Experience of QL optimization with twists and turns
background
Recently, I received an SQL tuning task, which performs nearly five seconds in a month of data statistics in the development environment. Originally thought it was a smooth optimization, but I didn't expect that in order to get the best result, it went through twists and turns.
First impression
- Initial slow SQL
select case when sum(n_xsajs) is null then 0 else sum(n_xsajs) end as value ,ay.c_aymc as name,ay.c_aydm as id, case when tbdata.tb is null then 0 else
round( cast ( sum(n_xsajs) - tbdata.tb as numeric )/ cast( tbdata.tb as numeric),2)*100 end as tb, case when sum(n_xsajs) < tbdata.tb then -1 when sum(n_xsajs)
> tbdata.tb then 1 else 0 end as tbTag, case when hbdata.hb is null then 0 else round( cast ( sum(n_xsajs) - hbdata.hb as numeric )/ cast( hbdata.hb as
numeric),2)*100 end as hb, case when sum(n_xsajs) < hbdata.hb then -1 when sum(n_xsajs) > hbdata.hb then 1 else 0 end as hbTag
from db_zntsfx.t_xsaj_ay aj
right join ( select c_aydm,c_aymc from db_zntsfx.d_ay ay WHERE ay.c_aylb = '14' ) ay
on aj.c_aydm = ay.c_aydm
left join ( select sum(n_xsajs) tb,ay.c_aydm
from db_zntsfx.t_xsaj_ay aj
right join ( select c_aydm,c_aymc from db_zntsfx.d_ay ay WHERE ay.c_aylb = '14' ) ay
on aj.c_aydm = ay.c_aydm and substr(aj.c_fydm,0,2)= '3' and aj.c_tjq >= '201608' and aj.c_tjq <= '201608'
GROUP BY ay.c_aymc,ay.c_aydm ) tbdata
on aj.c_aydm = tbdata.c_aydm
left join ( select sum(n_xsajs) hb,ay.c_aydm
from db_zntsfx.t_xsaj_ay aj
right join ( select c_aydm,c_aymc from db_zntsfx.d_ay ay WHERE ay.c_aylb = '14' ) ay
on aj.c_aydm = ay.c_aydm and substr(aj.c_fydm,0,2) = '3' and aj.c_tjq >= '201707' and aj.c_tjq <= '201707'
GROUP BY ay.c_aymc,ay.c_aydm ) hbdata
on aj.c_aydm = hbdata.c_aydm and substr(aj.c_fydm,0,2) = '3' and aj.c_tjq >= '201708' and aj.c_tjq <= '201708'
GROUP BY ay.c_aymc,ay.c_aydm,tbdata.tb,hbdata.hb limit 17 offset 1The original slow SQL was initially formatted.
But there are three reasons for manual formatting:
- The original formatted level of SQL is still unclear
- Manual formatting is the process of understanding the meaning of SQL business
- Tool automatic formatting is only indented according to keywords, which is not conducive to the presentation of the SQL level.
After SQL Formatting
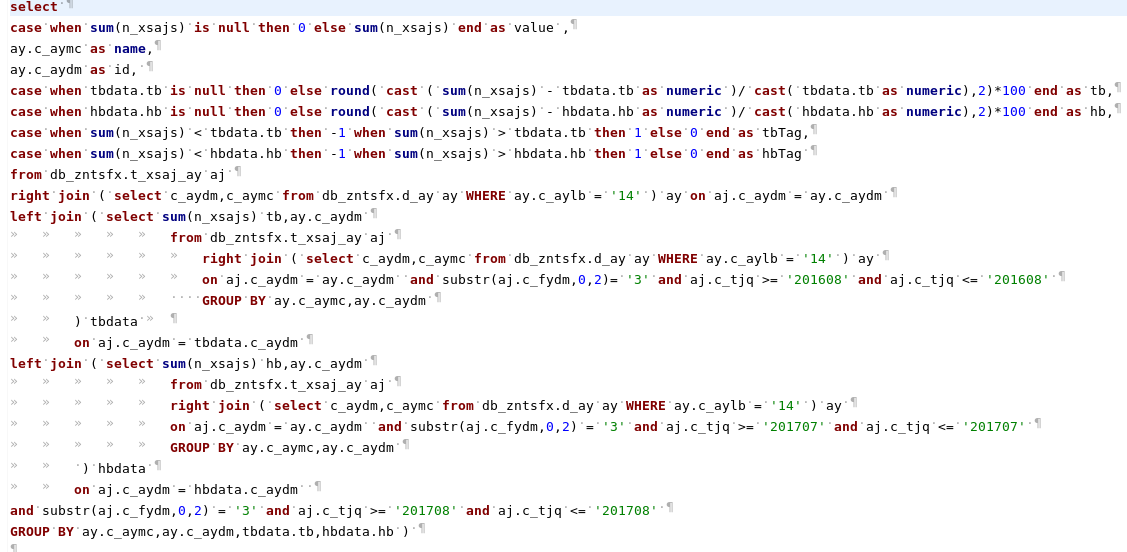
After formatting, it can be clearly seen that the business of SQL is "to count the number of new criminal cases received by type 14 in August and to compare the same number of cases with each other".
