Guide: in In the Spark Streaming document Documents can be roughly divided into: Transformations,Window Operations,Join Operations,Output Operations operation
Article directory
This article illustrates my code cloud Through train
Please get some basic information:
DStream is the basic abstraction provided by Spark Streaming. It represents a continuous data stream, either the input data stream received from the source or the processed data stream generated by transforming the input stream. Internally, DStream is represented by a series of consecutive RDDs, which is Spark's abstraction of immutable distributed data sets. Each RDD in DStream contains data from a specific time interval, as shown in the following figure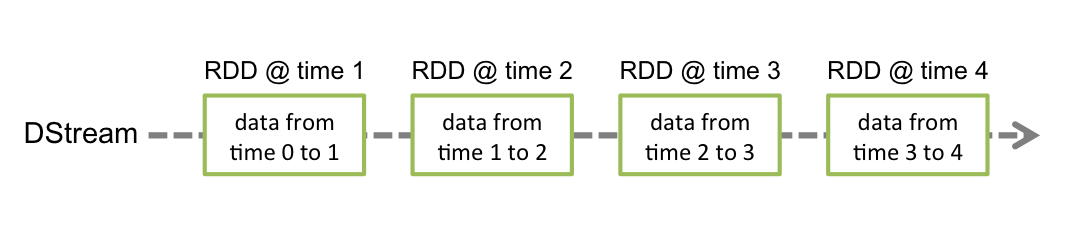
Transformations
1) map(func), which acts func functions on each element and generates a new element, resulting in a new Stream object containing these new elements.
Code
object Map {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val mapLines = lines.map(word => "map_" + word)
mapLines.print()
ssc.start()
ssc.awaitTermination()
}
}
Result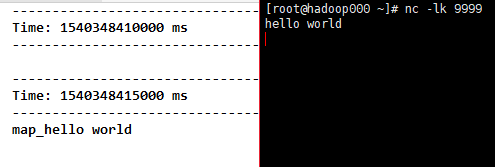
2) flatMap(func), which acts func functions on each element and generates 0 or more new elements (for example, split below generates >= 0 new elements), and obtains a new DStream object. Include these new elements.
Code
object FlatMap {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
fmapLines.print()
ssc.start()
ssc.awaitTermination()
}
}
Result
ps: Here we put a dependency graph on RDD map and flatMap (red block represents an RDD area and black block represents the set of partitions), which means
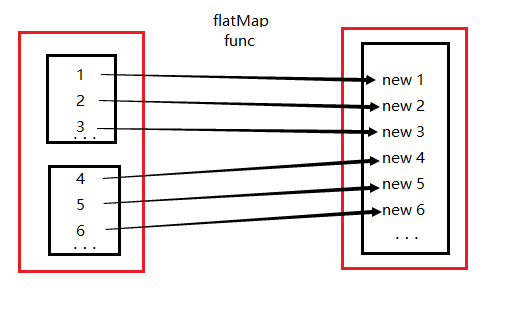
3) filter(func), every element of DStream is calculated by func method. If the func function returns true, the element is retained, otherwise the element is discarded and a new DStream is returned.
Code
object Filter {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val filterLines = lines.flatMap(_.split(" "))
.filter(!StringUtils.equals(_, "hello"))
filterLines.print()
ssc.start()
ssc.awaitTermination()
}
}
Result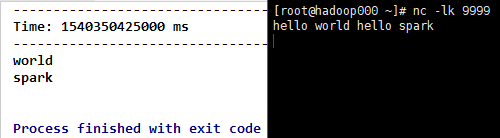
4) repartition (num Partitions), reset the partition, can operate on its own.
5) union (other Stream), which returns a new DStream containing the union of elements in the source DStream and other DStream.
Code
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val union1 = lines.map(word => "union1_" + word)
val union2 = lines.map(word => "union2_" + word)
val union1_2 = union1.union(union2)
union1.print()
union2.print()
union1_2.print()
ssc.start()
ssc.awaitTermination()
}
Result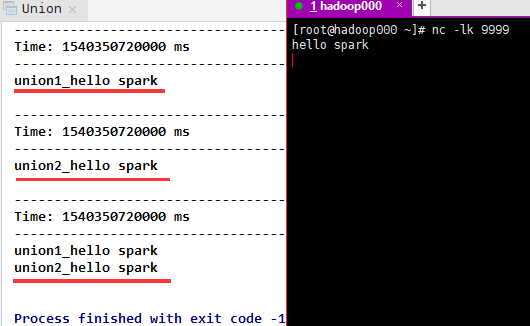
6) count(), which returns a new DStream for a single element RDD by calculating the number of elements in each RDD of the source DStream.
