Today, distributed computing engines are the backbone of many analysis, batch, and streaming applications. Spark provides many advanced functions (pivot, analysis window function, etc.) to convert data out of the box. Sometimes you need to process hierarchical data or perform hierarchical calculations. Many database vendors provide functions such as "recursive CTE (common expression)" or "join" SQL clauses to query / transform hierarchical data. CTE is also called recursive query or parent-child query. In this article, we will look at how to use spark to solve this problem.
Tiered data overview –
There is a hierarchical relationship where one item of data is the parent of the other. Hierarchical data can be represented by graphical attribute object model, in which each row is a vertex (node), the connection is the edge (relationship) connecting the vertices, and the column is the attributes of the vertices.
Some use cases
- Financial calculation - the sub account is accumulated to the parent account until the highest account
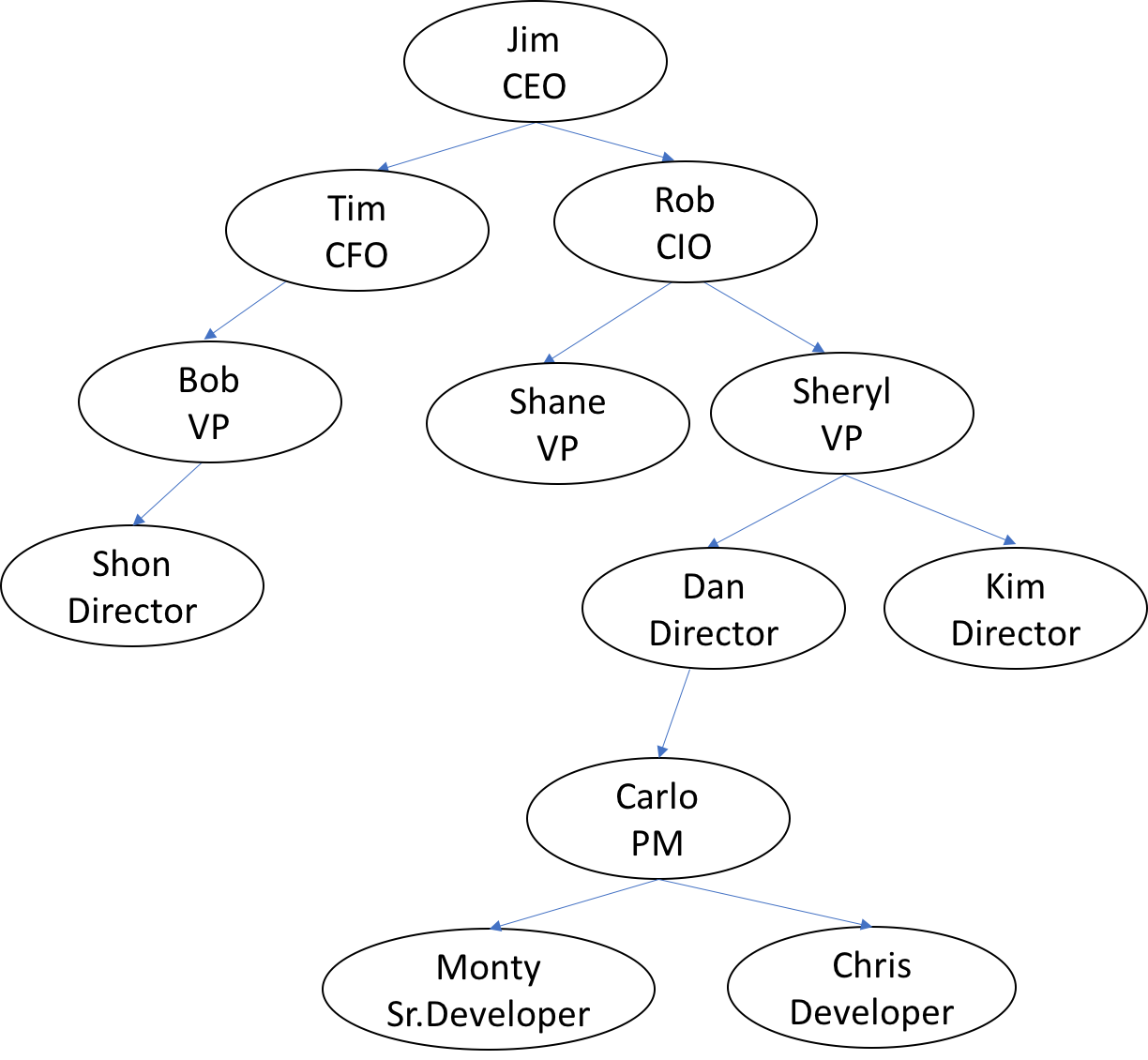
- Create organizational hierarchy - employee relationship between manager and path
- Use path to generate link graph between web pages
- Any type of iterative calculation involving linked data
Challenge
There are some challenges in querying hierarchical data in distributed systems
Data is connected, but it is distributed between partitions and nodes. The implementation to solve this problem should be optimized for performing iterations and shuffling data as needed.
