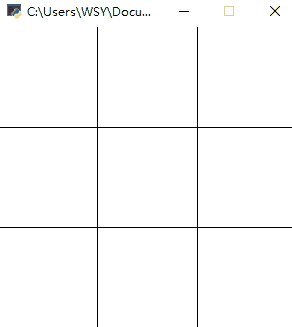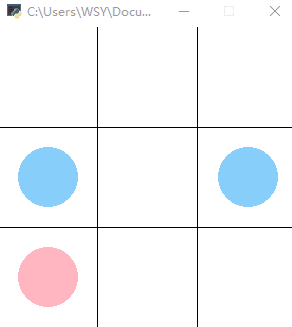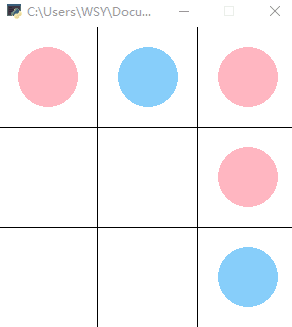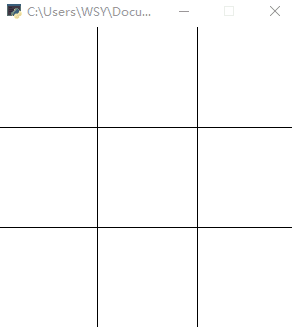In Article Enhanced Learning Practice|Customize the Gym Environment In, we learned how a simple environment should be defined and presented simply using print. In this article, we'll learn to customize a slightly more complex environment, Tingzi Chess. Recall the Tingzi game:
- This is a two-player round game. Players use different placeholders (circles/forks), so action writing needs to distinguish players
- The final reward is different for both players, winner + 1, loser - 1 (unless the draw + 0), reward writing needs to differentiate players
- The final condition is that any row/column/diagonal occupies the same placeholder or the field has no space to occupy
- From the perspective of a single player, the new state s_after action a under current state s It is not a follow-up state, but an intermediate state waiting for an opponent's action. The real follow-up state is the state s'(unless the game ends directly after taking action a), a s shown in the following figure:
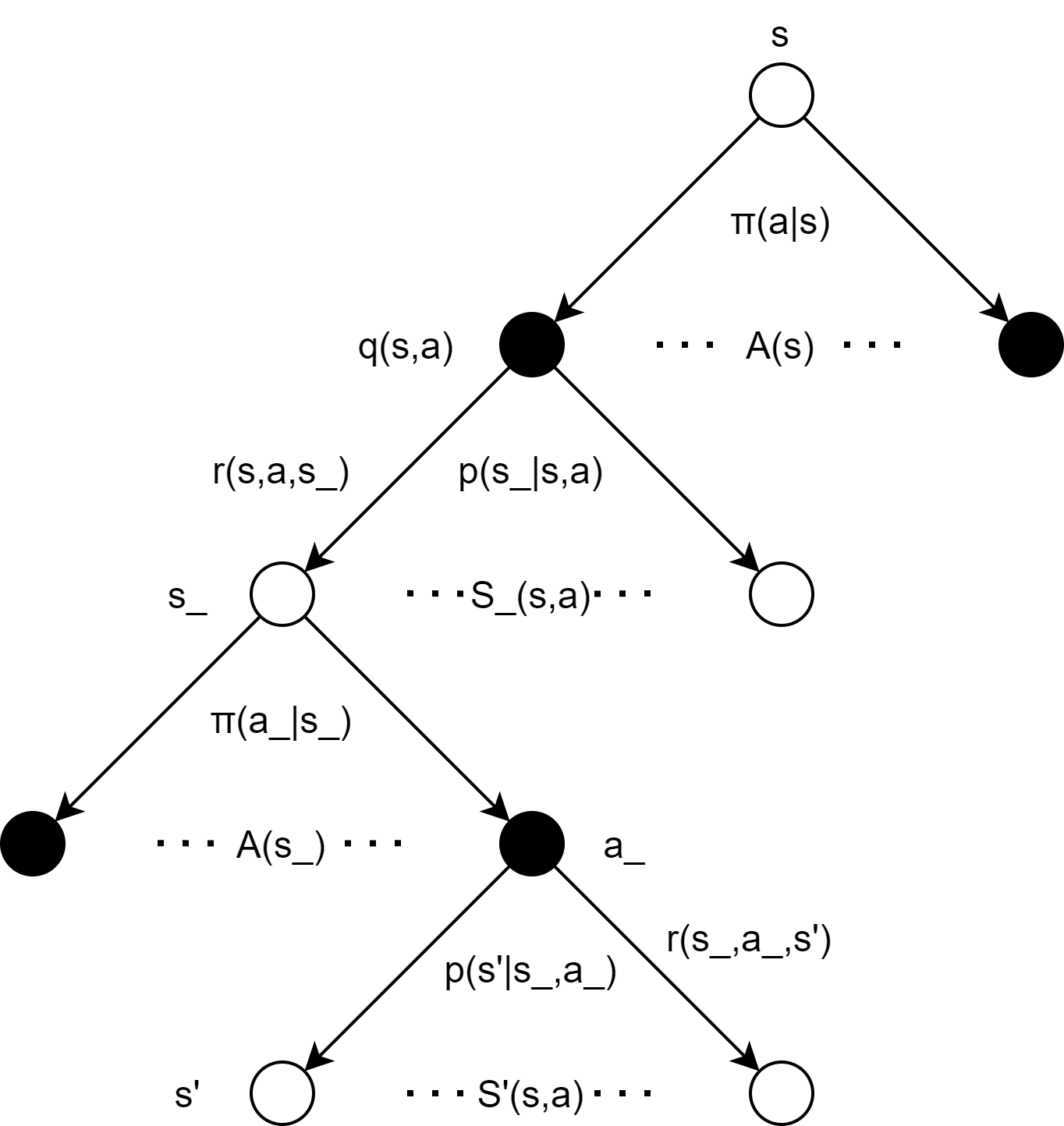
In addition to the mechanism of the game itself, considering the compatibility with gym's API interface format, it is convenient to control the game process through an external loop, so env itself does not have to write code to control the game process/switch the player. What's more, we need a more vivid presentation of the environment, not print! Then, let's get there!
Step 1: Create a new file
To the directory: D:\Anaconda\envs\pytorch1.1\Lib\site-packagesgym\envs\user, create the file_u user Init_u. Py and TicTacToe_env.py (remember? Folder user is an article) Enhanced Learning Practice|Customize the Gym Environment The folder we created to store the custom environment).
Step 2: Write TicTacToe_env.py and u Init_u. PY
gym has a built-in drawing tool, rendering, but it's not fully functional and it's cumbersome to draw complex things. This article does not intend to go into any further research, but simply uses the basic lines/squares/circles in renderings to present the environment (more vivid game performance can be achieved entirely through pygame). Renderings are drawn in a single frame, and when env.render() is called, the drawing elements recorded in the current self.viewer.geoms are rendered. The basic elements of the environment are designed as follows:
- Status: Represented by two-dimensional numpy.array, no placeholder value is 0, blue placeholder value is 1, and red placeholder value is -1.
- Action: Designed as a dictionary with formatting: action = {'mark':'blue','pos': (x, y)}, where'mark'denotes the color of placeholders to distinguish players and'POS' denotes placeholder positions.
- Reward: Lock the blue perspective, Win + 1, lose - 1, draw + 0.
