption starts from the submitted offset;
// When there is no committed offset, consumption starts from scratch
// #latest
// When there are submitted offsets under each partition, consumption starts from the submitted offset;
// When there is no committed offset, the newly generated data under the partition is consumed
// #none
// topic when there are committed offset s in each partition,
// Start consumption after offset;
// As long as there is no committed offset in one partition, an exception is thrown
props.put("auto.offset.reset", "latest");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(
"qfbap_ods.code_city",
new SimpleStringSchema(),
props);
//After setting checkpoint, submit offset, i.e. onCheck mode
// This value defaults to true,
consumer.setCommitOffsetsOnCheckpoints(true);
// The earliest data began to be consumed
// In this mode, the committed offset in Kafka will be ignored and will not be used as the starting position.
//consumer.setStartFromEarliest();
// The last submitted offset of the consumer group. The default is.
// If the offset of the partition cannot be found, the auto.offset.reset setting in the configuration will be used
//consumer.setStartFromGroupOffsets();
// The latest data began to consume
// In this mode, the committed offset in Kafka will be ignored and will not be used as the starting position.
//consumer.setStartFromLatest();
// Specifies the specific offset timestamp, in milliseconds
// For each partition, records whose timestamp is greater than or equal to the specified timestamp will be used as the starting location.
// If the latest record of a partition is earlier than the specified timestamp, only the partition data is read from the latest record.
// In this mode, the committed offset in Kafka will be ignored and will not be used as the starting position.
//consumer.setStartFromTimestamp(1585047859000L);
// Specify an offset for each zone
/*Map<KafkaTopicPartition, Long> specificStartOffsets = new HashMap<>();
specificStartOffsets.put(new KafkaTopicPartition("qfbap_ods.code_city", 0), 23L);
specificStartOffsets.put(new KafkaTopicPartition("qfbap_ods.code_city", 1), 31L);
specificStartOffsets.put(new KafkaTopicPartition("qfbap_ods.code_city", 2), 43L);
consumer1.setStartFromSpecificOffsets(specificStartOffsets);*/
/**
*
* Please note: when a Job automatically recovers from a failure or manually recovers using savepoint,
* These start location configuration methods do not affect the start location of consumption.
* During recovery, the starting position of each Kafka partition is determined by the offset stored in savepoint or checkpoint
*
*/
DataStreamSource<String> source = senv.addSource(consumer);
// TODO
source.print();
senv.execute("test kafka connector");
}
}
Interpretation of parameter configuration
In the Demo example, detailed configuration information is given, and the above parameter configurations will be analyzed one by one.
properties parameter configuration of kakfa
- bootstrap.servers: kafka broker address
- zookeeper.connect: only Kafka version 0.8 needs to be configured
- group.id: consumer group
- enable.auto.commit: automatic offset submission. The configuration of this value is not the final offset submission mode. You need to consider whether the user has enabled checkpoint, which will be interpreted in the following source code analysis
- auto.commit.interval.ms: the time interval of offset submission, in milliseconds
- key.deserializer: the key serializer of kafka message. If it is not specified, the ByteArrayDeserializer will be used
- value.deserializer:
The value serializer of kafka message. If it is not specified, the ByteArrayDeserializer serializer will be used
- auto.offset.reset: specifies where kafka consumers start consuming data. There are three ways,
- First: early
When there are submitted offsets under each partition, consumption starts from the submitted offset; When there is no committed offset, consumption starts from scratch - Second: latest
When there are submitted offsets under each partition, consumption starts from the submitted offset; When there is no committed offset, the newly generated data under the partition is consumed - Third: none
topic when there are committed offsets in each partition, consumption starts after offset; As long as there is no submitted offset in one partition, an exception will be thrown. Note: the consumption mode specified above is not the final consumption mode, which depends on the consumption mode configured by the user in the Flink program
Flink program user configured parameters
- consumer.setCommitOffsetsOnCheckpoints(true)
Explanation: after setting checkpoint, submit offset, i.e. onCheck mode. This value is true by default. This parameter will affect the submission method of offset. It will be analyzed in the following source code
- Consumer. Setstartfromearly() explains: the earliest data starts to be consumed. In this mode, the committed offset in Kafka will be ignored and will not be used as the starting position. This method inherits the parent class FlinkKafkaConsumerBase.
- consumer.setStartFromGroupOffsets() explains: the last submitted offset of the consumer group. It is the default. If the offset of the partition cannot be found, the auto.offset.reset setting in the configuration will be used. This method inherits the parent class FlinkKafkaConsumerBase.
- consumer.setStartFromLatest() explains: the latest data starts to be consumed. In this mode, the committed offset in Kafka will be ignored and will not be used as the starting position. This method inherits the parent class FlinkKafkaConsumerBase.
- consumer.setStartFromTimestamp(1585047859000L) explanation: Specifies the specific offset timestamp, in milliseconds. For each partition, records whose timestamp is greater than or equal to the specified timestamp will be used as the starting location. If the latest record of a partition is earlier than the specified timestamp, only the partition data is read from the latest record. In this mode, the committed offset in Kafka will be ignored and will not be used as the starting position.