Code
object Count {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val mapLines = lines.map(_.split(" "))
val fmapLines = lines.flatMap(_.split(" "))
mapLines.count().print()
fmapLines.count().print()
ssc.start()
ssc.awaitTermination()
}
}
Result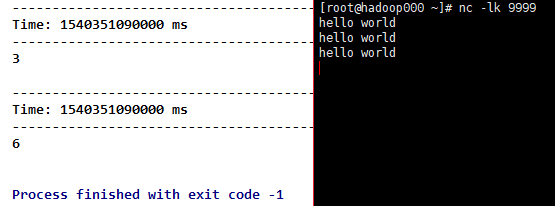
7) reduce(func), which returns a new DStream for a single element RDD by using the function func (which accepts two parameters and returns one), in which two parameters (elements) are calculated in pairs.
Code
object Reduce {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
val result = fmapLines.reduce(_ + "*" + _)
//fmapLines.reduce((a, b) => a + "*" + b)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
Result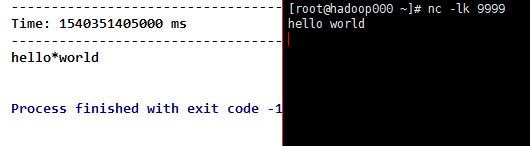
8) countByValue(), when called on a Stream element of type K, the element returning the new DStream is a (K, Long) pair, where the value of each key (Long) is its frequency in each RDD of the source DStream.
Code
object countByValue {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
val countByKey = fmapLines.countByValue()
countByKey.print()
ssc.start()
ssc.awaitTermination()
}
}
Result
9) ReducByKey (func, [numTasks]), when invoked on a Stream element of type (K, V), returns a new DStream of (K, V) pair, where K is the original K and V is calculated by K passing into func.
Note: By default, this uses Spark's default number of parallel tasks (default 2 in local mode and spark.default.parallelism in cluster mode) to group.
Code
object ReduceByKey {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
val tuple = fmapLines.map(word => (word, 1))
val reduceByKey = tuple.reduceByKey(_ + _)
reduceByKey.print()
ssc.start()
ssc.awaitTermination()
}
}
Result
10) join (other Stream, [num Tasks]), when invoked on two DStreams of (K, V) and (K, W) pairs, returns the new DStream content (K, (V, W) pair. numTasks Parallelism, optional
Code
object Join {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val words = lines.flatMap(_.split(" "))
val join1 = words.map(word => (word, "join1_" + word))
val join2 = words.map(word => (word, "join2_" + word))
val join1_2 = join1.join(join2)
join1.print()
join2.print()
join1_2.print()
ssc.start()
ssc.awaitTermination()
}
}
Result
11) cogroup (other Stream, [num Tasks]), when invoked on the DStream of (K, V) and (K, W) pairs, returns the new DStream of (K, Seq [V], Seq [W]) tuples. numTasks Parallelism, optional
Code
object Cogroup {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val words = lines.flatMap(_.split(" "))
val cogroup1 = words.map(word => (word, "cogroup1_" + word))
val cogroup2 = words.map(word => (word, "cogroup2_" + word))
val cogroup1_2 = cogroup1.cogroup(cogroup2)
cogroup1.print()
cogroup2.print()
cogroup1_2.print()
ssc.start()
ssc.awaitTermination()
}
}
Result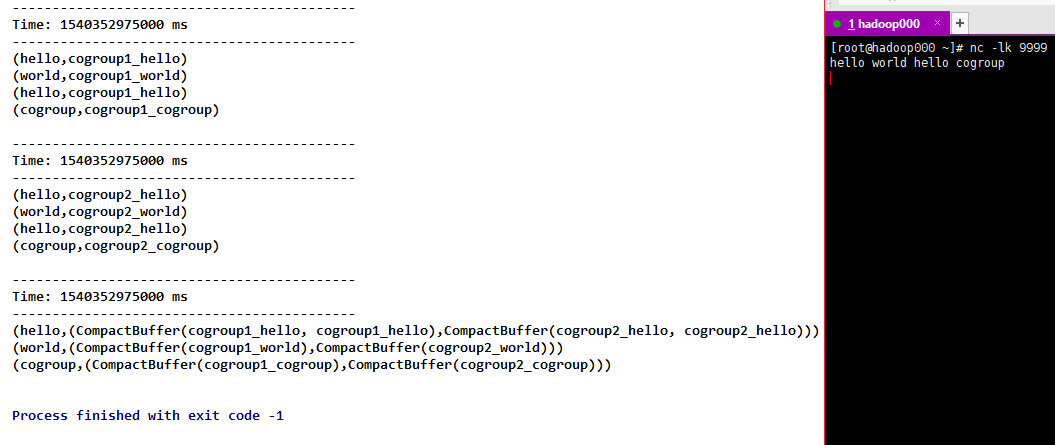
12)transform(func) Through train The new DStream is returned by applying the RDD-to-RDD function to each RDD of the source DStream. This can be used to perform any RDD operation on DStream.
Code
object Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val words = lines.transform(rdd=>{
rdd.flatMap(_.split(" "))
})
words.print()
ssc.start()
ssc.awaitTermination()
}
}
Result
13)updateStateByKey(func)Through train Returns a new "state" DStream in which the state of each key is updated by applying a given function to the prior state of the key and the new value of the key. This can be used to maintain arbitrary state data for each key.
Code
object UpdateStateByKey {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("FileWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
//Note that using updateStateByKey you need to configure the checkpoint directory
ssc.checkpoint("D:\\spark\\checkpoint")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val result = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
val state = result.updateStateByKey[Int](updateFunction _)
state.print()
ssc.start()
ssc.awaitTermination()
}
/**
* Update data
* @param newValues
* @param runningCount
* @return
*/
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val current = newValues.sum
val pre = runningCount.getOrElse(0)
Some(current + pre)
}
}
Result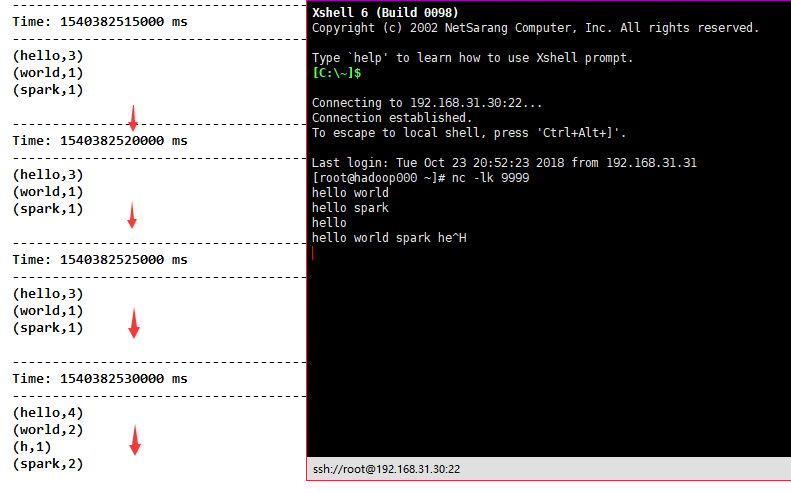
Window Operations
window: Timely operation of data over a period of time
Window length: window length
sliding interval: window spacing
These two parameters and batch size are multiples, and if they are not, errors will be reported.
1) Window (Windows Length, slideInterval), which takes out the elements of the current length window at the current moment to form a new DStream.
Code
object Window {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
//Calculate the results of the first 10 seconds every 5 seconds
val window = fmapLines.window(Seconds(10), Seconds(5))
window.print()
ssc.start()
ssc.awaitTermination()
}
}
Result
2) countByWindow (Windows Length, slideInterval) is similar to count, but Dstream is intercepted by us.
Code
object CountByWindow {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("D:\\spark\\checkpoint")
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
//The number of elements in the DStream of the current 10-second time window is counted every 5 seconds:
val countByWindow = fmapLines.countByWindow(Seconds(10), Seconds(5))
countByWindow.print()
ssc.start()
ssc.awaitTermination()
}
}
Result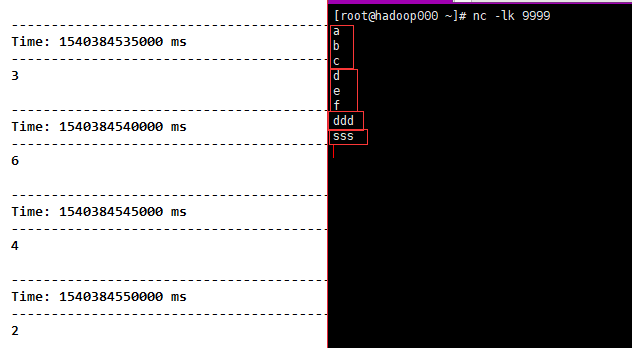
3) ReducByWindow (func, windows Length, slideInterval) is similar to reduce, but Dstream is intercepted by us.
Code
object ReduceByWindow {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("D:\\spark\\checkpoint")
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
val reduceByWindow = fmapLines.reduceByWindow(_ + "*" + _, Seconds(10), Seconds(5))
reduceByWindow.print()
ssc.start()
ssc.awaitTermination()
}
}
Result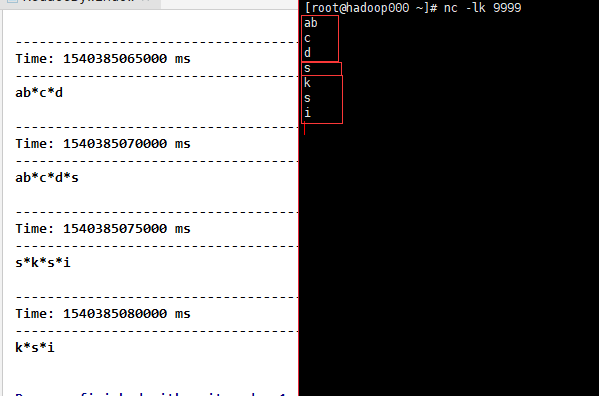
4)reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) Through train Similar to reduceByKey, but Dstream is intercepted by us.
Code
object ReduceByKeyAndWindow {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("D:\\spark\\checkpoint")
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
val tuple = fmapLines.map(word => (word, 1))
val reduceByKeyAndWindow = tuple.reduceByKeyAndWindow((a:Int,b:Int) => (a + b),Seconds(10),Seconds(5))
reduceByKeyAndWindow.print()
ssc.start()
ssc.awaitTermination()
}
}
Result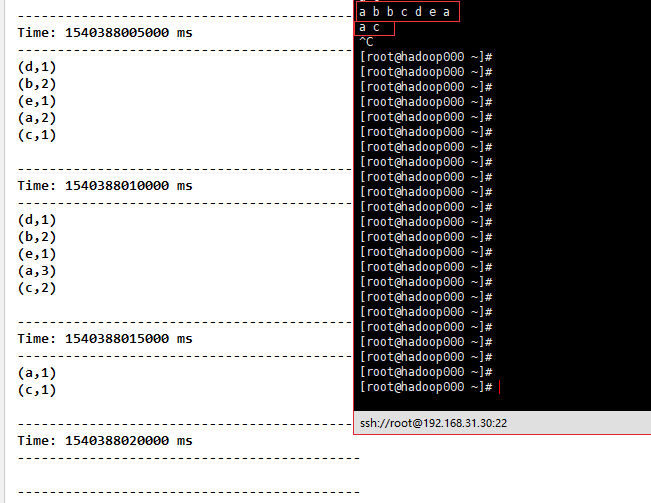
5) ReducByKey AndWindow (func, invFunc, windowLength, slideInterval, [numTasks]), compared with the above, an additional function invFunc is passed in. Like the station, there are people who go in, people who go out, people who go in + 1, people who come out - 1.
