1, Improve the game procedures and test the game procedures.
Change the end of the code slightly. If the code is correct, run it. Otherwise, output Error.
from random import random
#Printer introduction
def printIntro():
print("19 Deng Ruoyan, No. 23, Xinji class 2")
print("This program simulates two players A and B Table tennis competition of")
print("Required for program operation A and B Capability value of (expressed as a decimal between 0 and 1)")
#Get program running parameters
def printInputs():
a = eval(input("Please enter players A Ability value of(0-1): "))
b = eval(input("Please enter players B Ability value of(0-1): "))
n = eval(input("Number of simulated matches: "))
return a, b, n
# Play N games
def simNGames(n, probA, probB):
winsA, winsB = 0, 0
for i in range(n):
for j in range(7): #4 wins in 7 games
scoreA, scoreB = simOneGame(probA, probB)
if scoreA > scoreB:
winsA += 1
else:
winsB += 1
return winsA,winsB
#Play a game
def simOneGame(probA, probB):
scoreA, scoreB = 0, 0 #Score of initialization AB
serving = "A"
while not gameOver(scoreA, scoreB): #Using the while loop to perform a race
if scoreA==10 and scoreB==10:
return(simOneGame2(probA,probB))
if serving == "A":
if random() < probA: ##Using random numbers to generate the winner
scoreA += 1
else:
serving="B"
else:
if random() < probB:
scoreB += 1
else:
serving="A"
return scoreA, scoreB
def simOneGame2(probA,probB):
scoreA,scoreB=10,10
serving = "A"
while not gameOver2(scoreA, scoreB):
if serving == "A":
if random() < probA:
scoreA += 1
else:
serving="B"
else:
if random() < probB:
scoreB += 1
else:
serving="A"
return scoreA, scoreB
#The end of the game
def gameOver(a,b): #End of normal game
return a==11 or b==11
def gameOver2(a,b): #Grab 12. The game is over
if abs((a-b))>=2:
return a,b
#output data
def printSummary(winsA, winsB):
n = winsA + winsB
print("Start of competitive analysis, total simulation{}Games".format(n))
print("player A win victory{}Games, percentage{:0.1%}".format(winsA, winsA/n))
print("player B win victory{}Games, percentage{:0.1%}".format(winsB, winsB/n))
#Principal function
def main():
printIntro()
probA, probB, n = printInputs()
winsA, winsB = simNGames(n, probA, probB)
printSummary(winsA, winsB)
try:
main()
except:
print("Error!")
The results are as follows:

The test code is correct.
2, The get() function of the requests library is used to visit the homepage of Bing search dog 20 times, print the return status and text content, and calculate the length of the content returned by the text() property and content property.
The contents of the requests library can be stamped with the following links
https://www.cnblogs.com/deng11/p/12863994.html
import requests
for i in range(20):
r=requests.get("https://www.sogou.com",timeout=30) ා web link can be changed
r.raise_for_status()
r.encoding='utf-8'
print('state={}'.format(r.status_code))
print(r.text)
print('text Attribute length{},content Attribute length{}'.format(len(r.text),len(r.content)))
The result is as follows (take one of the 20 times, the text property is too long to display):
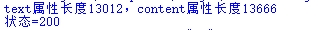
3. According to the given html page, keep it as a string, and complete the following requirements:
(1) Print the content of the head label and the last two digits of your student number
(2) Get the content of the body tag
(3) Get the first label object of id
(4) Get and print Chinese characters in html page
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>Rookie tutorial(runoob.com)</title> </head> <body> <h1>My first title</h1> <p id="first">My first paragraph.</p> </body> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> </table> </html>
The code is as follows:
from bs4 import BeautifulSoup r = ''' <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>Rookie tutorial(runoob.com) 23 Job No</title> </head> <body> <h1>My first title</h1> <p id="first">My first paragraph.</p> </body> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> </table> </html> ''' demo = BeautifulSoup(r,"html.parser") print(demo.title) print(demo.body) print(demo.p) print(demo.string)
The effect is as follows:

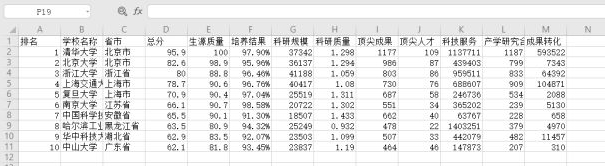
4, Crawl the ranking of Chinese universities (annual fee 2016), and save the data as a csv file.
import requests
from bs4 import BeautifulSoup
ALL = []
def getHTMLtext(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def fillUni(soup):
data = soup.find_all('tr')
for tr in data:
td1 = tr.find_all('td')
if len(td1) == 0:
continue
Single = []
for td in td1:
Single.append(td.string)
ALL.append(Single)
def printUni(num):
print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^6}{5:{0}^6}{6:{0}^6}{7:{0}^6}{8:{0}^6}{9:{0}^5}{10:{0}^6}{11:{0}^6}{12:{0}^6}{13:{0}^6}".format(chr(12288),"ranking","School name","Provinces and cities","Total score",\
"Source quality","Culture results","Scale of scientific research","Quality of scientific research",\
"Top results","Top Talent ","Science and technology services",\
"Industry university research cooperation","Transformation of achievements"))
for i in range(num):
u = ALL[i]
print("{1:^4}{2:{0}^10}{3:{0}^6}{4:{0}^8}{5:{0}^9}{6:{0}^9}{7:{0}^7}{8:{0}^9}{9:{0}^7}{10:{0}^9}{11:{0}^8}{12:{0}^9}{13:{0}^9}".format(chr(12288),u[0],\
u[1],u[2],eval(u[3]),\
u[4],u[5],u[6],u[7],u[8],\
u[9],u[10],u[11],u[12]))
def main(num):
url = "http://www.zuihaodaxue.com/zuihaodaxuepaiming2016.html"
html = getHTMLtext(url)
soup = BeautifulSoup(html,"html.parser")
fillUni(soup)
printUni(num)
main(10)
effect:

Save the crawled data as a csv file, just replace the printUni() function.
The changed code is as follows:
import requests
from bs4 import BeautifulSoup
import csv
import os
ALL = []
def getHTMLtext(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def fillUni(soup):
data = soup.find_all('tr')
for tr in data:
td1 = tr.find_all('td')
if len(td1) == 0:
continue
Single = []
for td in td1:
Single.append(td.string)
ALL.append(Single)
def writercsv(save_road,num,title):
if os.path.isfile(save_road):
with open(save_road,'a',newline='')as f:
csv_write=csv.writer(f,dialect='excel')
for i in range(num):
u=ALL[i]
csv_write.writerow(u)
else:
with open(save_road,'w',newline='')as f:
csv_write=csv.writer(f,dialect='excel')
csv_write.writerow(title)
for i in range(num):
u=ALL[i]
csv_write.writerow(u)
title=["ranking","School name","Provinces and cities","Total score","Source quality","Culture results","Scale of scientific research","Quality of scientific research","Top results","Top Talent ","Science and technology services","Industry university research cooperation","Transformation of achievements"]
save_road="C:\\Users\\Deng Ruoyan\\Desktop\\html.csv"
def main(num):
url = "http://www.zuihaodaxue.com/zuihaodaxuepaiming2016.html"
html = getHTMLtext(url)
soup = BeautifulSoup(html,"html.parser")
fillUni(soup)
writercsv(save_road,num,title)
main(10)
Effect: