From previous reading of the code, the key to discovering the problem is past_ Key_ A change in the value parameter makes the input less complex.
The overall structure of the model (from outside to inside)
The overall structure of the model determines the direction in which the data will operate.
Frame structure diagram of the overall model
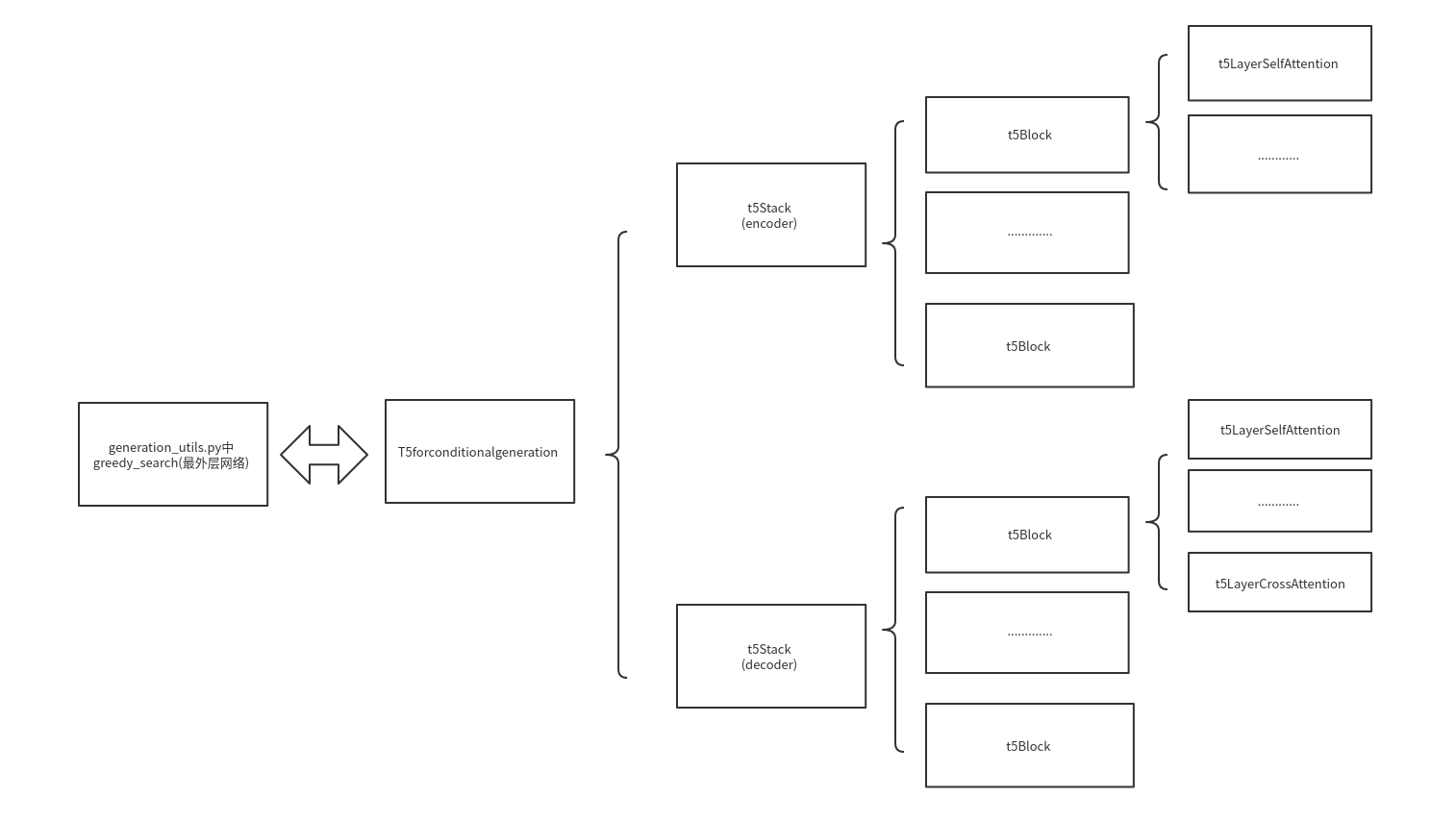
Outermost generation_ Greedy_in utils.py Interpretation of search call model
while True:
if synced_gpus:
