Fast padding of Nd array
In batch training of deep learning, it is often encountered that the length of input samples is not the same, such as time series, or the dimension of each sample in ffm is not the same. There are three solutions I know. The first one is to truncate the sample, the second one is to sample up or down, and the third one is to add zero to the sample. The third is called padding. The specific method is to set a maximum length maxlen (it is usually the longest length of each batch sample, or the longest length of all samples), and then fill zero after each sample to make the length of each sample equal.
Two methods of padding
In the presence of Here Two implementations of padding are found, as follows. The first one is to map each sample in lst, and the second one is to define a full 0 matrix whose width is the target length, and then fill in each sample in turn.
# Achieve one
def pad_list(lst):
inner_max_len = max(map(len, lst))
map(lambda x: x.extend([0]*(inner_max_len-len(x))), lst)
return np.array(lst)# Achieve two
def apply_to_zeros(lst, dtype=np.int64):
inner_max_len = max(map(len, lst))
result = np.zeros([len(lst), inner_max_len], dtype)
for i, row in enumerate(lst):
for j, val in enumerate(row):
result[i][j] = val
return resultThe speed of two padding methods
in order to compare the processing speed of the two methods, several sequences of different lengths are randomly generated, and two functions are called respectively for processing.
ns = range(5,10005,100)
np.random.seed(233)
time_consumption = []
for n in ns:
lens = np.random.randint(low=5,high=10,size=(n,))
sequences = [range(l) for l in lens]
start = time.time()
pad_list(sequences)
end = time.time()
# print "cost {0} sec".format(end-start)
time_consumption.append([end-start])
lens = np.random.randint(low=5,high=10,size=(n,))
sequences = [range(l) for l in lens]
start = time.time()
apply_to_zeros(sequences)
end = time.time()
# print "cost {0} sec".format(end-start)
time_consumption[-1].append(end-start)
if n% 100 == 0:
print n
time_consumption = np.array(time_consumption)
plt.plot(ns, time_consumption[:,0],label="pad_list")
plt.plot(ns, time_consumption[:,1],label="apply_to_zeros")
plt.xlabel("sample_size")
plt.ylabel("seconds")
plt.legend()
plt.show()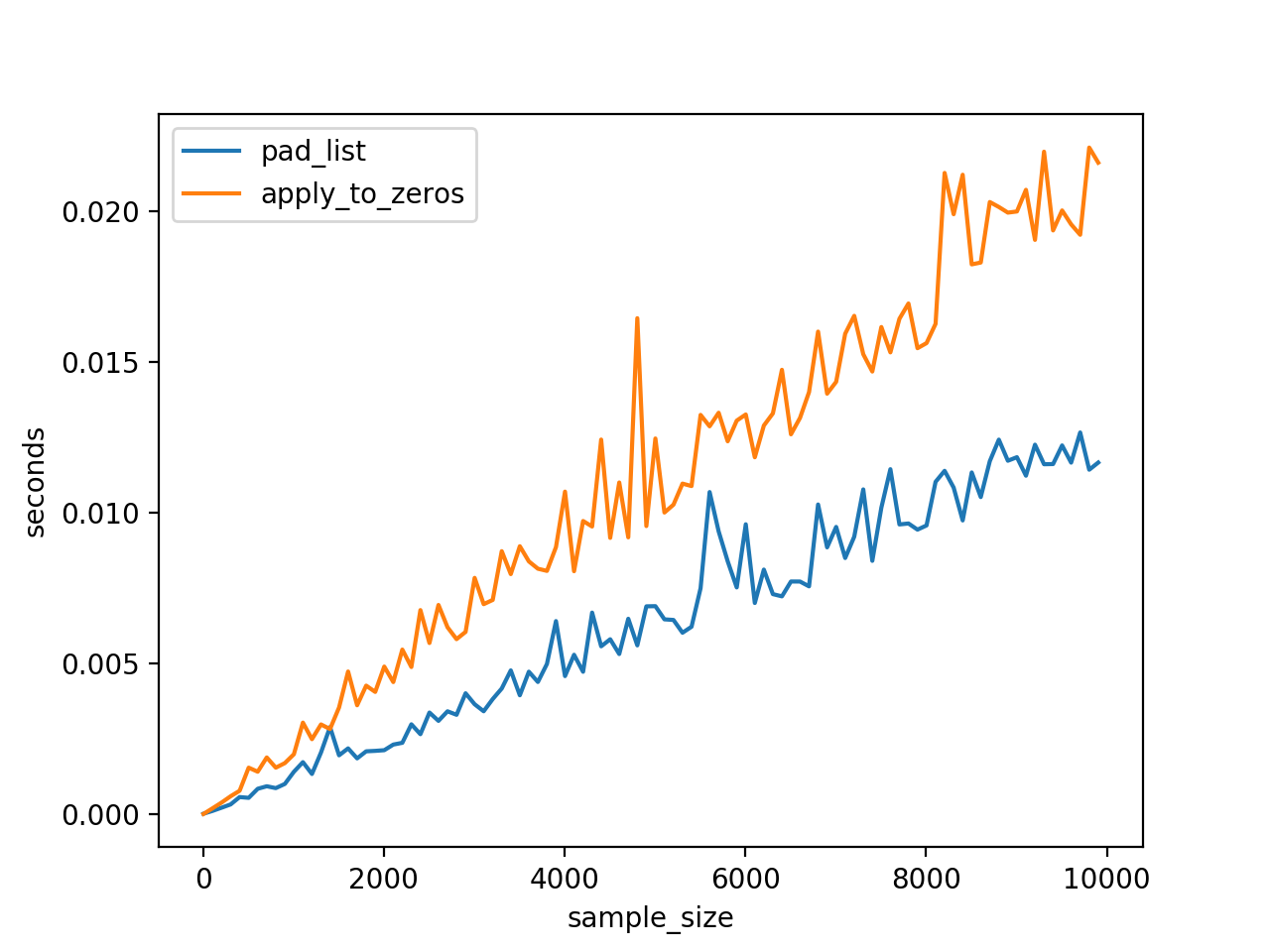
The results show that the first method is faster.