introduction
In my opinion, genetic algorithm is an algorithm that can be considered when adjusting parameters. It is a method that can find the global optimal parameters. When the data range that needs to be adjusted is large, the exhaustive method is obviously not a good choice! Here, the genetic algorithm is implemented through a simple example.
introduce
By simulating the evolution of survival of the fittest in nature, genetic algorithm abstracts the problem to be solved into a genetic evolution problem, maps the search space into genetic space, encodes the possible solution into a vector (chromosome), and each element in the vector becomes a gene. By constantly calculating the fitness value of each chromosome, it selects the best chromosome, Constantly select evolution and constantly approach the optimal solution we need.
I will first introduce the basic operation steps of genetic algorithm, and explain how to abstract our problems into the genetic algorithm itself.
Basic steps of genetic algorithm
- Selection operation
- Exchange operation
- variation
Select operation
Significance: select chromosomes with high fitness from the old population to prepare for future chromosome exchange and mutation to produce new chromosomes.
This step is the concrete realization of the survival of the fittest, and there are many ways to choose, such as rotation method, elite method and so on.
What exactly does that mean? That is, for example, if you create a group of people, you need a way to decide what conditions they can meet to survive. If you set the top 1/n in the team, the strong can survive, then your way is called the elite method, and only the strong can survive; If you set the greater the strength, the greater the probability of survival, rather than the absolute strength to survive, then this is called the rotation method, which is equivalent to your choice in turning the turntable. The more area (strong) you occupy, the greater the probability of being selected to survive!
The strength of this example is great. We call it the goal of the fitness function. You can decide to grow tall as the goal of the fitness function. Then, the tall nature is an important indicator for us to determine whether they survive, and the fitness function is a function of evaluating their strength with existing conditions (colorants). A group of people here refers to the number of chromosomes. You can set 10 people or 100 people. The more people you set, the richer the chromosomes will be. Of course, it will bring computational complexity.
Therefore, here we need to determine the parameters: chromosome number fitness function selection strategy
As in the previous example, we use the rotation method to make a selection operation:
If we set a group of people as 6 people, we have 6 chromosomes (false setting, don't ask why a person has one chromosome...), and we determine whether they survive through great strength. The greater the strength, the greater the probability of survival!
Here, the composition of chromosomes is composed of human characteristics: such as male or female, fat or thin, which are converted into the current binary according to a certain mapping relationship.
The fitness function here assumes that the strength value under the influence of various characteristics of the chromosome can be obtained according to some calculation and the binary composition of the chromosome.
| Serial number | chromosome | Fitness value | Cumulative | Convert to percentage |
|---|---|---|---|---|
| 1 | 110100 | 20 | 20+0 | 20/67=0.298=29.8% |
| 2 | 010010 | 05 | 20+5=25 | 5/67=0.074=7.4% |
| 3 | 001100 | 12 | 25+12=37 | 12/67=0.179=17.9% |
| 4 | 110011 | 30 | 37+30=67 | 30/67=0.447=44.7% |
Explain why there are two items: cumulative and percentage. This is mainly for the programming implementation of rotation method. As follows:
So that subsequent rotation can select chromosomes according to the area of fitness
Therefore, the selection method is as follows:
Randomly generate a number n, the range of which is 0 < n < the cumulative maximum value of fitness function (67 here), and then select the chromosome whose cumulative value is greater than or equal to N. for example, if the random number is 35, the selected chromosome is No. 3, because the cumulative value of No. 3 is 37 > 35. If the random number is 44, the selected chromosome is No. 4. In this way, you can select chromosomes until you reach the initial population size you set.
Exchange operation
The exchange operation simulates chromosome exchange and exchanges the genes on the chromosome according to certain rules to achieve the purpose of chromosome innovation.
Methods: single point crossing and multi-point crossing.
For example, a simple single point intersection is used here, and the location is selected as 1 / 2 node.
Selected chromosome:
Paternal chromosome 1:110 | 100
Parent chromosome 2: 010 | 010
The position marked in yellow above is the exchange position, and then exchange:
Daughter chromosome 1:110 | 010
Daughter chromosome 2: 010 | 100
variation
Mutation operation simulates the mutation of biological genes. In chromosome binary coding, the operation of mutation is, 1 becomes 0; Or 0 becomes 1.
Mutation produces chromosome diversity, avoids early maturation in evolution, falls into local extreme points, and the probability of mutation is very low.
This depends on your own
Simple implementation of genetic algorithm
Here, let's find the maximum value of a function.
The function is: y=1/2*x+sin(3x), and the range is x ∈ [1-9]
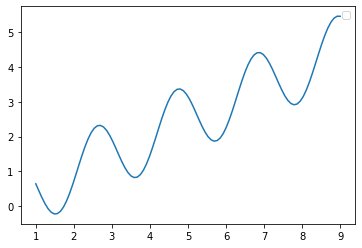
It can be seen that there will be multiple maxima of this function, which is what we often call the local optimality.
Therefore, according to the steps, we must first determine its fitness function, population size and selection strategy.