# Under synced_gpus the `forward` call must continue until all gpus complete their sequence.
# The following logic allows an early break if all peers finished generating their sequence
this_peer_finished_flag = torch.tensor(0.0 if this_peer_finished else 1.0).to(input_ids.device)
# send 0.0 if we finished, 1.0 otherwise
dist.all_reduce(this_peer_finished_flag, op=dist.ReduceOp.SUM)
# did all peers finish? the reduced sum will be 0.0 then
if this_peer_finished_flag.item() == 0.0:
break
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
# forward pass to get next token
outputs = self(
**model_inputs,
return_dict=True,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
)
if synced_gpus and this_peer_finished:
cur_len = cur_len + 1
continue # don't waste resources running the code we don't need
next_token_logits = outputs.logits[:, -1, :]
# Store scores, attentions and hidden_states when required
if return_dict_in_generate:
if output_scores:
scores += (next_token_logits,)
if output_attentions:
decoder_attentions += (
(outputs.decoder_attentions,) if self.config.is_encoder_decoder else (outputs.attentions,)
)
if self.config.is_encoder_decoder:
cross_attentions += (outputs.cross_attentions,)
if output_hidden_states:
decoder_hidden_states += (
(outputs.decoder_hidden_states,)
if self.config.is_encoder_decoder
else (outputs.hidden_states,)
)
# pre-process distribution
next_tokens_scores = logits_processor(input_ids, next_token_logits)
# argmax
next_tokens = torch.argmax(next_tokens_scores, dim=-1)
# finished sentences should have their next token be a padding token
if eos_token_id is not None:
if pad_token_id is None:
raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)
# update generated ids, model inputs, and length for next step
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
model_kwargs = self._update_model_kwargs_for_generation(
outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
)
cur_len = cur_len + 1
# if eos_token was found in one sentence, set sentence to finished
if eos_token_id is not None:
unfinished_sequences = unfinished_sequences.mul((next_tokens != eos_token_id).long())
# stop when each sentence is finished, or if we exceed the maximum length
if unfinished_sequences.max() == 0 or stopping_criteria(input_ids, scores):
if not synced_gpus:
break
else:
this_peer_finished = True
Input here
input_ids = torch.cat([input_ids,next_tokens[:,None]],dim=-1)
Get input_ids = [0,644]
Then?
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
Estimate here that the parameter is passed down previously (only [0][0] = (1,8,1,64)
model_inputs['past_key_value'][0][0] = torch.Size([1, 8, 1, 64]) model_inputs['past_key_value'][0][1] = torch.Size([1, 8, 1, 64]) model_inputs['past_key_value'][1][0] = torch.Size([1, 8, 11, 64]) model_inputs['past_key_value'][1][1] = torch.Size([1, 8, 11, 64])
Interpretation of t5Stack Model
Definition of t5stack
def forward(
self,
input_ids=None,
attention_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
inputs_embeds=None,
head_mask=None,
cross_attn_head_mask=None,
past_key_values=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
Enter the t5stack category to view content
for i,(layer_module,past_key_value) in enumerate(zip(self.block,past_key_values)):
............
else:
layer_outputs = layer_module(
hidden_states,
attention_mask=extended_attention_mask,
position_bias=position_bias,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
encoder_decoder_position_bias=encoder_decoder_position_bias,
layer_head_mask=layer_head_mask,
cross_attn_layer_head_mask=cross_attn_layer_head_mask,
past_key_value=past_key_value,
use_cache=use_cache,
output_attentions=output_attentions,
)
The layer_here at the beginning Module reads the model, past_key_values store six None s, followed by greedy_ The parameters in search are different, so the past_passed in Key_ The values parameters are different.