- consumer.setStartFromSpecificOffsets(specificStartOffsets)
Explanation: specify the offset for each partition. This method inherits the parent class FlinkKafkaConsumerBase.
Please note: these start location configuration methods will not affect the start location of consumption when Job automatically recovers from failure or manually recovers using savepoint. During recovery, the starting position of each Kafka partition is determined by the offset stored in savepoint or checkpoint.
Interpretation of Flink Kafka Consumer source code
Inheritance relationship
Flink Kafka Consumer inherits the abstract class of FlinkKafkaConsumerBase, and the abstract class of FlinkKafkaConsumerBase inherits the RichParallelSourceFunction. Therefore, there are two ways to implement a custom source: one is to define a data source with parallelism of 1 by implementing the SourceFunction interface; The other is to customize the data source with parallelism by implementing the ParallelSourceFunction interface or inheriting the RichParallelSourceFunction. The inheritance relationship of FlinkKafkaConsumer is shown in the following figure.
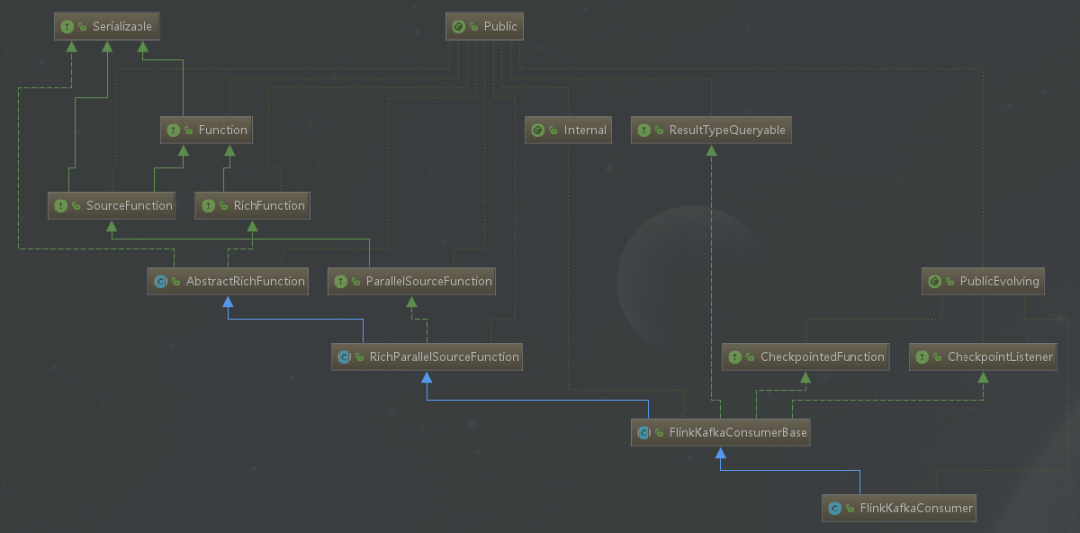
Source code interpretation
FlinkKafkaConsumer source code
Let's take a look at the source code of FlinkKafkaConsumer. In order to read, this article will try to give a relatively complete source code fragment, as shown below: the code is long, so you can have an overall impression here. The following will analyze the important code fragments in detail.
public class FlinkKafkaConsumer<T> extends FlinkKafkaConsumerBase<T> {
// To configure the polling timeout, use the flick.poll-timeout parameter in properties
public static final String KEY_POLL_TIMEOUT = "flink.poll-timeout";
// The time (in milliseconds) required to wait for polling if no data is available. If 0, all available records are returned immediately
//Default polling timeout
public static final long DEFAULT_POLL_TIMEOUT = 100L;
// User provided kafka parameter configuration
protected final Properties properties;
// The time (in milliseconds) required to wait for polling if no data is available. If 0, all available records are returned immediately
protected final long pollTimeout;
/**
* Create a kafka consumer source
* @param topic Subject name of consumption
* @param valueDeserializer Deserialization type, used to convert kafka's byte message to Flink's object
* @param props kafka parameter passed in by user
*/
public FlinkKafkaConsumer(String topic, DeserializationSchema<T> valueDeserializer, Properties props) {
this(Collections.singletonList(topic), valueDeserializer, props);
}
/**
* Create a kafka consumer source
* This constructor allows kafkadeserialization schema to be passed in, and the deserialization class supports access to additional information consumed by kafka
* For example: key/value pairs, offsets, topic
* @param topic Subject name of consumption
* @param deserializer Deserialization type, used to convert kafka's byte message to Flink's object
* @param props kafka parameter passed in by user
*/
public FlinkKafkaConsumer(String topic, KafkaDeserializationSchema<T> deserializer, Properties props) {
this(Collections.singletonList(topic), deserializer, props);
}
/**
* Create a kafka consumer source
* This construction method allows multiple topics to be passed in and supports the consumption of multiple topics
* @param topics The name of the consumed topic. Multiple topics are List collections
* @param deserializer Deserialization type, used to convert kafka's byte message to Flink's object
* @param props kafka parameter passed in by user
*/
public FlinkKafkaConsumer(List<String> topics, DeserializationSchema<T> deserializer, Properties props) {
this(topics, new KafkaDeserializationSchemaWrapper<>(deserializer), props);
}
/**
* Create a kafka consumer source
* This construction method allows multiple topics to be passed in and supports the consumption of multiple topics,
* @param topics The name of the consumed topic. Multiple topics are List collections
* @param deserializer Deserialization type, which is used to convert kafka's byte message into Flink's object, and supports obtaining additional information
* @param props kafka parameter passed in by user
*/
public FlinkKafkaConsumer(List<String> topics, KafkaDeserializationSchema<T> deserializer, Properties props) {
this(topics, null, deserializer, props);
}
/**