Fitness function: because we seek the maximum value of the function here, the goal of the fitness function here is to seek the maximum value, and the fitness function is the function itself!
Population size: set to 100 here
Selection strategy: rotation method
After the above values are determined, we need to establish the binary code corresponding to the function x value:
be careful
Explain why to convert to binary:
The two-level system has a larger search range and more schemas than the decimal system, and the operation is simpler.
If we set the solution accuracy to 4 digits after the decimal point, how many binary digits do we need to represent us?
The following formula is given:
Where l is the number of binary digits and m is the precision
2
l
>
=
(
U
m
a
x
−
U
m
i
n
)
∗
1
0
m
2^l >= (U_{max} - U_{min})*10^m
2l>=(Umax−Umin)∗10m
Therefore, if we need four decimal places, we need at least 17 binary digits
2
17
=
131072
>
=
(
9
−
1
)
∗
1
0
4
=
80000
2^{17}=131072 >= (9 - 1)*10^4=80000
217=131072>=(9−1)∗104=80000
Through this expression, we can also calculate its accuracy
The accuracy calculation formula is given here:
Precision Q
Q
=
(
U
m
a
x
−
U
m
i
n
)
/
2
l
−
1
Q = (U_{max} - U_{min})/2^{l} - 1
Q=(Umax−Umin)/2l−1
Precision results
Q
=
(
9
−
1
)
/
2
17
−
1
=
6.103515625
e
−
05
Q = (9 - 1)/2^{17} - 1 = 6.103515625e-05
Q=(9−1)/217−1=6.103515625e−05
The smaller the precision, the better, of course, but it brings huge binary digits, which is very troublesome to calculate.
Therefore, we need the following steps to carry out our algorithm:
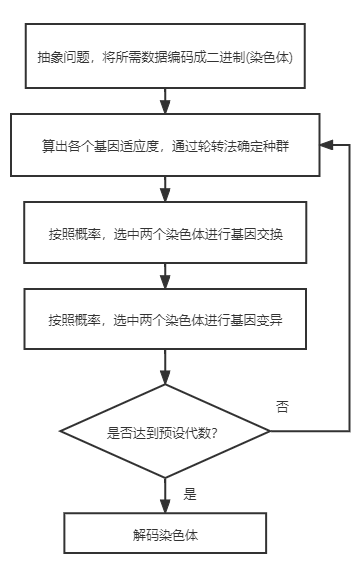
Result analysis
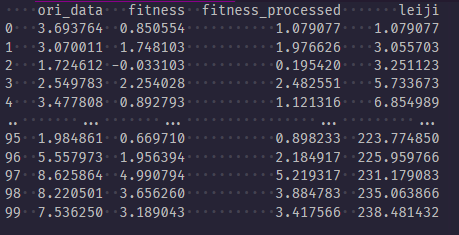
This is a dataframe when calculating the fitness. Because the fitness function has a negative number, the method adopted here is to raise the whole up (all plus the absolute value of the largest negative number). This is a way to deal with the fitness function as a negative number.
This is the best advantage selected by the final program (the red dot on the picture). You can see that the result is very good.
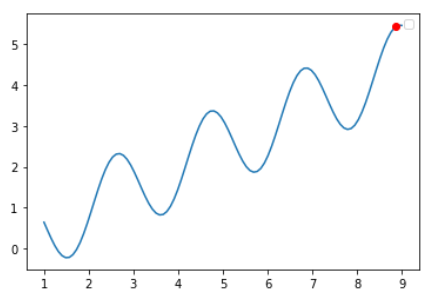
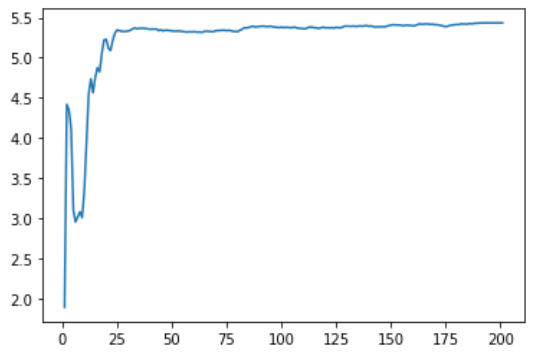
The following figure shows the change of population average adaptation value with the increase of genetic algebra. It can be seen that it has actually begun to converge in about 25 generations.