The main problems of SQL are:
- The execution speed is slow and the development environment is 4 seconds.
- The SQL body has a lot of repetition, repetitive sub-queries and group by.
- The index column uses a function, substr(aj.c_fydm,0,2) ='3'.
- The results of SQL statistics are incorrect, and the cases aggregated according to the cases are repetitive.
--Verification SQL
select t.id,t.name,count(*) from (
--primarySQL
) t group by t.id,t.name having count(*)>1
Verification results:
| id | name | count |
|---|---|---|
| 0E0401540000 | Disputes over rural land contract | 2 |
| 0E1014000000 | The third party withdraws the lawsuit | 2 |
| 0E0601010500 | Disputes over recourse for labour remuneration | 2 |
| 0E1003010000 | Apply for declaration of citizen's incapacity for civil conduct | 2 |
| 0E0901000000 | Disputes over tort liability | 2 |
| 0E0401551500 | Disputes over property service contracts | 2 |
| 0E0802080000 | Disputes over Share Transfer | 2 |
| 0E0201030000 | Property disputes after divorce | 2 |
| 0E0201020000 | divorce dispute | 2 |
| 0E1013010000 | Execution of objection by outsiders | 2 |
| 0E0401350900 | Contracts Disputes in Rural Housing Construction | 2 |
First tuning
- View the database version
db_zntsfx=# select version();
version
---------------------------------------------------------------------------------------------------
PostgreSQL 9.5.4 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.4.7 20120313 (Red Hat 4.4.7-16), 64-bit
(1 row)- With statement rewrites SQL, because abase 3.5.3 is used, so I want to try to use with grammar to solve the problem of duplication of SQL structure.
Rewritten SQL

- View execution plans and speed
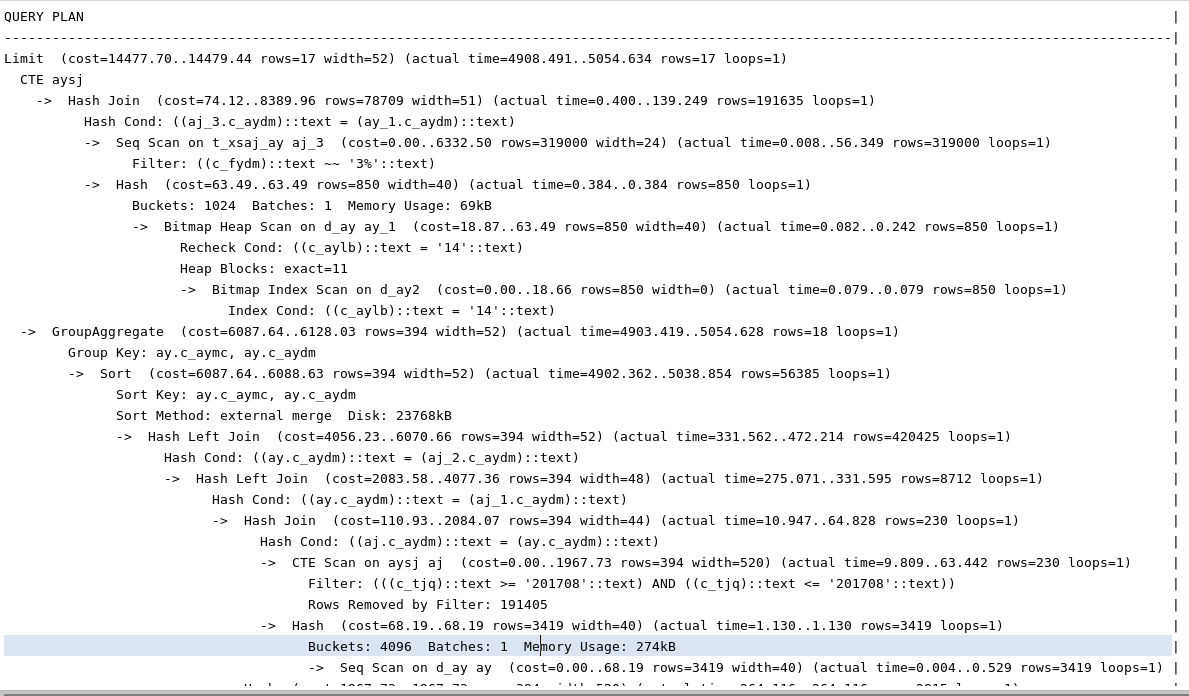
- Result
1. The structure of the SQL statement is still unclear, and the complexity is almost the same as before.
2.SQL runs slower than before, nearly 6 seconds. The main reason is that the result set of with statement can not be filtered by month, and the result set of subsequent operation is too large.
Second tuning
- Rewrite SQL

- View the execution plan
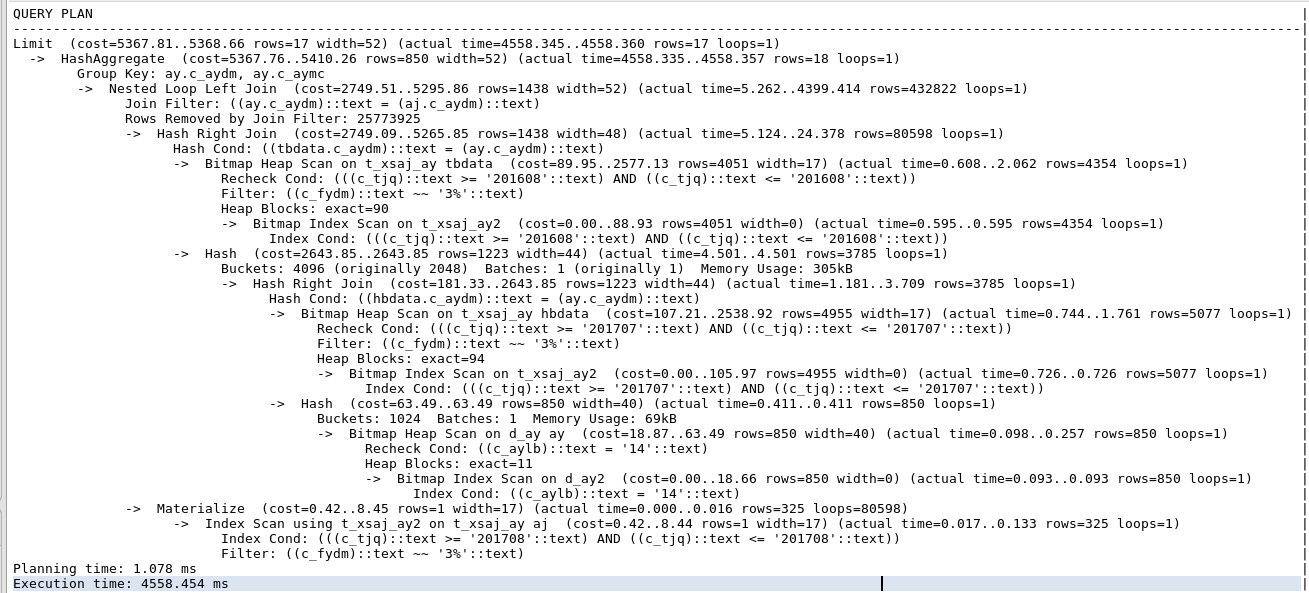
- Result
- The level of SQL statements is much clearer and the execution speed is the same as before.