The depth of the graph changes over time -- the solution should handle different depths and should not force the user to define it before processing.
Solution
One way to implement CTE in spark is to use the Graphx Pregel API.
What is the Graphx Pregel API?
Graphx is a Spark API for graphics and graphics parallel computing. Graph algorithms are iterative in nature, and the attributes of vertices depend on the attributes of vertices they connect directly or indirectly (connected by other vertices). Pregel is a vertex centered graph processing model developed by Google and spark graphX. It provides optimized variants of the pregel api.
How does the Pregel API work?
Pregel API processing includes executing super steps
Step 0:
Pass the initial message to all vertices
Sends the value as a message to the vertex to which it is directly connected
Step 1:
Receive messages from previous steps
change a value
Sends the value as a message to the vertex to which it is directly connected
Repeat step 1} until there is messaging, and stop when there is no more messaging.
Hierarchical data of use cases
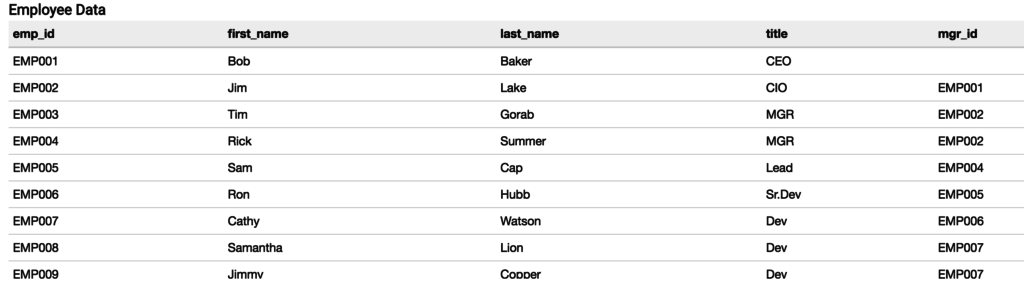
The following table shows the sample employee data we will use to generate a top-down hierarchy. Here, the manager of the employee has EMP_ Mgr of ID value_ The ID field indicates.
