International practice, first put Official Documents Introducing a wave
Every time you join a flink IO, you access the database, so the database read is based on disk IO, which must be slow, so this can become a performance bottleneck for stream processing.
Asynchronous IO then asynchronizes the original synchronous requests, and the total time consumed is allocated to IO multiple times.
Asynchronous interaction with the database means that a single parallel function instance can handle many requests concurrently and receive the responses concurrently.
Asynchronous means that a function with a concurrency of 1 can concurrently initiate multiple requests and concurrently receive multiple responses
Then you might ask, why not just increase the parallelism of the function?
parallelism is in some cases possible as well, but usually comes at a very high resource cost: Having many more parallel MapFunction instances means more tasks, threads, Flink-internal network connections, network connections to the database, buffers, and general internal bookkeeping overhead.
The higher the Parallel settings, the more Task s there will be, more threads will be opened, and more connections will be made to the internal network, which in fact will cause increased overhead.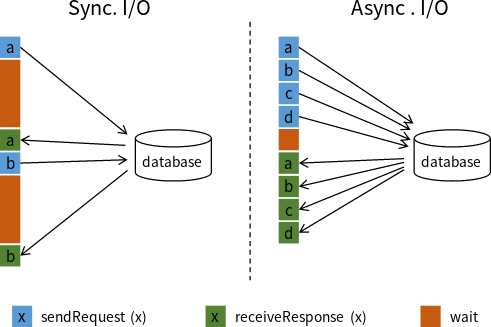
Talk is cheap, show me the code
If you want to make asynchronous IO requests to the database, you need to implement three parts:
-
Implement AsyncFunction to distribute requests
-
Callback function, passed to ResultFuture after the result of the request is obtained
-
In DataStream, use asynchronous IO operations as a transformation
//source stream DataStream<Integer> inputStream = env.addSource(new SimpleSource(maxCount)); //Create Asynchronous Function AsyncFunction<Integer, String> function = new SampleAsyncFunction(sleepFactor, failRatio, shutdownWaitTS); //Asynchronous IO as Operator DataStream<String> result; if (ORDERED.equals(mode)) { result = AsyncDataStream.orderedWait( inputStream, function, timeout, TimeUnit.MILLISECONDS, 20 ).setParallelism(taskNum); } else { result = AsyncDataStream.unorderedWait( inputStream, function, timeout, TimeUnit.MILLISECONDS, 20 ).setParallelism(taskNum); } result.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception { collector.collect(new Tuple2<>(s, 1)); } }) .keyBy(0) .sum(1) .print(); env.execute(); }
Then let's see how this callback function is set up
The key is to rewrite the asyncInoke function to return the results of the IO request to ResultFuture
private static class SampleAsyncFunction extends RichAsyncFunction<Integer, String> { private transient ExecutorService executorService; // Thread pool pause working time to simulate a time-consuming asynchronous operation private long sleepFactor; // Simulate an IO request in error private float failRatio; private long shutdownWaitTS; public SampleAsyncFunction(long sleepFactor, float failRatio, long shutdownWaitTS) { this.sleepFactor = sleepFactor; this.failRatio = failRatio; this.shutdownWaitTS = shutdownWaitTS; } //Simulate thread pool, issue request @Override public void open(Configuration parameters) throws Exception { super.open(parameters); executorService = Executors.newFixedThreadPool(30); } @Override public void close() throws Exception { super.close(); ExecutorUtils.gracefulShutdown(shutdownWaitTS, TimeUnit.MILLISECONDS, executorService); } //callback @Override public void asyncInvoke(Integer integer, ResultFuture<String> resultFuture) throws Exception { executorService.submit(() -> { long sleep = (long) (ThreadLocalRandom.current().nextFloat() * sleepFactor); try { Thread.sleep(sleep); if (ThreadLocalRandom.current().nextFloat() < failRatio) { resultFuture.completeExceptionally(new Exception("failed")); } else { resultFuture.complete(Collections.singletonList("key-" + (integer %10))); } } catch (InterruptedException e) { resultFuture.complete(new ArrayList<>(0)); } }); } }