Program source code
# -*- encoding: utf-8 -*-
'''
@Description: An example of genetic algorithm
@Date :2021/10/27 14:57:16
@Author :willpower
@version :V1.0
'''
#%%
import numpy as np
from numpy.lib.function_base import average
import pandas as pd
import matplotlib.pyplot as plt
import random
zhongqun_cnt = 100 # Chromosome number of population
p_jiaohuan = 60 # The probability of exchange is 60%
p_bianyi = 10 # The probability of variation is 10%
x_min = 1 # The minimum argument is 1
x_max = 9 # The maximum independent variable is 9
rotate_cnt = 200 # Genetic algebra
#%%
# Define function expression
def calc(x):
return 1/2*x+np.sin(3*x)
#%%
# Define a mapping function to map the specified range of decimal to binary
# (not a simple mapping, but the same stretch) this is a scale problem
def dec2bin(x):
return bin(int((2**17)*((x-1)/8)))
# Contrary to the above function
def bin2dec(x):
x1 = int(x, 2)
return x1/(2**17)*8+1
#%%
# Show the whole graph first
x = np.linspace(x_min,x_max,100)
y = calc(x)
plt.plot(x, y)
plt.legend()
plt.show()
# %%
# 0-1
# 2^17-9
#The Zhongqun to be used in the initial rotation method is randomly selected_ CNT gene
init_population = np.random.uniform(x_min,x_max,zhongqun_cnt)
# %%
# Fitness function
def fitness(x):
return calc(x)
#%%
# Select the function and select Zhongqun through the rotation method_ CNT initial population
# The input is the random previous generation, and the output is the gene selected by the rotation method (hexadecimal)
def select(x):
data = pd.DataFrame(x, columns=['ori_data'])
data['fitness'] = fitness(data['ori_data'])
# Because the fitness has a negative number, I move up as a whole and make it all positive (move up the lowest negative number)
data['fitness_processed'] = data['fitness'] + abs(data['fitness'].min())
# Add accumulation, and pay attention to the left closing and right opening
data['leiji'] = [sum(data['fitness_processed'][0:i]) for i in range(1, data.shape[0] + 1 )]
print(data)
# Start selection and randomly generate the random number with the cumulative value in the range of 0-(zhongqun_cnt-1), and take
# The number corresponding to the cumulative number greater than or equal to the random number. In this way, Zhongqun is taken_ CNT
select_dict = []
while len(select_dict) < data.shape[0]:
suijishu = np.random.uniform(data['leiji'][0], data['leiji'][data.shape[0] - 1], 1)[0]
print(suijishu)
xuanzeshu = data[data['leiji'] >= suijishu]['ori_data'].iloc[0]
print(xuanzeshu)
select_dict.append(xuanzeshu)
return select_dict
# For gene exchange operation, single point exchange is adopted here because the binary is 17 bits
# So here we randomly exchange the middle of the two genes
# The input is the two genes to be exchanged, and the output is the two genes to be exchanged (binary input)
def exchangge(x, y, div = 0.5):
weishu = len(x) - 2
# Subtract 2 because 0b will occupy 2 positions
percent = int(div * weishu)
# Start combination
x1 = x[:2+percent] + y[-(weishu-percent):-1] + y[-1]
# print(x1)
y1 = y[:2+percent] + x[-(weishu-percent):-1] + x[-1]
# print(y1)
return x1, y1
# For gene mutation operation, random inversion is adopted here
# Input is binary
#%%
def variation(x, y):
x1 = x[:-1] + str((int(x[-1]) + 1)%2)
print(x1)
y1 = y[:-1] + str((int(y[-1]) + 1)%2)
print(y1)
return x1, y1
# Probability execution function
def random_run(probability):
"""with probability%Probabilistic execution func(*args)"""
list = []
for i in range(probability):
list.append(1)#Put probability 1 in the list
for x in range(100 - probability):
list.append(0)#Put the remaining positions into 0
a = random.choice(list)#Take one at random
return a
#%%
# Main function
# Determine the initial population
selected = select(init_population)
# Start to enter the 30 rounds of survival of the fittest
average_genes = []
average_genes.append(fitness(average(selected)))
while rotate_cnt:
rotate_cnt -= 1
# Probability exchange
index_x = random.randint(0, 19)
index_y = random.randint(0, 19)
# If you win, swap
if random_run(p_jiaohuan):
x1, y1 = exchangge(dec2bin(selected[index_x]), dec2bin(selected[index_y]))
selected[index_x], selected[index_y] = bin2dec(x1), bin2dec(y1)
# Probability variation (variation if selected)
index_x = random.randint(0, 19)
index_y = random.randint(0, 19)
if random_run(p_bianyi):
x2, y2 = variation(dec2bin(selected[index_x]), dec2bin(selected[index_y]))
selected[index_x], selected[index_y] = bin2dec(x2), bin2dec(y2)
# Select again
selected = select(selected)
average_genes.append(fitness(average(selected)))
#%%
plt.plot(list(range(1, len(average_genes) + 1)),average_genes)
# %%
# Print out the position of the best point and have a look
x = np.linspace(x_min,x_max,100)
y = calc(x)
plt.plot(x, y)
plt.plot(average(selected), fitness(average(selected)), marker='o', color='red')
plt.legend()
plt.show()
epilogue
The description may not be very clear, mainly because there are too many variable things in genetic algorithm, such as selection method, exchange method, mutation method and so on. Therefore, there is no absolute best. The deeper you understand the problem itself, the better you can abstract the problem to genetic algorithm! In addition, only when you seriously implement the genetic algorithm, will you find that its core principle is not difficult to understand. Therefore, if you want to design this algorithm, you'd better write it.
reference resources
How to explain genetic algorithm easily? What are some examples?
Python: executes a function with a specified probability.