Add the following as part of the process
| Level (Depth) | The level of the vertex in the hierarchy |
|---|---|
| Path | The path from the topmost vertex to the current vertex in the hierarchy |
| Root | The topmost vertex in a hierarchy, which is useful when there are multiple hierarchies in the dataset |
| Iscyclic | If there is bad data, there is a circular relationship, and then mark it |
| Isleaf | If a vertex has no parent node, it is marked |
code
import org.apache.log4j.{Level, Logger}
import org.apache.spark.graphx._
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
import scala.util.hashing.MurmurHash3
/**
* Pregel API
* @author zyh
*/
object PregelTest {
// The code below demonstrates use of Graphx Pregel API - Scala 2.11+
// functions to build the top down hierarchy
//setup & call the pregel api
//Set up and call the pregel api
def calcTopLevelHierarcy(vertexDF: DataFrame, edgeDF: DataFrame): RDD[(Any,(Int,Any,String,Int,Int))] = {
// create the vertex RDD
// primary key, root, path
val verticesRDD: RDD[(VertexId, (Any, Any, String))] = vertexDF
.rdd
.map{x=> (x.get(0),x.get(1) , x.get(2))}
.map{ x => (MurmurHash3.stringHash(x._1.toString).toLong, ( x._1.asInstanceOf[Any], x._2.asInstanceOf[Any] , x._3.asInstanceOf[String]) ) }
// create the edge RDD
// top down relationship
val EdgesRDD = edgeDF
.rdd
.map{x=> (x.get(0),x.get(1))}
.map{ x => Edge(MurmurHash3.stringHash(x._1.toString).toLong, MurmurHash3.stringHash(x._2.toString).toLong,"topdown" )}
// create graph
val graph = Graph(verticesRDD, EdgesRDD).cache()
val pathSeperator = """/"""
// Initialization message
// initialize id,level,root,path,iscyclic, isleaf
val initialMsg = (0L,0,0.asInstanceOf[Any], List("dummy"),0,1)
// add more dummy attributes to the vertices - id, level, root, path, isCyclic, existing value of current vertex to build path, isleaf, pk
val initialGraph = graph.mapVertices((id, v) => (id, 0, v._2, List(v._3), 0, v._3, 1, v._1) )
val hrchyRDD = initialGraph.pregel(
initialMsg,
Int.MaxValue, // The number of iterations, set to the current value, indicates that the iteration will continue indefinitely
EdgeDirection.Out)(
setMsg,
sendMsg,
mergeMsg)
// build the path from the list
val hrchyOutRDD = hrchyRDD.vertices.map{case(id,v) => (v._8,(v._2,v._3,pathSeperator + v._4.reverse.mkString(pathSeperator),v._5, v._7 )) }
hrchyOutRDD
}
//Change the value of the vertex
def setMsg(vertexId: VertexId, value: (Long,Int,Any,List[String], Int,String,Int,Any), message: (Long,Int, Any,List[String],Int,Int)): (Long,Int, Any,List[String],Int,String,Int,Any) = {
// The first message received is the initialization message initialMsg
