This topic is similar to some of the search topics in Leetcode.
The problem you want to deal with is: count the number of two adjacent digits of a word. If there are w1,w2,w3,w4,w5,w6, then:
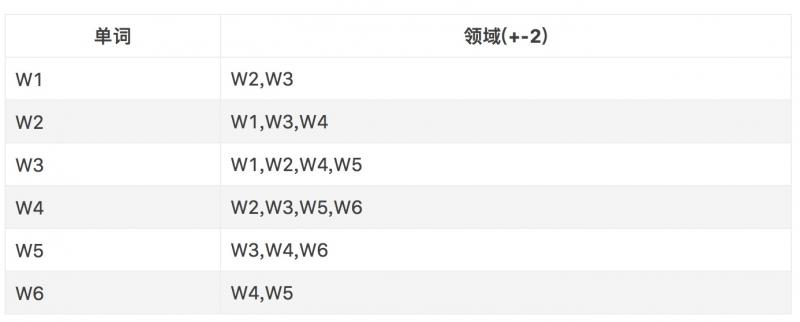
The final output is (word,neighbor,frequency).
We implement it in five ways:
- MapReduce
- Spark
- Spark SQL method
- Scala method
- Spark SQL for Scala
MapReduce
//map function @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] tokens = StringUtils.split(value.toString(), " "); //String[] tokens = StringUtils.split(value.toString(), "\\s+"); if ((tokens == null) || (tokens.length < 2)) { return; } //Calculation rules for two adjacent words for (int i = 0; i < tokens.length; i++) { tokens[i] = tokens[i].replaceAll("\\W+", ""); if (tokens[i].equals("")) { continue; } pair.setWord(tokens[i]); int start = (i - neighborWindow < 0) ? 0 : i - neighborWindow; int end = (i + neighborWindow >= tokens.length) ? tokens.length - 1 : i + neighborWindow; for (int j = start; j <= end; j++) { if (j == i) { continue; } pair.setNeighbor(tokens[j].replaceAll("\\W", "")); context.write(pair, ONE); } // pair.setNeighbor("*"); totalCount.set(end - start); context.write(pair, totalCount); } }
//reduce function @Override protected void reduce(PairOfWords key, Iterable<intwritable> values, Context context) throws IOException, InterruptedException { //Equal to * means the word itself, and its count is totalCount if (key.getNeighbor().equals("*")) { if (key.getWord().equals(currentWord)) { totalCount += totalCount + getTotalCount(values); } else { currentWord = key.getWord(); totalCount = getTotalCount(values); } } else { //Others are single word, which needs to be added through getTotalCount int count = getTotalCount(values); relativeCount.set((double) count / totalCount); context.write(key, relativeCount); } }
Spark
public static void main(String[] args) { if (args.length < 3) { System.out.println("Usage: RelativeFrequencyJava <neighbor-window> <input-dir> <output-dir>"); System.exit(1); } SparkConf sparkConf = new SparkConf().setAppName("RelativeFrequency"); JavaSparkContext sc = new JavaSparkContext(sparkConf); int neighborWindow = Integer.parseInt(args[0]); String input = args[1]; String output = args[2]; final Broadcast<integer> brodcastWindow = sc.broadcast(neighborWindow); JavaRDD<string> rawData = sc.textFile(input); /* * Transform the input to the format: (word, (neighbour, 1)) */ JavaPairRDD<string, tuple2<string, integer>> pairs = rawData.flatMapToPair( new PairFlatMapFunction<string, string, tuple2<string, integer>>() { private static final long serialVersionUID = -6098905144106374491L; @Override public java.util.Iterator<scala.tuple2<string, scala.tuple2<string, integer>>> call(String line) throws Exception { List<tuple2<string, tuple2<string, integer>>> list = new ArrayList<tuple2<string, tuple2<string, integer>>>(); String[] tokens = line.split("\\s"); for (int i = 0; i < tokens.length; i++) { int start = (i - brodcastWindow.value() < 0) ? 0 : i - brodcastWindow.value(); int end = (i + brodcastWindow.value() >= tokens.length) ? tokens.length - 1 : i + brodcastWindow.value(); for (int j = start; j <= end; j++) { if (j != i) { list.add(new Tuple2<string, tuple2<string, integer>>(tokens[i], new Tuple2<string, integer>(tokens[j], 1))); } else { // do nothing continue; } } } return list.iterator(); } } ); // (word, sum(word)) //PairFunction<t, k, v> T => Tuple2<k, v> JavaPairRDD<string, integer> totalByKey = pairs.mapToPair( new PairFunction<tuple2<string, tuple2<string, integer>>, String, Integer>() { private static final long serialVersionUID = -213550053743494205L; @Override public Tuple2<string, integer> call(Tuple2<string, tuple2<string, integer>> tuple) throws Exception { return new