- According to "Database Selection Index Exploration I", combination or coverage index will speed up the execution of SQL and add coverage index.
create index i_ay_zh01 on db_zntsfx.d_ay(c_aydm, c_aymc);
create index i_xsay_zh01 on db_zntsfx.t_xsaj_ay(c_aydm, c_tjq, c_fydm, n_xsajs);- Look at the implementation plan again
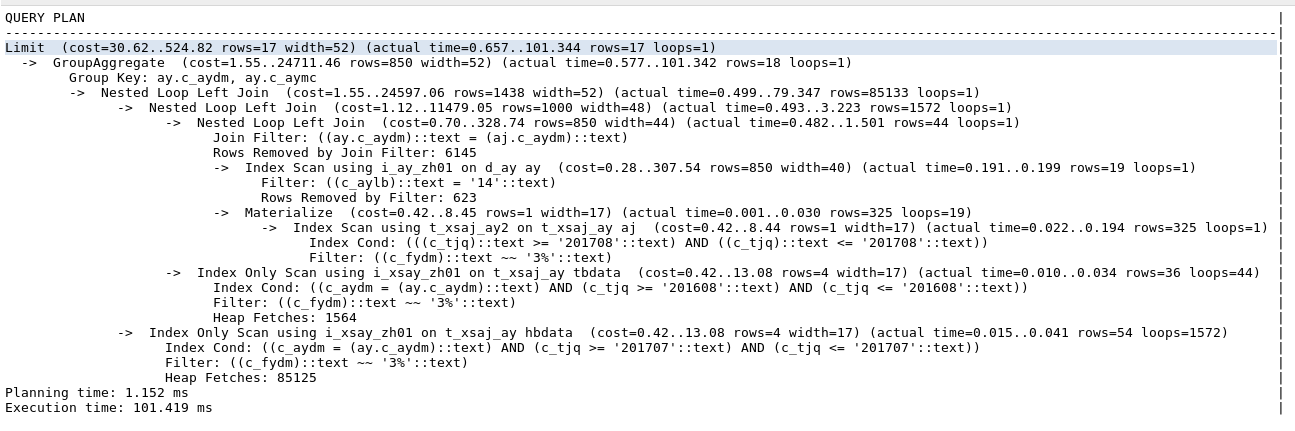
The execution time of SQL is 100ms
- Correctness of preliminary investigation results
select id,name,count(*) from (
--Second rewriteSQL
) t group by t.id,t.name having count(*) >1
Verification results:
| id | name | count |
|---|---|---|
No duplicate case statistics
Third tuning
- Doubts about the correctness of statistical results
Just when I thought I had found a perfect solution to both clarity and efficiency of SQL, Liu Guoming, the DBA team, questioned the correctness of the query results.
Brother Guoming thought that group by should be followed by left join.
- Verification process
The data of current, year-on-year and ring-on-ring cases of one kind of cause are taken separately.
1. Computing the comparative ring data of "disputes over the right to use homestead" with SQL after the second transformation.
