https://github.com/pdfminer/pdfminer.six
Extract files after downloading
Due to the processing of Chinese files, precompiling is required
To work with the CJK language, do the following before running setup.py install:
mkdir pdfminer\cmap
python tools\conv_cmap.py -c B5=cp950 -c UniCNS-UTF8=utf-8 pdfminer\cmap Adobe-CNS1 cmaprsrc\cid2code_Adobe_CNS1.txt python tools\conv_cmap.py -c GBK-EUC=cp936 -c UniGB-UTF8=utf-8 pdfminer\cmap Adobe-GB1 cmaprsrc\cid2code_Adobe_GB1.txt python tools\conv_cmap.py -c RKSJ=cp932 -c EUC=euc-jp -c UniJIS-UTF8=utf-8 pdfminer\cmap Adobe-Japan1 cmaprsrc\cid2code_Adobe_Japan1.txt python tools\conv_cmap.py -c KSC-EUC=euc-kr -c KSC-Johab=johab -c KSCms-UHC=cp949 -c UniKS-UTF8=utf-8 pdfminer\cmap Adobe-Korea1 cmaprsrc\cid2code_Adobe_Korea1.txt python setup.py install
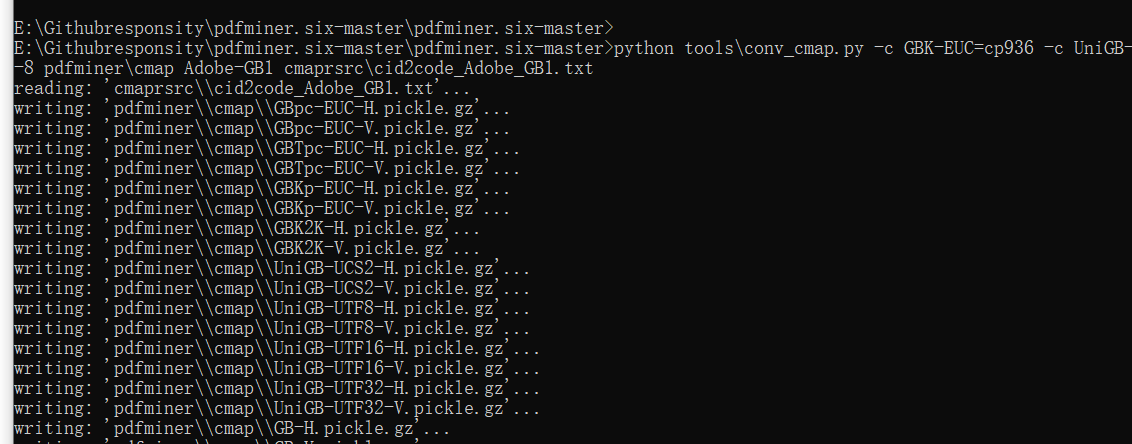
It's just being implemented, isn't it
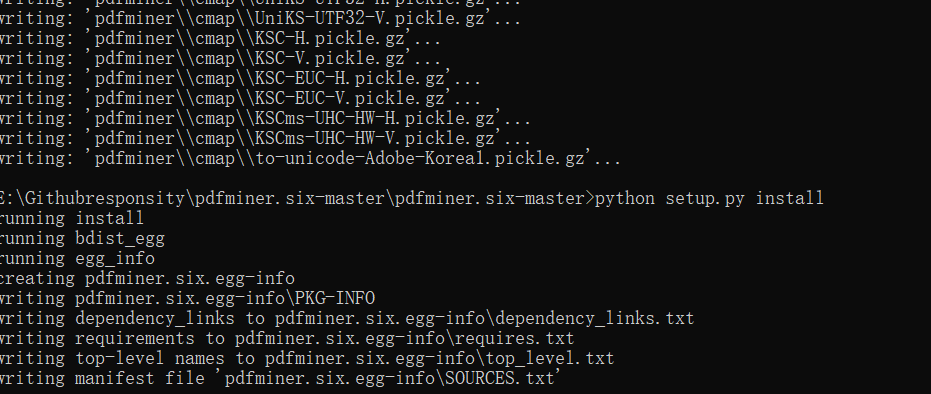
After Chinese, Japanese and Korean characters are compiled, start setup
Success! 20181108 version

At last. Great.
The required documents are
import argparse
import logging
import six
import sys
import pdfminer.settings
pdfminer.settings.STRICT = False
import pdfminer.high_level
import pdfminer.layout
from pdfminer.image import ImageWriter
def extract_text(files=[], outfile='-',
_py2_no_more_posargs=None, # Bloody Python2 needs a shim
no_laparams=False, all_texts=None, detect_vertical=None, # LAParams
word_margin=None, char_margin=None, line_margin=None, boxes_flow=None, # LAParams
output_type='text', codec='utf-8', strip_control=False,
maxpages=0, page_numbers=None, password="", scale=1.0, rotation=0,
layoutmode='normal', output_dir=None, debug=False,
disable_caching=False, **other):
if _py2_no_more_posargs is not None:
raise ValueError("Too many positional arguments passed.")
if not files:
raise ValueError("Must provide files to work upon!")
# If any LAParams group arguments were passed, create an LAParams object and
# populate with given args. Otherwise, set it to None.
if not no_laparams:
laparams = pdfminer.layout.LAParams()
for param in ("all_texts", "detect_vertical", "word_margin", "char_margin", "line_margin", "boxes_flow"):
paramv = locals().get(param, None)
if paramv is not None:
setattr(laparams, param, paramv)
else:
laparams = None
imagewriter = None
if output_dir:
imagewriter = ImageWriter(output_dir)
if output_type == "text" and outfile != "-":
for override, alttype in ( (".htm", "html"),
(".html", "html"),
(".xml", "xml"),
(".tag", "tag") ):
if outfile.endswith(override):
output_type = alttype
if outfile == "-":
outfp = sys.stdout
if outfp.encoding is not None:
codec = 'utf-8'
else:
outfp = open(outfile, "wb")
for fname in files:
with open(fname, "rb") as fp:
pdfminer.high_level.extract_text_to_fp(fp, **locals())
return outfp
The experience of this time is that we should pay more attention to the source code and find out the version problem. We can't just transfer packets and go deep into the code research principle. Look at GitHub frequently. Most of the content in China is directly copied from foreign open source content