* Subscribe to multiple topic s based on regular expressions
* If partition discovery is enabled, that is, flinkkafkaconsumer.key_ PARTITION_ DISCOVERY_ INTERVAL_ The millis value is non negative
* Once a topic is created, it will be subscribed as long as it can be regularly matched
* @param subscriptionPattern Regular expressions for topics
* @param valueDeserializer Deserialization type, which is used to convert kafka's byte message into Flink's object, and supports obtaining additional information
* @param props kafka parameter passed in by user
*/
public FlinkKafkaConsumer(Pattern subscriptionPattern, DeserializationSchema<T> valueDeserializer, Properties props) {
this(null, subscriptionPattern, new KafkaDeserializationSchemaWrapper<>(valueDeserializer), props);
}
/**
* Subscribe to multiple topic s based on regular expressions
* If partition discovery is enabled, that is, flinkkafkaconsumer.key_ PARTITION_ DISCOVERY_ INTERVAL_ The millis value is non negative
* Once a topic is created, it will be subscribed as long as it can be regularly matched
* @param subscriptionPattern Regular expressions for topics
* @param deserializer The deserialization class supports accessing additional information of kafka consumption, such as key/value pairs, offsets, and topic
* @param props kafka parameter passed in by user
*/
public FlinkKafkaConsumer(Pattern subscriptionPattern, KafkaDeserializationSchema<T> deserializer, Properties props) {
this(null, subscriptionPattern, deserializer, props);
}
private FlinkKafkaConsumer(
List<String> topics,
Pattern subscriptionPattern,
KafkaDeserializationSchema<T> deserializer,
Properties props) {
// Call the construction method of the parent class (FlinkKafkaConsumerBase). The first parameter of PropertiesUtil.getLong method is Properties, the second parameter is key, and the third parameter is the default value of value
super(
topics,
subscriptionPattern,
deserializer,
getLong(
checkNotNull(props, "props"),
KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS, PARTITION_DISCOVERY_DISABLED),
!getBoolean(props, KEY_DISABLE_METRICS, false));
this.properties = props;
setDeserializer(this.properties);
// Configure polling timeout. If key is configured in properties_ POLL_ If the timeout parameter is selected, the specific configuration value is returned; otherwise, the default value is returned_ POLL_ TIMEOUT
try {
if (properties.containsKey(KEY_POLL_TIMEOUT)) {
this.pollTimeout = Long.parseLong(properties.getProperty(KEY_POLL_TIMEOUT));
} else {
this.pollTimeout = DEFAULT_POLL_TIMEOUT;
}
}
catch (Exception e) {
throw new IllegalArgumentException("Cannot parse poll timeout for '" + KEY_POLL_TIMEOUT + '\'', e);
}
}
// The parent class (FlinkKafkaConsumerBase) method is overridden. The function of this method is to return a fetcher instance,
// The function of the fetcher is to connect with kafka's broker, pull and deserialize the data, and then output the data as a data stream
@Override
protected AbstractFetcher<T, ?> createFetcher(
SourceContext<T> sourceContext,
Map<KafkaTopicPartition, Long> assignedPartitionsWithInitialOffsets,
SerializedValue<AssignerWithPeriodicWatermarks<T>> watermarksPeriodic,
SerializedValue<AssignerWithPunctuatedWatermarks<T>> watermarksPunctuated,
StreamingRuntimeContext runtimeContext,
OffsetCommitMode offsetCommitMode,
MetricGroup consumerMetricGroup,
boolean useMetrics) throws Exception {
// Make sure that when the commit mode of offset is on_ When checkpoints (condition 1: enable checkpoint, condition 2: consumer.setCommitOffsetsOnCheckpoints(true)), automatic submission is disabled
// This method is a static method of the parent class (FlinkKafkaConsumerBase)
// This overrides any settings configured by the user in properties
// When offset mode is on_ When checkpoints or DISABLED, the user configured properties property will be overwritten
// Specifically, enable_ AUTO_ COMMIT_ The value of config = "enable. Auto. Commit" is reset to "false"
// It can be understood as: if checkpoint is enabled and consumer.setCommitOffsetsOnCheckpoints(true) is set, it is true by default,
// The enable.auto.commit of kafka properties will be set to false
adjustAutoCommitConfig(properties, offsetCommitMode);
return new KafkaFetcher<>(
sourceContext,
assignedPartitionsWithInitialOffsets,
watermarksPeriodic,
watermarksPunctuated,
runtimeContext.getProcessingTimeService(),
runtimeContext.getExecutionConfig().getAutoWatermarkInterval(),