TicTacToe_ The overall code for env.py is as follows:
import gym import random import time import numpy as np from gym.envs.classic_control import rendering class TicTacToeEnv(gym.Env): def __init__(self): self.state = np.zeros([3, 3]) self.winner = None WIDTH, HEIGHT = 300, 300 self.viewer = rendering.Viewer(WIDTH, HEIGHT) def reset(self): self.state = np.zeros([3, 3]) self.winner = None self.viewer.geoms.clear() # Empty the elements on the drawing board that need to be drawn self.viewer.onetime_geoms.clear() def step(self, action): # Format of action: action = {'mark':'circle'/'cross', 'pos':(x,y)}# Generation State x = action['pos'][0] y = action['pos'][1] if action['mark'] == 'blue': self.state[x][y] = 1 elif action['mark'] == 'red': self.state[x][y] = -1 # reward done = self.judgeEnd() if done: if self.winner == 'blue': reward = 1 else: reward = -1 else: reward = 0 # Presentation info = {} return self.state, reward, done, info def judgeEnd(self): # Check two diagonals check_diag_1 = self.state[0][0] + self.state[1][1] + self.state[2][2] check_diag_2 = self.state[2][0] + self.state[1][1] + self.state[0][2] if check_diag_1 == 3 or check_diag_2 == 3: self.winner = 'blue' return True elif check_diag_1 == -3 or check_diag_2 == -3: self.winner = 'red' return True # Check three rows and three columns state_T = self.state.T for i in range(3): check_row = sum(self.state[i]) # Check line check_col = sum(state_T[i]) # Check Columns if check_row == 3 or check_col == 3: self.winner = 'blue' return True elif check_row == -3 or check_col == -3: self.winner = 'red' return True # Check to see if the whole board is still empty empty = [] for i in range(3): for j in range(3): if self.state[i][j] == 0: empty.append((i,j)) if empty == []: return True return False def render(self, mode='human'): SIZE = 100 # Draw Separator Line line1 = rendering.Line((0, 100), (300, 100)) line2 = rendering.Line((0, 200), (300, 200)) line3 = rendering.Line((100, 0), (100, 300)) line4 = rendering.Line((200, 0), (200, 300)) line1.set_color(0, 0, 0) line2.set_color(0, 0, 0) line3.set_color(0, 0, 0) line4.set_color(0, 0, 0) # Add drawing elements to the drawing board self.viewer.add_geom(line1) self.viewer.add_geom(line2) self.viewer.add_geom(line3) self.viewer.add_geom(line4) # according to self.state Draw placeholder for i in range(3): for j in range(3): if self.state[i][j] == 1: circle = rendering.make_circle(30) # Draw a circle with a diameter of 30 circle.set_color(135/255, 206/255, 250/255) # mark = blue move = rendering.Transform(translation=(i * SIZE + 50, j * SIZE + 50)) # Create Pan Operation circle.add_attr(move) # Add a translation operation to the properties of a circle self.viewer.add_geom(circle) # Add a circle to the drawing board if self.state[i][j] == -1: circle = rendering.make_circle(30) circle.set_color(255/255, 182/255, 193/255) # mark = red move = rendering.Transform(translation=(i * SIZE + 50, j * SIZE + 50)) circle.add_attr(move) self.viewer.add_geom(circle) return self.viewer.render(return_rgb_array=mode == 'rgb_array')
In u Init_u. Introducing class information in py, adding:
from gym.envs.user.TicTacToe_env import TicTacToeEnv
Step 3: Register Environment
To the directory: D:\Anaconda\envs\pytorch1.1Lib\site-packages\gym, open_u Init_u. Py, add code:
register( id="TicTacToeEnv-v0", entry_point="gym.envs.user:TicTacToeEnv", max_episode_steps=20, )
Step 4: Test environment
In the test code, we keep the game going in the main loop. The blue and red players randomly select a space action at a 0.5s interval with the following code:
import gym import random import time # View all registered environments # from gym import envs # print(envs.registry.all()) def randomAction(env_, mark): # Randomly Select Unoccupied Grid Action action_space = [] for i, row in enumerate(env_.state): for j, one in enumerate(row): if one == 0: action_space.append((i,j)) action_pos = random.choice(action_space) action = {'mark':mark, 'pos':action_pos} return action def randomFirst(): if random.random() > 0.5: # Random First Hand first_, second_ = 'blue', 'red' else: first_, second_ = 'red', 'blue' return first_, second_ env = gym.make('TicTacToeEnv-v0') env.reset() # For the first time step Reset environment first or error will occur first, second = randomFirst() while True: # First-hand action action = randomAction(env, first) state, reward, done, info = env.step(action) env.render() time.sleep(0.5) if done: env.reset() env.render() first, second = randomFirst() time.sleep(0.5) continue # Behind-the-scenes action action = randomAction(env, second) state, reward, done, info = env.step(action) env.render() time.sleep(0.5) if done: env.reset() env.render() first, second = randomFirst() time.sleep(0.5) continue
The effect is as follows: