1 ES data organization concept
The data organization concept of ES is compared with MySQL and MongoDB as follows:( "Most popular" basis)
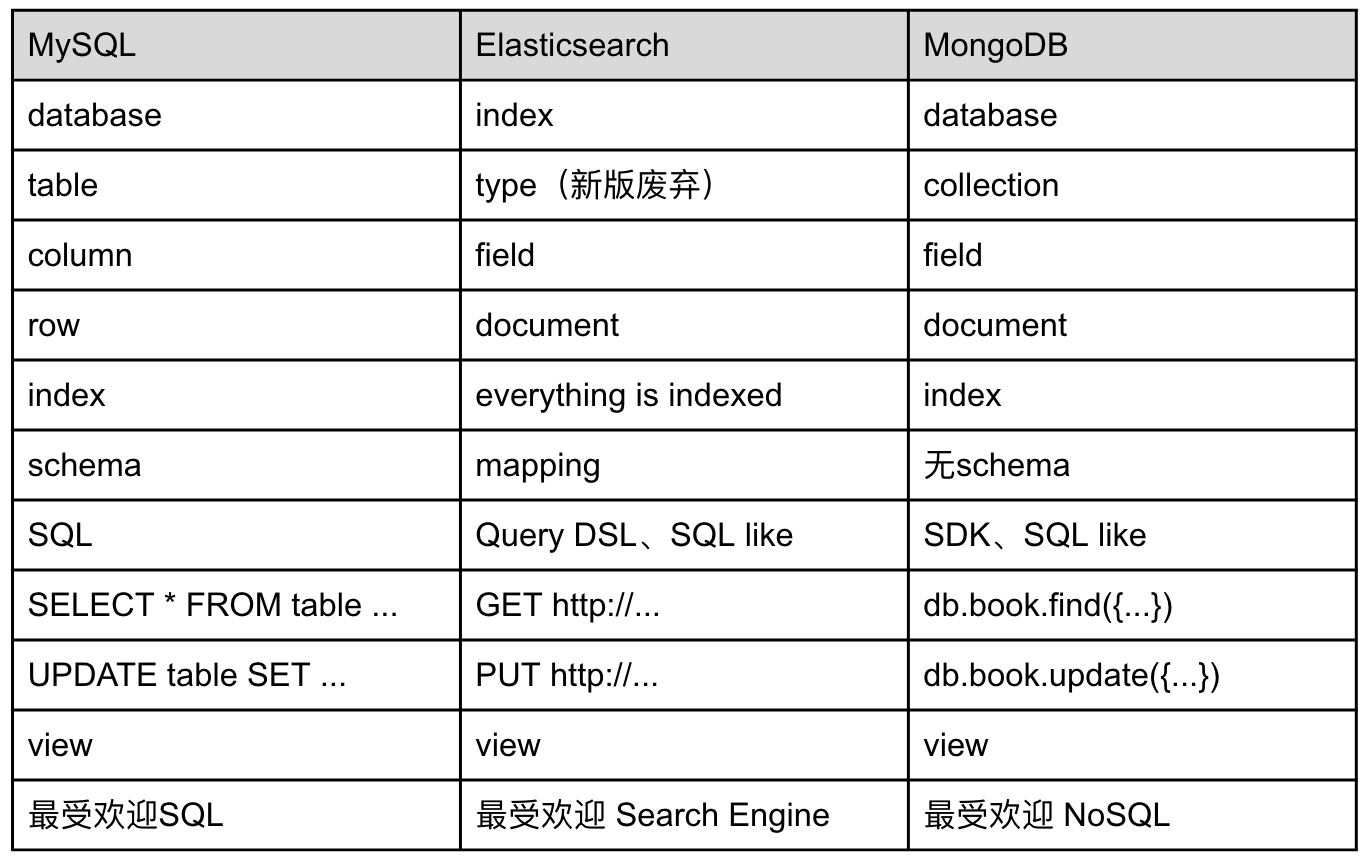
Note that the concept of ES Index here is similar to that of MySQL database, which is easy to be confused later.
What is more noteworthy is that after ES6, multiple types are not allowed in an Index. In Elasticsearch 7, the type has been removed. However, in order to be compatible with the old format, the _doc or self named type will be used as a unique type, and 8.x will not support type at all.