runtimeContext.getUserCodeClassLoader(),
runtimeContext.getTaskNameWithSubtasks(),
deserializer,
properties,
pollTimeout,
runtimeContext.getMetricGroup(),
consumerMetricGroup,
useMetrics);
}
//Parent class (FlinkKafkaConsumerBase) method override
// Returns a partition discovery class. Partition discovery can use kafka broker's advanced consumer API to discover the metadata of topic and partition
@Override
protected AbstractPartitionDiscoverer createPartitionDiscoverer(
KafkaTopicsDescriptor topicsDescriptor,
int indexOfThisSubtask,
int numParallelSubtasks) {
return new KafkaPartitionDiscoverer(topicsDescriptor, indexOfThisSubtask, numParallelSubtasks, properties);
}
/**
*Judge whether automatic submission is enabled in the parameter of kafka, that is, enable.auto.commit=true,
* And auto. Commit. Interval. MS > 0,
* Note: if the enable.auto.commit parameter is not set, it defaults to true
* If the parameter auto.commit.interval.ms is not set, it defaults to 5000 milliseconds
* @return
*/
@Override
protected boolean getIsAutoCommitEnabled() {
//
return getBoolean(properties, ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true) &&
PropertiesUtil.getLong(properties, ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000) > 0;
}
/**
* Ensure that the deserialization method of key and value of kafka message is configured,
* If not configured, the ByteArrayDeserializer serializer is used,
* The deserialize method of this class return s the data directly without any processing
* @param props
*/
private static void setDeserializer(Properties props) {
final String deSerName = ByteArrayDeserializer.class.getName();
Object keyDeSer = props.get(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG);
Object valDeSer = props.get(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG);
if (keyDeSer != null && !keyDeSer.equals(deSerName)) {
LOG.warn("Ignoring configured key DeSerializer ({})", ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG);
}
if (valDeSer != null && !valDeSer.equals(deSerName)) {
LOG.warn("Ignoring configured value DeSerializer ({})", ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG);
}
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, deSerName);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, deSerName);
}
}
analysis
The above code has given very detailed comments. The key parts will be analyzed below.
- Construction method analysis
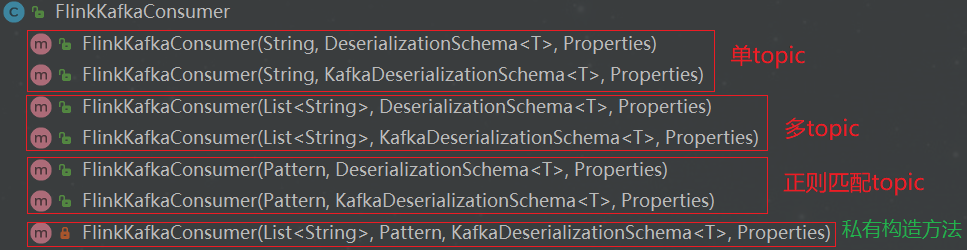
FlinkKakfaConsumer provides seven construction methods, as shown in the figure above. Different construction methods have different functions, and the unique functions of each construction method can also be roughly analyzed through the passed parameters. In order to facilitate understanding, this paper will discuss them in groups, as follows:
Single topic
/**
* Create a kafka consumer source
* @param topic Subject name of consumption
* @param valueDeserializer Deserialization type, used to convert kafka's byte message to Flink's object
* @param props kafka parameter passed in by user
*/
public FlinkKafkaConsumer(String topic, DeserializationSchema<T> valueDeserializer, Properties props) {
this(Collections.singletonList(topic), valueDeserializer, props);
}
/**
* Create a kafka consumer source
* This constructor allows kafkadeserialization schema to be passed in, and the deserialization class supports access to additional information consumed by kafka
* For example: key/value pairs, offsets, topic
* @param topic Subject name of consumption
* @param deserializer Deserialization type, used to convert kafka's byte message to Flink's object
* @param props kafka parameter passed in by user
*/
public FlinkKafkaConsumer(String topic, KafkaDeserializationSchema<T> deserializer, Properties props) {
this(Collections.singletonList(topic), deserializer, props);
}
The above two construction methods only support a single topic. The difference is that the way of deserialization is different. The first one uses the de serialization schema, and the second one uses the kafkade serialization schema. Using the construction method with the kafkade serialization schema parameter can obtain more auxiliary information. For example, in some scenarios, you need to obtain key/value pairs, offsets, topic and other information. You can choose to use this construction method. The above two methods call the private constructor. See the following for the analysis of the private constructor.