println(s"Set value: $value Received message: $message")
if (message._2 < 1) { //superstep 0 - initialize
(value._1,value._2+1,value._3,value._4,value._5,value._6,value._7,value._8)
}
else if ( message._5 == 1) { // set isCyclic (judge whether it is a ring)
(value._1, value._2, value._3, value._4, message._5, value._6, value._7,value._8)
} else if ( message._6 == 0 ) { // set isleaf
(value._1, value._2, value._3, value._4, value._5, value._6, message._6,value._8)
}
else { // set new values
//( message._1,value._2+1, value._3, value._6 :: message._4 , value._5,value._6,value._7,value._8)
( message._1,value._2+1, message._3, value._6 :: message._4 , value._5,value._6,value._7,value._8)
}
}
// Send values to vertices
def sendMsg(triplet: EdgeTriplet[(Long,Int,Any,List[String],Int,String,Int,Any), _]): Iterator[(VertexId, (Long,Int,Any,List[String],Int,Int))] = {
val sourceVertex: (VertexId, Int, Any, List[String], Int, String, Int, Any) = triplet.srcAttr
val destinationVertex: (VertexId, Int, Any, List[String], Int, String, Int, Any) = triplet.dstAttr
println(s" source: $sourceVertex destination: $destinationVertex")
// Check whether it is a dead ring, that is, a is the leader of b and b is the leader of A
// check for icyclic
if (sourceVertex._1 == triplet.dstId || sourceVertex._1 == destinationVertex._1) {
println(s"There is a dead ring source: ${sourceVertex._1} destination: ${triplet.dstId}")
if (destinationVertex._5 == 0) { //set iscyclic
Iterator((triplet.dstId, (sourceVertex._1, sourceVertex._2, sourceVertex._3, sourceVertex._4, 1, sourceVertex._7)))
} else {
Iterator.empty
}
}
else {
// Judge whether it is a leaf node or a node without child nodes. It belongs to a leaf node and the root node does not count. Therefore, the leaf nodes in the sample data are 3, 8 and 10
if (sourceVertex._7==1) //is NOT leaf
{
Iterator((triplet.srcId, (sourceVertex._1,sourceVertex._2,sourceVertex._3, sourceVertex._4 ,0, 0 )))
}
else { // set new values
Iterator((triplet.dstId, (sourceVertex._1, sourceVertex._2, sourceVertex._3, sourceVertex._4, 0, 1)))
}
}
}
// Receive values from all connected vertices
def mergeMsg(msg1: (Long,Int,Any,List[String],Int,Int), msg2: (Long,Int, Any,List[String],Int,Int)): (Long,Int,Any,List[String],Int,Int) = {
println(s"Merge value: $msg1 $msg2")
// dummy logic not applicable to the data in this usecase
msg2
}
// Test with some sample data
def main(args: Array[String]): Unit = {
// Mask log
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
val spark: SparkSession = SparkSession
.builder
.appName(s"${this.getClass.getSimpleName}")
.master("local[1]")
.getOrCreate()
val sc = spark.sparkContext