Past_here Key_ Value holds six corresponding past_key_value content (all none for the first time),
past_key_value[0][0] = (1,8,1,64) past_key_value[0][1] = (1,8,1,64) past_key_value[0][2] = (1,8,11,64) past_key_value[0][3] = (1,8,11,64) ............ ............ past_key_value[5][0] = (1,8,1,64) past_key_value[5][1] = (1,8,1,64) past_key_value[5][2] = (1,8,11,64) past_key_value[5][3] = (1,8,11,64)
The last t5stack left for this t5stack is the same layer
Notice that past_in the t5stack Value_ State is [None, None, None, None, None] for the first time, and each subsequent time is a legacy of the previous wave
That is, the content in the t5block network layer that follows passes in the output of the previous t5block at the same time, such as the content in the second call to the t5block layer passes in the content in the second call to the t5block network layer for the first time.
Interpretation of content in t5block network layer
Enter the use of t5block
hidden_states,present_key_value_state = self_attention_outputs[:2]
What's passed here is the previously predicted content propagated within the t5layerselfattention network layer (content from the same layer as the previous network structure), which also understands why it's just beginning here
self_attn_past_key_value = past_key_value[:2] ...... ...... self_attention_outputs = self.layer[0]( ...... past_key_value=self_attn_past_key_value, ...... )
Acquired
self_attn_past_key_value[0][0] = (1,8,1,64) self_attn_past_key_value[0][1] = (1,8,1,64) self_attn_past_key_value[0][2] = (1,8,11,64) self_attn_past_key_value[0][3] = (1,8,11,64)
After this wave of data output, call the new present_key_value_state
hidden_states,present_key_value_state = self_attention_outputs[:2]
Here present_ Key_ Value_ The content of the state is
present_key_value_state[0] = torch.Size([1, 8, 1, 64]) present_key_value_state[1] = torch.Size([1, 8, 1, 64])
Next, after the decoder section, call the new present_key_value_state
cross_attention_outputs = self.layer[1](
hidden_states,
key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
position_bias=encoder_decoder_position_bias,
layer_head_mask=cross_attn_layer_head_mask,
past_key_value=cross_attn_past_key_value,
query_length=query_length,
use_cache=use_cache,
output_attentions=output_attentions,
)
New present_obtained Key_ Value_ Content of state
# Combine self attn and cross attn key value states
if present_key_value_state is not None:
present_key_value_state = present_key_value_state + cross_attention_outputs[1]
Get a new present_ Key_ Value_ The content of the state is
present_key_value_state = torch.Size([1, 8, 1, 64]) torch.Size([1, 8, 1, 64]) torch.Size([1, 8, 11, 64]) torch.Size([1, 8, 11, 64])
The offset parameters for the other two locations are also saved later
# Keep cross-attention outputs and relative position weights attention_outputs = attention_outputs + cross_attention_outputs[2:]
The content of the resulting location offset is
attention_outputs = torch.Size([1, 8, 1, 1]) torch.Size([1, 8, 1, 11])
Interpretation of T5 layerselfattention
There are two modes of t5block, one is the interpretation of t5layerselfattention, the other is the interpretation of the network structure of t5layerselfattention+t5layerselfattention. Here we will explain t5layerselfattention
Past_injected here Key_ The contents of the value should be
None perhaps (1,8,1,64) (1,8,1,64)
Interpretation of t5layerselfattention code in t5layerselfattention+t5layercrossattention
There are two modes in t5block, one is the interpretation of t5layerselfattention and the other is the interpretation of t5layerselfattention+t5layercrossattention network structure. Here we explain the code content of t5layerselfattention in t5layerselfattention+t5layercrossattention network structure
t5layerselfattention goes directly into t5attention's content
First run of t5attention
On first run
batch_size = 1,seq_length = 11,key_length = 11
Then we go into the calling process
query_states = shape(self.q(hidden_states))
obtain
query_states = (1,8,1,64)
(The contents of query_states are fixed here)
Next move on to key_states and value_ Operation in states
key_states = project(
hidden_states, self.k, key_value_states, past_key_value[0] if past_key_value is not None else None
)