Multi topic
/**
* Create a kafka consumer source
* This construction method allows multiple topics to be passed in and supports the consumption of multiple topics
* @param topics The name of the consumed topic. Multiple topics are List collections
* @param deserializer Deserialization type, used to convert kafka's byte message to Flink's object
* @param props kafka parameter passed in by user
*/
public FlinkKafkaConsumer(List<String> topics, DeserializationSchema<T> deserializer, Properties props) {
this(topics, new KafkaDeserializationSchemaWrapper<>(deserializer), props);
}
/**
* Create a kafka consumer source
* This construction method allows multiple topics to be passed in and supports the consumption of multiple topics,
* @param topics The name of the consumed topic. Multiple topics are List collections
* @param deserializer Deserialization type, which is used to convert kafka's byte message into Flink's object, and supports obtaining additional information
* @param props kafka parameter passed in by user
*/
public FlinkKafkaConsumer(List<String> topics, KafkaDeserializationSchema<T> deserializer, Properties props) {
this(topics, null, deserializer, props);
}
The above two construction methods of multiple topics can use a list collection to receive multiple topics for consumption. The difference is that the way of deserialization is different. The first one uses the de serialization schema, and the second one uses the kafkade serialization schema. Using the construction method with the kafkade serialization schema parameter can obtain more auxiliary information. For example, in some scenarios, you need to obtain key/value pairs, offsets, topic and other information. You can choose to use this construction method. The above two methods call the private constructor. See the following for the analysis of the private constructor.
Regular matching topic
/**
* Subscribe to multiple topic s based on regular expressions
* If partition discovery is enabled, that is, flinkkafkaconsumer.key_ PARTITION_ DISCOVERY_ INTERVAL_ The millis value is non negative
* Once a topic is created, it will be subscribed as long as it can be regularly matched
* @param subscriptionPattern Regular expressions for topics
* @param valueDeserializer Deserialization type, which is used to convert kafka's byte message into Flink's object, and supports obtaining additional information
* @param props kafka parameter passed in by user
*/
public FlinkKafkaConsumer(Pattern subscriptionPattern, DeserializationSchema<T> valueDeserializer, Properties props) {
this(null, subscriptionPattern, new KafkaDeserializationSchemaWrapper<>(valueDeserializer), props);
}
/**
* Subscribe to multiple topic s based on regular expressions
* If partition discovery is enabled, that is, flinkkafkaconsumer.key_ PARTITION_ DISCOVERY_ INTERVAL_ The millis value is non negative
* Once a topic is created, it will be subscribed as long as it can be regularly matched
* @param subscriptionPattern Regular expressions for topics
* @param deserializer The deserialization class supports accessing additional information of kafka consumption, such as key/value pairs, offsets, and topic
* @param props kafka parameter passed in by user
*/
public FlinkKafkaConsumer(Pattern subscriptionPattern, KafkaDeserializationSchema<T> deserializer, Properties props) {
this(null, subscriptionPattern, deserializer, props);
}
There may be some requirements in the actual production environment. For example, a flick job needs to aggregate a variety of different data, and these data correspond to different kafka topics. With the growth of business, a new type of data and a new kafka topic are added. How can the job automatically perceive the new topic without restarting the job. First, you need to set the flink.partition-discovery.interval-millis parameter to a non negative value in the properties when building flinkkafkaconsumer, indicating that the dynamic discovery switch is turned on and the set time interval. At this time, the flykafkaconsumer will start a separate thread to kafka regularly to obtain the latest meta information. For specific call execution information, see the following private constructor
Private construction method
private FlinkKafkaConsumer(
List<String> topics,
Pattern subscriptionPattern,
KafkaDeserializationSchema<T> deserializer,
Properties props) {
// Call the construction method of the parent class (FlinkKafkaConsumerBase). The first parameter of PropertiesUtil.getLong method is properties, the second parameter is key, and the third parameter is the default value of value. KEY_ PARTITION_ DISCOVERY_ INTERVAL_ The millis value is the configuration parameter to enable partition discovery. In the properties, configure flip.partition-discovery.interval-millis = 5000 (the number greater than 0). If it is not configured, use partition_ DISCOVERY_ DISABLED=Long.MIN_ Value (indicates that partition discovery is disabled)
super(
topics,
subscriptionPattern,
deserializer,
getLong(
checkNotNull(props, "props"),
KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS, PARTITION_DISCOVERY_DISABLED),
!getBoolean(props, KEY_DISABLE_METRICS, false));
this.properties = props;
setDeserializer(this.properties);
// Configure polling timeout. If key is configured in properties_ POLL_ If the timeout parameter is selected, the specific configuration value is returned; otherwise, the default value is returned_ POLL_ TIMEOUT
try {
if (properties.containsKey(KEY_POLL_TIMEOUT)) {
this.pollTimeout = Long.parseLong(properties.getProperty(KEY_POLL_TIMEOUT));
} else {
this.pollTimeout = DEFAULT_POLL_TIMEOUT;
}
}
catch (Exception e) {
throw new IllegalArgumentException("Cannot parse poll timeout for '" + KEY_POLL_TIMEOUT + '\'', e);
}
}
- Analysis by other methods
KafkaFetcher object creation
// The parent class (FlinkKafkaConsumerBase) method is overridden. The function of this method is to return a fetcher instance,