Code
object ReduceByKeyAndWindow2 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("D:\\spark\\checkpoint")
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
val tuple = fmapLines.map(word => (word, 1))
val reduceByKeyAndWindow = tuple.reduceByKeyAndWindow((a: Int, b: Int) => (a + b), (a: Int, b: Int) => (a - b), Seconds(10), Seconds(5))
reduceByKeyAndWindow.print()
ssc.start()
ssc.awaitTermination()
}
}
Result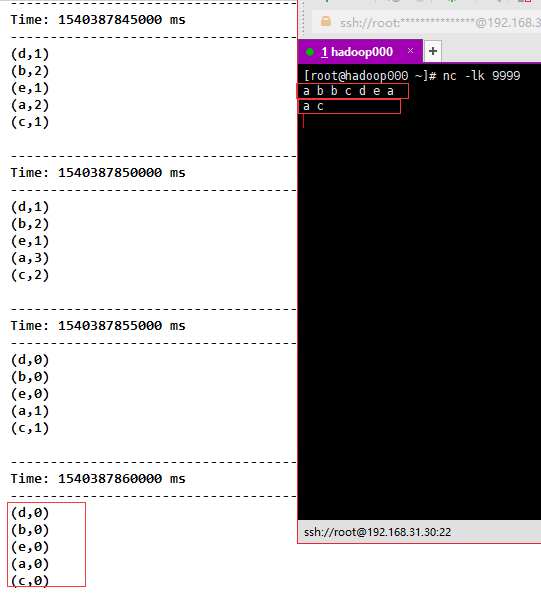
6) countByValue AndWindow (Windows Length, slideInterval, [numTasks]) is similar to countByValue, except that Dstream is intercepted by us.
Code
object CountByValueAndWindow {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("D:\\spark\\checkpoint")
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
val countByValueAndWindow = fmapLines.countByValueAndWindow(Seconds(10), Seconds(5))
countByValueAndWindow.print()
ssc.start()
ssc.awaitTermination()
}
}
Result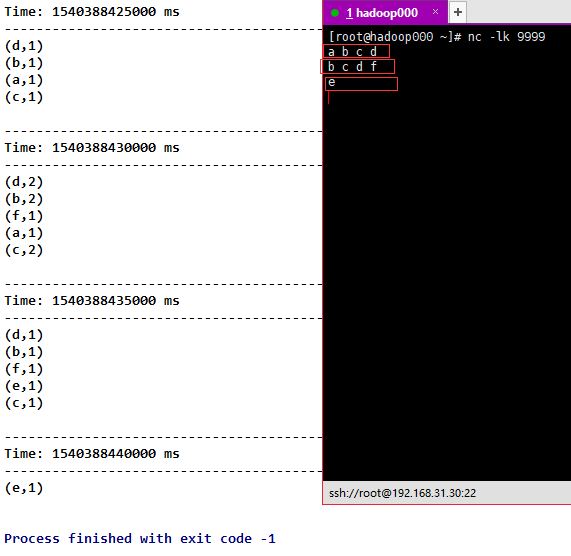
Join Operations
1)Stream-stream joins Through train
Call join, leftOuterJoin, rightOuterJoin, fullOuterJoin.
2)Stream-dataset joins Through train
val dataset: RDD[String, String] = ...
val windowedStream = stream.window(Seconds(20))...
val joinedStream = windowedStream.transform { rdd => rdd.join(dataset) }
After we call transform, we can connect to dataset.
Output Operations
| Output operation | Meaning |
|---|---|
| print() | Print the first ten elements of each batch of data in DStream on the driver node of the running stream application. This is very useful for development and debugging. |
| saveAsTextFiles(prefix, [suffix]) | Save the contents of this DStream as a text file. File names for each batch interval are generated based on prefix and suffix: "prefix-TIME_IN_MS [.suffix]". |
| saveAsObjectFiles(prefix, [suffix]) | Save the contents of this DStream as SequenceFiles serialized Java objects. File names for each batch interval are generated based on prefix and suffix: "prefix-TIME_IN_MS [.suffix]". |
| saveAsHadoopFiles(prefix, [suffix]) | Save the contents of this DStream as SequenceFiles serialized Java objects. File names for each batch interval are generated based on prefix and suffix: "prefix-TIME_IN_MS [.suffix]". Python API This is not available in Python API |
| foreachRDD(func) | The most general output operator, which applies the function func to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to a file or writing it to a database over the network. Note that the function func is executed in the driver process that runs the streaming application, and usually the RDD operation is executed in it, which forces the computation of streaming RDD. |
1) foreach RDD (func), correct and efficient use Through train
connection is an external link
Code
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}
More efficient
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}