value_states = project(
hidden_states, self.v, key_value_states, past_key_value[1] if past_key_value is not None else None
)
Enter the project function to view the contents
def project(hidden_states, proj_layer, key_value_states, past_key_value):
"""projects hidden states correctly to key/query states"""
if key_value_states is None:
# self-attn
# (batch_size, n_heads, seq_length, dim_per_head)
hidden_states = shape(proj_layer(hidden_states))
elif past_key_value is None:
# cross-attn
# (batch_size, n_heads, seq_length, dim_per_head)
hidden_states = shape(proj_layer(key_value_states))
if past_key_value is not None:
if key_value_states is None:
# self-attn
# (batch_size, n_heads, key_length, dim_per_head)
hidden_states = torch.cat([past_key_value, hidden_states], dim=2)
else:
# cross-attn
hidden_states = past_key_value
return hidden_states
Here key_value_states is None, the following elif, if statements have not been called, directly calling the network layer
hidden_states = shape(proj_layer(hidden_states))
Result obtained
hidden_states = torch.size([1,8,11,64])
Next call
key_states = project(
hidden_states, self.k, key_value_states, past_key_value[0] if past_key_value is not None else None
)
value_states = project(
hidden_states, self.v, key_value_states, past_key_value[1] if past_key_value is not None else None
)
Result obtained
key_states = torch.Size([1, 8, 11, 64]) value_states = torch.Size([1, 8, 11, 64])
Then calculate the corresponding score
# compute scores
scores = torch.matmul(
query_states, key_states.transpose(3, 2)
) # equivalent of torch.einsum("bnqd,bnkd->bnqk", query_states, key_states), compatible with onnx op>9
Get results
scores = (1,8,11,11)
Next calculate position_ Contents of bias
if position_bias is None:
if not self.has_relative_attention_bias:
position_bias = torch.zeros(
(1, self.n_heads, real_seq_length, key_length), device=scores.device, dtype=scores.dtype
)
if self.gradient_checkpointing and self.training:
position_bias.requires_grad = True
else:
position_bias = self.compute_bias(real_seq_length, key_length)
# if key and values are already calculated
# we want only the last query position bias
if past_key_value is not None:
position_bias = position_bias[:, :, -hidden_states.size(1) :, :]
if mask is not None:
position_bias = position_bias + mask # (batch_size, n_heads, seq_length, key_length)
What should be running here is
position_bias = self.compute_bias(real_seq_length,key_length)
Get position_ Shape of bias
position_bias = (1,8,11,11)
What to do next
scores += position_bias
attn_weights = nn.functional.softmax(scores.float(), dim=-1).type_as(
scores
) # (batch_size, n_heads, seq_length, key_length)
attn_weights = nn.functional.dropout(
attn_weights, p=self.dropout, training=self.training
) # (batch_size, n_heads, seq_length, key_length)
# Mask heads if we want to
if layer_head_mask is not None:
attn_weights = attn_weights * layer_head_mask
Attn_here Weights = (1,8,11,11)
Then go through a wave of output
attn_output = unshape(torch.matmul(attn_weights,value_states)) attn_output = self.o(attn_output)
attn_weights, including key_states, value_states and position_bias are equivalent to the parameter content of the intermediate process, only outputs are the parameter content of the final result
Finally, save these as tulpe output
present_key_value_state = (key_states, value_states) if (self.is_decoder and use_cache) else None
outputs = (attn_output,) + (present_key_value_state,) + (position_bias,)
if output_attentions:
outputs = outputs + (attn_weights,)
return outputs
Position_calculated here Bias is None for the first time, and the calculations are then passed back, saving the running time of the model. position_bias are identical in the selflayerattentions of the six encoder s, the selflayerattentions of the six decoders are identical, the selfcrossattentions of the six decoders are identical, the selflayerattentions and the position_in the selfcrossattentions are identical Bias are different
t5attention encoder second call
The first call ends. During the prediction process, the encoder only calls six corresponding t5attention encoder s at a time. After the encoder call is completed, the decoder part is called continuously until the decoder part outputs the stop symbol of the prediction.
Interpretation of t5layerselfattention code in t5layerselfattention+t5layercrossattention
The first call process does not have the previous call to t5layerselfattention, decoder_input_ids = (1,1)
Decoder_here Input_ IDS is an input parameter that has been initialized since the beginning, as opposed to the previous encoder_ The contents of outputs are irrelevant
From the category of T5 for conditionalgeneration
decoder_outputs = self.decoder(
input_ids=decoder_input_ids,
attention_mask=decoder_attention_mask,
inputs_embeds=decoder_inputs_embeds,
past_key_values=past_key_values,
encoder_hidden_states=hidden_states,
encoder_attention_mask=attention_mask,
head_mask=decoder_head_mask,
cross_attn_head_mask=cross_attn_head_mask,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
The only part of the previous encoder output here is
encoder_hidden_states=hidden_states
Previous hidden_called States = (1,11,512), the rest of the parameters are independent of the encoder part
Then enter the category of t5block for viewing
self_attention_outputs = self.layer[0](
hidden_states,
attention_mask=attention_mask,
position_bias=position_bias,
layer_head_mask=layer_head_mask,
past_key_value=self_attn_past_key_value,
use_cache=use_cache,
output_attentions=output_attentions,
)
That is, the selflayerattention call in decoder is always unrelated to the output of the previous encoder
View decoder section in t5block
cross_attention_outputs = self.layer[1]( hidden_states, key_value_states=encoder_hidden_states, attention_mask=encoder_attention_mask, position_bias=encoder_decoder_position_bias, layer_head_mask=cross_attn_layer_head_mask, past_key_value=cross_attn_past_key_value, query_length=query_length, use_cache=use_cache, output_attentions=output_attentions, )
The crosslayerattention section in decoder calls the output of the previous encoder
key_value_states = encoder_hidden_states
Let's first look at the output from the first encoder section
The first t5layerselfattention code call to the decoder section
Beginning parameters
batch_size,seq_length = hidden_states.shape[:2] real_seq_length = seq_length
Obtained parameters
batch_size = 1,seq_length = 1,real_seq_length = 1
Next the call to the network layer is unchanged
query_states = shape(self.q(hidden_states))
Get query_states content
query_states = torch.Size([1, 8, 1, 64])
Then call
key_states = project(
hidden_states, self.k, key_value_states, past_key_value[0] if past_key_value is not None else None
)
value_states = project(
hidden_states, self.v, key_value_states, past_key_value[1] if past_key_value is not None else None
)
Get Shape
key_states = torch.tensor([1, 8, 1, 64]) value_states = torch.tensor([1, 8, 1, 64])
The subsequent program operations are similar to those above, and the output is called last
outputs = (attn_output,)+(present_key_value_state,)+(position_bias,)
The second decoder section's t5layerselfattention code call (the second here is the t5layerselfattention that calls six encoders and the t5layerselfattention and t5layercrossattention content of six encoders in decoder)
The second run here corresponds to the second run to a new location after the first value has been predicted. Past_called here Key_ Value[0] corresponds to the key_of the same layer output from the previous location States, past_key_value[1] corresponds to the value_of the same layer output from the previous location States (for example, here is the selflayerattention of the second wave of six encoders + three decoders + the fourth decoder, which is equivalent to the selflayerattention of the first wave of six encoders + three decoders + the fourth decoder)
Next Enter
key_states = project(
hidden_states, self.k, key_value_states, past_key_value[0] if past_key_value is not None else None
)
value_states = project(
hidden_states, self.v, key_value_states, past_key_value[1] if past_key_value is not None else None
)
if past_key_value is not None:
if key_value_states is None:
# self-attn
# (batch_size, n_heads, key_length, dim_per_head)
hidden_states = torch.cat([past_key_value, hidden_states], dim=2)
else:
# cross-attn
hidden_states = past_key_value
Here the first if is called if it is t5layerselfattention and the second if is called if it is crossattention
If it is t5layerselfattention, the following code is called inside the project function
if past_key_value is not None:
if key_value_states is None:
# self-attn
# (batch_size, n_heads, key_length, dim_per_head)
hidden_states = torch.cat([past_key_value, hidden_states], dim=2)
............