// The function of the fetcher is to connect with kafka's broker, pull and deserialize the data, and then output the data as a data stream
@Override
protected AbstractFetcher<T, ?> createFetcher(
SourceContext<T> sourceContext,
Map<KafkaTopicPartition, Long> assignedPartitionsWithInitialOffsets,
SerializedValue<AssignerWithPeriodicWatermarks<T>> watermarksPeriodic,
SerializedValue<AssignerWithPunctuatedWatermarks<T>> watermarksPunctuated,
StreamingRuntimeContext runtimeContext,
OffsetCommitMode offsetCommitMode,
MetricGroup consumerMetricGroup,
boolean useMetrics) throws Exception {
// Make sure that when the commit mode of the offset is on_ When checkpoints (condition 1: enable checkpoint, condition 2: consumer.setCommitOffsetsOnCheckpoints(true)), automatic submission is disabled
// This method is a static method of the parent class (FlinkKafkaConsumerBase)
// This overrides any settings configured by the user in properties
// When offset mode is on_ When checkpoints or DISABLED, the user configured properties property will be overwritten
// Specifically, enable_ AUTO_ COMMIT_ The value of config = "enable. Auto. Commit" is reset to "false"
// It can be understood as: if checkpoint is enabled and consumer.setCommitOffsetsOnCheckpoints(true) is set, it is true by default,
// The enable.auto.commit of kafka properties will be set to false
adjustAutoCommitConfig(properties, offsetCommitMode);
return new KafkaFetcher<>(
sourceContext,
assignedPartitionsWithInitialOffsets,
watermarksPeriodic,
watermarksPunctuated,
runtimeContext.getProcessingTimeService(),
runtimeContext.getExecutionConfig().getAutoWatermarkInterval(),
runtimeContext.getUserCodeClassLoader(),
runtimeContext.getTaskNameWithSubtasks(),
deserializer,
properties,
pollTimeout,
runtimeContext.getMetricGroup(),
consumerMetricGroup,
useMetrics);
}
The function of this method is to return a fetcher instance. The function of the fetcher is to connect kafka's broker, pull the data and deserialize it, and then output the data as a data stream. Here, the automatic offset submission mode is forcibly adjusted, that is, to ensure that when the offset submission mode is on_checkpoints (condition 1: enable checkpoint, condition 2: consumer.setCommitOffsetsOnCheckpoints(true)), disable automatic submission. This will override any settings configured by the user in properties. It can be understood simply as: if checkpoint is enabled and consumer.setCommitOffsetsOnCheckpoints(true) is set If the default value is true, enable.auto.commit of kafka properties will be set to false. For the submission mode of offset, see the analysis of offset submission mode below.
Determine whether auto submit is set
@Override
protected boolean getIsAutoCommitEnabled() {
//
return getBoolean(properties, ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true) &&
PropertiesUtil.getLong(properties, ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000) > 0;
}
Judge whether automatic submission is enabled in the parameter of kafka, that is, enable.auto.commit=true, and auto. Commit. Interval. MS > 0. Note: if the parameter of enable.auto.commit is not set, it will be true by default. If the parameter of auto.commit.interval.ms is not set, it will be 5000 ms by default. This method will be initialized when the open method of FlinkKafkaConsumerBase is initialized Call.
Deserialization
private static void setDeserializer(Properties props) {
// Default deserialization method
final String deSerName = ByteArrayDeserializer.class.getName();
//Get the deserialization mode of user configured properties about key and value
Object keyDeSer = props.get(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG);
Object valDeSer = props.get(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG);
// If configured, the user configured value is used
if (keyDeSer != null && !keyDeSer.equals(deSerName)) {
LOG.warn("Ignoring configured key DeSerializer ({})", ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG);
}
if (valDeSer != null && !valDeSer.equals(deSerName)) {
LOG.warn("Ignoring configured value DeSerializer ({})", ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG);
}
// If not configured, the ByteArrayDeserializer is used for deserialization
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, deSerName);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, deSerName);
}
Ensure that the deserialization method of key and value of kafka message is configured. If not configured, use the ByteArrayDeserializer serializer,
The deserialize method of ByteArrayDeserializer class return s the data directly without any processing.
FlinkKafkaConsumerBase source code
@Internal
public abstract class FlinkKafkaConsumerBase<T> extends RichParallelSourceFunction<T> implements
CheckpointListener,
ResultTypeQueryable<T>,
CheckpointedFunction {
public static final int MAX_NUM_PENDING_CHECKPOINTS = 100;
public static final long PARTITION_DISCOVERY_DISABLED = Long.MIN_VALUE;
public static final String KEY_DISABLE_METRICS = "flink.disable-metrics";
public static final String KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS = "flink.partition-discovery.interval-millis";
private static final String OFFSETS_STATE_NAME = "topic-partition-offset-states";
private boolean enableCommitOnCheckpoints = true;
/**
* The submission mode of offset can only be configured in FlinkKafkaConsumerBase#open(Configuration)
* This value depends on whether the user has enabled checkpoint
*/
private OffsetCommitMode offsetCommitMode;
/**
* Configure where to start consuming kafka messages,
* The default is StartupMode#GROUP_OFFSETS, that is, consumption starts from the currently submitted offset
*/
private StartupMode startupMode = StartupMode.GROUP_OFFSETS;
private Map<KafkaTopicPartition, Long> specificStartupOffsets;
private Long startupOffsetsTimestamp;
/**
* Make sure that when the commit mode of the offset is on_ When checkpoints, auto submit is disabled,
* This overrides any settings configured by the user in properties.