Tuple2<string, integer>(tuple._1, tuple._2._2); } }).reduceByKey( new Function2<integer, integer, integer>() { private static final long serialVersionUID = -2380022035302195793L; @Override public Integer call(Integer v1, Integer v2) throws Exception { return (v1 + v2); } }); JavaPairRDD<string, iterable<tuple2<string, integer>>> grouped = pairs.groupByKey(); // (word, (neighbour, 1)) -> (word, (neighbour, sum(neighbour))) //flatMapValues operates at least on value, but does not change the order of key s JavaPairRDD<string, tuple2<string, integer>> uniquePairs = grouped.flatMapValues( //Function<t1, r> -> R call(T1 v1) new Function<iterable<tuple2<string, integer>>, Iterable<tuple2<string, integer>>>() { private static final long serialVersionUID = 5790208031487657081L; @Override public Iterable<tuple2<string, integer>> call(Iterable<tuple2<string, integer>> values) throws Exception { Map<string, integer> map = new HashMap<>(); List<tuple2<string, integer>> list = new ArrayList<>(); Iterator<tuple2<string, integer>> iterator = values.iterator(); while (iterator.hasNext()) { Tuple2<string, integer> value = iterator.next(); int total = value._2; if (map.containsKey(value._1)) { total += map.get(value._1); } map.put(value._1, total); } for (Map.Entry<string, integer> kv : map.entrySet()) { list.add(new Tuple2<string, integer>(kv.getKey(), kv.getValue())); } return list; } }); // (word, ((neighbour, sum(neighbour)), sum(word))) JavaPairRDD<string, tuple2<tuple2<string, integer>, Integer>> joined = uniquePairs.join(totalByKey); // ((key, neighbour), sum(neighbour)/sum(word)) JavaPairRDD<tuple2<string, string>, Double> relativeFrequency = joined.mapToPair( new PairFunction<tuple2<string, tuple2<tuple2<string, integer>, Integer>>, Tuple2<string, string>, Double>() { private static final long serialVersionUID = 3870784537024717320L; @Override public Tuple2<tuple2<string, string>, Double> call(Tuple2<string, tuple2<tuple2<string, integer>, Integer>> tuple) throws Exception { return new Tuple2<tuple2<string, string>, Double>(new Tuple2<string, string>(tuple._1, tuple._2._1._1), ((double) tuple._2._1._2 / tuple._2._2)); } }); // For saving the output in tab separated format // ((key, neighbour), relative_frequency) //Convert the result to a String JavaRDD<string> formatResult_tab_separated = relativeFrequency.map( new Function<tuple2<tuple2<string, string>, Double>, String>() { private static final long serialVersionUID = 7312542139027147922L; @Override public String call(Tuple2<tuple2<string, string>, Double> tuple) throws Exception { return tuple._1._1 + "\t" + tuple._1._2 + "\t" + tuple._2; } }); // save output formatResult_tab_separated.saveAsTextFile(output); // done sc.close(); }
Spark SQL
public static void main(String[] args) { if (args.length < 3) { System.out.println("Usage: SparkSQLRelativeFrequency <neighbor-window> <input-dir> <output-dir>"); System.exit(1); } SparkConf sparkConf = new SparkConf().setAppName("SparkSQLRelativeFrequency"); //Create the SparkSession required by SparkSQL SparkSession spark = SparkSession .builder() .appName("SparkSQLRelativeFrequency") .config(sparkConf) .getOrCreate(); JavaSparkContext sc = new JavaSparkContext(spark.sparkContext()); int neighborWindow = Integer.parseInt(args[0]); String input = args[1]; String output = args[2]; final Broadcast<integer> brodcastWindow = sc.broadcast(neighborWindow); /* *Register a Schema table. This frequency will be used later * Schema (word, neighbour, frequency) */ StructType rfSchema = new StructType(new StructField[]{ new StructField("word", DataTypes.StringType, false, Metadata.empty()), new StructField("neighbour", DataTypes.StringType, false, Metadata.empty()), new StructField("frequency", DataTypes.IntegerType, false, Metadata.empty())}); JavaRDD<string> rawData = sc.textFile(input); /* * Transform the input to the format: (word, (neighbour, 1)) */ JavaRDD<row> rowRDD = rawData .flatMap(new FlatMapFunction<string, row>() { private static final long serialVersionUID = 5481855142090322683L; @Override public Iterator<row> call(String line) throws Exception { List<row> list = new ArrayList<>(); String[] tokens = line.split("\\s"); for (int i = 0; i < tokens.length; i++) { int start = (i - brodcastWindow.value() < 0) ? 