// RDD to DF, implicit conversion
import spark.implicits._
val empData = Array(
// If there is no top-level parent node in the test, a null pointer exception will occur. When building the graph, a null vertex will be generated according to the edge
("EMP001", "Bob", "Baker", "CEO", null.asInstanceOf[String])
, ("EMP002", "Jim", "Lake", "CIO", "EMP001")
, ("EMP003", "Tim", "Gorab", "MGR", "EMP002")
, ("EMP004", "Rick", "Summer", "MGR", "EMP002")
, ("EMP005", "Sam", "Cap", "Lead", "EMP004")
, ("EMP006", "Ron", "Hubb", "Sr.Dev", "EMP005")
, ("EMP007", "Cathy", "Watson", "Dev", "EMP006")
, ("EMP008", "Samantha", "Lion", "Dev", "EMP007")
, ("EMP009", "Jimmy", "Copper", "Dev", "EMP007")
, ("EMP010", "Shon", "Taylor", "Intern", "EMP009")
// Null pointers have nothing to do with duplicate vertex data
// The null pointer is related to the fact that the parent node cannot be found in the vertex (it doesn't matter if the parent vertex is null, so the parent vertex needs to be found in the vertex list)
, ("EMP011", "zhang", "xiaoming", "CTO", null)
)
// create dataframe with some partitions
val empDF = sc.parallelize(empData, 3)
.toDF("emp_id","first_name","last_name","title","mgr_id")
.cache()
// primary key , root, path - dataframe to graphx for vertices
val empVertexDF = empDF.selectExpr("emp_id","concat(first_name,' ',last_name)","concat(last_name,' ',first_name)")
// parent to child - dataframe to graphx for edges
val empEdgeDF = empDF.selectExpr("mgr_id","emp_id").filter("mgr_id is not null")
// call the function
val empHirearchyExtDF: DataFrame = calcTopLevelHierarcy(empVertexDF,empEdgeDF)
.map{ case(pk,(level,root,path,iscyclic,isleaf)) => (pk.asInstanceOf[String],level,root.asInstanceOf[String],path,iscyclic,isleaf)}
.toDF("emp_id_pk","level","root","path","iscyclic","isleaf").cache()
// extend original table with new columns
val empHirearchyDF = empHirearchyExtDF.join(empDF , empDF.col("emp_id") === empHirearchyExtDF.col("emp_id_pk"))
.selectExpr(
"emp_id","first_name","last_name",
"title","mgr_id",
"level",
"root",
"path",
"iscyclic","isleaf"
)
// print
empHirearchyDF.show()
}
}
output

Task execution
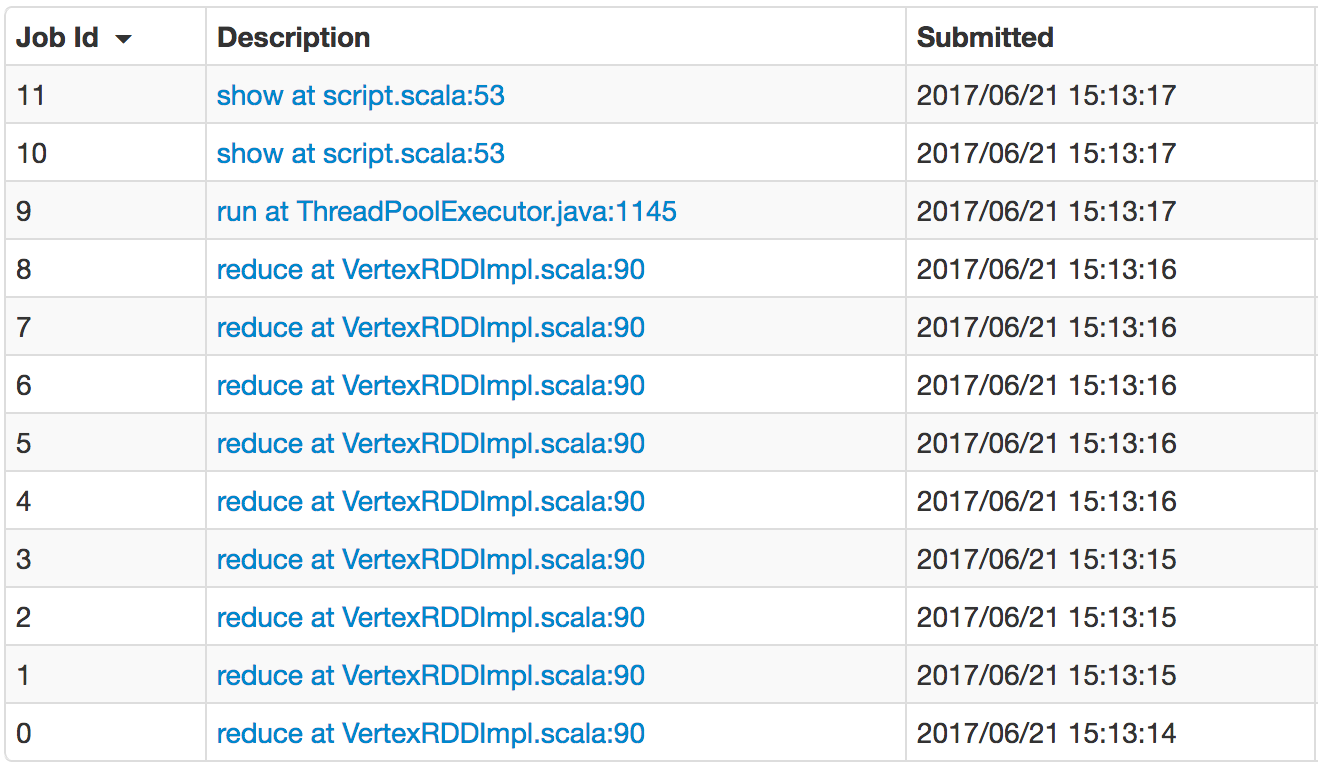
Spark jobs are broken down into jobs, phases and tasks. Because of its iterative nature, the Pregel API generates multiple jobs internally. A job is generated each time a message is delivered to a vertex. Since the data may be located on different nodes, each job may end with multiple shuffle s.
Note the long RDD lineage created when working with large datasets.
generalization
The Graphx Pregel API is very powerful and can be used to solve iterative problems or any graphical computing.