* When offset mode is on_ When checkpoints or DISABLED, the user configured properties property will be overwritten
* Specifically, enable_ AUTO_ COMMIT_ The value of config = "enable. Auto. Commit" is reset to "false", that is, automatic submission is disabled
* @param properties kafka The configured properties will be overwritten by this method
* @param offsetCommitMode offset Submission mode
*/
static void adjustAutoCommitConfig(Properties properties, OffsetCommitMode offsetCommitMode) {
if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS || offsetCommitMode == OffsetCommitMode.DISABLED) {
properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
}
}
/**
* Determines whether to submit the offset after the checkpoint when the checkpoint is enabled,
* This parameter has no effect until the user configures enable checkpoint
* If checkpoint is not enabled, use kafka's configuration parameter: enable.auto.commit
* @param commitOnCheckpoints
* @return
*/
public FlinkKafkaConsumerBase<T> setCommitOffsetsOnCheckpoints(boolean commitOnCheckpoints) {
this.enableCommitOnCheckpoints = commitOnCheckpoints;
return this;
}
/**
* Starting from the earliest offset,
*In this mode, the submitted offset in Kafka will be ignored and will not be used as the starting position.
*It can be set through consumer1. Setstartfromearly()
*/
public FlinkKafkaConsumerBase<T> setStartFromEarliest() {
this.startupMode = StartupMode.EARLIEST;
this.startupOffsetsTimestamp = null;
this.specificStartupOffsets = null;
return this;
}
/**
* Starting with the latest data,
* In this mode, the submitted offset in Kafka will be ignored and will not be used as the starting position.
*
*/
public FlinkKafkaConsumerBase<T> setStartFromLatest() {
this.startupMode = StartupMode.LATEST;
this.startupOffsetsTimestamp = null;
this.specificStartupOffsets = null;
return this;
}
/**
*Specifies the specific offset timestamp, in milliseconds
*For each partition, records whose timestamp is greater than or equal to the specified timestamp will be used as the starting location.
* If the latest record of a partition is earlier than the specified timestamp, only the partition data is read from the latest record.
* In this mode, the committed offset in Kafka will be ignored and will not be used as the starting position.
*/
protected FlinkKafkaConsumerBase<T> setStartFromTimestamp(long startupOffsetsTimestamp) {
checkArgument(startupOffsetsTimestamp >= 0, "The provided value for the startup offsets timestamp is invalid.");
long currentTimestamp = System.currentTimeMillis();
checkArgument(startupOffsetsTimestamp <= currentTimestamp,
"Startup time[%s] must be before current time[%s].", startupOffsetsTimestamp, currentTimestamp);
this.startupMode = StartupMode.TIMESTAMP;
this.startupOffsetsTimestamp = startupOffsetsTimestamp;
this.specificStartupOffsets = null;
return this;
}
/**
*
* The default method is to start consumption from the offset recently submitted by a specific consumer group
* If the offset of the partition is not found, use the value configured by the auto.offset.reset parameter
* @return
*/
public FlinkKafkaConsumerBase<T> setStartFromGroupOffsets() {
this.startupMode = StartupMode.GROUP_OFFSETS;
this.startupOffsetsTimestamp = null;
this.specificStartupOffsets = null;
return this;
}
/**
*Specify an offset for each partition to consume
*/
public FlinkKafkaConsumerBase<T> setStartFromSpecificOffsets(Map<KafkaTopicPartition, Long> specificStartupOffsets) {
this.startupMode = StartupMode.SPECIFIC_OFFSETS;
this.startupOffsetsTimestamp = null;
this.specificStartupOffsets = checkNotNull(specificStartupOffsets);
return this;
}
@Override
public void open(Configuration configuration) throws Exception {
// determine the offset commit mode
// Determine the submission mode of the offset,
// The first parameter is whether automatic submission is enabled,
// The second parameter is whether CommitOnCheckpoint mode is enabled
// The third parameter is whether checkpoint is enabled
this.offsetCommitMode = OffsetCommitModes.fromConfiguration(
getIsAutoCommitEnabled(),
enableCommitOnCheckpoints,
((StreamingRuntimeContext) getRuntimeContext()).isCheckpointingEnabled());
// Omitted code
}
// Omitted code
/**
* Create a fetcher to connect to kafka's broker, pull the data and deserialize it, and then output the data as a data stream
* @param sourceContext Context of data output
* @param subscribedPartitionsToStartOffsets The topic partition set that the current sub task needs to process, that is, the Map set of topic partition and offset
* @param watermarksPeriodic Optional, a serialized timestamp extractor generates watermark of periodic type
* @param watermarksPunctuated Optional, a serialized timestamp extractor generates watermark of punctuated type
* @param runtimeContext task runtime context context for