0 : i - brodcastWindow.value(); int end = (i + brodcastWindow.value() >= tokens.length) ? tokens.length - 1 : i + brodcastWindow.value(); for (int j = start; j <= end; j++) { if (j != i) { list.add(RowFactory.create(tokens[i], tokens[j], 1)); } else { // do nothing continue; } } } return list.iterator(); } }); //Create DataFrame Dataset<row> rfDataset = spark.createDataFrame(rowRDD, rfSchema); //Turn rfDataset into a table for query rfDataset.createOrReplaceTempView("rfTable"); String query = "SELECT a.word, a.neighbour, (a.feq_total/b.total) rf " + "FROM (SELECT word, neighbour, SUM(frequency) feq_total FROM rfTable GROUP BY word, neighbour) a " + "INNER JOIN (SELECT word, SUM(frequency) as total FROM rfTable GROUP BY word) b ON a.word = b.word"; Dataset<row> sqlResult = spark.sql(query); sqlResult.show(); // print first 20 records on the console sqlResult.write().parquet(output + "/parquetFormat"); // saves output in compressed Parquet format, recommended for large projects. sqlResult.rdd().saveAsTextFile(output + "/textFormat"); // to see output via cat command // done sc.close(); spark.stop(); }
Scala
def main(args: Array[String]): Unit = { if (args.size < 3) { println("Usage: RelativeFrequency <neighbor-window> <input-dir> <output-dir>") sys.exit(1) } val sparkConf = new SparkConf().setAppName("RelativeFrequency") val sc = new SparkContext(sparkConf) val neighborWindow = args(0).toInt val input = args(1) val output = args(2) val brodcastWindow = sc.broadcast(neighborWindow) val rawData = sc.textFile(input) /* * Transform the input to the format: * (word, (neighbour, 1)) */ val pairs = rawData.flatMap(line => { val tokens = line.split("\\s") for { i <- 0 until tokens.length start = if (i - brodcastWindow.value < 0) 0 else i - brodcastWindow.value end = if (i + brodcastWindow.value >= tokens.length) tokens.length - 1 else i + brodcastWindow.value j <- start to end if (j != i) //Use yield to collect the converted function (word, (neighbor, 1)) } yield (tokens(i), (tokens(j), 1)) }) // (word, sum(word)) val totalByKey = pairs.map(t => (t._1, t._2._2)).reduceByKey(_ + _) val grouped = pairs.groupByKey() // (word, (neighbour, sum(neighbour))) val uniquePairs = grouped.flatMapValues(_.groupBy(_._1).mapValues(_.unzip._2.sum)) //Join two RDD S with join function // (word, ((neighbour, sum(neighbour)), sum(word))) val joined = uniquePairs join totalByKey // ((key, neighbour), sum(neighbour)/sum(word)) val relativeFrequency = joined.map(t => { ((t._1, t._2._1._1), (t._2._1._2.toDouble / t._2._2.toDouble)) }) // For saving the output in tab separated format // ((key, neighbour), relative_frequency) val formatResult_tab_separated = relativeFrequency.map(t => t._1._1 + "\t" + t._1._2 + "\t" + t._2) formatResult_tab_separated.saveAsTextFile(output) // done sc.stop() }
Spark SQL for Scala