return hidden_states
Get the output from the second wave
key_states.size = torch.Size([1, 8, 2, 64]) value_states.size = torch.Size([1, 8, 2, 64])
Next call scores content
# compute scores
scores = torch.matmul(
query_states, key_states.transpose(3, 2)
) # equivalent of torch.einsum("bnqd,bnkd->bnqk", query_states, key_states), compatible with onnx op>9
Result obtained
scores = torch.Size([1, 8, 1, 2])
Next, look at position_ Calculation of bias
if position_bias is None:
if not self.has_relative_attention_bias:
position_bias = torch.zeros(
(1, self.n_heads, real_seq_length, key_length), device=scores.device, dtype=scores.dtype
)
if self.gradient_checkpointing and self.training:
position_bias.requires_grad = True
else:
position_bias = self.compute_bias(real_seq_length, key_length)
Position_obtained here Bias results
position_bias = torch.Size([1, 8, 2, 2])
Next, there is a corresponding line of small word labels:
if key and values are already calculated, we want only the last query position bias.
Call the corresponding code
if past_key_value is not None: position_bias = position_bias[:, :, -hidden_states.size(1) :, :]
Notice that the last dimension is taken out, after which position_bias = (1,8,1,2)
Then call the statement
scores += position_bias
#scores = (1,8,1,2)
attn_weights = nn.functional.softmax(scores.float(), dim=-1).type_as(
scores
) # (batch_size, n_heads, seq_length, key_length)
attn_weights = nn.functional.dropout(
attn_weights, p=self.dropout, training=self.training
) # (batch_size, n_heads, seq_length, key_length)
# Mask heads if we want to
if layer_head_mask is not None:
attn_weights = attn_weights * layer_head_mask
The contents of scores so far have been (1,8,1,2)
Next call
attn_output = unshape((torch.matmul(attn_weights,value_states))
attn_weights = (1,8,1,2),value_states = (1,8,2,64)
Multiplication results (1,8,1,64)
Then use unshape for output
attn_output = unshape(torch.matmul(attn_weights,value_states)) #attn_output = (1,1,512) attn_output = self.o(attn_output)
Get results
attn_output = (1,1,512)
Interpretation of t5layerselfattention code in t5layerselfattention+t5layercrossattention
There are two modes of T5 block, one is the interpretation of T5 layerselfattention, the other is the interpretation of T5 layerselfattention+t5 layersrossattention network structure. Here we explain the code content of T5 layerselfattention+t5 layersrossattention network structure
The first call to t5layercrossattention
The previous parameters are similar to selflayerattention
batch_size = 1,seq_length = 1,real_seq_length = 1
Next call statement
key_length = real_seq_length if key_value_states is None else key_value_states.shape[1]
Because key_value_states is not None, so what you get here is
key_length = 11
Here key_value_states = (1,11,512), which is the result of the previous six encoder outputs (the same result for the six t5layercrossattention s)
Next, call the contents of the project mapping section
def project(hidden_states, proj_layer, key_value_states, past_key_value):
"""projects hidden states correctly to key/query states"""
if key_value_states is None:
# self-attn
# (batch_size, n_heads, seq_length, dim_per_head)
hidden_states = shape(proj_layer(hidden_states))
elif past_key_value is None:
# cross-attn
# (batch_size, n_heads, seq_length, dim_per_head)
hidden_states = shape(proj_layer(key_value_states))
if past_key_value is not None:
if key_value_states is None:
# self-attn
# (batch_size, n_heads, key_length, dim_per_head)
hidden_states = torch.cat([past_key_value, hidden_states], dim=2)
else:
# cross-attn
hidden_states = past_key_value
return hidden_states
The first wave of layercrossattention calls this statement directly
elif past_key_value is None: hidden_states = shape(proj_layer(key_value_states))
Here key_ Value_ The contents of states are the parts of the previous encoder output (1,8,11,64)
So hidden_here States = (1,8,11,64)
Then past_ Key_ if statement after value == None is not called