* @param offsetCommitMode offset There are three submission modes: Disabled (disable automatic submission of offset), on_checkpoints (submit offset to Kafka only after checkpoints are completed)
* KAFKA_PERIODIC(Use kafka auto submit function to automatically submit offset periodically)
* @param kafkaMetricGroup Flink Metric of
* @param useMetrics Use Metric
* @return Returns a fetcher instance
* @throws Exception
*/
protected abstract AbstractFetcher<T, ?> createFetcher(
SourceContext<T> sourceContext,
Map<KafkaTopicPartition, Long> subscribedPartitionsToStartOffsets,
SerializedValue<AssignerWithPeriodicWatermarks<T>> watermarksPeriodic,
SerializedValue<AssignerWithPunctuatedWatermarks<T>> watermarksPunctuated,
StreamingRuntimeContext runtimeContext,
OffsetCommitMode offsetCommitMode,
MetricGroup kafkaMetricGroup,
boolean useMetrics) throws Exception;
protected abstract boolean getIsAutoCommitEnabled();
// Omitted code
}
The above code is part of the code fragment of FlinkKafkaConsumer base, which is basically commented in detail. Some methods are inherited by FlinkKafkaConsumer, and some are rewritten. The reason why it is given here can be compared with the source code of FlinkKafkaConsumer for convenience of understanding.
Offset submission mode analysis
Flink Kafka Consumer allows you to configure how to submit offsets back to Kafka broker (or Zookeeper in version 0.8). Please note: Flink Kafka Consumer does not rely on the submitted offsets to ensure fault tolerance. The submitted offsets are just a method to disclose the progress of consumers for monitoring.
Whether the method of configuring offset submission behavior is the same depends on whether checkpointing is enabled for the job. Here, the specific conclusion of the submission mode is given, and the two methods are analyzed in detail below. The basic conclusions are as follows:
- Open checkpoint
- Case 1: the user enables the submission of offset by calling the setCommitOffsetsOnCheckpoints(true) method on the consumer (true by default)
When the checkpointing is completed, Flink Kafka Consumer stores the submitted offset in the checkpoint state.
This ensures that the offset submitted in Kafka broker is consistent with the offset in checkpoint status.
Note that in this scenario, the automatic periodic offset submission setting in Properties will be completely ignored.
In this case, ON_CHECKPOINTS is used - Case 2: if the user disables the submission of offset by calling the setCommitOffsetsOnCheckpoints("false") method on the consumer, the DISABLED mode is used to submit offset
- checkpoint is not enabled
Flink Kafka Consumer relies on the automatic periodic offset submission function of internally used Kafka client. Therefore, it is necessary to disable or enable offset submission - Case 1: configure the parameters of Kafka properties, configure "enable.auto.commit" = "true" or auto.commit.enable=true of Kafka 0.8, and submit offset using KAFKA_PERIODIC mode, that is, automatically submit offset
- Case 2: the enable.auto.commit parameter is not configured and the offset is submitted in the DISABLED mode, which means that kafka does not know the offset of each consumption of the current consumer group.
Submit mode source code analysis
- Submit mode of offset
public enum OffsetCommitMode {
// Disable offset auto commit
DISABLED,
// The offset is submitted to kafka only after the checkpoints are completed
ON_CHECKPOINTS,
// Use the kafka auto submit function to automatically submit offsets periodically
KAFKA_PERIODIC;
}
- Invocation of commit mode
public class OffsetCommitModes {
public static OffsetCommitMode fromConfiguration(
boolean enableAutoCommit,
boolean enableCommitOnCheckpoint,
boolean enableCheckpointing) {
// If checkinpoint is enabled, perform the following judgment
if (enableCheckpointing) {
// If checkpoint is enabled, further judge whether to submit when checkpoint is enabled (setCommitOffsetsOnCheckpoints(true)). If yes, use the ON_CHECKPOINTS mode
// Otherwise, use DISABLED mode
return (enableCommitOnCheckpoint) ? OffsetCommitMode.ON_CHECKPOINTS : OffsetCommitMode.DISABLED;
} else {
// If the parameter of Kafka properties is configured with "enable.auto.commit" = "true", the offset is submitted using KAFKA_PERIODIC mode
// Otherwise, use DISABLED mode
return (enableAutoCommit) ? OffsetCommitMode.KAFKA_PERIODIC : OffsetCommitMode.DISABLED;
}
}
}
Summary
This paper mainly introduces flinkkafka consumer. Firstly, it compares different versions of FlinkKafkaConsumer, then gives a complete Demo case, explains the configuration parameters of the case in detail, then analyzes the inheritance relationship of FlinkKafkaConsumer, and interprets the source code of FlinkKafkaConsumer and its parent class FlinkKafkaConsumer base respectively, Finally, the offset submission mode of Flink Kafka Consumer is analyzed from the source code level, and each submission mode is combed.