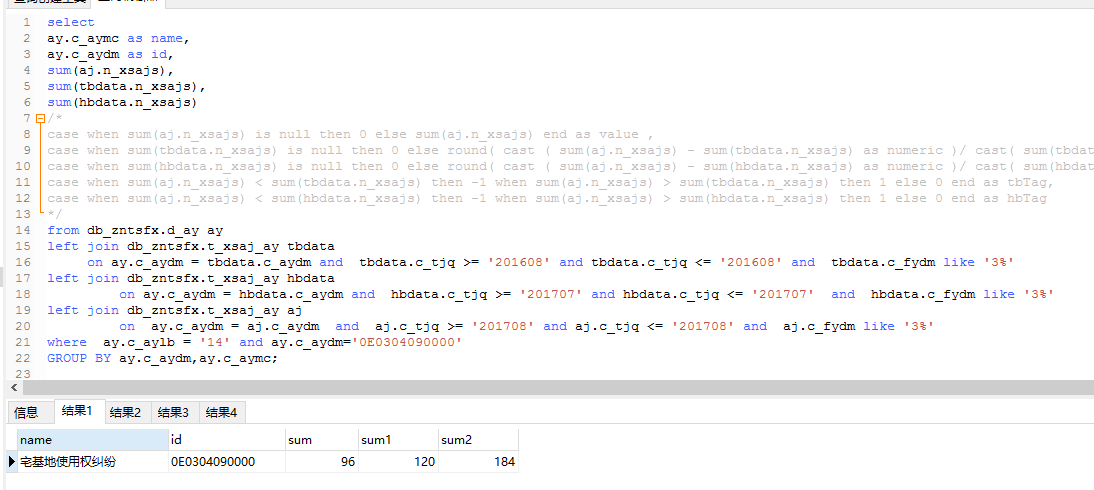
2. New SQL calculates the comparative ring data of "disputes over the right to use homestead" separately.
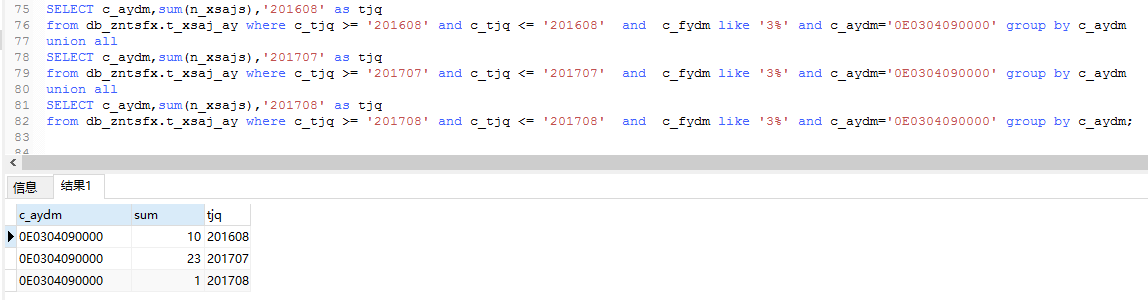
- Verification results
The statistical results of "Perfect SQL" after rewriting are incorrect
- Reflect
Why is the rewritten SQL statistics wrong?
Answer: Looking at the execution plan of SQL, we find that the reason for the statistical errors in SQL rewriting is that we assume that the year-to-year, ring ratio and current monthly data are connected to the main table d_ay separately, but they are not. In fact, the main table first does Cartesian product with the current monthly result set, then Cartesian product with the same comparative data, and Cartesian product with the new set and the ring ratio data. Causes data duplication.
Correct SQL
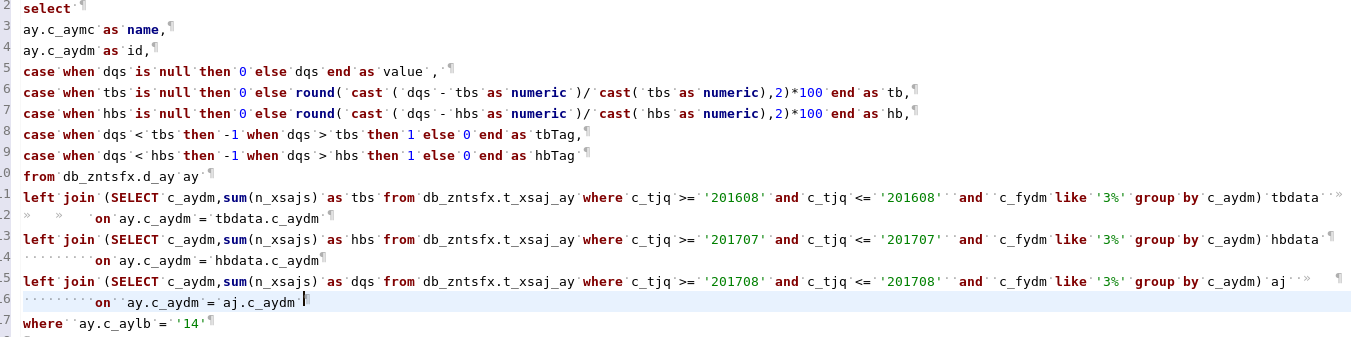
Correct implementation plan
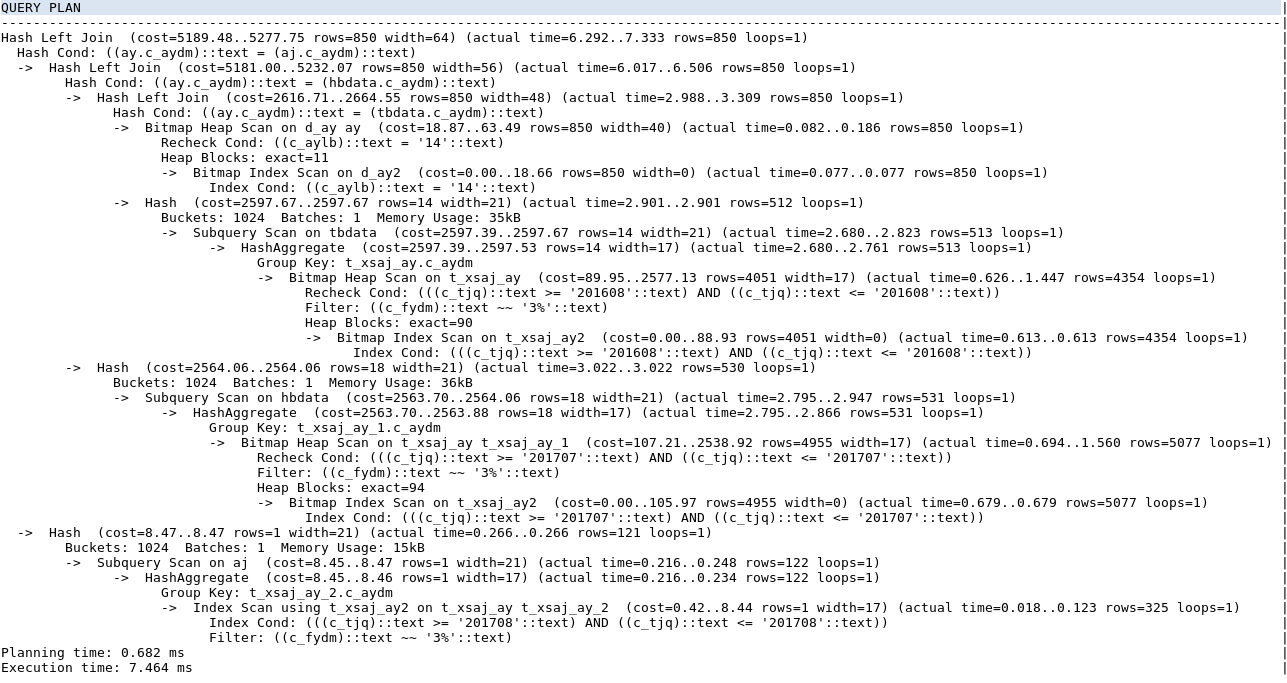
SQL execution time: less than 10ms (development environment)
summary
- In the process of SQL optimization, it is necessary to format SQL, understand business, view execution plan, try index, rewrite SQL and even redesign table structure. It takes one or more times to achieve the required performance standards.
- For the join order of tables, don't take it for granted that SQL is executed in the order it was written. At the same time, the platform of SQLFX finds that there are more than four tables joined in the SQL of many projects. With the increase of data, the Cartesian product of these SQLs will increase exponentially, resulting in the shortage of CPU and IO resources. Hope that the project team can pay attention to these potential performance problems of SQL, hope that SYBASE switch to ABASE, the performance improvement brought by database platform upgrade will not be offset by slow SQL in the program, hope that "Andy Bill Theorem" will not happen around us.