Next call
query_states = shape(self.q(hidden_states))
query_states = (1,8,1,64)
Then the next two calls
key_states = project(
hidden_states, self.k, key_value_states, past_key_value[0] if past_key_value is not None else None
)
value_states = project(
hidden_states, self.v, key_value_states, past_key_value[1] if past_key_value is not None else None
)
obtain
key_states = (1,8,11,64) value_states = (1,8,11,64)
Then scores calls the intermediate procedure
scores = torch.matmul(query_states,key_states.transpose(3,2))
Get results
scores = (1,8,1,64)*(1,8,64,11) = (1,8,1,11)
Next, call the following statement
scores += position_bias
attn_weights = nn.functional.softmax(scores.float(), dim=-1).type_as(
scores
) # (batch_size, n_heads, seq_length, key_length)
attn_weights = nn.functional.dropout(
attn_weights, p=self.dropout, training=self.training
) # (batch_size, n_heads, seq_length, key_length)
# Mask heads if we want to
if layer_head_mask is not None:
attn_weights = attn_weights * layer_head_mask
attn_weights = (1,8,1,11)
Last multiplied and returned
attn_output = unshape(torch.matmul(attn_weights,value_states)) attn_output= self.o(attn_output)
Get results
attn_output = (1,8,1,11)*(1,8,11,64) = (1,8,1,64)->(1,1,512) attn_output After Linear Layer->(1,1,512)
Finally, package these parameters together for output
present_key_value_state = (key_states, value_states) if (self.is_decoder and use_cache) else None
outputs = (attn_output,) + (present_key_value_state,) + (position_bias,)
if output_attentions:
outputs = outputs + (attn_weights,)
Second call to t5layercrossattention content
The same parameters as the first call
batch_size,seq_length = hidden_states.shape[:2] real_seq_length = seq_length
Here's batch_size = 1,seq_length = 1,real_seq_length = 1
Next call
key_length = real_seq_length if key_value_states is None else key_value_states.shape[1]
Get parameters
key_length = 11
The only difference is key_states and value_states are called differently
key_states = project(
hidden_states, self.k, key_value_states, past_key_value[0] if past_key_value is not None else None
)
value_states = project(
hidden_states, self.v, key_value_states, past_key_value[1] if past_key_value is not None else None
)
First, pass in past_here Key_ Value[0] and past_key_value[1] is the result of a wave running at the same level
Past_called here Key_ Value[0] corresponds to the key_of the same layer output from the previous location States, past_key_value[1] corresponds to the value_of the same layer output from the previous location States (for example, here is the selflayerattention of the second wave of six encoders + three decoders + the fourth decoder, which is equivalent to the selflayerattention of the first wave of six encoders + three decoders + the fourth decoder)
Next to the project function
def project(hidden_states, proj_layer, key_value_states, past_key_value):
"""projects hidden states correctly to key/query states"""
if key_value_states is None:
# self-attn
# (batch_size, n_heads, seq_length, dim_per_head)
hidden_states = shape(proj_layer(hidden_states))
elif past_key_value is None:
# cross-attn
# (batch_size, n_heads, seq_length, dim_per_head)
hidden_states = shape(proj_layer(key_value_states))
if past_key_value is not None:
if key_value_states is None:
# self-attn
# (batch_size, n_heads, key_length, dim_per_head)
hidden_states = torch.cat([past_key_value, hidden_states], dim=2)
else:
# cross-attn
hidden_states = past_key_value
return hidden_states
Run the last else directly
hidden_states = past_key_value
Get hidden_states = torch.Size([1, 8, 11, 64])
To summarize the contents of the project function, the first if for the first selflayerattention (including encoder and decoder sections), else for the first layercrossattention, the second if for the second to nth selflayerattention, and else for the second to nth layercrossattention
Subsequent operations are similar
(1,8,1,64)*(1,8,64,11) = (1,8,1,11) (1,8,1,11)*(1,8,11,64) = (1,8,1,64)