-
The way we often compare two-dimensional database with ES is an incorrect assumption. We compare "index" to database, "type" The specific reason is that the database tables are physically independent, and the columns of one table have no relationship with the columns of another table with the same name, which is not the case in ES. Fields with the same name in different type mapping types are internally supported by the same Lucene field.
-
When you want to index a deleted field, the data types are different in different types. One type is a date field and the other type is a Boolean field, this may lead to the storage failure of ES, because it affects the original design of ES.
-
In addition, the establishment of many entities in an index, type, without the same fields, will lead to sparse data. The final result is to interfere with Lucene's ability to effectively compress documents. In other words, it will affect the storage and retrieval efficiency of ES.
2 index management
The syntax of ES follows the RESTfull style, and the resource structure of PATH is / [index]/[type]/[document]
- The simplest way to create an index is to use the default configuration
PUT /index_name
- Create an index and specify some configurations
PUT /index_name
{
"settings": { // settings
"number_of_shards": 10, // Number of slices
"number_of_replicas": 1, // Number of copies per slice
"refresh_interval": "1s" // Refresh frequency of data falling disk
},
"mappings": { // mapping defines the data schema. Five fields are defined below,
"properties": { // In addition to type, each field has more optional attributes, which will not be introduced here
"uid": { "type": "long" },
"phone": {"type": "long"},
"message": {"type": "keyword"},
"msgcode": {"type": "long"},
"sendtime": {"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"}
}
}
}
- The mapping of the index can be automatically updated according to the data. For example, the following data can be directly inserted without creating an index
POST /index_name/_doc/1
{
"first_name" : "Tim2",
"last_name" : "Wang",
"age" : 26,
"about" : "go go go golang",
"interests": [ "golang", "world peace" ],
"hasomer": "gugu"
}
The recommended approach is to define the Schema of the index in advance, that is, create the index and formulate Mapping, and turn off the Dynamic Mapping feature.
PUT /index_name/_mapping/data
{
"dynamic":false
}
perhaps
PUT /index_name/_mapping/data
{
"dynamic":"strict"
}
The latter is more restrictive than the former. When a document has fields that are not in Mapping, the former can still be inserted, but no longer index new fields and provide search. The latter directly does not allow insertion.
You can also close Dynamic Mapping in the elasticsearch.yml configuration file
action.auto_create_index: false index.mapper.dynamic: false
- Delete index
DELETE /index_name
- Set index alias
PUT /index_name/_alias/my_alias
An index can have multiple aliases, and an alias can also act on multiple indexes. The index alias can be used for smooth migration. It is recommended to use the index alias in the project rather than the index name directly.
The application of index alias can facilitate smooth migration, which is recommended.
3 CRUD of data
3.1 insert data
You can use a simple PUT request to perform the operation. The request must specify the index name of the document, the unique document ID, and one or more key value pairs in the request body.
PUT /customer/_doc/1
{
"name": "John Doe"
}
This request (if it does not exist) will automatically create a new document with ID 1, store and index the key value pair.
Since this is a new document, the returned result shows that the version number of the newly created document is 1.
{
"_index" : "customer",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 26,
"_primary_term" : 4
}
3.2 simple query data
GET /customer/_doc/1
The document itself will be returned
{
"_index" : "customer",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 26,
"_primary_term" : 4,
"found" : true,
"_source" : {
"name": "John Doe"
}
}
3.3 search data
Once you start inserting data into Elasticsearch, you can send a request through _search. If you use the matching search function, use Elasticsearch Query DSL in the request body to specify the search criteria. You can also specify the index name to search in the request header.
As follows, in the search bank index, all accounts are sorted by account_number
GET /bank/_search
{
"query": { "match_all": {} },
"sort": [
{ "account_number": "asc" }
]
}
The first ten results that meet the criteria are returned by default
{
"took" : 63,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value": 1000,
"relation": "eq"
},
"max_score" : null,
"hits" : [ {
"_index" : "bank",
"_type" : "_doc",
"_id" : "0",
"sort": [0],
"_score" : null,
"_source" : {"account_number":0,"balance":16623,"firstname":"Bradshaw","lastname":"Mckenzie","age":29,"gender":"F","address":"244 Columbus Place","employer":"Euron","email":"bradshawmckenzie@euron.com","city":"Hobucken","state":"CO"}
}, {
"_index" : "bank",
"_type" : "_doc",
"_id" : "1",
"sort": [1],
"_score" : null,
"_source" : {"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"amberduke@pyrami.com","city":"Brogan","state":"IL"}
}, ...
]
}
}