def main(args: Array[String]): Unit = { if (args.size < 3) { println("Usage: SparkSQLRelativeFrequency <neighbor-window> <input-dir> <output-dir>") sys.exit(1) } val sparkConf = new SparkConf().setAppName("SparkSQLRelativeFrequency") val spark = SparkSession .builder() .config(sparkConf) .getOrCreate() val sc = spark.sparkContext val neighborWindow = args(0).toInt val input = args(1) val output = args(2) val brodcastWindow = sc.broadcast(neighborWindow) val rawData = sc.textFile(input) /* * Schema * (word, neighbour, frequency) */ val rfSchema = StructType(Seq( StructField("word", StringType, false), StructField("neighbour", StringType, false), StructField("frequency", IntegerType, false))) /* * Transform the input to the format: * Row(word, neighbour, 1) */ //Convert to the format required in StructType val rowRDD = rawData.flatMap(line => { val tokens = line.split("\\s") for { i <- 0 until tokens.length //Normal calculation rules are different from MapReduce start = if (i - brodcastWindow.value < 0) 0 else i - brodcastWindow.value end = if (i + brodcastWindow.value >= tokens.length) tokens.length - 1 else i + brodcastWindow.value j <- start to end if (j != i) } yield Row(tokens(i), tokens(j), 1) }) val rfDataFrame = spark.createDataFrame(rowRDD, rfSchema) //Create rfTable table rfDataFrame.createOrReplaceTempView("rfTable") import spark.sql val query = "SELECT a.word, a.neighbour, (a.feq_total/b.total) rf " + "FROM (SELECT word, neighbour, SUM(frequency) feq_total FROM rfTable GROUP BY word, neighbour) a " + "INNER JOIN (SELECT word, SUM(frequency) as total FROM rfTable GROUP BY word) b ON a.word = b.word" val sqlResult = sql(query) sqlResult.show() // print first 20 records on the console sqlResult.write.save(output + "/parquetFormat") // saves output in compressed Parquet format, recommended for large projects. sqlResult.rdd.saveAsTextFile(output + "/textFormat") // to see output via cat command // done spark.stop() }
Statement: all articles in this article are original except for special notes. Readers of the public number have the right of priority reading. They can not be reproduced without the permission of the author, otherwise they will be held liable for infringement.
Pay attention to my public address, background reply [JAVAPDF] get 200 page test questions! 50000 people pay attention to the way of big data becoming God, don't you come to understand it? 50000 people pay attention to the way of big data becoming God. Don't you really come to understand it? 50000 people pay attention to the way of big data becoming God. Are you sure you don't want to understand it?
Welcome to follow The way of big data becoming God
 </output-dir></input-dir></neighbor-window></output-dir></input-dir></neighbor-window></row></row></row></row></string,></row></string></integer></output-dir></input-dir></neighbor-window></tuple2<string,></tuple2<tuple2<string,></string></string,></tuple2<string,></string,></tuple2<string,></string,></tuple2<string,></tuple2<string,></string,></string,></string,></string,></tuple2<string,></tuple2<string,></string,></tuple2<string,></tuple2<string,></tuple2<string,></iterable<tuple2<string,></t1,></string,></string,></integer,></string,></string,></string,></tuple2<string,></string,></k,></t,></string,></string,></tuple2<string,></tuple2<string,></scala.tuple2<string,></string,></string,></string></integer></output-dir></input-dir></neighbor-window></intwritable>
</output-dir></input-dir></neighbor-window></output-dir></input-dir></neighbor-window></row></row></row></row></string,></row></string></integer></output-dir></input-dir></neighbor-window></tuple2<string,></tuple2<tuple2<string,></string></string,></tuple2<string,></string,></tuple2<string,></string,></tuple2<string,></tuple2<string,></string,></string,></string,></string,></tuple2<string,></tuple2<string,></string,></tuple2<string,></tuple2<string,></tuple2<string,></iterable<tuple2<string,></t1,></string,></string,></integer,></string,></string,></string,></tuple2<string,></string,></k,></t,></string,></string,></tuple2<string,></tuple2<string,></scala.tuple2<string,></string,></string,></string></integer></output-dir></input-dir></neighbor-window></intwritable>